Supervised and Unsupervised Learning in R Programming (original) (raw)
Last Updated : 23 Jul, 2025
Machine Learning (ML) is a subset of Artificial Intelligence (AI) that enables computers to learn from data and improve their performance over time without being explicitly programmed. The choice of ML algorithms depends on the type of data and the task at hand which can be broadly divided into Supervised and Unsupervised Learning.
Difference Between Labeled and Unlabeled Data
In the context of Machine Learning data can be divided into two types:
- **Labeled Data: This type of data includes both the input and the corresponding output (also called the label). For example, in a dataset of house prices, each data point includes both the features (such as square footage, number of bedrooms, etc.) and the price (the label).
- **Unlabeled Data: In this type of data only the input data is provided and there are no labels. The task of the machine learning algorithm is to find patterns, groupings or structure within the data. For example a dataset of customer transactions where there’s no information about which customers bought a particular product (labels).
The distinction between these two types of data forms the foundation for Supervised and Unsupervised Learning.
1. Supervised Learning
Supervised learning involves training a model on labeled data where both the input data and the correct output (label) are provided. The goal is to predict the output for new or unseen data.
Types of Supervised Learning:
- **Classification: Predicts a categorical label (e.g. "disease" or "no disease").
- **Regression: Predicts a continuous value (e.g. changes in "price", "weight", "temperature").
Example: Linear Regression in R
Linear Regression is a supervised learning algorithm used for predicting continuous values. We will use an example of implementing Simple Linear Regression in R.
R `
install.packages('caTools') install.packages("ggplot2") library(caTools) library(ggplot2)
dataset = mtcars
lm.r = lm(mpg ~ wt, data = dataset)
ypred = predict(lm.r, newdata = dataset)
ggplot() + geom_point(aes(x = dataset$wt, y = dataset$mpg), colour = 'red') + ggtitle('MPG vs Weight Data') + xlab('Weight') + ylab('Miles per Gallon')
ggplot() + geom_point(aes(x = dataset$wt, y = dataset$mpg), colour = 'red') + geom_line(aes(x = dataset$wt, y = predict(lm.r, newdata = dataset)), colour = 'blue') + ggtitle('MPG vs Weight With Regression Line') + xlab('Weight') + ylab('Miles per Gallon')
`
**Output:
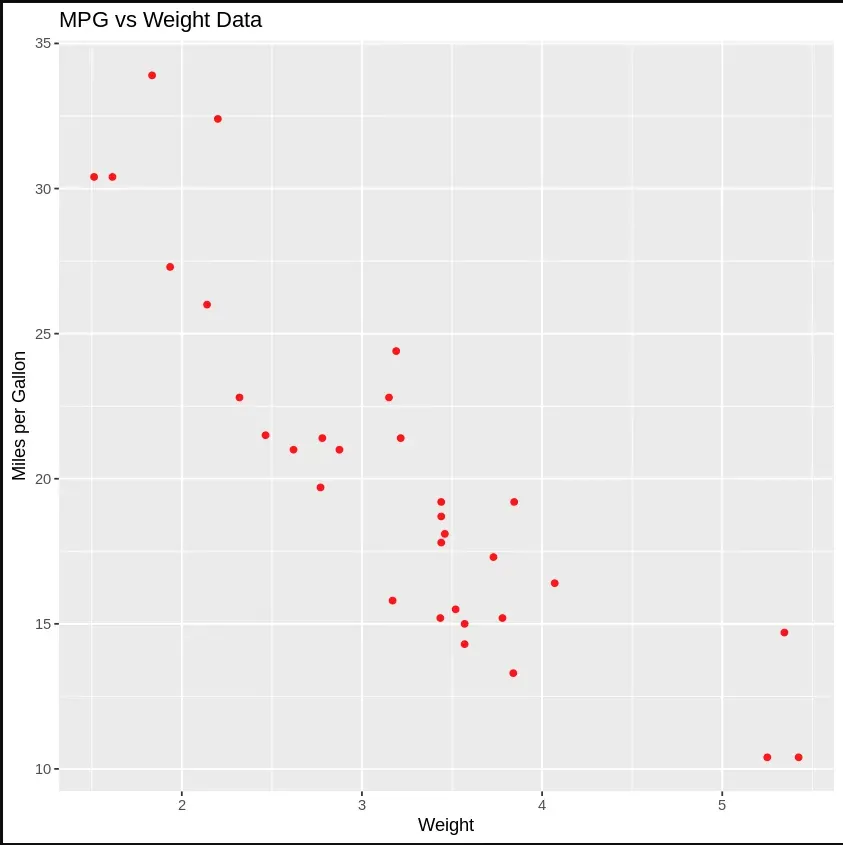
Mileage vs Weight
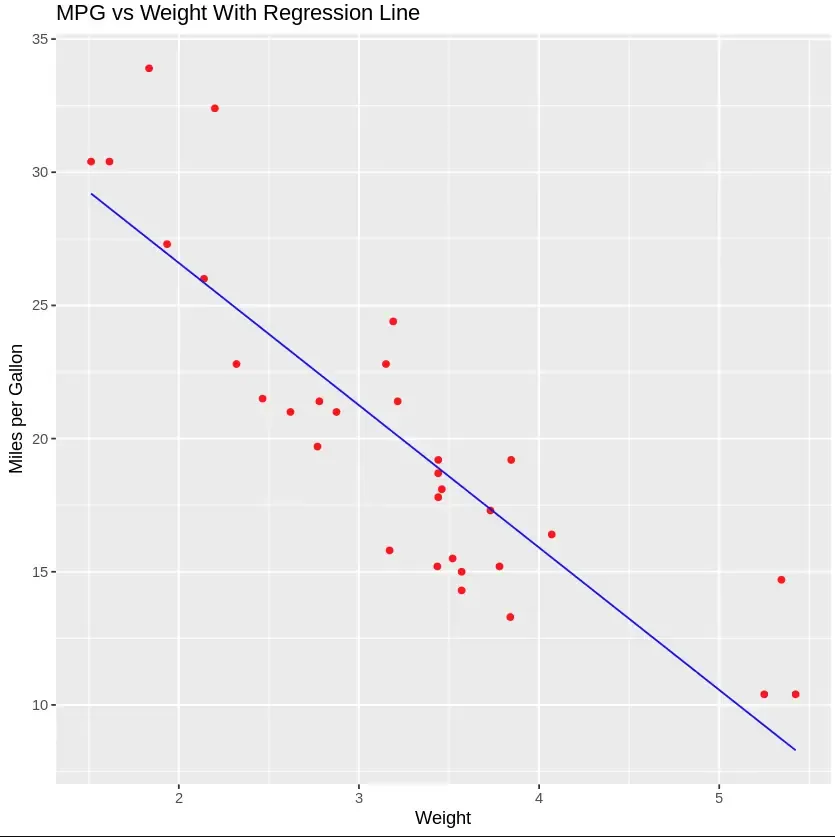
Mileage vs Weight and Regression Line
2. Unsupervised Learning
Unsupervised learning deals with datasets that are not labeled. The algorithm tries to identify hidden patterns or groupings in the data. There is no supervision, meaning the model does not know the "right" answers in advance.
Types of Unsupervised Learning:
- Clustering: Groups data based on similarity (e.g., customer segmentation).
- Association: Finds relationships between variables (e.g., market basket analysis).
Example: K-Means Clustering in R
K-Means Clustering is an unsupervised algorithm that divides data into clusters based on similarity. We will use an example of implementing K-Means Clustering in R.
R `
install.packages("cluster") library(cluster)
data(iris) iris_1 <- iris[, -5]
set.seed(240) kmeans.re <- kmeans(iris_1, centers = 3, nstart = 20)
plot(iris_1[c("Sepal.Length", "Sepal.Width")], main="Unlabeled Data")
y_kmeans <- kmeans.re$cluster clusplot(iris_1[, c("Sepal.Length", "Sepal.Width")], y_kmeans, lines = 0, shade = TRUE, color = TRUE, labels = 0, plotchar = FALSE, span = TRUE, main = paste("Cluster iris"), xlab = 'Sepal.Length', ylab = 'Sepal.Width')
`
**Output:
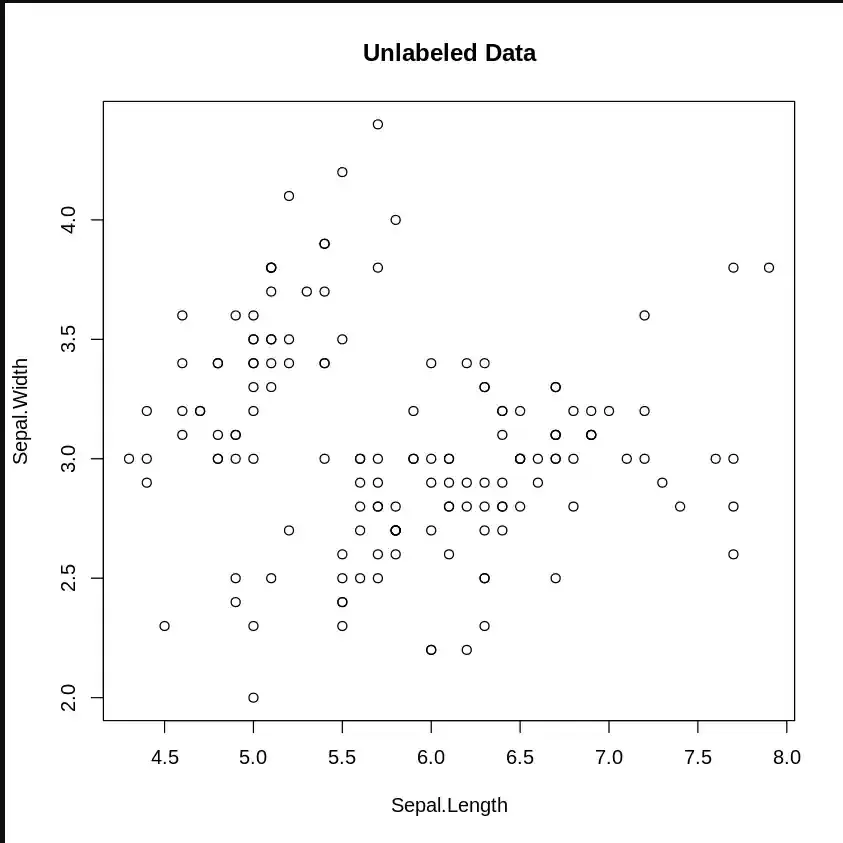
Unlabeled Data
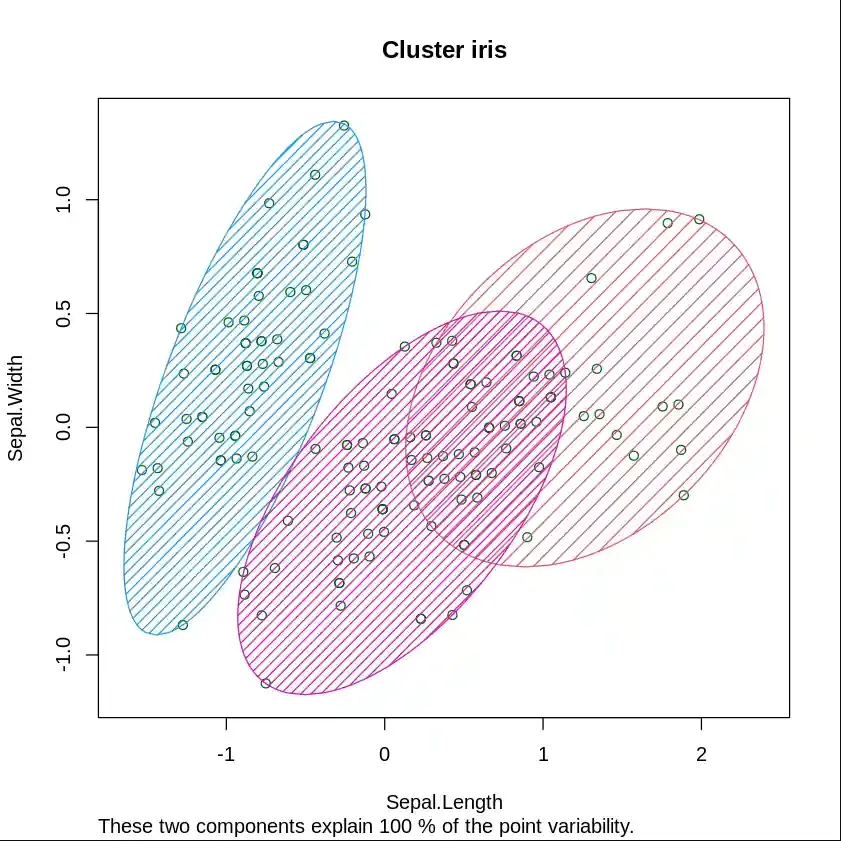
K-Means Clustering
In this article, we explored Supervised and Unsupervised Learning in R programming and understood how to decide which type of machine learning algorithm to use.