Inventory Demand Forecasting using Machine Learning Python (original) (raw)
Last Updated : 23 Jul, 2025
Vendors selling everyday items need to keep their stock updated so that customers don’t leave empty-handed. Maintaining the right stock levels helps avoid shortages that disappoint customers and prevents overstocking which can increase costs.
In this article we’ll learn how to use Machine Learning (ML) to predict stock needs for different products across multiple stores in a simple way.
**Step 1: Importing Libraries and Dataset
We begin by importing the necessary Python libraries for data handling, preprocessing, visualization and model building: Pandas, Numpy, Matplotlib, Seaborn, and Sklearn.
Python `
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sb from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder, StandardScaler from sklearn import metrics from sklearn.svm import SVC from xgboost import XGBRegressor from sklearn.linear_model import LinearRegression, Lasso, Ridge from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_absolute_error as mae
import warnings warnings.filterwarnings('ignore')
`
**Step 2: Load and Explore the Dataset
Load the dataset into a pandas DataFrame and examine its structure. The dataset contains sales data for 10 stores and 50 products over five years. To download the dataset: **click here.
Python `
df = pd.read_csv('StoreDemand.csv') display(df.head()) display(df.tail())
`
**Output:

First five rows of the dataset.
Python `
df.shape
`
**Output:
(913000, 4)
Let's check which column of the dataset contains which type of data using **info() function.
Python `
df.info()
`
**Output:

Information regarding data in the columns
As per the above information regarding the data in each column we can observe that there are no null values.
Python `
df.describe()
`
**Output:
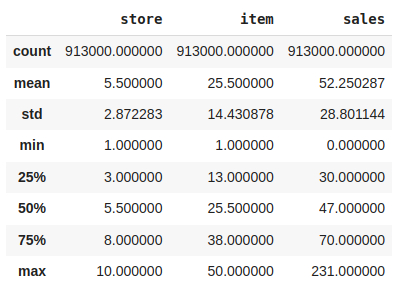
Descriptive statistical measures of the dataset
**Step 3: Feature Engineering
There are times when multiple features are provided in the same feature or we have to derive some features from the existing ones. We will also try to include some extra features in our dataset so, that we can derive some interesting insights from the data we have.
Also if the features derived are meaningful then they become a deciding factor in increasing the model's accuracy significantly.
Python `
parts = df["date"].str.split("-", n = 3, expand = True) df["year"]= parts[0].astype('int') df["month"]= parts[1].astype('int') df["day"]= parts[2].astype('int') df.head()
`
**Output:

Addition of day, month, and year feature
Whether it is a weekend or a weekday must have some effect on the requirements to fulfill the demands.
Python `
from datetime import datetime
def weekend_or_weekday(year, month, day): d = datetime(year, month, day) return 1 if d.weekday() > 4 else 0
df['weekend'] = df.apply(lambda x: weekend_or_weekday(x['year'], x['month'], x['day']), axis=1)
`
**Output:
Addition of a weekend feature
It would be nice to have a column which can indicate whether there was any holiday on a particular day or not.
Python `
from datetime import date import holidays
india_holidays = holidays.country_holidays('IN') df['holidays'] = df['date'].apply(lambda x: 1 if india_holidays.get(x) else 0)
`
**Output:
Addition of a holiday feature
Now, let's add some cyclical features.
Python `
df['m1'] = np.sin(df['month'] * (2 * np.pi / 12)) df['m2'] = np.cos(df['month'] * (2 * np.pi / 12)) df.head()
`
**Output:
Addition of Cyclical Features
Let's have a column whose value indicates which day of the week it is.
Python `
def which_day(year, month, day): return datetime(year, month, day).weekday()
df['weekday'] = df.apply(lambda x: which_day(x['year'], x['month'], x['day']), axis=1)
`
**Output:
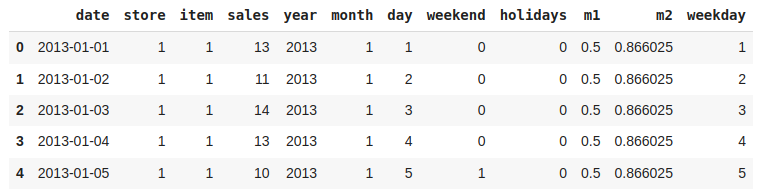
Addition of weekday Features
Now let's remove the columns which are not useful for us.
Python `
df.drop('date', axis=1, inplace=True)
`
There may be some other relevant features as well which can be added to this dataset but let's try to build a build with these ones and try to extract some insights as well.
**Step 4: Exploratory Data Analysis
EDA analyzes the data using visual techniques. It is used to discover trends, and patterns or to check assumptions with the help of statistical summaries and graphical representations. We have added some features to our dataset using some assumptions.
Now let's check the unique values in the store and item column using **nunique().
Python `
df['store'].nunique(), df['item'].nunique()
`
**Output:
(10, 50)
From here we can conclude that there are 10 unique stores and they sell 50 different products.
Now, let's analyze the relationship between various features and sales performance by visualizing.
- plt.subplots() is used to creates a figure to accommodate multiple subplots
- df.groupby(col).mean()['sales'].plot.bar() groups the data by current column and calculate the mean sales of each group and plot a bar chart to show the averages for each category of features. Python `
df['weekend'] = df['weekday'].apply(lambda x: 1 if x >= 5 else 0) features = ['store', 'year', 'month', 'weekday', 'weekend', 'holidays']
plt.subplots(figsize=(20, 10)) for i, col in enumerate(features): plt.subplot(2, 3, i + 1) df.groupby(col).mean()['sales'].plot.bar() plt.show()
`
**Output:

Bar plot for the average count of the ride request
Now let's check the variation of stock as the month closes to the end using line plot.
Python `
plt.figure(figsize=(10,5)) df.groupby('day').mean()['sales'].plot() plt.show()
`
**Output:

Line plot for the average count of stock required on the respective days of the month
Let's draw the simple moving average for 30 days period. Plotting simple moving average with help to smooth out short-term fluctuations and highlight longer-term trend or cycles in the data.
Python `
plt.figure(figsize=(15, 10))
Calculating Simple Moving Average
for a window period of 30 days
window_size = 30 data = df[df['year']==2013] windows = data['sales'].rolling(window_size) sma = windows.mean() sma = sma[window_size - 1:]
data['sales'].plot() sma.plot() plt.legend() plt.show()
`
**Output:
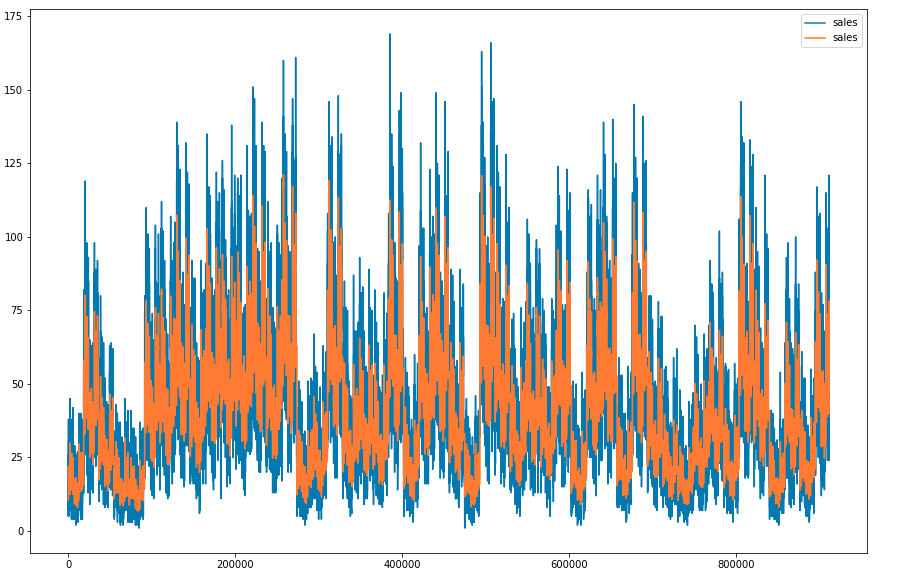
As the data in the sales column is continuous let's check the distribution of it and check whether there are some outliers in this column or not. For this we are using distplot and boxplot.
Python `
plt.subplots(figsize=(12, 5)) plt.subplot(1, 2, 1) sb.distplot(df['sales'])
plt.subplot(1, 2, 2) sb.boxplot(df['sales']) plt.show()
`
**Output:

Distribution plot and Box plot for the target column
We can observe that the distribution is right skewed and the dataset contains outliers.
Now, let's check the correlation between the features of the data and added a filter to identify only the highly correlated features. For computing the correlation between the features of the dataset, we use corr() function.
Python `
plt.figure(figsize=(10, 10)) sb.heatmap(df.corr() > 0.8, annot=True, cbar=False) plt.show()
`
**Output:
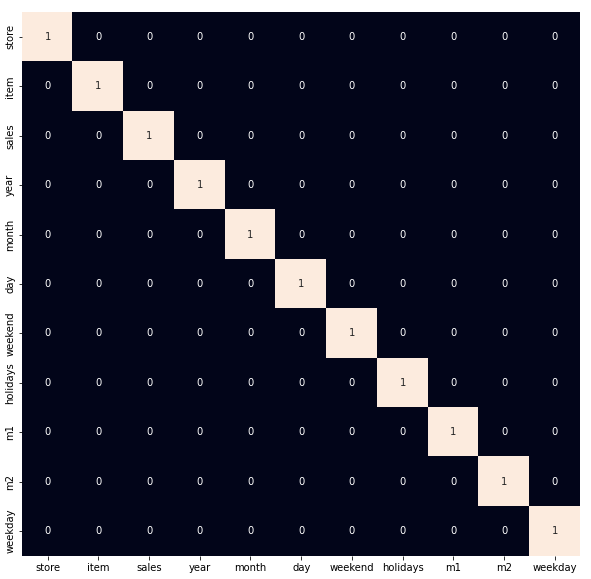
Heatmap to detect the highly correlated features
As we observed earlier let's remove the outliers which are present in the data.
Python `
df = df[df['sales']<140]
`
**Step 5: Model Training
Now, we will separate the features and target variables and split them into training and the testing data by using which we will select the model which is performing best on the validation data.
Python `
features = df.drop(['sales', 'year'], axis=1) target = df['sales'].values
X_train, X_val, Y_train, Y_val = train_test_split(features, target, test_size = 0.05, random_state=22) X_train.shape, X_val.shape
`
**Output:
((861170, 9), (45325, 9))
Normalizing the data before feeding it into machine learning models helps us to achieve stable and fast training.
Python `
Normalizing the features for stable and fast training.
scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_val = scaler.transform(X_val)
`
We have split our data into training and validation data also the normalization of the data has been done. Now let's train machine learning models and select the best out of them using the validation dataset.
For this implementation, we have used Linear Regression, XGBoost, Lasso Regression and Ridge Regression.
Python `
models = [LinearRegression(), XGBRegressor(), Lasso(), Ridge()]
for i in range(4): models[i].fit(X_train, Y_train)
print(f'{models[i]} : ')
train_preds = models[i].predict(X_train)
print('Training Error : ', mae(Y_train, train_preds))
val_preds = models[i].predict(X_val)
print('Validation Error : ', mae(Y_val, val_preds))
print()`
**Output:
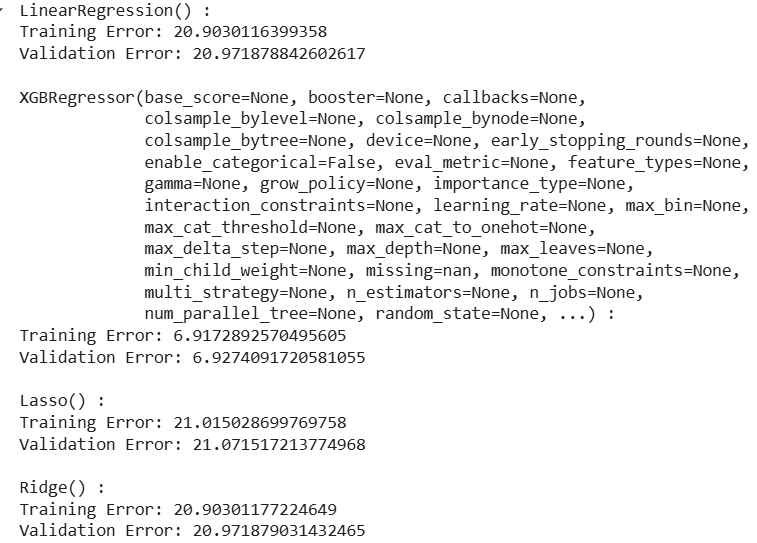
After training and evaluating the models, we observe that **XGBoost performs the best with the lowest validation error. This demonstrates the power of ensemble methods in capturing complex patterns in sales data.
**Get the complete notebook link here: **Inventory Demand Forecasting