What is LlamaIndex (original) (raw)
Last Updated : 31 Mar, 2026
LlamaIndex is an open-source framework that helps connect private and domain-specific data with large language models to build context-aware AI applications. It simplifies data ingestion, indexing and querying for better and more efficient outputs.
- Combines private and public data for richer context.
- Simplifies loading and processing of different data sources.
- Organizes data for efficient retrieval and search.
- Enables accurate and context-aware responses.
- Helps build practical AI applications using external data.
LlamaIndex Framework
Key Features of LlamaIndex
LlamaIndex provides features to connect, organize and retrieve data efficiently for building context aware AI applications.
**1. Data Ingestion: Supports loading data from APIs, PDFs, databases, spreadsheets and more. With LlamaHub, it offers ready made connectors for easy integration of structured and unstructured data.
**2. Indexing: Converts raw data into structured formats for fast and accurate retrieval, with different index types for different needs.
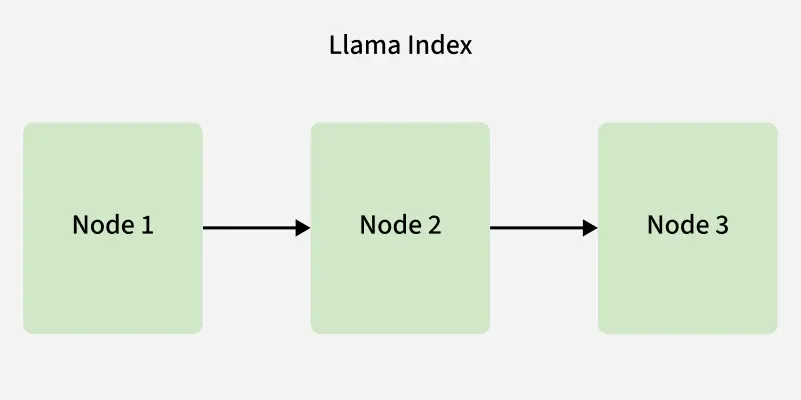
- **List Index: Organizes data sequentially, ideal for working with ordered or evolving datasets like logs or time series information. It enables straightforward querying where data order matters.
List Index
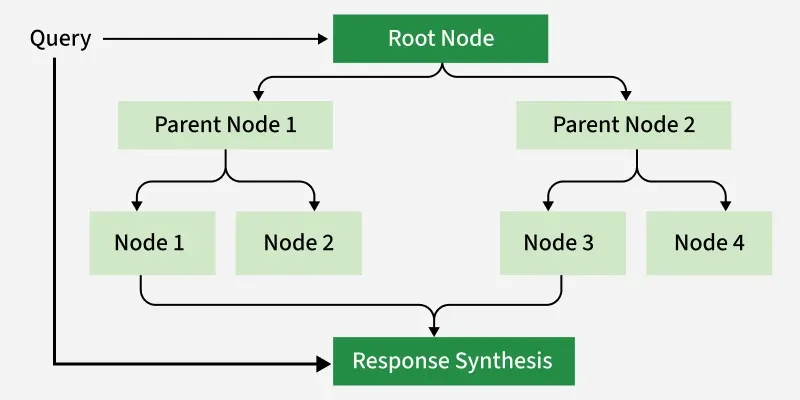
- **Tree Index: Structures data hierarchically using a binary tree format. This is well suited for complex, nested data or for applications that require traversing decision paths or hierarchical knowledge bases.
Tree Index
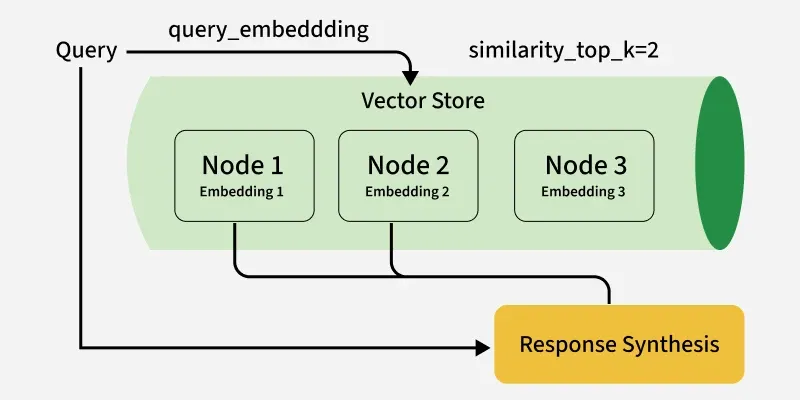
- **Vector Store Index: Converts documents into vector embeddings that capture their semantic meaning, enabling similarity search and helping the model retrieve contextually relevant information instead of relying on keyword matching.
Vector Store Index
- **Keyword Index: Maps metadata tags or keywords to specific data nodes, optimizing retrieval for keyword driven queries over large corpora. This supports effective filtering or selective data access based on key attributes.
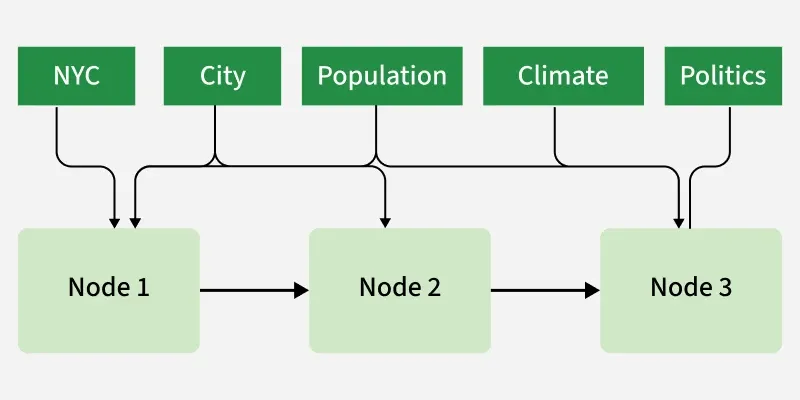
Keyword Index
- **Composite Index (Advanced usage): Combines multiple indexing strategies to balance query performance and precision, allowing hybrid searches that leverage both hierarchical and semantic features.
**3. Querying: LlamaIndex allows users to query data using natural language, where the system interprets the query and retrieves relevant information from indexed data, enabling easy and intuitive interaction with large datasets.
**4. Context Augmentation and Retrieval-Augmented Generation (RAG): LlamaIndex enhances responses by injecting relevant data into the model’s context, improving accuracy and making outputs more context aware using RAG techniques.
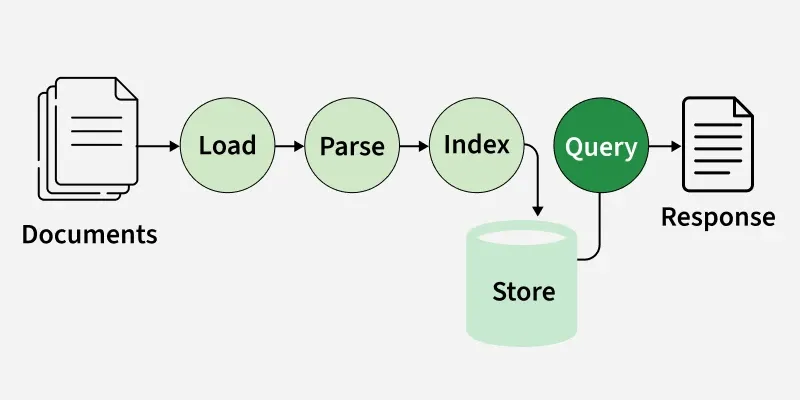
Working of LlamaIndex
Let's see how LlamaIndex works:
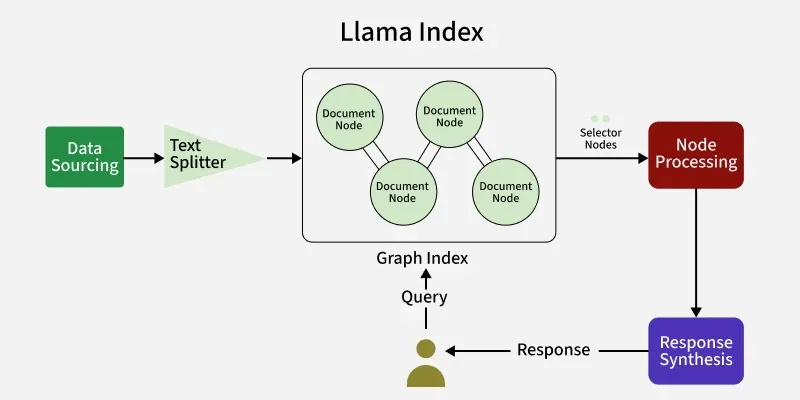
LlamaIndex Workflow
1. Data Ingestion
LlamaIndex can ingest data from multiple sources including local documents. This example uses SimpleDirectoryReader to load all files from a local directory (e.g., PDFs, text files) and prepares them for indexing.
**Implementation:
- Imports SimpleDirectoryReader which reads local files from the specified directory.
- The load_data() method reads and parses all documents in the folder into a list of document objects.
- The documents are now ready for indexing. Python `
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("documents").load_data() print(f"Loaded {len(documents)} documents.")
`
2. Setting Up the Language Model
LlamaIndex uses a language model (LLM) to process and query the indexed data. Here an OpenAI GPT-3.5-turbo model is configured with a controlled temperature for consistent results.
**Implementaion:
- Imports the OpenAI wrapper for LLMs in LlamaIndex.
- Creates an instance of GPT-3.5-turbo with zero temperature (deterministic output).
- Assigns this LLM instance to LlamaIndex's global Settings making it the default model used for querying. Python `
from llama_index.llms.openai import OpenAI from llama_index.core import Settings
llm = OpenAI(temperature=0, model="gpt-3.5-turbo") Settings.llm = llm
`
3. Data Indexing
The ingested documents are indexed using the VectorStoreIndex which converts the documents into vector embeddings for semantic search capabilities.
**Implementation:
- Imports the VectorStoreIndex.
- Uses the from_documents class method to create an embedding based index from the ingested documents.
- This index supports semantic similarity search, improving contextual retrieval beyond simple keyword matching. Python `
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
`
4. Querying
The index is converted to a query engine that accepts natural language queries and returns contextually relevant answers.
**Implementation:
- The as_query_engine() method transforms the index into an interactive query engine.
- The query() method takes a natural language question and processes it using the LLM and indexed data.
- The LLM returns a synthesized, context aware answer based on the documents. Python `
query_engine = index.as_query_engine()
response = query_engine.query("Summarize the key points from the documents.") print("Response from LlamaIndex:") print(response)
`
**Output:

Output
Data Agents
Data agents in LlamaIndex are AI powered systems that handle tasks like reading, writing, retrieving and processing data. They work with multiple data sources and perform tasks automatically.
- Automated search and retrieval across diverse data types including unstructured, semi structured and structured data
- Making API calls to external services with results that can be processed immediately, indexed for future use or cached
- Storing and managing conversation history to maintain contextual awareness
- Executing both simple and complex data oriented tasks autonomously
Agent Framework
AI agents interact with external systems using APIs and tools. LlamaIndex supports frameworks like OpenAI Function agents and ReAct agents, built on two core components.
1. Reasoning Loop
Agents follow a step by step reasoning process (ReAct) where they decide which tools to use, in what order and with what inputs to solve a task. This allows them to handle both simple and multi step problems effectively.
2. Tool Abstractions
These define how agents interact with different tools using a standard interface, making integration smooth and consistent.
- **FunctionTool: Wraps normal functions so agents can use them as tools during execution.
- **QueryEngineTool: Enables agents to search, retrieve and use information from data sources.
3. Tool Ecosystem
LlamaIndex connects with a wide range of tools through LlamaHub, including databases, Gmail, LLMs and utility tools, allowing agents to perform more powerful and diverse tasks.
LlamaIndex vs. LangChain
Let's see the differences between LlamaIndex and LangChain:
| Aspect | LlamaIndex | LangChain |
|---|---|---|
| Focus | Data ingestion, indexing and retrieval pipelines | Language model orchestration and generation |
| Indexing | Multiple optimized index types for diverse data | Emphasis on generative workflows rather than indexing |
| Querying | Semantic search and knowledge retrieval | Advanced LLM driven text generation and tasks |
| Learning Curve | More accessible for data integration tasks | Requires deeper understanding of LLM chaining |
Applications
- Conversational chatbots provide real time responses using company knowledge and data.
- Knowledge agents handle complex decisions and adapt to changing information.
- Semantic search engines find relevant results using natural language queries.
- Data augmentation improves AI by combining public models with private data.
Advantages
- Seamless data integration connects easily with APIs, databases, PDFs and documents.
- Powerful semantic search uses embeddings to find meaningful, context-aware results.
- Natural language querying allows users to interact with data through simple conversations.
- Flexible indexing supports multiple methods to optimize data retrieval for different use cases.
Limitations
Despite its robust capabilities, LlamaIndex faces several challenges:
- Handling large data volumes can be resource intensive during indexing and updates.
- Semantic search on large vector databases may cause delays in response time.
- Integration with different systems and data formats can require technical expertise.
- Scaling to handle many users and large datasets can be challenging.