Random Sampling in R (original) (raw)
Last Updated : 24 Jul, 2025
Random sampling is a technique used in statistics to select a subset of individuals or items from a larger population, where each individual has an equal chance of being selected. The idea behind random sampling is to ensure that the sample accurately represents the entire population, minimizing biases that might otherwise distort the results of statistical analysis.
There are two primary types of random sampling:
- **Simple Random Sampling: Each element of the population has an equal probability of being selected.
- **Stratified Sampling: The population is divided into distinct subgroups and samples are randomly selected from each subgroup.
Random sampling is used in many fields, such as in predictive modeling, hypothesis testing and when building or validating machine learning models.
Implementation of Random Sampling in R
We will be implementing random sampling in R programming language using the dplyr Package. The dplyr package in R is useful for data manipulation since it provides several functions that simplify the process of selecting random samples from a data frame.
1. Installing and Loading the dplyr Package
We first need to install and load the package into our R environment.
R `
install.packages("dplyr") library(dplyr)
`
2. Random Sampling using the sample_n() Function
The sample_n() function is used when we need to select a fixed number of random rows from a data frame. This function is used in situations where we need a specific number of observations for training or testing machine learning models or when performing statistical tests on a subset of the data.
**Syntax:
sample_n(tbl, size, replace = FALSE, weight = NULL, .env = NULL, .funs = NULL)
**Parameters:
- **tbl: A data frame (or tibble) from which samples are drawn.
- **size: The number of random rows to select.
- **replace: A logical value indicating whether sampling should be done with replacement (TRUE) or without replacement (FALSE).
- **weight: An optional parameter for weighted sampling (if we want some elements to have a higher probability of being selected).
- ****.env and .funs:** Additional arguments for advanced sampling.
**Example:
We will use the iris dataset which is a built-in dataset in R and then select 10 random rows.
R `
library(dplyr)
random_sample <- sample_n(iris, 10) print(random_sample)
`
**Output:
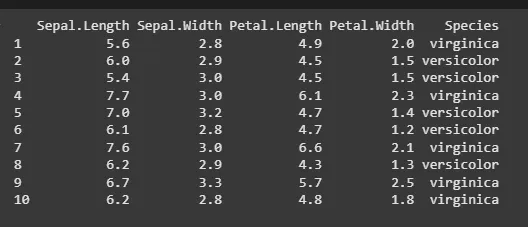
sample_n() Function
3. Random Sampling using the sample_frac() Function
The **sample_frac() function allows to select a random fraction of rows from a data frame. This is useful when we need a percentage-based random sample.
**Syntax:
sample_frac(tbl, size, replace = FALSE, weight = NULL, .env = NULL, .funs = NULL)
**Parameters:
- **tbl: A data frame (or tibble) from which samples are drawn.
- **size: The fraction (between 0 and 1) of rows to select.
- **replace: A logical value indicating whether sampling should be done with replacement (TRUE) or without replacement (FALSE).
- **weight: An optional parameter for weighted sampling.
**Example:
We will select 6.5% of the rows from the iris dataset.
R `
library(dplyr)
random_fraction <- sample_frac(iris, 0.065) print(random_fraction)
`
**Output:
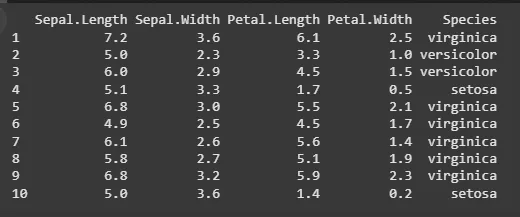
sample_frac() Function
Difference Between sample_n() and sample_frac() Functions
Both functions are used in R when working with large datasets, allowing us to extract smaller, randomized subsets for tasks like data exploration, model training and testing. Understanding the distinction between these two functions ensures that we can choose the appropriate method based on our specific needs.
| Function | Purpose | Input Type | Output Type |
|---|---|---|---|
| sample_n() | Select a fixed number of random rows | size is an integer value for the number of rows to sample | A data frame with the specified number of random rows |
| sample_frac() | Select a random fraction of rows | size is a decimal value between 0 and 1 for the percentage of rows to sample | A data frame with the specified fraction of random rows |
Use Cases of Random Sampling in R
- **Model Training and Testing: Random samples are commonly used to split datasets into training and testing subsets, ensuring that the model is evaluated on data that it hasn't seen before.
- **Statistical Analysis: Random sampling ensures unbiased estimates when performing statistical analysis or hypothesis testing.
- **Simulation Studies: In Monte Carlo simulations or bootstrapping methods, random samples are used repeatedly to simulate a range of possible outcomes.
In this article, we explored the concept of random sampling and two commonly used functions for random sampling in R programming language.