Boyer Moore Algorithm | Good Suffix heuristic (original) (raw)
Last Updated : 12 Apr, 2025
Before diving into the **Good Suffix Heuristic, it is recommended to first read about the **Boyer-Moore Pattern Searching Algorithm and the **Bad Character Heuristic to gain a clear understanding of how this algorithm optimizes pattern searching.
Refer Boyer Moore Algorithm for Pattern Searching for clear understanding of Boyer Moore Algo.
One important part of the Boyer-Moore algorithm is the **Good Suffix Heuristic. When the algorithm encounters a mismatch, this heuristic helps by shifting the pattern to align with another occurrence of a similar part (suffix) of the pattern that has already matched. This reduces the number of checks needed, making the search faster.
Good Suffix Heuristic for Pattern Searching
Just like the **Bad Character Heuristic, the **Good Suffix Heuristic also involves a preprocessing step where a table is generated to optimize the pattern matching process. The **Strong Good Suffix Heuristic is an important optimization in the **Boyer-Moore algorithm for string pattern matching. It helps to skip unnecessary comparisons and efficiently shift the pattern when a mismatch occurs. Let’s break down how it works and its associated preprocessing.
Let t be a substring of the text T that matches a substring of the pattern P. When a mismatch occurs, the pattern is shifted based on the following rules:
- **Another occurrence of
tinP - **Prefix of
Pmatches the suffix oft - **Move the pattern past
t
This heuristic helps optimize the search by allowing the pattern to skip over sections of the text that have already been matched, leading to faster string matching.
**Case 1: Another occurrence of t in P matched with t in T
If there are other occurrences of the substring t in the pattern P, the pattern is shifted so that one of these occurrences aligns with the substring t in the text T. This allows the pattern to continue matching efficiently. For example-
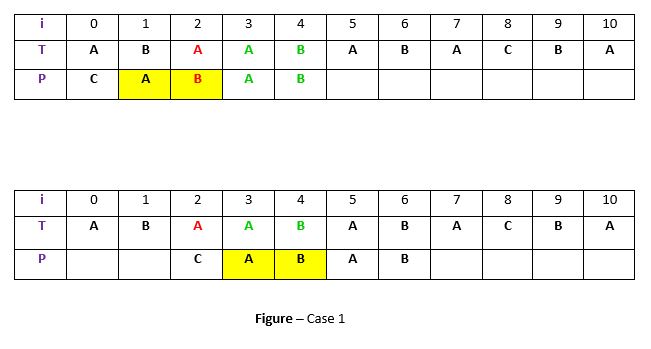
**Explanation:
In the above example, we have a substring t of text T that matches with pattern P (in green) before the mismatch occurs at index 2. Now, we search for occurrences of t ("AB") within P. We find an occurrence starting at position 1 (highlighted with a yellow background). Therefore, we right shift the pattern by 2 positions to align the occurrence of t in P with t in T.
This is the weak rule of the original Boyer-Moore algorithm, which is not very effective. We will discuss the **Strong Good Suffix rule shortly, which provides a more efficient approach.
**Case 2: A prefix of P, which matches with suffix of t in T
It is not always guaranteed that we will find an occurrence of t in P. In some cases, there may be no exact occurrence at all. In such situations, we can instead look for a **suffix of t that matches with a **prefix of P. If a match is found, we can shift the pattern P to align the matched suffix of t with the prefix of P, allowing us to continue the search effectively. This method helps when direct matches for t are not found, and it ensures that the search can still progress efficiently. For example -
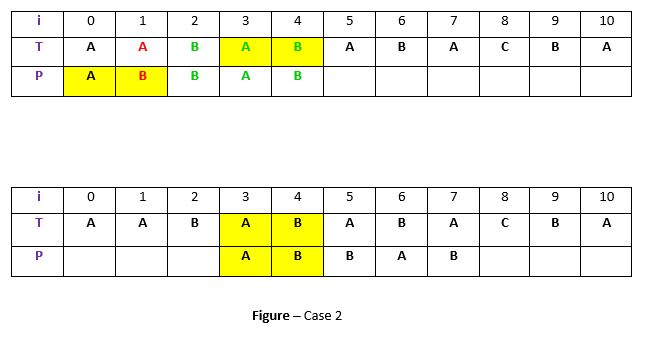
**Explanation:
In above example, we have got t (“BAB”) matched with P (in green) at index 2-4 before mismatch . But because there exists no occurrence of t in P we will search for some prefix of P which matches with some suffix of t. We have found prefix “AB” (in the yellow background) starting at index 0 which matches not with whole t but the suffix of t “AB” starting at index 3. So now we will shift pattern 3 times to align prefix with the suffix.
**Case 3: P moves past t
If the above two cases are not satisfied, we will shift the pattern past the t. For example -
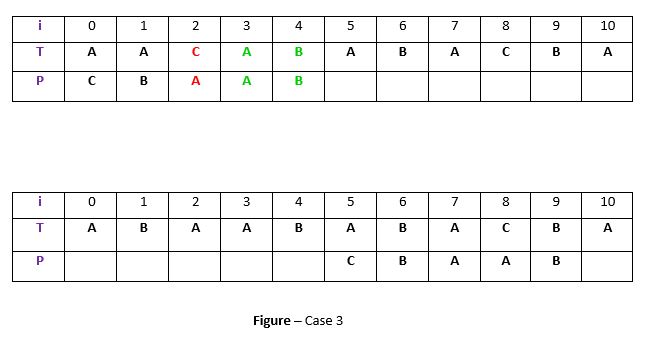
**Explanation:
If above example, there exist no occurrence of t (“AB”) in P and also there is no prefix in P which matches with the suffix of t. So, in that case, we can never find any perfect match before index 4, so we will shift the P past the t ie. to index 5.
Suppose the substring q = P[i to n] of the pattern P has matched with the substring t in the text T, and the character c = P[i-1] is the mismatching character.
Unlike the weak rule of the Good Suffix Heuristic, we now search for the substring t in P where t is not preceded by the character c. This means we look for occurrences of t in the pattern P that are **not immediately preceded by the mismatching character c.
The **closest occurrence of t in P, which is not preceded by c, is then aligned with t in T. The pattern P is shifted accordingly to align this occurrence of t in the pattern with the matched substring t in the text. This **strong rule of the Good Suffix Heuristic enhances the efficiency of the Boyer-Moore algorithm by ensuring that the pattern is shifted more effectively, reducing unnecessary comparisons and speeding up the search process.
For example -
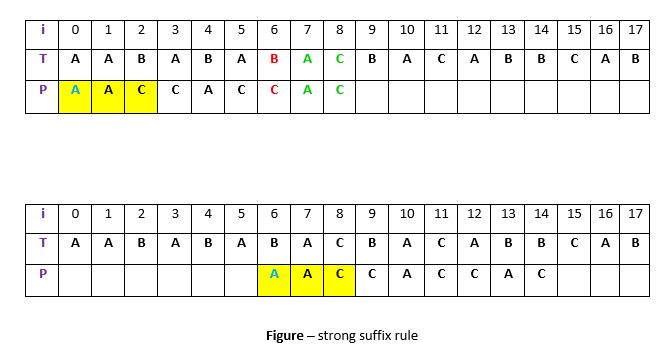
**Explanation:
Consider the scenario where a substring q = P[i to n] of the pattern P has matched with a substring t in the text T, and the mismatching character c = P[i-1] is found at position P[i-1]. Instead of searching for the occurrence of t in the pattern P that is preceded by the mismatching character c, we focus on finding the occurrence of t in P **not preceded by c.
- **Step 1: Search for
tin the patternP. If the first occurrence oftis found at position4, but this occurrence is preceded by the mismatching characterc = "C", we skip it and continue searching. - **Step 2: At position
1, we find another occurrence oftinP. This occurrence is preceded by the characterA, which is **not equal toc. Therefore, we shift the pattern by **6 positions to align this occurrence with the matched substringtin the textT.
This method helps avoid unnecessary comparisons and ensures that the pattern shifts efficiently, reducing the time complexity of the pattern matching process.
Preprocessing for Good Suffix Heuristic
As part of the **preprocessing, an array shift is created. Each entry shift[i] stores the distance the pattern will shift when a mismatch occurs at position i-1. Essentially, shift[i] tells us how far we should shift the pattern when a mismatch happens after matching the suffix starting at position i in the pattern P.
**1) Preprocessing for Strong Good Suffix
Before we dive into the preprocessing steps, it’s important to understand the concept of **borders. A **border is a substring that is both a proper suffix and a proper prefix. For example, in the string "ccacc", "c" and "cc" are borders because they appear at both ends of the string, but "cca" is not a border.
During preprocessing, we calculate the array bpos (border positions). Each entry bpos[i] stores the starting index of the border for the suffix starting at position i in the given pattern P.
- The suffix starting at position
mhas no border, sobpos[m] = m + 1(wheremis the length of the pattern).
The **shift position is determined by these borders, and the pattern is shifted based on these positions. The following code shows the preprocessing algorithm for the Strong Good Suffix Heuristic:
C++ `
void preprocess_strong_suffix(int *shift, int *bpos, char *pat, int m) { int i = m, j = m + 1; bpos[i] = j; while (i > 0) { while (j <= m && pat[i - 1] != pat[j - 1]) { if (shift[j] == 0) shift[j] = j - i; j = bpos[j]; } i--; j--; bpos[i] = j; } }
`
Explanation of the Code
**Initialization:
i = mandj = m + 1set up the initial boundary for calculating the borders.bpos[i] = jinitializes thebposarray, marking the end of the pattern.
**Main Loop:
- The main loop starts from the end of the pattern (
i = m), and compares the character atpat[i-1]withpat[j-1]. - If the characters match, the loop proceeds with calculating the borders.
- If a mismatch is found, we adjust
jusingbpos[j]and try to find a new border.
**Shifting the Pattern:
- If
shift[j] == 0, we calculate the shift based on the current mismatch and store it inshift[j] = j - i.
**Example for bpos[i] = j :
Consider the pattern P = "ABBABAB" where m = 7. Here’s how the preprocessing works:
- The suffix
"AB"starting at positioni = 5has no border, sobpos[5] = 7. - The suffix
"BABAB"starting at positioni = 2has a border"BAB", sobpos[2] = 4.
This helps in determining where to shift the pattern when a mismatch occurs.
**2) Preprocessing for Case 2 (Widest Border of the Pattern)
In this preprocessing step, we determine the **widest border of the pattern that is contained in each suffix. The **widest border refers to the longest substring that serves as both a proper prefix and a proper suffix of the pattern.
bpos[0]stores the starting position of the widest border of the entire pattern.- This value is initially set in all free entries of the
shiftarray. If the suffix length becomes smaller thanbpos[0], the algorithm proceeds to the next-wider border.
This preprocessing ensures that when a mismatch occurs, the pattern is shifted optimally, either by aligning borders or skipping over parts of the text that are already matched.
Following is the implementation of the search algorithm -
C++ `
#include <stdio.h> #include <string.h>
// preprocessing for strong good suffix rule void preprocess_strong_suffix(int *shift, int *bpos, char *pat, int m) { // m is the length of pattern int i=m, j=m+1; bpos[i]=j;
while(i>0)
{
/*if character at position i-1 is not equivalent to
character at j-1, then continue searching to right
of the pattern for border */
while(j<=m && pat[i-1] != pat[j-1])
{
/* the character preceding the occurrence of t in
pattern P is different than the mismatching character in P,
we stop skipping the occurrences and shift the pattern
from i to j */
if (shift[j]==0)
shift[j] = j-i;
//Update the position of next border
j = bpos[j];
}
/* p[i-1] matched with p[j-1], border is found.
store the beginning position of border */
i--;j--;
bpos[i] = j;
}}
//Preprocessing for case 2 void preprocess_case2(int *shift, int *bpos, char pat, int m) { int i, j; j = bpos[0]; for(i=0; i<=m; i++) { / set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 */ if(shift[i]==0) shift[i] = j;
/* suffix becomes shorter than bpos[0], use the position of
next widest border as value of j */
if (i==j)
j = bpos[j];
}}
void search(char *text, char *pat) { // s is shift of the pattern with respect to text int s=0, j; int m = strlen(pat); int n = strlen(text);
int bpos[m+1], shift[m+1];
//initialize all occurrence of shift to 0
for(int i=0;i<m+1;i++) shift[i]=0;
//do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
while(s <= n-m)
{
j = m-1;
/* Keep reducing index j of pattern while characters of
pattern and text are matching at this shift s*/
while(j >= 0 && pat[j] == text[s+j])
j--;
/* If the pattern is present at the current shift, then index j
will become -1 after the above loop */
if (j<0)
{
printf("pattern occurs at shift = %d\n", s);
s += shift[0];
}
else
/*pat[i] != pat[s+j] so shift the pattern
shift[j+1] times */
s += shift[j+1];
}}
int main() { char text[] = "ABAAAABAACD"; char pat[] = "ABA"; search(text, pat); return 0; }
Java
class GFG {
// preprocessing for strong good suffix rule static void preprocess_strong_suffix(int []shift, int []bpos, char []pat, int m) { // m is the length of pattern int i = m, j = m + 1; bpos[i] = j;
while(i > 0)
{
/*if character at position i-1 is not
equivalent to character at j-1, then
continue searching to right of the
pattern for border */
while(j <= m && pat[i - 1] != pat[j - 1])
{
/* the character preceding the occurrence of t
in pattern P is different than the mismatching
character in P, we stop skipping the occurrences
and shift the pattern from i to j */
if (shift[j] == 0)
shift[j] = j - i;
//Update the position of next border
j = bpos[j];
}
/* p[i-1] matched with p[j-1], border is found.
store the beginning position of border */
i--; j--;
bpos[i] = j;
}}
static void preprocess_case2(int []shift, int []bpos, char []pat, int m) { int i, j; j = bpos[0]; for(i = 0; i <= m; i++) { /* set the border position of the first character of the pattern to all indices in array shift having shift[i] = 0 */ if(shift[i] == 0) shift[i] = j;
/* suffix becomes shorter than bpos[0],
use the position of next widest border
as value of j */
if (i == j)
j = bpos[j];
}}
/*Search for a pattern in given text using Boyer Moore algorithm with Good suffix rule */ static void search(char []text, char []pat) { // s is shift of the pattern // with respect to text int s = 0, j; int m = pat.length; int n = text.length;
int []bpos = new int[m + 1];
int []shift = new int[m + 1];
//initialize all occurrence of shift to 0
for(int i = 0; i < m + 1; i++)
shift[i] = 0;
//do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m);
preprocess_case2(shift, bpos, pat, m);
while(s <= n - m)
{
j = m - 1;
/* Keep reducing index j of pattern while
characters of pattern and text are matching
at this shift s*/
while(j >= 0 && pat[j] == text[s+j])
j--;
/* If the pattern is present at the current shift,
then index j will become -1 after the above loop */
if (j < 0)
{
System.out.printf("pattern occurs at shift = %d\n", s);
s += shift[0];
}
else
/*pat[i] != pat[s+j] so shift the pattern
shift[j+1] times */
s += shift[j + 1];
}}
public static void main(String[] args) { char []text = "ABAAAABAACD".toCharArray(); char []pat = "ABA".toCharArray(); search(text, pat); } }
// This code is contributed by 29AjayKumar
Python
preprocessing for strong good suffix rule
def preprocess_strong_suffix(shift, bpos, pat, m): # m is the length of pattern i = m j = m + 1 bpos[i] = j
while i > 0:
# if character at position i-1 is not equivalent to
# character at j-1, then continue searching to right
# of the pattern for border
while j <= m and pat[i - 1] != pat[j - 1]:
# the character preceding the occurrence of t in
# pattern P is different than the mismatching character in P,
# we stop skipping the occurrences and shift the pattern
# from i to j
if shift[j] == 0:
shift[j] = j - i
# Update the position of next border
j = bpos[j]
# p[i-1] matched with p[j-1], border is found.
# store the beginning position of border
i -= 1
j -= 1
bpos[i] = jPreprocessing for case 2
def preprocess_case2(shift, bpos, pat, m): j = bpos[0] for i in range(m + 1): # set the border position of the first character of the pattern # to all indices in array shift having shift[i] = 0 if shift[i] == 0: shift[i] = j
# suffix becomes shorter than bpos[0], use the position of
# next widest border as value of j
if i == j:
j = bpos[j]def search(text, pat): # s is shift of the pattern with respect to text s = 0 m = len(pat) n = len(text)
bpos = [0] * (m + 1)
shift = [0] * (m + 1)
# do preprocessing
preprocess_strong_suffix(shift, bpos, pat, m)
preprocess_case2(shift, bpos, pat, m)
while s <= n - m:
j = m - 1
# Keep reducing index j of pattern while characters of
# pattern and text are matching at this shift s
while j >= 0 and pat[j] == text[s + j]:
j -= 1
# If the pattern is present at the current shift, then index j
# will become -1 after the above loop
if j < 0:
print(f'pattern occurs at shift = {s}')
s += shift[0]
else:
# pat[i] != pat[s+j] so shift the pattern
# shift[j+1] times
s += shift[j + 1]if name == 'main': text = 'ABAAAABAACD' pat = 'ABA' search(text, pat)
` JavaScript ``
function preprocessStrongSuffix(shift, bpos, pat, m) { let i = m; let j = m + 1; bpos[i] = j;
while (i > 0) {
// If character at position i-1 is not equivalent to character at j-1,
// then continue searching to the right of the pattern for a border.
while (j <= m && pat[i - 1] !== pat[j - 1]) {
// The character preceding the occurrence of t in pattern P is different
// than the mismatching character in P, so stop skipping the occurrences
// and shift the pattern from i to j.
if (shift[j] === 0) {
shift[j] = j - i;
}
// Update the position of the next border.
j = bpos[j];
}
// pat[i-1] matched with pat[j-1], a border is found.
// Store the beginning position of the border.
i--;
j--;
bpos[i] = j;
}}
// Preprocessing for case 2 function preprocessCase2(shift, bpos, pat, m) { let j = bpos[0]; for (let i = 0; i <= m; i++) { // Set the border position of the first character of the pattern // to all indices in the shift array having shift[i] = 0. if (shift[i] === 0) { shift[i] = j; }
// If the suffix becomes shorter than bpos[0], use the position of
// the next widest border as the value of j.
if (i === j) {
j = bpos[j];
}
}}
// Search for a pattern in given text using Boyer-Moore algorithm with Good Suffix rule function search(text, pat) { let s = 0; let j; const m = pat.length; const n = text.length; const bpos = new Array(m + 1); const shift = new Array(m + 1).fill(0);
// Initialize all occurrences of shift to 0
for (let i = 0; i < m + 1; i++) {
shift[i] = 0;
}
// Perform preprocessing
preprocessStrongSuffix(shift, bpos, pat, m);
preprocessCase2(shift, bpos, pat, m);
while (s <= n - m) {
j = m - 1;
// Keep reducing index j of pattern while characters of
// pattern and text are matching at this shift s
while (j >= 0 && pat[j] === text[s + j]) {
j--;
}
// If the pattern is present at the current shift, then index j
// will become -1 after the above loop
if (j < 0) {
console.log(`Pattern occurs at shift = ${s}`);
s += shift[0];
} else {
// pat[i] != pat[s+j] so shift the pattern shift[j+1] times
s += shift[j + 1];
}
}}
function main() { const text = "ABAAAABAACD"; const pat = "ABA"; search(text, pat); }
main();
``
Output
pattern occurs at shift = 0 pattern occurs at shift = 5