CrossValidation in R programming (original) (raw)
Cross-Validation in R programming
Last Updated : 15 Jul, 2025
Cross-validation is an essential technique in machine learning used to assess the performance and accuracy of a model. The primary goal is to ensure that the model is not overfitting to the training data and that it will perform well on unseen, real-world data. Cross-validation involves partitioning the dataset into multiple subsets, training the model on some subsets and testing it on the remaining subsets.

Cross-Validation in R programming
Cross-validation helps to address two major concerns:
- **Overfitting: If a model performs well on the training data but poorly on new data, it might be overfitting. Cross-validation ensures that the model is tested on different subsets of data, reducing the risk of overfitting.
- **Underfitting: Cross-validation also helps in assessing if the model is too simple or not complex enough to capture patterns in the data.
Implementation of Cross-Validation in R
We will implement various methods like Validation Set Approach, Leave-One-Out Cross-Validation (LOOCV), K-Fold Cross-Validation and Repeated K-Fold Cross-Validation in R programming language.
Installing the Required Libraries and Loading the Dataset
To begin, we will install and load required packages and import the marketing dataset. We will be using the marketing dataset in R to demonstrate how cross-validation works.
- **tidyverse: Used for data manipulation and visualization.
- **caret: Provides tools for training models and cross-validation.
- **datarium : Used to import the marketing dataset. R `
install.packages("tidyverse") install.packages("caret") install.packages("datarium")
library(tidyverse) library(caret)
data("marketing", package = "datarium")
head(marketing)
`
**Output:
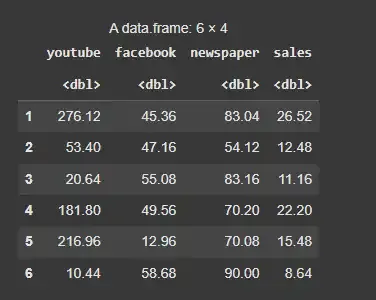
Marketing Dataset
1. Validation Set Approach
The Validation Set Approach, randomly split the dataset into training (80%) and testing (20%) sets. We then train a linear regression model using the training data. and evaluate it on the testing set using RMSE, MAE and R-Square metrics.
- **createDataPartition(): Randomly splits the data into training and testing sets.
- **lm(): Fits a linear regression model.
- **predict(): Makes predictions on the testing set.
- **R2(), RMSE(), MAE(): Evaluate model performance. R `
set.seed(123)
random_sample <- createDataPartition(marketing$sales, p = 0.8, list = FALSE) training_dataset <- marketing[random_sample, ] testing_dataset <- marketing[-random_sample, ]
model <- lm(sales ~ ., data = training_dataset)
predictions <- predict(model, testing_dataset)
df= data.frame( R2 = R2(predictions, testing_dataset$sales), RMSE = RMSE(predictions, testing_dataset$sales), MAE = MAE(predictions, testing_dataset$sales) )
df
`
**Output:
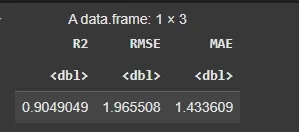
Validation Set Approach
2. Leave-One-Out Cross-Validation (LOOCV)
LOOCV splits the dataset into N-1 data points for training and 1 data point for testing. This is repeated for every data point and the average of the prediction errors is calculated.
- **trainControl(method = "LOOCV"): Defines the cross-validation method as LOOCV.
- **train(): Trains the model using LOOCV. R `
train_control <- trainControl(method = "LOOCV")
model <- train(sales ~ ., data = marketing, method = "lm", trControl = train_control) print(model)
`
**Output:
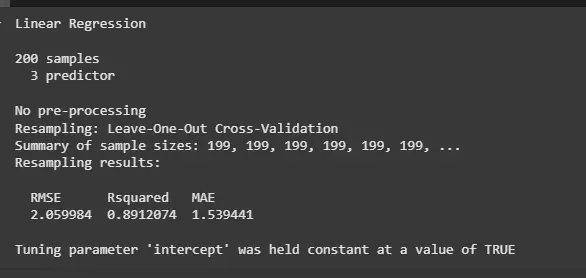
Leave-One-Out Cross-Validation (LOOCV)
3. K-Fold Cross-Validation
In K-fold cross-validation, we split the data into K subsets (folds). The model is trained on K-1 folds and tested on the remaining fold. This process is repeated K times. Then we calculate the average prediction error.
- **trainControl(method = "cv", number = 10): Defines K-fold cross-validation with K = 10.
- **train(): Trains the model using K-fold cross-validation. R `
train_control <- trainControl(method = "cv", number = 10)
model <- train(sales ~ ., data = marketing, method = "lm", trControl = train_control) print(model)
`
**Output:
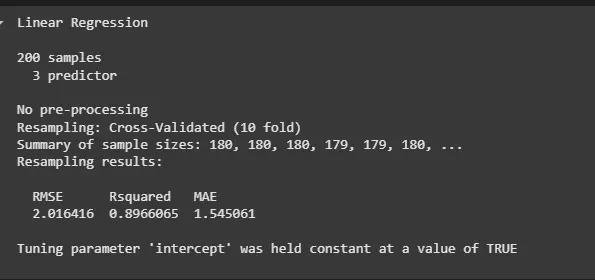
K-Fold Cross-Validation
4. Repeated K-Fold Cross-Validation
Repeated K-Fold Cross-Validation method repeats K-fold cross-validation multiple times. This helps to further reduce the variance of the performance metrics. We split the data into K subsets and then train the model on K-1 subsets and test it on the left-out fold. This process is repeated for a specified number of times.
- **trainControl(method = "repeatedcv", number = 10, repeats = 3): Defines repeated K-fold cross-validation with K = 10 and 3 repetitions.
- **train(): Trains the model using repeated K-fold cross-validation. R `
train_control <- trainControl(method = "repeatedcv", number = 10, repeats = 3)
model <- train(sales ~ ., data = marketing, method = "lm", trControl = train_control) print(model)
`
**Output:
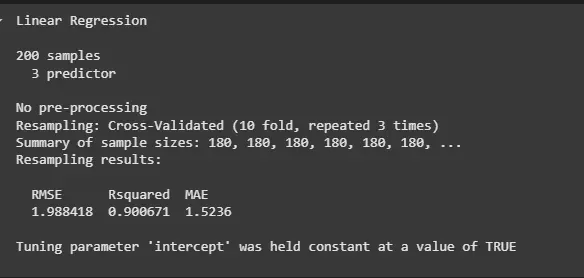
Repeated K-Fold Cross-Validation
In this article, we demonstrated different cross-validation techniques in R to evaluate the performance of a linear regression model. We covered the Validation Set Approach, LOOCV, K-Fold Cross-Validation and Repeated K-Fold Cross-Validation.