What is Embedding Layer ? (original) (raw)
Last Updated : 23 Jul, 2025
The embedding layer converts high-dimensional data into a lower-dimensional space. This helps models to understand and work with complex data more efficiently, mainly in tasks such as natural language processing (NLP) and recommendation systems.
In this article, we will discuss what an embedding layer is, how it works, and its applications in simple language, and simple example code.
Table of Content
- What is an Embedding Layer?
- How Embedding Layers Work ?
- Building a Simple Neural Network with an Embedding Layer
- Pre-trained Embeddings: Word2Vec, GloVe, FastText
- Visualizing Embedding Space
What is an Embedding Layer?
The embedding layer represents data, such as words or categories, in a more meaningful form by converting them into numerical vectors that a machine can understand. It is commonly used in Natural Language Processing (NLP) and recommendation systems to handle categorical data. Since computers can only process numbers, an embedding layer helps convert large sets of data into smaller, more efficient vectors, making it easier for the machine to learn patterns.
The main uses of embedding layers include:
- **Reduce Dimensionality: It compresses high-dimensional data into a more manageable size.
- **Capture Relationships: It enables the model to understand relationships between different inputs, such as words in a sentence.
- **Improve Efficiency: By using dense vectors, the model processes data faster and more effectively.
How Embedding Layers Work ?
- **Input Representation: Suppose we have a sentence with words such as "cat", "dog", and "apple". Each of these words will gets a unique number in ID form
- **Embedding Mapping: The embedding layer maps each word to a vector. So it does not represent ****"cat"** as just a number, it is changed into a list of numbers that describes its features in a meaningful way. For example, "cat" could be represented as **[0.2, 0.8, -0.5], and "dog" could be represented as **[0.3, 0.7, -0.6].
- **Learning Relationships: With time the machine learning model learns how to adjust these vectors so that words with similar meanings or relationships such as "cat" and "dog" are positioned closer to each other in this numerical space.

Example of Learning Relationships
Consider the sentence ****"The cat chased the mouse."**
In this context, the model learns that the word "cat" often appears near words like "chased" and "mouse".
As a result, "cat" will have a vector representation that is similar to other animals, such as "dog****"** because they share similar contexts in many sentences. This means that if we visualize these words in an embedding space, "cat," "dog," and "mouse" will be clustered together reflecting their roles as animals.
Building a Simple Neural Network with an Embedding Layer
The following is a simple example that helps us understand how to use an embedding layer in Python with TensorFlow. The model utilizes an embedding layer to process input data. Here's how it works:
- **input_dim refers to the size of the vocabulary, which is the number of unique words.
- **output_dim specifies the size of each word's vector, also known as the embedding size. For example, each word could be represented as a 128-dimensional vector.
- **input_length defines the length of each input sequence.
This setup allows the model to transform words into dense vectors of fixed size, which are easier for neural networks to process and understand.
Python `
import tensorflow as tf from tensorflow.keras import layers, models
vocab_size = 10000 # Size of the vocabulary embedding_dim = 128 # Dimension of the embedding vector input_length = 100 # Length of input sequences
model = models.Sequential()
Embedding layer
model.add(layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim, input_length=input_length))
model.add(layers.GlobalAveragePooling1D())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Check the model summary
model.build(input_shape=(None, input_length)) model.summary()
`
**Output:
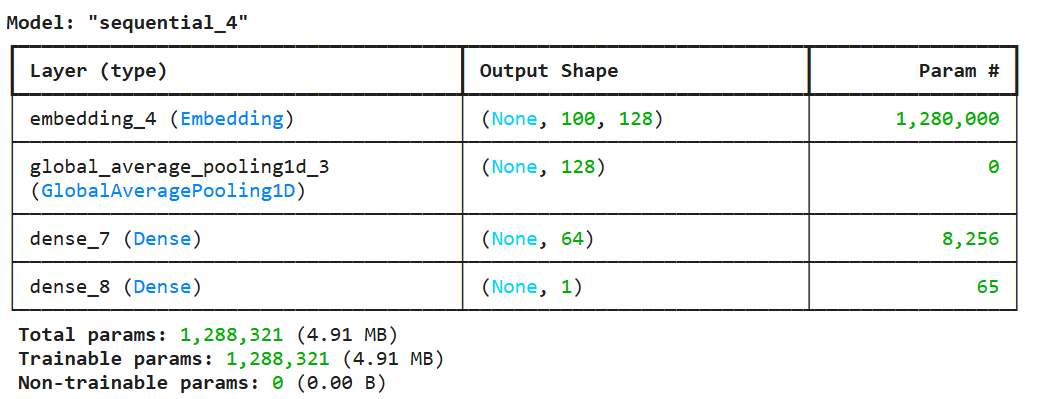
In the model summary, embedding layers an output shape of (None, 100, 128), meaning it processes input sequences of length 100 and maps each token to a 128-dimensional vector. The layer contains 1,280,000 parameters, which are the embeddings for each word in the vocabulary. These parameters will be learned during training.
Pre-trained Embeddings Models: Word2Vec, GloVe, FastText
Creating embeddings from scratch requires huge amount of datasets and computational power. Pre-trained embeddings makes this process easy:
- **Word2Vec****:** It is one of the earliest models to create word embeddings. It learns how different words are related to each other just by looking at different words that surround them in a sentence.
- **GloVe (Global Vectors for Word Representation)****:** This model mainly focuses on capturing the overall statistics of word occurrences in a large dataset.
- **FastText: It was developed by Facebook. FastText is more advanced as it also captures the meanings of word parts like prefixes and suffixes. This is helpful for dealing with languages where word forms change such as adding _"-ing" or "-ed"_ to verbs.
Visualizing Embedding Space
Visualizing embedding space helps us to observe how words that are semantically similar are clustered together in the embedding space. For this task, we will use GloVe (Global Vectors for Word Representation), a pre-trained word embedding model. We will load the GloVe embeddings, extract the vectors for specific words like "king", "queen", "man", "woman", "boy", and "girl", and then reduce the dimensionality of these vectors to 2D using t-SNE.
You can download the GloVe Embeddings from here.
Python `
import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE
Define the words
words = ['king', 'queen', 'man', 'woman', 'boy', 'girl']
Function to load GloVe embeddings
def load_glove_embeddings(file_path): embeddings = {} with open(file_path, 'r', encoding='utf-8') as f: for line in f: values = line.strip().split() word = values[0] vector = np.asarray(values[1:], dtype='float32') embeddings[word] = vector return embeddings
glove_embeddings = load_glove_embeddings('glove.6B.50d.txt')
embedding_vectors = [] for word in words: if word in glove_embeddings: embedding_vectors.append(glove_embeddings[word])
embedding_vectors = np.array(embedding_vectors)
Use t-SNE for dimensionality reduction to 2D
tsne = TSNE(n_components=2, random_state=42, perplexity=2) reduced_embeddings_tsne = tsne.fit_transform(embedding_vectors)
Plot the words in the 2D space
plt.figure(figsize=(8, 6)) for i, word in enumerate(words): plt.scatter(reduced_embeddings_tsne[i, 0], reduced_embeddings_tsne[i, 1]) plt.text(reduced_embeddings_tsne[i, 0] + 0.1, reduced_embeddings_tsne[i, 1] + 0.1, word, fontsize=12)
plt.title('Word Embeddings Visualization (2D)') plt.show()
`
**Output:

This visualization will help us see how words like "king" and "queen", or "man" and "woman" are placed in proximity, reflecting the semantic relationships between them in the embedding space.
Use Case of Embedding Layer
- **Word Embeddings: The embedding layer converts words or tokens into dense vectors (low-dimensional representation) that capture semantic meaning. These embeddings can then be used in various NLP tasks such as text classification, NER, machine translation, part-of-speech tagging, and question answering.
- **Collaborative Filtering: The embedding layer is used to learn embeddings for both users and items (such as products, movies, etc.). The learned embeddings can then be used to predict user preferences and recommend items.
- **Combining Text and Image Data: In tasks that involve both text and images (e.g., visual question answering, image captioning), embeddings can be used to represent both the visual and textual inputs in a unified space, facilitating cross-modal understanding.
- **Node Embeddings: In graph-based tasks (e.g., social networks), embedding layers can be used to learn representations of nodes (users, products, etc.), which can be used in tasks such as node classification or link prediction.
Embedding layers are one of important components in modern neural networks, especially for tasks which involves textual and categorical data. It helps in converting words, categories, or items into meaningful numerical representations. It allows machines to understand relationships between them. With pre-trained embeddings like Word2Vec, GloVe, and FastText, we can get started easily without needing massive amounts of data.