Boosting in R (original) (raw)
Last Updated : 19 Feb, 2026
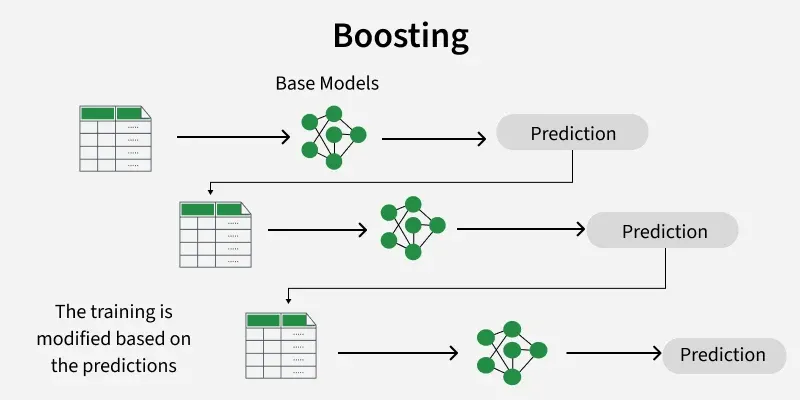
Boosting is an ensemble learning technique used to improve the accuracy of machine learning models. It combines multiple weak learners, usually small decision trees, to form a strong predictive model. In R, boosting algorithms are widely used for both regression and classification problems.
- Boosting trains models one after another.
- It gives more importance to misclassified or poorly predicted data points.
- Common boosting methods in R include GBM, AdaBoost and XGBoost.
Boosting
How Boosting Works
Boosting follows an iterative learning approach:
- Train a weak learner (usually a small decision tree).
- Calculate the errors made by the model.
- Train a new model to reduce those errors.
- Combine all models to produce the final prediction.
Unlike bagging methods such as Random Forest, boosting reduces bias by learning from previous mistakes.
Gradient Boosting Machine (GBM) in R
Gradient Boosting Machine (GBM) is one of the most widely used boosting algorithms. It minimizes a loss function using gradient descent and works effectively for regression and classification tasks.
GBM is implemented using the gbm package.
Example: GBM for Regression
We use the mtcars dataset and predict mpg.
- **n.trees: Number of trees (boosting iterations)
- **interaction.depth: Tree depth
- **shrinkage: Learning rate
- **n.minobsinnode: Minimum observations in terminal nodes
- **distribution: Type of problem ("gaussian" for regression) R `
install.packages("caTools") install.packages("gbm")
Split dataset
library(caTools) library(gbm) set.seed(123) split <- sample.split(mtcars$mpg, SplitRatio = 0.7) train <- mtcars[split, ] test <- mtcars[!split, ]
Train GBM model
library(gbm) boost <- gbm( mpg ~ ., data = train, distribution = "gaussian", n.trees = 500, interaction.depth = 3, shrinkage = 0.05, n.minobsinnode = 2 )
Predict
predictions <- predict(boost, newdata = test)
Evaluate
mse <- mean((test$mpg - predictions)^2) mse
`
**Output:
Using 500 trees...
2.35537023283051
AdaBoost in R
AdaBoost (Adaptive Boosting) is a boosting algorithm mainly used for classification problems. It works by increasing the weight of misclassified observations after each iteration. The next model focuses more on these difficult cases and all weak learners are combined to form a strong classifier.
AdaBoost can be implemented using the adabag package.
Example: AdaBoost on Iris Dataset
R `
Install and load package
install.packages("adabag") library(adabag)
Load dataset
data(iris)
iris$Species <- as.factor(iris$Species)
index <- sample(nrow(iris), nrow(iris) * 0.7) train <- iris[index, ] test <- iris[-index, ]
Train AdaBoost model
model <- boosting(Species ~ ., data = train, mfinal = 10)
Predict
predictions <- predict(model, newdata = test)
Evaluate
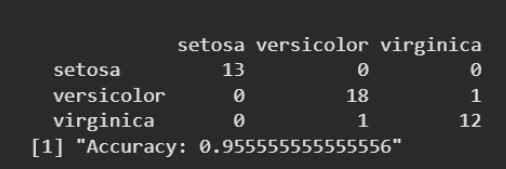
confusion_matrix <- table(predictions$class, test$Species) accuracy <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(confusion_matrix) print(paste0("Accuracy: ", accuracy))
`
**Output:
Output of AdaBoost
**Explanation:
- **mfinal: Number of boosting iterations
- **boos: Enables weighted boosting
- **control: Controls tree complexity
XGBoost in R
XGBoost (Extreme Gradient Boosting) is an advanced and optimized implementation of gradient boosting. It is faster, includes regularization to prevent overfitting and handles large datasets efficiently. XGBoost is widely used in real-world machine learning projects and competitions.
XGBoost is implemented using the
xgboostpackage.
Example: XGBoost for Binary Classification
We use the built-in mushroom dataset from the xgboost package.
R `
install.packages("xgboost") library(xgboost)
Load dataset
data(agaricus.train, package='xgboost') data(agaricus.test, package='xgboost')
Convert to DMatrix
dtrain <- xgb.DMatrix(agaricus.train$data, label = agaricus.train$label) dtest <- xgb.DMatrix(agaricus.test$data, label = agaricus.test$label)
Set parameters
params <- list(max_depth = 2, objective = "binary:logistic", eval_metric = "error")
Train model
xgb_model <- xgb.train(params = params, data = dtrain, nrounds = 25)
Predict
pred <- predict(xgb_model, dtest) head(pred)
`
**Output:
- 0.0108139282092452
- 0.953587055206299
- 0.0108139282092452
- 0.0108139282092452
- 0.0655693635344505
- 0.159496515989304
**Explanation:
- **max_depth: Depth of each tree
- **eta: Learning rate
- **nrounds: Number of boosting rounds
- **objective: Type of problem (regression or classification)
Advantages of Boosting
- High predictive accuracy
- Works well with structured/tabular data
- Handles non-linear relationships
- Robust to overfitting (with proper tuning)
Limitations of Boosting
- Computationally expensive
- Sensitive to noisy data
- Requires careful parameter tuning