Design Distributed Job Scheduler | System Design (original) (raw)
Last Updated : 28 Mar, 2026
In today's technology-driven world, it's critical to handle computing tasks across different systems efficiently. A Distributed Job Scheduler system helps coordinate the running of tasks across multiple computers in a distributed computing environment. It manages the scheduling, distributing, and tracking of these tasks, including data processing, analysis, batch job runs, and resource assignment.
1. System Requirements
This section defines the functional and non-functional requirements for the system.
1. Functional Requirements
This section describes the core features the system must support.
- **Job Scheduling: Enable users to submit jobs for execution at specific times or intervals.
- **Distributed Execution: Execute jobs across multiple worker nodes in parallel.
- **Monitoring and Reporting: Track job status, system health, and resource usage.
2. Non-Functional Requirements
This section outlines system qualities like performance, scalability, and reliability.
- **Reliability: Ensure jobs are executed correctly and on time.
- **Performance: Execute jobs efficiently with low latency and minimal overhead.
- **Scalability: Support horizontal scaling to handle many concurrent jobs.
- **Fault Tolerance: Handle failures with retries and recovery mechanisms.
- **Security: Protect data with proper authentication and access control.
2. Capacity Estimations
This section estimates system capacity in terms of traffic, storage, bandwidth, and memory requirements.
1. Traffic Estimate
This section calculates the expected number of job requests over time.
- **Job Submissions: Estimate jobs per unit time (e.g., 1000 jobs/hour during peak).
- Helps in sizing schedulers and worker nodes.
2. Storage Estimate
This section estimates data storage requirements.
- **Job Metadata: If each job uses ~1 KB and there are 1 million jobs - ~1 GB storage.
- **Logs & Configuration: Additional storage based on logging level and retention policies.
3. Bandwidth Estimate
This section calculates network usage between system components.
- **Communication Overhead: If each message is 1 KB and 1000 messages/sec - ~1 MB/s bandwidth.
- Important for scheduler-worker communication and coordination.
4. Memory Estimate
This section estimates RAM usage for active processing.
- **Job Queues: If each job takes 100 bytes and 10,000 concurrent jobs - ~1 MB memory.
- **Execution Context: Additional memory for job state, processing logic, and concurrency handling.
3. High-Level Design
This section explains the major components involved in the job scheduling system and how they interact.
.webp)
HLD
1. Job Submission Interfaces
This section describes how users submit jobs into the system.
- Users submit jobs via a web portal connected to an API Gateway.
- API Gateway acts as a single entry point and forwards jobs to the Scheduler.
2. Scheduling Algorithms
This section explains how jobs are scheduled for execution.
- Scheduler receives jobs from the API Gateway.
- Uses algorithms based on priority, resource needs, and system load to schedule jobs.
3. Resource Management
This section manages allocation and utilization of system resources.
- Cluster Manager coordinates resource allocation across nodes.
- Resource Managers handle specific resources like CPU, memory, and storage.
4. Worker Nodes
This section handles actual job execution.
- Worker nodes (Compute Nodes) execute assigned jobs.
- They receive tasks and resources from the Cluster Manager.
5. Monitoring Services
This section tracks system health and performance.
- **Alerts: Notify about failures or critical events.
- **Logging: Store execution details for debugging and auditing.
- **Metrics: Track performance like job time, resource usage, and system health.
4. Low-Level Design
This section provides a detailed view of the internal components, data structures, and interactions within the system.

1. Job Submission Interface
This section describes how jobs enter the system securely.
- API Gateway acts as the entry point for all job submissions.
- Authentication Service verifies user credentials before forwarding requests to the Job Queue.
2. Message Queuing System
This section ensures reliable and asynchronous job handling.
- Job Queue stores incoming job requests temporarily.
- Jobs are processed later by the Scheduler, ensuring decoupling.
3. Scheduler and Lock Manager
This section manages job execution and concurrency.
- Scheduler Service decides job execution order based on priority and retry logic.
- Lock Manager ensures safe processing in concurrent environments.
4. Concurrency Control
This section prevents conflicts in multi-threaded execution.
- Lock Manager coordinates access to shared resources.
- Ensures consistency and avoids race conditions.
5. Distributed Coordination
This section maintains synchronization across distributed components.
- Coordination Service ensures smooth communication between services.
- Maintains consistency across the system.
6. Fault Tolerance
This section handles failures and ensures system reliability.
- Retry Logic retries failed jobs automatically.
- Dead Letter Queue stores failed jobs for later analysis.
7. Resource Allocation
This section manages compute resources for job execution.
- Resource Manager allocates CPU, memory, and storage.
- Integrates with container orchestration for running jobs.
- Tracks data using Job Metadata Store and Resource State DB.
8. Distributed Database
This section stores system data reliably.
- Job Metadata Store keeps job-related information.
- Resource State Database tracks resource usage and availability.
9. Performance Optimizations
This section improves system speed and efficiency.
- Caching layer stores frequently accessed data in memory.
- Reduces latency and improves response time.
5. Database Design
This section defines the database tables used to store job, user, and execution-related data.
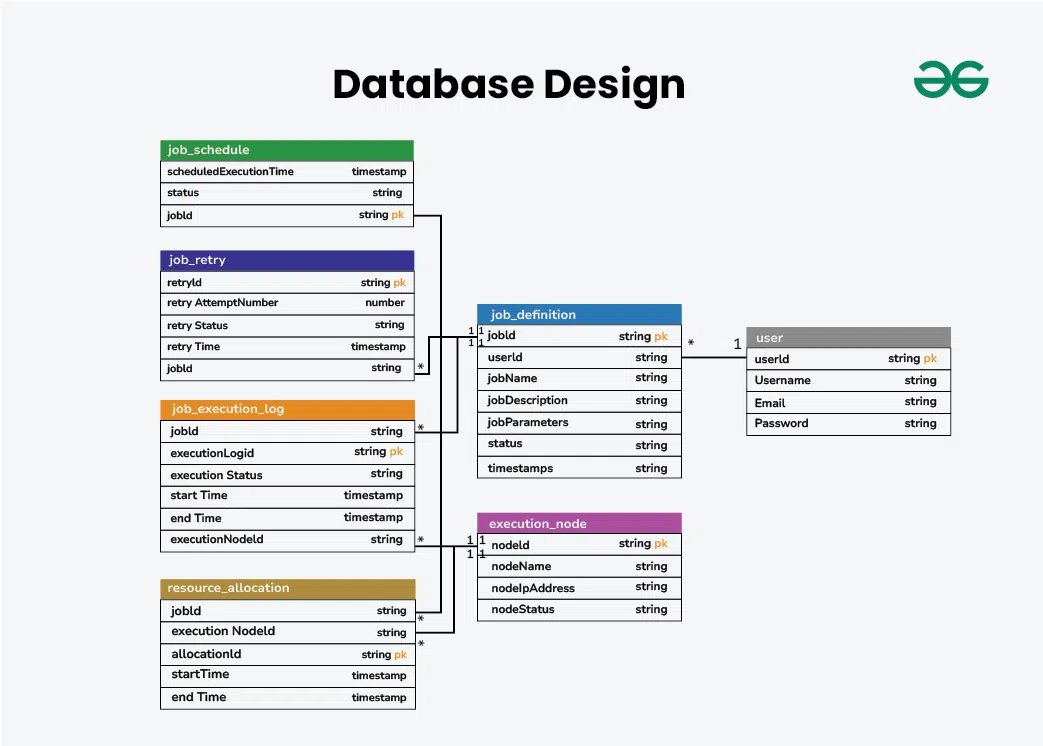
Database Design
1. Job Definition Table
This table stores details of all submitted jobs.
- Contains job ID, user ID, job name, description, parameters, status, and timestamps.
- Tracks the lifecycle of a job from creation to completion.
2. Job Schedule Table
This table stores scheduling information for jobs.
- Includes job ID, scheduled time, and status (scheduled/canceled).
- Helps manage when a job should be executed.
3. Execution Node Table
This table stores details of worker nodes.
- Contains node ID, name, IP address, and status (available/busy).
- Helps in assigning jobs to available nodes.
4. Job Execution Log Table
This table records execution history of jobs.
- Includes job ID, node ID, execution status, start and end time.
- Useful for monitoring, debugging, and auditing.
5. Resource Allocation Table
This table tracks resource usage for job execution.
- Stores allocation ID, job ID, node ID, start/end time.
- Helps manage CPU, memory, and other resource allocation.
6. Job Retry Table
This table manages retry attempts for failed jobs.
- Contains retry ID, job ID, attempt number, status, and retry time.
- Ensures reliability by tracking retries.
7. User Table
This table stores user information.
- Includes user ID, username, email, password (hashed), and other details.
- Used for authentication and tracking job ownership.
6. Microservices and API
In a job scheduler designed for distributed systems, a microservices architecture offers scalability, flexibility, and modularity. It achieves this by splitting the system into independent, smaller services, each handling specific tasks. These services communicate through clearly defined APIs (Application Programming Interfaces). Here's a rundown of the microservices and APIs in such a system:
1. Job Management Microservice
This service handles job creation, scheduling, and tracking execution.
- Create, update, and delete job definitions.
- Schedule jobs and monitor execution status.
- APIs:
/jobs/create,/jobs/schedule,/jobs/status
2. Execution Node Microservice
This service manages worker nodes and their availability.
- Register and maintain execution node details.
- Update node status (available/busy).
- APIs:
/nodes/register,/nodes/update-status,/nodes/list
3. Resource Management Microservice
This service manages allocation of system resources.
- Allocate and release CPU, memory, and storage.
- Monitor resource usage across jobs.
- APIs:
/resources/allocate,/resources/release,/resources/usage
This service ensures secure access to the system.
- Authenticate users and generate tokens.
- Handle authorization for protected resources.
- APIs:
/auth/login,/auth/authorize,/auth/logout
5. Logging and Monitoring Microservice
This service tracks system performance and logs.
- Collect and query logs for debugging.
- Provide metrics and configure alerts.
- APIs:
/logs/query,/metrics/get,/alerts/setup
7. Scalability
This section explains strategies to scale the system efficiently as workload increases.
1. Horizontal Scaling
This approach scales the system by adding more machines.
- Add more nodes to handle increasing job load.
- Use load balancers to distribute jobs evenly.
- Improves throughput by leveraging multiple machines.
2. Vertical Scaling
This approach increases the capacity of existing machines.
- Upgrade CPU, memory, and storage of nodes.
- Suitable for compute-intensive or memory-heavy jobs.
- Enhances performance without changing architecture.
3. Elasticity
This enables dynamic scaling based on workload.
- Auto-scale servers up/down based on demand.
- Handles peak loads and reduces cost during low usage.
- Ensures efficient resource utilization in real-time.
4. Database Scaling
This ensures the database can handle growing data and traffic.
- Use sharding to split data across multiple databases.
- Apply replication to improve read performance and availability.
- Use partitioning to optimize queries and reduce load.
5. Caching
This improves performance by storing frequently accessed data.
- Cache job data and results to reduce database load.
- Use tools like Redis or Memcached for fast access.
- Reduces latency and improves system responsiveness.