Mask RCNN (original) (raw)
Mask R-CNN
Last Updated : 20 May, 2026
Mask R-CNN is an advanced computer vision model used for object detection and instance segmentation. It extends Faster R-CNN by adding a mask prediction branch that generates pixel-level segmentation masks for detected objects.
- Detects objects and predicts bounding boxes
- Generates segmentation masks for each object instance
- Uses a Fully Convolutional Network (FCN) for mask prediction
- Provides accurate pixel-level object segmentation
- Widely used in computer vision and image analysis applications
Instance Segmentation
Instance segmentation identifies and separates each individual object present in an image by assigning unique pixel-level masks to every object instance.
- Detects and segments each object separately
- Classifies individual pixels belonging to objects
- Generates segmentation masks for each object instance
- Provides detailed object boundaries and localisation
- Helps improve object understanding in images
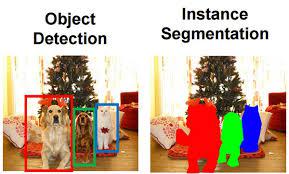
Instance Segmentation
Working of Mask R-CNN
Mask R-CNN extends the two-stage Faster R-CNN architecture by adding a separate mask prediction branch for instance segmentation. It detects objects, classifies them and generates pixel-level segmentation masks for each object instance.
- Uses a Region Proposal Network (RPN) to generate object proposals
- Performs object classification and bounding box prediction
- Adds a parallel mask branch for segmentation mask generation
- Uses RoI Align for accurate pixel-to-pixel feature alignment
- Produces class labels, bounding boxes and segmentation masks as output
Mask R-CNN Architecture
Mask R-CNN was proposed by Kaiming He et al. in 2017 as an extension of Faster R-CNN for instance segmentation. Along with object detection and bounding box prediction, it also generates a binary segmentation mask for each detected object.
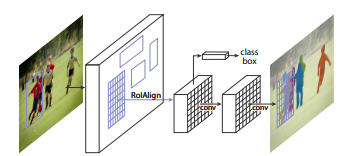
Mask R-CNN Architecture
Main components include:
- Backbone Network
- Region Proposal Network
- Mask Representation
- RoI Align
1. Backbone Network
The backbone network extracts feature maps from the input image using architectures like ResNet-C4 and ResNet-FPN.
- Uses deep CNNs for feature extraction
- Feature Pyramid Network (FPN) improves multi-scale object detection
- Uses 1×1 and 3×3 convolutions for efficient feature processing
- Generates feature maps such as P2, P3, P4, P5 and P6
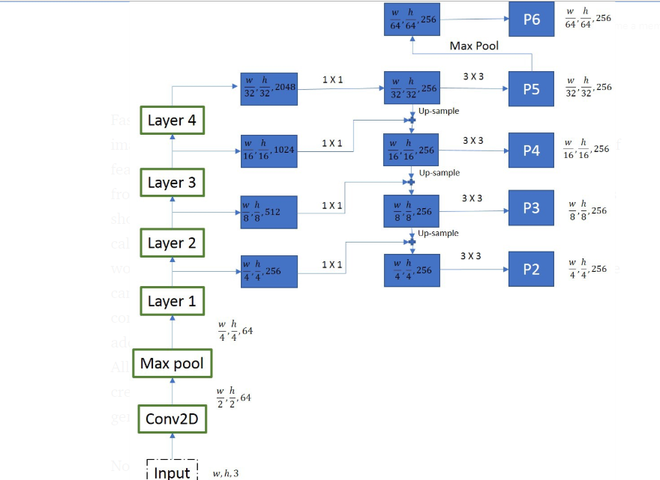
Mask R-CNN backbone architecture
2. Region Proposal Network
The RPN generates candidate object regions from convolutional feature maps.
- Uses 3×3 convolution layers for proposal generation
- Predicts objectness scores and bounding box coordinates
- Uses anchor boxes with different aspect ratios
- Helps identify potential object locations efficiently
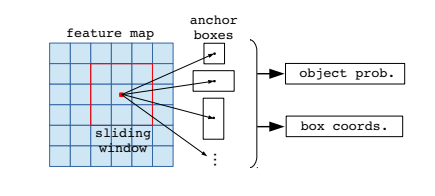
Anchor Generation Mask R-CNN
3. Mask Representation
The mask branch predicts segmentation masks for each Region of Interest (RoI).
- Uses a Fully Convolutional Network (FCN) for mask prediction
- Preserves pixel-level spatial information
- Generates an m×m segmentation mask for each class
- Uses RoI Align to create fixed-size feature maps for mask generation
4. RoI Align
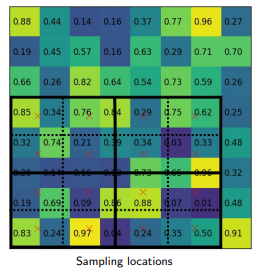
RoI align has the same motive as of RoI pool, to generate the fixed size regions of interest from region proposals. It works in the following steps:
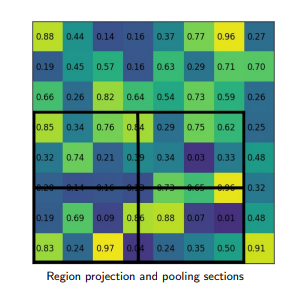
ROI Align
Given the feature map of the previous Convolution layer of size _h*w, divide this feature map into _M * N grids of equal size (we will NOT just take integer value).
The mask R-CNN inference speed is around _2 fps, which is good considering the addition of a segmentation branch in the architecture.
Applications
- Human pose estimation and body part detection
- Self-driving cars for object and lane detection
- Drone image mapping and aerial analysis
- Medical image segmentation and analysis
- Video surveillance and object tracking
- Image editing and augmented reality applications
Advantages
- Reduces computational cost compared to exhaustive search methods
- Flexible architecture that supports different backbone networks
- Achieves state-of-the-art performance in instance segmentation tasks
Limitations
- Requires high computing resources such as GPUs
- Needs detailed pixel-level annotated datasets for training
- Training and inference can be slower compared to simpler detection models
- Less suitable for real-time applications with strict latency requirements