Gaussian Distribution In Machine Learning (original) (raw)
Last Updated : 18 Feb, 2026
The Gaussian distribution, also called the normal distribution, is a continuous probability distribution used to represent how real-valued data is spread. It is widely used in machine learning and statistics to understand patterns in data. Its shape looks like a smooth bell curve.
- It is centered around the mean (average).
- Most values are close to the mean.
- Fewer values appear as we move away from the mean.
- The standard deviation shows how spread out the data is.
Gaussian Distribution Formula
The PDF (probability density function) of the Gaussian distribution is given by the formula:
f(x) = \frac{1}{\sigma \sqrt{2\pi}} \exp \left( -\frac{(x - \mu)^2}{2\sigma^2} \right)
**where:
- x represents the Variable
- μ represents the Mean
- σ represents the Standard Deviation
- e represents the base of the Natural Logarithm.
Gaussian Distribution Curve
The curve is symmetric and bell-shaped and it mathematically represents the probability distribution of a continuous random variable. The Gaussian distribution is characterized by two parameters: the mean (μ) and the standard deviation (σ), which determine the location and the spread of the curve.

- The standard deviations are used to subdivide the area under the normal curve. Each subdivided section defines the percentage of data, which falls into the specific region of a graph.
- Analysis : A smaller standard deviation results in a narrower and taller bell curve, indicating that data points are clustered closely around the mean. Conversely, a larger standard deviation leads to a wider and shorter bell curve, suggesting that data points are more spread out from the mean.
- The Empirical Rule, also known as the 68-95-99.7 rule, quantifies the proportion of data falling within certain intervals around the mean in a normal distribution. It provides a quick way to estimate the spread of data without performing detailed calculations.
- Within one standard deviation of the mean (Mean ± 1 SD), approximately **68% of the data is expected to fall.
- Within two standard deviations of the mean (Mean ± 2 SD), approximately **95% of the data is expected to fall.
- Within three standard deviations of the mean (Mean ± 3 SD), approximately **99.7% of the data is expected to fall.
Gaussian Distribution Table
- A Gaussian distribution table, also known as a standard normal distribution table or z-table, is a tabulated form that provides values of the cumulative distribution function (CDF) for the standard normal distribution.
- The standard normal distribution has a mean(central value) of 0 and a standard deviation of 1.
- Normally, the table consists of two columns namely Z-value and their Cumulative probability. Z-value is the number of standard deviations away from the mean. It ranges from negative infinity to positive infinity.
- Cumulative probability represents the probability that a standard normal random variable is less than or equal to the corresponding z-value.
**Note:
- Columns = value of z ranging from -3.4 to 3.4, with increments of 0.1.
- Rows = percentile value ranging from 0.00 to 0.09, with increments of 0.01.
| Z- Value | 0.00 | 0.01 | 0.02 | 0.03 | 0.04 | 0.05 | 0.06 | 0.07 | 0.08 | 0.09 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.5000 | 0.5040 | 0.5080 | 0.5120 | 0.5160 | 0.5199 | 0.5239 | 0.5279 | 0.5319 | 0.5359 |
| 0.1 | 0.5398 | 0.5438 | 0.5478 | 0.5517 | 0.5557 | 0.5596 | 0.5636 | 0.5675 | 0.5714 | 0.5753 |
| 0.2 | 0.5793 | 0.5832 | 0.5871 | 0.5910 | 0.5948 | 0.5987 | 0.6026 | 0.6064 | 0.6103 | 0.6141 |
| 0.3 | 0.6179 | 0.6217 | 0.6255 | 0.6293 | 0.6331 | 0.6368 | 0.6406 | 0.6443 | 0.6480 | 0.6517 |
| 0.4 | 0.6554 | 0.6591 | 0.6628 | 0.6664 | 0.6700 | 0.6736 | 0.6772 | 0.6808 | 0.6844 | 0.6879 |
| 0.5 | 0.6915 | 0.6950 | 0.6985 | 0.7019 | 0.7054 | 0.7088 | 0.7123 | 0.7157 | 0.7190 | 0.7224 |
| 0.6 | 0.7257 | 0.7291 | 0.7324 | 0.7357 | 0.7389 | 0.7422 | 0.7454 | 0.7486 | 0.7517 | 0.7549 |
| 0.7 | 0.7580 | 0.7611 | 0.7642 | 0.7673 | 0.7704 | 0.7734 | 0.7764 | 0.7794 | 0.7823 | 0.7852 |
| 0.8 | 0.7881 | 0.7910 | 0.7939 | 0.7967 | 0.7995 | 0.8023 | 0.8051 | 0.8078 | 0.8106 | 0.8133 |
| 0.9 | 0.8159 | 0.8186 | 0.8212 | 0.8238 | 0.8264 | 0.8289 | 0.8315 | 0.8340 | 0.8365 | 0.8389 |
| 1.0 | 0.8413 | 0.8438 | 0.8461 | 0.8485 | 0.8508 | 0.8531 | 0.8554 | 0.8577 | 0.8599 | 0.8621 |
| 1.5 | 0.9332 | 0.9345 | 0.9357 | 0.9370 | 0.9382 | 0.9394 | 0.9406 | 0.9418 | 0.9429 | 0.9441 |
| 1.9 | 0.9713 | 0.9719 | 0.9726 | 0.9732 | 0.9738 | 0.9744 | 0.9750 | 0.9756 | 0.9761 | 0.9767 |
| 2.0 | 0.9772 | 0.9778 | 0.9783 | 0.9788 | 0.9793 | 0.9798 | 0.9803 | 0.9808 | 0.9812 | 0.9817 |
| 2.5 | 0.9938 | 0.9940 | 0.9941 | 0.9943 | 0.9945 | 0.9946 | 0.9948 | 0.9949 | 0.9951 | 0.9952 |
| 3.0 | 0.9987 | 0.9987 | 0.9988 | 0.9988 | 0.9989 | 0.9989 | 0.9990 | 0.9990 | 0.9991 | 0.9991 |
The Z score table is often used in statistical calculations and hypothesis testing to determine probabilities associated with specific z-values.
For example, z-value of 1.96 in the table then the cumulative probability to be approximately 0.975, we can infer that approximately 97.5% of the area under the standard normal curve lies to the left of z = 1.96.
Properties of Gaussian Distribution
Some important properties are:
- It is symmetric around the mean, with equal probability on both sides.
- The sum of many independent random variables tends to follow a Gaussian distribution (Central Limit Theorem).
- Mean and variance can be efficiently estimated using maximum likelihood estimation.
- Linear transformations (aX + b) of a Gaussian variable remain Gaussian.
- In multiple dimensions, it extends naturally to model relationships between variables.
Machine Learning Methods that uses Gaussian Distribution
- **Likelihood Modeling: Used in linear regression and Gaussian Mixture Models for parameter estimation.
- **Bayesian Inference: Commonly used as a prior distribution over model parameters.
- **Clustering: Gaussian Mixture Model (GMM) models complex data distributions.
- **Anomaly Detection: Identifies outliers based on probability under the Gaussian model.
- **Dimensionality Reduction: Principal Component Analysis (PCA) relies on variance structure in data.
- **Kernel Methods: Used in Support Vector Machine (SVM) and Gaussian Process (GP).
Implementation of Gaussian Distribution in Machine Learning
Consider the famous Iris dataset consists of 150 samples of iris flowers, each with four features: sepal length, sepal width, petal length and petal width. We can examine the distribution of one of these features, such as sepal length, using a histogram to see if it approximately follows a Gaussian distribution.
- **x = np.linspace(np.min(sepal_length), np.max(sepal_length), 100) : the np.linspace function is used to create an array of 100 evenly spaced numbers between the minimum and maximum values of the sepal length feature (sepal_length). This array is used to plot the Gaussian distribution curve. Python `
from sklearn.datasets import load_iris import matplotlib.pyplot as plt import numpy as np
Load the Iris dataset
iris = load_iris() sepal_length = iris.data[:, 0] # Extract sepal length (feature at index 0)
mu, std = np.mean(sepal_length), np.std(sepal_length) x = np.linspace(np.min(sepal_length), np.max(sepal_length), 100) y = (1 / (std * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / std)**2)
plt.figure(figsize=(8, 6)) plt.hist(sepal_length, bins=20, color='skyblue', edgecolor='black', alpha=0.7, density=True) plt.plot(x, y, color='red', label='Gaussian Fit') plt.xlabel('Sepal Length (cm)') plt.ylabel('Density') plt.title('Distribution of Sepal Length in Iris Dataset with Gaussian Fit') plt.legend() plt.show()
`
**Output:
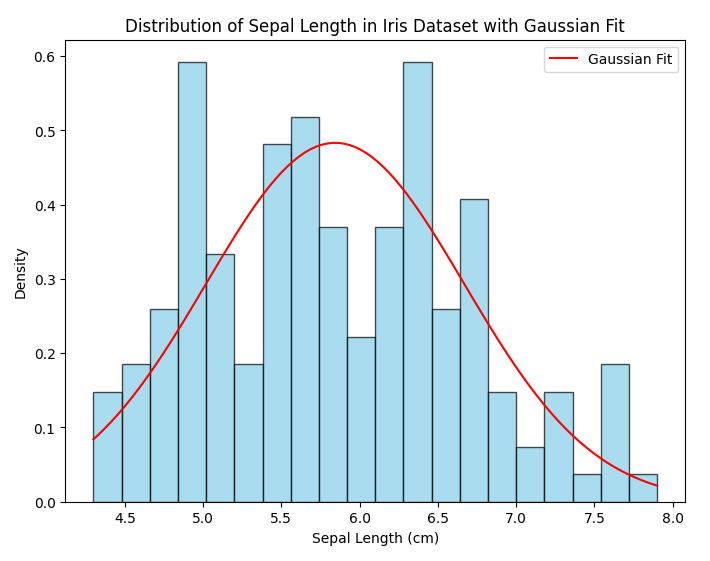
FIGURE 1
- **Central Tendency: The peak of the distribution (mean) suggests that the most common sepal length among the iris flowers in the dataset is around 5.8 centimeters.
- **Variability: The spread of the distribution (standard deviation) indicates how much the sepal lengths vary from the mean. A larger standard deviation would imply more variability in sepal lengths among the iris flowers.
- **Normality: The distribution roughly follows a bell-shaped curve, which is characteristic of a normal (Gaussian) distribution. This suggests that sepal lengths in the Iris dataset may be normally distributed.
- **Outliers: The presence of outliers, particularly on the right tail of the distribution, indicates that there are some iris flowers with unusually long sepal lengths compared to the rest of the dataset. These outliers could be due to measurement errors or represent a distinct subgroup of iris flowers.
The stability of Gaussian distributions under linear combinations facilitates analytical solutions for understanding the behavior of random variables and making predictions based on data making it a cornerstone in statistical modeling and analysis.