Vision Transformer (ViT) Architecture (original) (raw)
Last Updated : 20 Dec, 2025
Vision Transformer (ViT) is a deep learning architecture that applies the Transformer model to images. Instead of relying on convolutions, ViTs use self-attention to capture relationships across all image patches, enabling a global understanding of the image. This approach has achieved state-of-the-art results in various computer vision tasks.
- Uses self-attention to model global dependencies between image patches.
- Unlike CNNs, it does not rely on convolution operations for feature extraction.
- Demonstrates strong performance in image classification, object detection and segmentation.
Vision Transformer (ViT) Architecture Overview
Instead of processing words, ViT treats an image as a sequence of fixed-size patches and applies self-attention across them. This allows the model to capture long range dependencies between different parts of an image without relying on convolution operations.
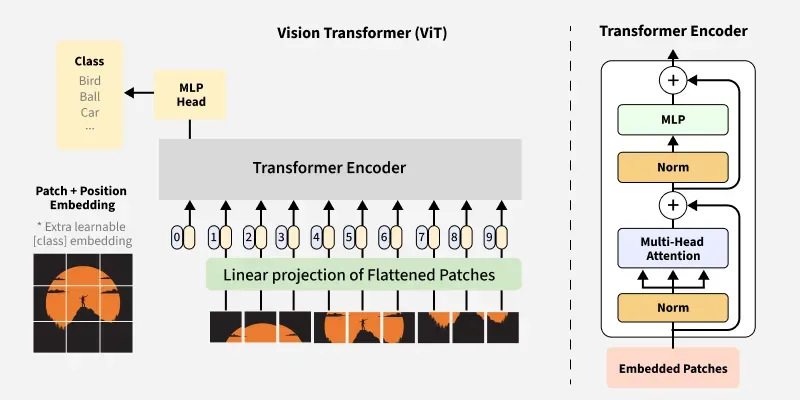
ViT Architecture
ViT architecture includes the following major components:
1. Image Patching and Embedding
This stage converts a 2D image into a sequence of patch embeddings, analogous to tokens in NLP. It forms the input for the Transformer by turning spatial information into a linear sequence.
- ****Patch Splitting:**The image is divided into fixed size and non-overlapping patches each treated as a token and converted into a 1D sequence for the Transformer reducing computation while preserving local spatial information.

Patch Splitting
- **Patch Flattening: Each patch of size P \times P \times C is flattened into a single vector of length P^2 \times C. This flattening removes spatial dimensions temporarily and allows the model to treat patches uniformly. The flattened vectors serve as the raw inputs to the linear projection layer.
- **Patch Embedding (Linear Projection): Each flattened patch is mapped to a learnable D dimensional embedding enabling the model to learn high level features similar to word embeddings in NLP.
Patch embeddings can also be extracted using a convolution layer with kernel size and stride equal to the patch size, making each convolution act as a patch extractor.
2. Positional Encoding
Since Transformers are permutation invariant, positional encodings inject spatial order so the model knows the relative positions of patches.
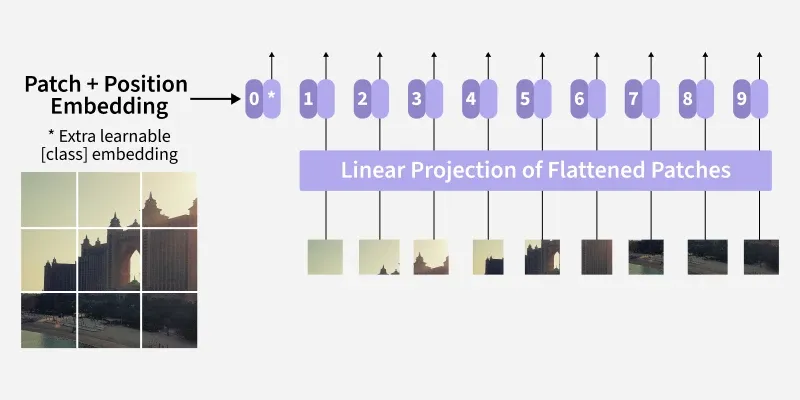
Positional Encoding
- **Need for Positional Encoding: Since Transformers treat tokens as unordered positional encodings are added to retain spatial structure and patch location information.
- **Learnable Positional Embeddings: ViT uses learnable positional vectors to capture local and global spatial relationships adapting better than fixed encodings across image resolutions.
3. Adding the Classification Token (CLS Token)
A learnable CLS token is prepended to the patch sequence to aggregate information from all patches, serving as the image-level representation for classification.
- **Purpose of the CLS Token: The CLS token is a learnable vector added to patch embeddings that gathers global information and is used for final classification, similar to BERT.
- **How the CLS Token Learns Image-Level Representation: The CLS token attends to all patches to learn global image features and its final output alone is used for prediction without CNN style pooling.
4. Transformer Encoder (Pre-LayerNorm Architecture)
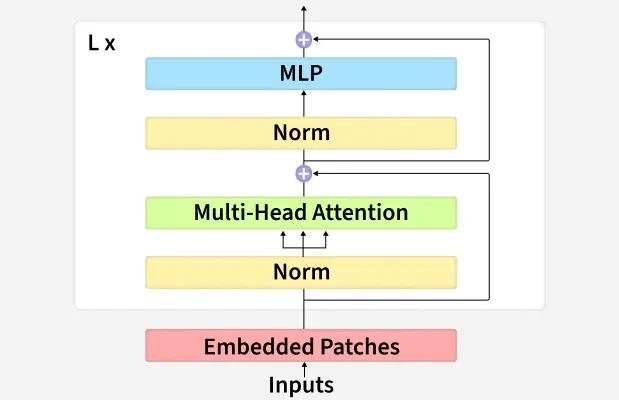
Transformer Encoder
Pre-LayerNorm applies LayerNorm before both the attention and feed-forward blocks. This stabilizes gradient flow and prevents the exploding/vanishing gradient problem in deep Transformers.
\text{LayerNorm}(x) = \frac{x - \mu}{\sigma} \odot \gamma + \beta
Where
- \mu, \sigma are mean and std across features
- \gamma, \beta are learnable.
Each Encoder Block has:
- Multi-Head Self-Attention (MSA)
- Feed-Forward Network (FFN)
- Residual connections and LayerNorm
5. Multi-Head Self-Attention (MSA)
Allows each patch to attend to every other patch to model global dependencies, capturing relationships between distant image regions.
**1. **Self-Attention Mechanism
Self-attention enables each patch to relate to all others by using query, key and value projections with the attention matrix controlling token influence. The input sequence consists of N image patches plus 1 CLS token, with each token represented by a D-dimensional embedding.
Compute Queries, Keys and Values
Q = XW_Q, K = XW_K, V = XW_V
where W_Q, W_K, W_V are learnable weight matrices for linear projections
Attention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
- QK^T computes similarity between all pairs of tokens (dot product)
- d_k = \frac{D}{h} the dimension per attention head
- Divide by \sqrt{d_k} for scaling to prevent large values causing softmax saturation
- softmax normalizes scores into probabilities for attention weights
- Multiply by V to get weighted sum of information from all tokens
Multiple attention heads allow the model to attend to different types of information simultaneously. The outputs of all heads are concatenated and linearly projected to form the final attention output. This parallel attention mechanism leads to richer and more diverse feature representations.
\text{MSA}(\mathbf{X}) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)\mathbf{W}_O
Multiple heads (hhh) allow the model to focus on different types of relationships simultaneously (e.g., edges, color, textures, global shapes)
\text{head}_i = \text{Attention}(\mathbf{X}\mathbf{W}_Q^i, \mathbf{X}\mathbf{W}_K^i, \mathbf{X}\mathbf{W}_V^i)
6. Feed-Forward Network (FFN)
The FFN transforms each patch embedding to a higher-dimensional space and back using two dense layers with a GELU activation, enabling complex feature learning. It operates independently on each token with shared weights, allowing efficient non-linear transformations.
\text{FFN}(\mathbf{x}) = \mathbf{W}_2 \text{GELU}(\mathbf{W}_1 \mathbf{x} + \mathbf{b}_1) + \mathbf{b}_2
Expands and transforms features for better expressiveness. GELU Activation is used for smooth non-linearity improves learning and stability.
7. Residual Connections and Layer Normalization
Ensures stable training in deep networks by preserving information and normalizing activations.
- **Residual (Skip) Connections: Residual connections bypass transformation blocks to preserve earlier layer information, preventing degradation in deep networks. They enable the model to learn incremental refinements, improving convergence and stability in deep ViTs.
- **Layer Normalization: LayerNorm normalizes features across the input, stabilizing training and reducing internal covariate shift. Pre-LN ensures well-conditioned gradients and consistent scaling across tokens in deep Transformers.
8. Classification Head (MLP Head)
Converts the CLS token output into class probabilities using a small feed-forward network.
- **MLP Head Structure: The classification head uses one or two fully connected layers on the final CLS token to produce class probabilities, optionally with dropout for regularization. It serves as the ViT’s final decision-making component.
- **Softmax for Prediction: Softmax converts logits into normalized probabilities summing to 1, with the highest probability indicating the predicted class. It enables multi-class classification and pairs with cross-entropy loss during training.
9. Training Vision Transformers
ViTs need more data than CNNs due to low inductive bias and training involves pretraining on large datasets followed by finetuning.
- **Inductive Bias Differences: CNNs use strong inductive biases like locality and translation invariance, while ViTs treat images as patch sequences, requiring more data but offering greater flexibility.
- **Data Requirements: ViTs need large-scale datasets and augmentations to generalize well due to their low inductive bias, unlike CNNs.
- **Pretraining: Pretraining lets ViTs learn general visual features via supervised or self-supervised methods, reducing compute needs for downstream tasks.
- **Finetuning: Finetuning adapts pretrained ViTs to specific datasets using fewer labels, often with layer-wise learning rate decay to improve performance.
Vision Transformer (ViT) vs. Convolutional Neural Networks (CNNs)
Here we compare ViT with CNN
| Features | CNNs | ViTs |
|---|---|---|
| Attention Scope | Capture local features via convolutions | Capture global relationships via self-attention |
| Inductive Bias | Strong biases (locality, translation invariance) | Minimal biases, more flexible but data-hungry |
| Data Requirement | Work well with small datasets | Need large datasets for best performance |
| Feature Learning | Learn hierarchical features | Learn context-rich, long-range features |
Advantages
- **Global Context: Captures long-range dependencies between patches, understanding the overall image context.
- **Scalability: Performs well with larger datasets and deeper architectures for complex vision tasks.
- **Parallel Processing: Transformer architecture allows for efficient parallel computation compared to sequential CNN operations.
- **Unified Architecture: Can handle different input modalities (images, patches, or tokens) within the same framework.
- **Strong Representations: Learns powerful high-level feature representations due to attention mechanisms capturing diverse patterns.
Limitations
- **Data-Hungry Nature: Requires very large datasets to learn meaningful visual representations.
- **High Computational Cost: Self-attention scales quadratically with the number of patches, increasing memory and compute requirements.
- **Lack of Local Feature Bias: Does not naturally exploit local patterns, reducing sample efficiency.
- **Sensitivity to Hyperparameters: Patch size, embedding dimension, and attention heads need careful tuning.
- **Difficulty with Small Images: Few tokens from small images reduce attention effectiveness.
- **Longer Training Times: High complexity and large datasets lead to extended training durations.