Pairplot in Matplotlib (original) (raw)
Last Updated : 23 Jul, 2025
**Pair Plot is a type of chart that shows how different numbers in a dataset relate to each other. It creates multiple small scatter plots, comparing two variables at a time. While Seaborn has a ready-made pairplot() function to quickly create this chart, Matplotlib allows more control to customize how the plot looks and behaves. A Pair Plot (also called a scatterplot matrix) consists of:
- Scatter plots for each pair of numerical variables.
- Histograms (or kernel density plots) on the diagonal, representing the distribution of individual variables.
This visualization helps in identifying:
- Linear and non-linear relationships between features.
- Clusters or groups within data.
- Potential outliers.
Creating a pair plot using matplotlib
To get started, we first need to import the necessary libraries.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
- matplotlib.pyplot: Used for creating visualizations.
- pandas: Helps in handling structured data (dataframes).
- numpy: Useful for generating numerical data.
Implementation:
Python `
import matplotlib.pyplot as plt import pandas as pd import numpy as np
np.random.seed(42) data = pd.DataFrame({ 'Feature 1': np.random.rand(50), 'Feature 2': np.random.rand(50), 'Feature 3': np.random.rand(50), 'Feature 4': np.random.rand(50) })
Number of features
num_features = len(data.columns)
Create Subplots Grid
fig, axes = plt.subplots(num_features, num_features, figsize=(10, 10))
Loop through each pair of features
for i in range(num_features): for j in range(num_features): ax = axes[i, j]
if i == j:
# Diagonal: Histogram of the feature
ax.hist(data.iloc[:, i], bins=15, color='skyblue', edgecolor='black')
else:
# Scatter plot for feature pairs
ax.scatter(data.iloc[:, j], data.iloc[:, i], alpha=0.7, s=10, color="blue")
# Set labels on the left and bottom axes
if j == 0:
ax.set_ylabel(data.columns[i], fontsize=10)
if i == num_features - 1:
ax.set_xlabel(data.columns[j], fontsize=10)
# Remove ticks for a cleaner look
ax.set_xticks([])
ax.set_yticks([])Adjust layout
plt.tight_layout() plt.show()
`
**Output

**Explanation:
- **Data Generation: 4 features × 50 values (0-1) stored in a Pandas DataFrame ****(np.random.seed(42))**.
- **Subplots Grid: 4×4 layout (plt.subplots()), with histograms on the diagonal (i == j) and scatter plots elsewhere (i ≠ j).
- **Histograms: ax.hist() with 15 bins, skyblue fill, black edges for clarity.
- **Scatter Plots: ax.scatter() with alpha=0.7, s=10, blue color to show relationships.
- **Formatting: Labels only on leftmost column (j == 0) & bottom row (i == num_features - 1). Ticks removed for a clean look. plt.tight_layout() prevents overlap.
- **plt.show() renders the final visualization.
Advantages of pair plot in matplotlib
- **Customizability: Unlike Seaborn’s pairplot(), Matplotlib allows full control over plot styling.
- **Better Integration: Works seamlessly within larger Matplotlib-based visualizations.
- **Flexibility: Can modify elements like colors, markers, line styles, and annotations easily.
Enhancing the pair plot
To improve the visualization, consider:
- Adding regression lines to scatter plots.
- Using different colors to highlight categories in the dataset.
- Replacing histograms with kernel density estimation (KDE) plots.
**Example:
Python `
import matplotlib.pyplot as plt import numpy as np import pandas as pd
np.random.seed(42) data = pd.DataFrame(np.random.rand(50, 4), columns=['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4'])
Number of features
num_features = len(data.columns)
Create figure
fig, axes = plt.subplots(num_features, num_features, figsize=(10, 10))
Loop through each pair of features
for i in range(num_features): for j in range(num_features): ax = axes[i, j]
if i == j:
# Plot histogram on the diagonal
ax.hist(data.iloc[:, i], bins=10, color="skyblue", edgecolor="black")
else:
# Scatter plot
x = data.iloc[:, j]
y = data.iloc[:, i]
ax.scatter(x, y, alpha=0.7, s=10, color="blue")
# Add Regression Line
m, b = np.polyfit(x, y, 1) # Linear regression
ax.plot(x, m*x + b, color="red", linewidth=1)
# Labels
if j == 0:
ax.set_ylabel(data.columns[i], fontsize=10)
if i == num_features - 1:
ax.set_xlabel(data.columns[j], fontsize=10)
# Hide ticks for cleaner look
ax.set_xticks([])
ax.set_yticks([])Adjust layout
plt.tight_layout() plt.show()
`
**Output:
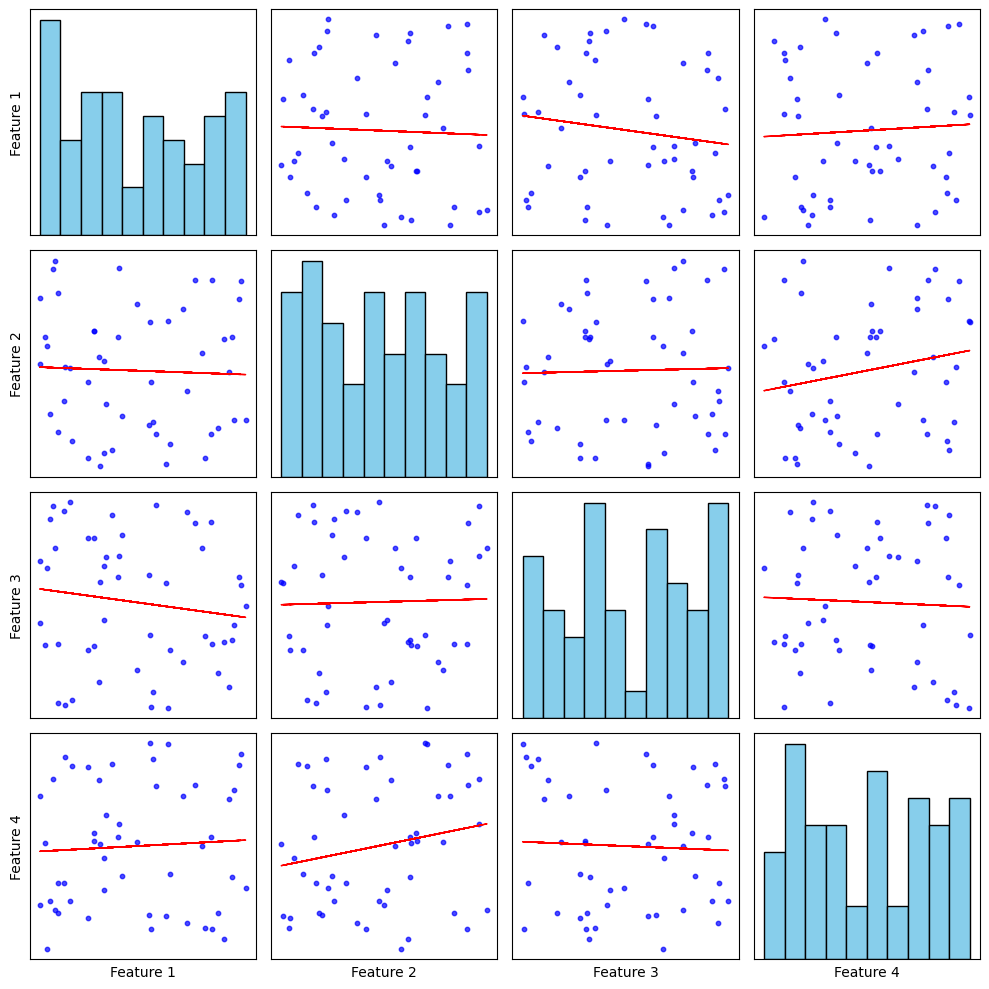
**Explanation:
- **Data Preparation: Random values are generated for four features using **NumPy and **Pandas DataFrame stores the dataset.
- **Creating Subplots: A 4×4 grid of subplots is created to display the pairwise relationships. plt.subplots(num_features, num_features, figsize=(10, 10)) sets up the grid layout.
- **Plotting the Pair Plot: If i == j, a histogram is plotted on the diagonal using ax.hist(). If i ≠ j, a scatter plot is created using ax.scatter().
- **Adding Regression Lines: The np.polyfit(x, y, 1) function computes the slope (m) and intercept (b) of the regression line. The **ax.plot(x, m*x + b, color="red", linewidth=1) function overlays a red regression line on the scatter plot.
- **Labels are added to only the leftmost and bottom plots. Ticks are hidden for a clean design.
- **plt.tight_layout() ensures proper spacing for readability.