Knowledge Distillation (original) (raw)
Last Updated : 23 Jul, 2025
Knowledge Distillation is a model compression technique in which a smaller, simpler model (student) is trained to imitate the behavior of a larger, complex model (teacher). Instead of learning directly from data, the student model learns from the soft targets or probabilities, which are produced by the teacher model. This technique helps in deploying deep models on edge devices like mobiles or IOT. Let's explore more about Knowledge Distillation and its Working.
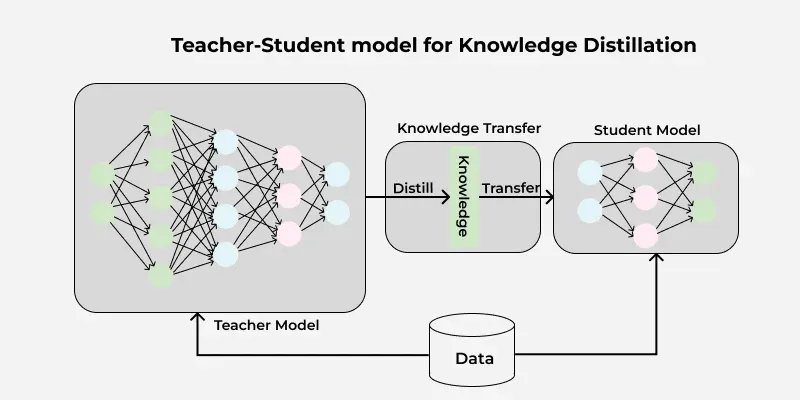
An Illustrative model for Knowledge Distillation
**Key Features of Knowledge Distillation
- **Model Compression: Reduces model size without much loss in accuracy.
- **Performance Retention: Maintains the accuracy of large models.
- **Faster Inference: Compressing a large BERT model into a smaller one like DistilBERT for fast inference in NLP tasks. Student model is lightweight and runs faster.
- **Soft Target Learning: Uses logits or softmax outputs instead of hard labels.
- **Teacher-Student Framework: Knowledge is transferred from teacher to student.
- **Regularization Effect: Reduces overfitting in student models.
**Types of Knowledge Distillation
The image above displays the representation of various Types of Knowledge Representation. These types are Response-based, Feature-based, and Relation-based Knowledge Representation.
1. **Response-based Distillation
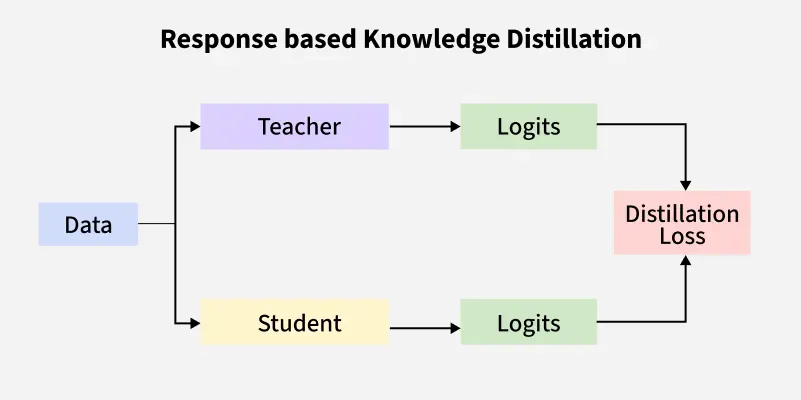
Response-based Distillation
This is the most classic and widely used form of knowledge distillation. It transfers the softened output probabilities (logits) from the teacher model to the student. These outputs provide richer information than hard labels because they reflect class similarities learned by the teacher.
- Relies on softmax outputs with a temperature parameter.
- Uses KL divergence loss to align student predictions with teacher.
- Does not require access to internal layers of the teacher.
- Simple and easy to implement.
- Highly effective in classification tasks.
2. Feature-based Distillation
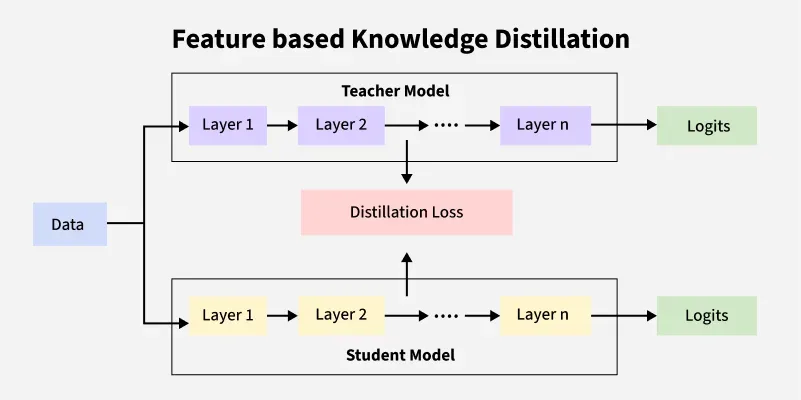
Feature-based Distillation
Instead of using final outputs, this method transfers intermediate representations or feature maps from the teacher to the student. The idea is to guide the student to learn similar internal feature structures.
- Matches hidden layer activations between teacher and student.
- Can use L2 loss or attention maps for alignment.
- Useful in vision and NLP models (e.g., CNNs, Transformers).
- Allows deeper guidance than response-based KD.
- Requires access to teacher’s internal layers.
3. Relation-based Distillation
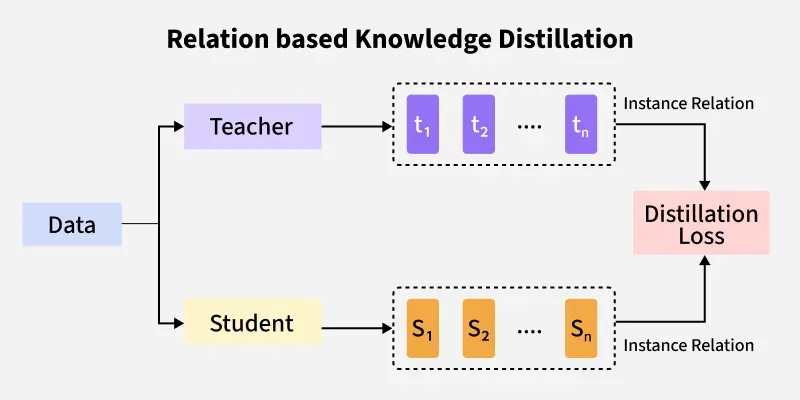
Relation-based Distillation
This technique focuses on the relationships between different input samples, such as pairwise distances or similarities. The goal is to maintain the relative structure of the learned space.
- Transfers relationships between instances, like distances or similarities between samples.
- Captures teacher’s understanding of sample distribution.
- Helps in tasks like metric learning and representation learning.
- Independent of specific output predictions.
- Requires calculating inter-sample statistics.
Working of Knowledge Distillation
Input Data --> Teacher (Large model) --> (Soft Targets / Logits) --> Student (Small model) --> Combined Loss (Distillation + True Label)
Terminologies
- **Teacher Model: A large, powerful, pre-trained model which has high accuracy but is computationally expensive. Example: ResNet152, BERT-large, GPT-3.
- **Student Model: A smaller, lightweight model designed to mimic the teacher. It is aimed to be cheaper to train, faster at inference, and deployable on edge devices. Example: MobileNet, TinyBERT, shallow CNN.
- **Distillation Loss: A custom loss function that compares student outputs with teacher outputs. It combines Soft Target Loss and Hard Target Loss (True class labels from the dataset).
- **Soft Targets: The probability distribution produced by the teacher model after applying softmax with temperature.
- **Temperature (T): A scaling factor applied to logits before softmax. Higher
Tsmooths the output probabilities. - **Logits: The raw outputs (unnormalized scores) from the last layer before softmax. Used for both soft target comparison and visualization.
- **Compression Ratio: Ratio of teacher model size to student model size.
Steps to Implement Knowledge Distillation
Knowledge Distillation is a model compression technique where a smaller, simpler model (student) is trained to replicate the behavior of a larger, complex model (teacher).
- **Train the Teacher Model on the dataset: A large model (like BERT, ResNet) or Teacher is trained on the dataset.
- **Generate Soft Targets: Pass training data through the teacher to get softmax outputs (logits/soft targets).
- **Train the Student Model: The student learns from a combination of:
- Soft targets from the teacher using Kullback-Leibler Divergence
- Hard targets (original labels) using Cross-Entropy loss
- **Use a Temperature Parameter
- Softmax outputs are softened using a temperature parameter (T>1) to emphasize the probabilities of incorrect classes that still carry meaningful knowledge
- Student may also mimic the intermediate representations or relationships between data samples from the teacher
**Formula: q_i = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}
Where,
- q_i : Softmax output or probability assigned to class i
- z_i : Logit (raw score before softmax) for class i
- T : Temperature parameter
- \sum_j \exp(z_j / T) : Normalization Term (Partition function)
**Note: We can Optimize the Combined Loss Function:
\text{Loss} = \alpha \cdot \text{CE}(y_{\text{true}}, y_{\text{student}}) + \beta \cdot \text{KL}(y_{\text{teacher}}, y_{\text{student}})
Where,
- CE({y_{true},y_{student}}) : Cross-Entropy Loss between the true labels, and the student model's predictions
- KL(y_{teacher}, y_{student}) : KL Divergence between the teacher's soft predictions and the student model's predictions
- α and β balance the loss terms
This process helps the student model generalize better despite having fewer parameters. It is widely used in deep learning for model compression, efficiency, and deployment on edge devices.
Different Training Strategies of Knowledge Distillation
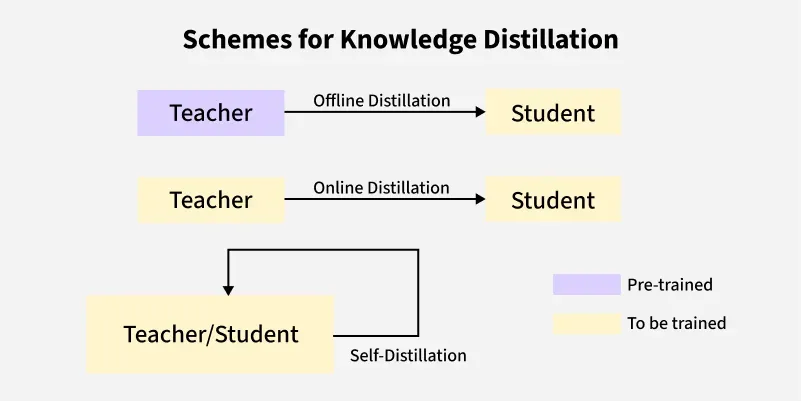
Different Training Strategies of Knowledge Distillation
**1. Offline Knowledge Distillation
- A pre-trained teacher model is first trained independently and then used to guide the student.
- The student is trained separately using the teacher’s soft outputs or features.
- Most common approach (e.g., Hinton's Vanilla KD).
**2. Online Knowledge Distillation
- The teacher and student are trained simultaneously in a multi-model setup.
- Often involves co-training multiple models that learn collaboratively (e.g., Peer Teaching, DML).
- No pre-trained teacher is needed.
**3. Self-Distillation
- The model learns from itself, either temporally (later epochs learn from earlier ones), Layer-wise (shallower layers guided by deeper ones), or by cloning the model and using an earlier checkpoint as the teacher.
- No separate teacher model is required.
**Applications of Knowledge Distillation
Knowledge Distillation is used in scenarios where high performance is needed in resource-constrained environments. Some of its applications are:
- **Mobile & Edge AI: Compress models for deployment on smartphones and IoT.
- **Faster transformer models: Some of these are DistilBERT and TinyBERT.
- **Computer Vision: Use in object detection, segmentation with smaller CNNs.
- **Speech Recognition: Speed up large acoustic models.
- **Compression: Combine multiple models into one student.
- **Robotics: Embed efficient models for fast decision-making.
- **Medical Imaging: Deploy high-accuracy models under hardware constraints.
**Advantages
- Speeds up inference time.
- Reduces model size significantly.
- Improves generalization by transferring "dark knowledge" (class relationships).
- Makes deployment on edge devices feasible.
- Multiple Teacher models can be ensembled. Knowledge Distillation can be combined with pruning.
- Student models are easier to interpret. Learns richer knowledge (e.g., class similarities).
**Disadvantages
- Requires a well-trained teacher model.
- Soft labels may not always provide useful guidance.
- Choosing temperature and loss weights is confusing.
- Doesn’t guarantee performance retention.
- Complex setup for feature or relation-based distillation.