ECLAT Algorithm ML (original) (raw)
Last Updated : 2 May, 2026
ECLAT stands for Equivalence Class Clustering and bottom-up Lattice Traversal. It is a data mining algorithm used to find frequent itemsets in a dataset. These frequent itemsets are then used to create association rules which helps to identify patterns in data. It is an improved alternative to the Apriori algorithm by providing better scalability and computational efficiency.
What Makes ECLAT Different from Apriori?
The main difference between the two lies in how they store and search through the data:
- Apriori uses a horizontal format where each transaction is a row and it follows a breadth-first search (BFS) strategy. This means it scans the database multiple times to find frequent item combinations.
- ECLAT on the other hand uses a vertical format where each item is linked to a list of transaction IDs (TIDs). It uses a depth-first search (DFS) strategy which requires fewer scans and makes it faster and more memory-efficient.
This vertical approach significantly reduces the number of database scans making ECLAT faster and more memory-efficient especially for large datasets.
| Aspect | Apriori | ECLAT |
|---|---|---|
| Data Format | Horizontal (transactions as rows) | Vertical (items linked to transaction IDs) |
| Search Strategy | Breadth-First Search (BFS) | Depth-First Search (DFS) |
| Database Scans | Multiple scans required | Fewer scans needed |
| Memory Efficiency | Less memory-efficient | More memory-efficient |
| Speed | Slower, especially with large datasets | Faster due to vertical representation |
Working
Let’s walk through an example to better understand how ECLAT algorithm works. Consider the following transaction dataset represented in a Boolean matrix:
| Transaction ID | Bread | Butter | Milk | Coke | Jam |
|---|---|---|---|---|---|
| T1 | 1 | 1 | 0 | 0 | 1 |
| T2 | 0 | 1 | 0 | 1 | 0 |
| T3 | 0 | 1 | 1 | 0 | 0 |
| T4 | 1 | 1 | 0 | 1 | 0 |
| T5 | 1 | 0 | 1 | 0 | 0 |
| T6 | 0 | 1 | 1 | 0 | 0 |
| T7 | 1 | 0 | 1 | 0 | 0 |
| T8 | 1 | 1 | 1 | 0 | 1 |
| T9 | 1 | 1 | 1 | 0 | 0 |
The core idea of the ECLAT algorithm is based on the interaction of datasets to calculate the support of itemsets, avoiding the generation of subsets that are not likely to exist in the dataset. Here’s a breakdown of the steps:
Step 1: Create the Tidset
The first step is to generate the tidset for each individual item. A tidset is simply a list of transaction IDs where the item appears. For example: k = 1, minimum support = 2
| Item | Tidset |
|---|---|
| Bread | {T1, T4, T5, T7, T8, T9} |
| Butter | {T1, T2, T3, T4, T6, T8, T9} |
| Milk | {T3, T5, T6, T7, T8, T9} |
| Coke | {T2, T4} |
| Jam | {T1, T8} |
Step 2: Calculate the Support of Itemsets by Intersecting Tidsets
ECLAT then proceeds by recursively combining the tidsets. The support of an itemset is determined by the intersection of tidsets. For example: k = 2
| Item | Tidset |
|---|---|
| {Bread, Butter} | {T1, T4, T8, T9} |
| {Bread, Milk} | {T5, T7, T8, T9} |
| {Bread, Coke} | {T4} |
| {Bread, Jam} | {T1, T8} |
| {Butter, Milk} | {T3, T6, T8, T9} |
| {Butter, Coke} | {T2, T4} |
| {Butter, Jam} | {T1, T8} |
| {Milk, Jam} | {T8} |
Step 3: Recursive Call and Generation of Larger Itemsets
The algorithm continues recursively by combining pairs of itemsets (k-itemsets) checking the support by intersecting the tidsets. The recursion continues until no further frequent itemsets can be generated. Now k = 3
| Item | Tidset |
|---|---|
| {Bread, Butter, Milk} | {T8, T9} |
| {Bread, Butter, Jam} | {T1, T8} |
Step 4: Stop When No More Frequent Itemsets Can Be Found
The algorithm stops once no more itemset combinations meet the minimum support threshold. k = 4
| Item | Tidset |
|---|---|
| {Bread, Butter, Milk, Jam} | {T8} |
We stop at k = 4 because there are no more item-tidset pairs to combine. Since minimum support = 2, we conclude the following rules from the given dataset:-
| Items Bought | Recommended Products |
|---|---|
| Bread | Butter |
| Bread | Milk |
| Bread | Jam |
| Butter | Milk |
| Butter | Coke |
| Butter | Jam |
| Bread and Butter | Milk |
| Bread and Butter | Jam |
Implementation
Let's see how ECLAT Algorithm works with the help of an example,
Step 1: Import Packages and Dataset
We will import necessary libraires and provide the dataset.
Python `
from collections import defaultdict from itertools import combinations transactions = { "T1": ["Bread", "Butter", "Jam"], "T2": ["Butter", "Coke"], "T3": ["Butter", "Milk"], "T4": ["Bread", "Butter", "Coke"], "T5": ["Bread", "Milk"], "T6": ["Butter", "Milk"], "T7": ["Bread", "Milk"], "T8": ["Bread", "Butter", "Milk", "Jam"], "T9": ["Bread", "Butter", "Milk"] } min_support = 2
`
Step 2: Generate Tidsets (Vertical representation)
- **Purpose: create a mapping item -> set_of_tids (the vertical format ECLAT uses).
- **Benefit: intersections of these tidsets are quick to compute and give support counts. Python `
def generate_tidsets(transactions): item_tidset = defaultdict(set) for tid, items in transactions.items(): for item in items: item_tidset[item].add(tid) return item_tidset
item_tidset = generate_tidsets(transactions)
for item, tidset in item_tidset.items(): print(item, ":", sorted(tidset))
`
**Output:
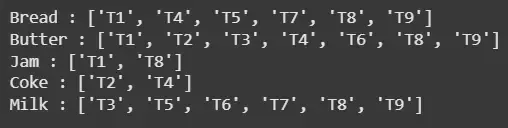
Tidsets
Step 3: Prepare a sorted list of items
- **Purpose: convert the item_tidset dict into a sorted list of (item, tidset) pairs.
- **Tip: sorting by tidset size (ascending) often helps pruning and makes intersections cheaper earlier. Python `
items = sorted(item_tidset.items(), key=lambda x: len(x[1]))
`
Step 4: Implement recursive ECLAT
Recursively build larger itemsets by intersecting tidsets (depth-first). How it works:
- Pop one (item, tidset) from the list.
- If len(tidset) >= min_support, record the itemset (prefix + item).
- Build a suffix by intersecting this tidset with each remaining item's tidset; keep intersections that meet min_support.
- Recurse on the suffix to extend the current itemset.
**Data structure: we use frequent_itemsets dict with frozenset(itemset) -> support_count.
Python `
def eclat(prefix, items, min_support, frequent_itemsets): """ prefix: list of items forming the current prefix items: list of tuples (item, tidset) to consider for extension min_support: absolute minimum support (count) frequent_itemsets: dict to collect results {frozenset(itemset): support_count} """ while items: item, tidset = items.pop() support = len(tidset) if support >= min_support: new_itemset = prefix + [item] frequent_itemsets[frozenset(new_itemset)] = support suffix = [] for other_item, other_tidset in items: intersection = tidset & other_tidset if len(intersection) >= min_support: suffix.append((other_item, intersection)) suffix = sorted(suffix, key=lambda x: len(x[1])) eclat(new_itemset, suffix, min_support, frequent_itemsets)
`
Step 5: Run ECLAT and collect frequent itemsets
Call the recursive function, then inspect the found frequent itemsets (with support counts).
Python `
item_tidset = generate_tidsets(transactions) items = sorted(item_tidset.items(), key=lambda x: len(x[1])) frequent_itemsets = {} eclat([], items, min_support, frequent_itemsets)
print("Frequent itemsets (as list) -> support count") for itemset, support in sorted(frequent_itemsets.items(), key=lambda x: (-len(x[0]), -x[1], sorted(list(x[0])))): print(list(itemset), "=>", support)
`
**Output:
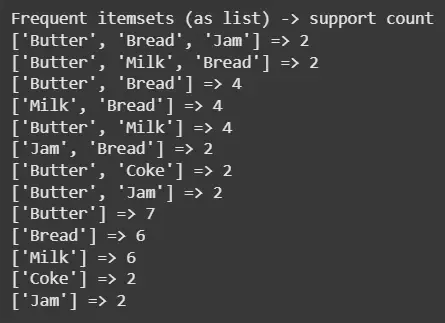
Result
Applications
- **Market Basket Analysis: Identifying frequently purchased items together.
- **Recommendation Systems: Suggesting products based on past purchase patterns.
- **Medical Diagnosis: Finding co-occurring symptoms in medical records.
- **Web Usage Mining: Analyzing web logs to understand user behavior.
- **Fraud Detection: Discovering frequent patterns in fraudulent activities.
Advantages
- **Efficient in Dense Datasets: Performs better than Apriori in datasets with frequent co-occurrences.
- **Memory Efficient: Uses vertical representation, reducing redundant scans.
- **Fast Itemset Intersection: Computing itemset support via TID-set intersections is faster than scanning transactions repeatedly.
- **Better Scalability: Can handle larger datasets due to its depth-first search mechanism.
Disadvantages
- **High Memory Requirement: Large TID sets can consume significant memory.
- **Not Suitable for Sparse Data: Works better in dense datasets, but performance drops for sparse datasets where intersections result in small itemsets.
- **Sensitive to Large Transactions: If a transaction has too many items its corresponding TID-set intersections can be expensive.