Apriori Algorithm (original) (raw)
Last Updated : 13 May, 2026
Apriori Algorithm is a data mining technique used to identify items that frequently appear together in large datasets. It helps discover relationships and association rules between items, making it widely used in market basket analysis.
**For Example:
If customers often buy bread and butter together in a grocery store, the store can place these items nearby or create combo offers to improve sales and customer experience.
- Finds frequent item combinations in datasets
- Discovers association rules between items
- Widely used in market basket analysis
- Helps businesses improve recommendations and sales strategies
Working
**1. Identifying Frequent Item-Sets
- The Apriori algorithm starts by looking through all the data to count how many times each single item appears. These single items are called 1-Item-Sets.
- Next it uses a rule called minimum support this is a number that tells us how often an item or group of items needs to appear to be important. If an item appears often enough meaning its count is above this minimum support it is called a frequent Item-Set.
**2. Creating Possible Item Group
- After finding the single items that appear often enough (frequent 1-item groups) the algorithm combines them to create pairs of items (2-item groups). Then it checks which pairs are frequent by seeing if they appear enough times in the data.
- This process keeps going step by step making groups of 3 items, then 4 items and so on. The algorithm stops when it can’t find any bigger groups that happen often enough.
**3. Removing Infrequent Item Groups
- The Apriori algorithm uses a helpful rule to save time. This rule says, if a group of items does not appear often enough then any larger group that includes these items will also not appear often.
- Because of this, the algorithm does not check those larger groups. This way it avoids wasting time looking at groups that won’t be important making the whole process faster.
4. **Generating Association Rules
- The algorithm makes rules to show how items are related.
- It checks these rules using support, confidence and lift to find the strongest ones.
Key Metrics of Apriori Algorithm
1. Support
Support measures how frequently an item or item-set appears in the dataset relative to the total number of transactions.
Support(X) = \frac{\text{Number of transactions containing } X}{\text{Total number of transactions}}
- Indicates the overall occurrence of an item-set
- Higher support means the item-set appears more frequently
2. Confidence
Confidence measures the likelihood that item Y is purchased when item X is purchased.
Confidence(X \rightarrow Y) =\frac{Support(X \cup Y)}{Support(X)}
- Indicates the strength of association between items
- Shows how often items occur together
**3. Lift
Lift measures how much more likely two items are purchased together compared to random chance.
Lift(X \rightarrow Y) =\frac{Confidence(X \rightarrow Y)}{Support(Y)}
- Evaluates the strength of item relationships
- Lift greater than 1 indicates a positive association
Example
Let's understand the concept of apriori Algorithm with the help of an example. Consider the following dataset and we will find frequent Item-Sets and generate association rules for them:
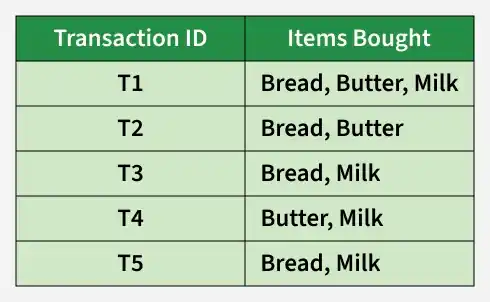
Transactions of a Grocery Shop
**Step 1 : Setting the parameters
**Minimum Support Threshold: 50% (item must appear in at least 3/5 transactions). This threshold is formulated from this formula:
\text{Support}(A) = \frac{\text{Number of transactions containing itemset } A}{\text{Total number of transactions}}
**Minimum Confidence Threshold: 70% ( You can change the value of parameters as per the use case and problem statement ). This threshold is formulated from this formula:
\text{Confidence}(X \rightarrow Y) = \frac{\text{Support}(X \cup Y)}{\text{Support}(X)}
**Step 2: Find Frequent 1-Item-Sets
Let's count how many transactions include each item in the dataset (calculating the frequency of each item).
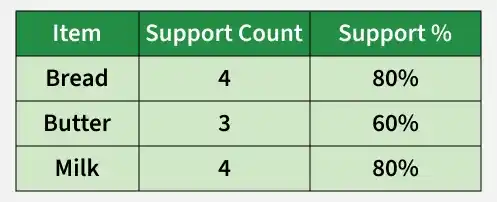
Frequent 1-Itemsets
All items have support ≥ 50%, so they qualify as frequent 1-Item-Sets. If any item has support < 50%, It will be omitted from the frequent 1- Item-Sets.
**Step 3: Generate Candidate 2-Item-Sets
Combine the frequent 1-Item-Sets into pairs and calculate their support. For this use case we will get 3 item pairs ( bread,butter) , (bread,milk) and (butter,milk). Their support values are calculated similarly to Step 2.
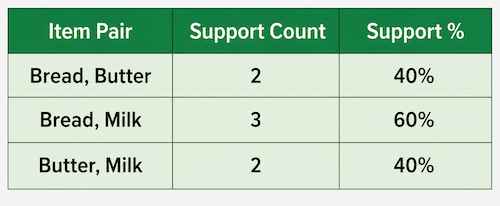
Candidate 2-Itemsets
**Frequent 2-Item-Sets: {Bread, Milk} meets the 50% minimum support threshold. However, {Bread, Butter} and {Butter, Milk} do not meet the threshold, so they are omitted.
**Step 4: Generate Candidate 3-Item-Sets
The Apriori Algorithm generates candidate 3-itemsets only from frequent 2-itemsets. Since only {Bread, Milk} satisfies the minimum support threshold in Step 3, there is no valid 3-itemset can be generated.
**Step 5: Generate Association Rules
Now we generate association rules from the frequent itemsets and calculate their confidence values.
Rule 1: If Bread implies Butter
If a customer buys Bread, they are likely to buy Butter as well.
- Support of {Bread, Butter} = 2.
- Support of {Bread} = 4.
- Confidence = 2/4 = 50% (Fails threshold)
Rule 2: Butter implies Bread
If a customer buys Butter, they are likely to buy Bread as well.
- Support of {Bread, Butter} = 2.
- Support of {Butter} = 3.
- Confidence = 2/3 = 66.67% (Fails threshold).
Rule 3: Bread implies Milk
If a customer buys Bread, they are likely to buy Milk as well.
- Support of {Bread, Milk} = 3.
- Support of {Bread} = 4.
- Confidence = 3/4 = 75% (Passes threshold).
The Apriori Algorithm, as demonstrated in the bread-butter example, is widely used in modern startups like Zomato, Swiggy and other food delivery platforms. These companies use it to perform market basket analysis which helps them identify customer behaviour patterns and optimise recommendations.
Applications
- Used in e-commerce to recommend products that are frequently bought together
- Helps food delivery platforms identify popular meal combinations and combo offers
- Enables streaming services to recommend related movies and shows
- Assists financial services in analyzing spending patterns and personalized offers
- Supports travel platforms in creating combined travel and hotel packages
- Used in health and fitness applications for personalized recommendations based on user behavior