Fault Tolerance in System Design (original) (raw)
Last Updated : 17 Apr, 2026
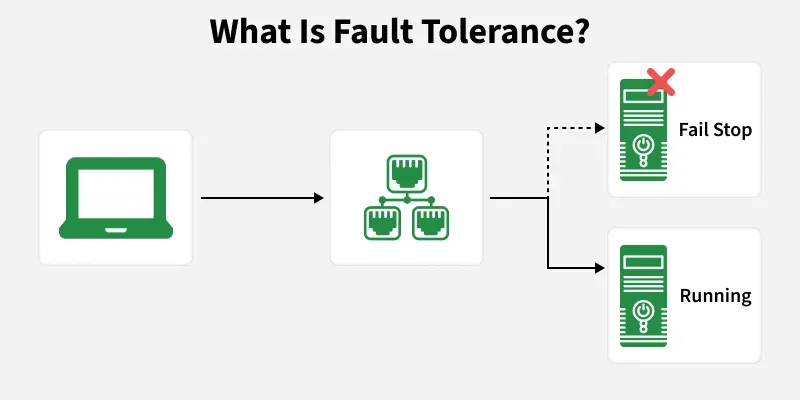
Fault tolerance refers to a system's capacity to keep working even in the face of hardware or software issues. Redundancy, error detection, and error recovery techniques must be used to avoid a costly failure . This will allow the system to continue operating or deteriorate in performance at a slower rate.
- Prevents complete system failure by allowing the system to continue working even if some components stop functioning.
- Improves system reliability by detecting errors and switching to backup components when needed.
**Example
- In cloud services, if one server fails, traffic is automatically redirected to another active server so users can still access the application.
- In a distributed database system, data is replicated across multiple nodes so that if one node fails, the data can still be accessed from another node.
Systems That Require Fault Tolerance
Fault tolerance is essential in systems where continuous operation is critical and failures can cause service disruption or data loss.
- **RAID (Redundant Array of Independent Disks): In storage systems, RAID configurations distribute data across multiple disks with redundancy, allowing the system to continue functioning even if one disk fails.
- **Load Balancing: Distributing network traffic across multiple servers ensures that if one server fails, others can still handle the load.
- **Clustering: Creating clusters of servers ensures that if one server fails, another can take over the workload seamlessly.
- **Virtualization: Running virtual machines on a server allows for easy migration of workloads to another server in case of hardware failure.
- **Microservices Architecture: Breaking down applications into smaller, independent services allows for the isolation of faults, preventing the entire system from failing if one service encounters issues.
- **Distributed Cloud Architecture: Distributing applications across multiple cloud regions or providers enhances fault tolerance by reducing the impact of a failure in a specific region or service.
Replication Strategies for Enhancing Fault Tolerance
Replication is a common technique used to improve fault tolerance by maintaining multiple copies of data or services across different nodes. If one node fails, another replica can continue serving requests without interrupting the system.
1. Full Replication
Full replication means creating a complete copy of the system or dataset across multiple nodes. Each node stores the same data so that if one node fails, another node can immediately take over.
- **Advantages: The system ensures straightforward fault tolerance with a seamless switch to a backup node in case of failure.
- **Challenges: Hosting a full replica on each node makes the system resource-intensive, highlighting the importance of synchronization mechanisms for maintaining consistency.
**Implementation: Every node maintains an identical copy of the entire system or dataset. Read out more in detail.
2. Partial Replication
Partial replication means only duplicating important or frequently used components instead of the entire system.
- **Advantages: Partial replication enhances resource efficiency by focusing on replicatingonly key components, which necessitates a careful selection process to determine which components are most critical for replication.
- **Challenges: Determining which parts are critical introduces complexity, and selectively replicated components present synchronization challenges.
**Implementation: Replicates only essential elements for system functionality, optimizing resource usage.
3. Shadowing or Passive Replication
Shadowing, also known as passive replication, maintains backup replicas that remain inactive during normal operation and become active only when the primary system fails.
- **Advantages: Shadowing or passive replication offers resource efficiency during normal operation and ensures a quick response in case of a failure.
- **Challenges: Ensuring synchronization during the transition from passive to active state is essential, and having effective fault detection mechanisms is crucial for maintaining system reliability.
**Implementation: Inactive replicas become active when the primary system encounters a fault.
4. Active Replication
Active replication involves multiple replicas processing the same requests simultaneously to ensure continuous system operation.
- **Advantages: Active replication provides high fault tolerance, ensuring that processing continues seamlessly even if some replicas fail.
- **Challenges: However, it comes with increased communication overhead due to multiple replicas actively processing, and managing consistency among these active replicas can be complex.
**Implementation: Requests are distributed to all replicas, and their outputs are compared to determine the correct result.
Fault Detection and Recovery
Fault detection and recovery are important parts of fault-tolerant systems. Fault detection helps identify when a component or service fails, while recovery mechanisms restore the system to a normal working state. Together, these processes ensure that the system can quickly respond to failures and continue operating with minimal disruption.
- **Fault Detection: Systems use monitoring tools, health checks, and heartbeat signals to detect failures in servers, databases, or network components.
- **Automatic Recovery: Once a fault is detected, recovery mechanisms such as service restarts, failover to backup systems, or switching to replicated nodes help restore normal operations.
**Example
• In a distributed application, monitoring systems detect when a server stops responding and automatically redirect traffic to another healthy server.
• In cloud environments, if a virtual machine crashes, the orchestration system automatically restarts it or launches a new instance to maintain service availability.
Fault Tolerance Vs High Availability Load Balancing
Fault Tolerance ensures a system continues working even when components fail, while High Availability focuses on keeping the system accessible with minimal downtime using techniques like load balancing.
| **Fault Tolerance | **High Availability Load Balancing |
|---|---|
| Ensures the system continues working even if some components fail. | Distributes workload across multiple servers to keep the system available. |
| **Goal: Maintain system functionality during failures. | **Goal: Maximize uptime and efficiently distribute traffic. |
| Uses techniques like redundancy, replication, failover, and error handling. | Uses techniques like load balancing algorithms, health checks, and traffic distribution. |
| Requires high redundancy where multiple components perform the same task. | Uses moderate redundancy to distribute traffic and avoid overload. |
| Focuses on preventing system failure even during component crashes. | Focuses on keeping services available and responsive to users. |
| Example: RAID storage systems or replicated distributed databases. | Example: Load balancers like NGINX or HAProxy distributing traffic across servers. |
| May slightly reduce performance due to extra checks and replication. | Usually improves performance by balancing requests across servers. |
Challenges in Implementing Fault Tolerance
Fault tolerance helps systems continue operating during failures, but implementing it introduces several practical challenges that must be carefully managed.
- **Scalability Issues: Scalability refers to the ability of a system to handle increasing workload or data size gracefully without sacrificing performance or availability. Scalability challenges in fault tolerance involve ensuring that fault-tolerant mechanisms can scale alongside the system's growth.
- **Performance Impacts: Fault tolerance mechanisms, such as redundancy and error correction, can impact system performance. This challenge involves minimizing performance degradation while maintaining high fault tolerance.
- **Cost Considerations: Implementing robust fault tolerance strategies often incurs additional costs due to the need for redundant hardware, software licenses, maintenance, and monitoring systems.