Data Normalization Machine Learning (original) (raw)
Last Updated : 12 Sep, 2025
Data normalization is a preprocessing method that resizes the range of feature values to a specific scale, usually between 0 and 1. It is a feature scaling technique used to transform data into a standard range. Normalization ensures that features with different scales or units contribute equally to the model and improves the performance of many machine learning algorithms.
Key Features of Normalization:
- Maps the minimum and maximum of a feature to a defined range
- Preserves the relative relationships of the original data
- Useful for algorithms that rely on distance metrics such as k-Nearest Neighbours and clustering
Why do we need Normalization?
Machine learning models often assume that all features contribute equally. Features with different scales can dominate the model’s behavior if not scaled properly. Using normalization, we can:
- **Ensure Equal Contribution of Features: Prevents features with larger scales from dominating models that are sensitive to magnitude such as K-Nearest Neighbours or neural networks.
- **Improve Model Performance: Algorithms that rely on distances or similarities (KNN, K-Means clustering) perform better when features are normalized.
- **Accelerate Convergence: Helps gradient-based algorithms like logistic regression or neural networks converge faster by keeping feature values in a similar range.
- **Maintain Interpretability of Scales: By converting all features to a common range, it’s easier to understand their relative impact on predictions.
Difference Between Normalization and Standardization
Standardization, also called Z-score normalization is a separate technique. It transforms data so that it has a mean of 0 and a standard deviation of 1.
Key Features of Standardization:
- Centers the data around zero
- Scales according to the variability (standard deviation)
- Useful for algorithms that assume Gaussian distributions such as linear regression,logistic regression and neural networks.
- Less sensitive to outliers compared to Min-Max normalization.
Standardization and Normalization are quite similar and confusing lets see the quick differences between them:
| Feature | Normalization (Min-Max) | Standardization (Z-score) |
|---|---|---|
| Goal | Rescale data to a specific range | Center data to mean 0, SD 1 |
| Range of values | Fixed (e.g., 0–1) | Not fixed |
| Effect of outliers | Sensitive | Less sensitive |
| Assumes data distribution | No | Assumes roughly Gaussian |
| Use case | Distance-based algorithms | Algorithms assuming Gaussian or regularization |
| Example | Scaling pixel values to [0,1] | Scaling test scores to z-scores |
**Note: Normalization and Standardization are two distinct feature scaling techniques.
Different Data Normalization Techniques
There are several techniques to normalize data, each transforming values to a common scale in different ways
1. Min-Max Normalization
Min-Max normalization rescales a feature to a specific range, typically [0, 1]:
X_{\text{normalized}} = \frac{X - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}}
- The minimum value maps to 0
- The maximum value maps to 1
- Other values are scaled proportionally
2. Decimal Scaling
Decimal scaling normalizes data by shifting the decimal point of values:
v' = \frac{v}{10^j}
- j is the smallest integer such that the maximum absolute value of v′ is less than 1
3. Logarithmic Transformation
Log transformation compresses large values and spreads out small values:
X' = \log(X + 1)
- Reduces skewness in data
- Stabilizes variance across features
4. Unit Vector (Vector) Normalization
Scales a data vector to have a magnitude of 1:
X' = \frac{X}{||X||}
- Commonly used in text mining and machine learning algorithms like KNN
- Preserves direction but normalizes magnitude
Implementation in Python
We will demonstrate how to normalize and standardize features in Python using scikit-learn library.
1. Import Required Libraries
We will import the necessary libraries like pandas and scikit-learn.
Python `
import pandas as pd from sklearn.preprocessing import MinMaxScaler, StandardScaler
`
2. Loading the Dataset
We will load the dataset and separate the features from the target variable.
You can download the dataset from here.
- **pd.read_csv('heart.csv'): Reads the CSV file into a DataFrame.
- **drop('target', axis=1): Removes the target column from feature set.
- **df['target']: Selects the target variable for prediction.
- **df.head(): Displays the first 5 rows of the dataset. Python `
df = pd.read_csv('/content/heart.csv') X = df.drop('target', axis=1) y = df['target'] df.head()
`
**Output:
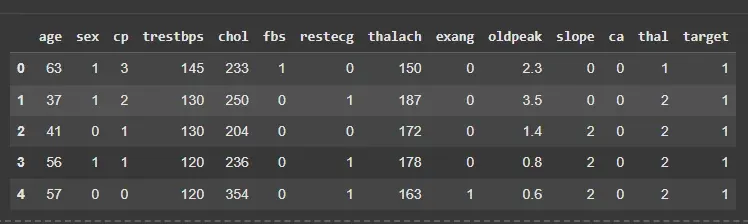
Dataset
3. Normalising the Features
We will normalize selected numeric features to scale them between 0 and 1.
- **MinMaxScaler(): Initializes a Min-Max scaler.
- **fit_transform(X[features]): Learns min and max values from data and scales features.
- **X.copy(): Creates a copy to avoid modifying the original dataset. Python `
features = ['age','trestbps','chol','thalach','oldpeak'] scaler = MinMaxScaler()
X_normalized = X.copy() X_normalized[features] = scaler.fit_transform(X[features]) X_normalized.head()
`
**Output:
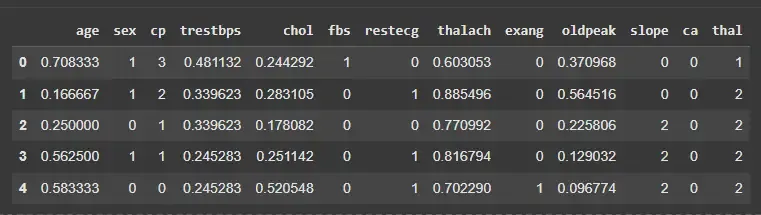
Normalization
4. Standardizing the Features
We will standardize the same features to have mean 0 and standard deviation 1.
- **StandardScaler(): Initializes a standard scaler.
- **fit_transform(X[features]): Computes mean and standard deviation, then standardizes the features.
**Note: Standardization is less sensitive to outliers compared to normalization.
Python `
scaler_z = StandardScaler() X_standardized = X.copy() X_standardized[features] = scaler_z.fit_transform(X[features]) X_standardized.head()
`
**Output:
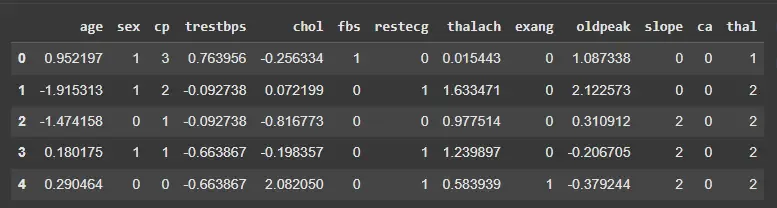
Standardization
Deciding Which Technique to Use
- Use normalization for distance-based models or when a specific range is required.
- Use standardization for algorithms that assume Gaussian distribution or are sensitive to variance.