Designing Amazon.com's Database System Design (original) (raw)
Last Updated : 8 Apr, 2026
Designing Amazon’s database requires handling customers, products, orders, and recommendations in a scalable way. It integrates components like load balancers, caching, CDNs, and analytics to ensure performance.
- Integrates multiple services like caching, search engines, and analytics for efficiency.
- Focuses on scalability and handling high traffic smoothly.
- Identifies and resolves bottlenecks for better performance.
**Example: During a sale event, caching and CDNs help serve product pages quickly while load balancers distribute traffic across servers.
1. System Requirements
This section defines the overall functional and non-functional needs of the system.
1. Functional Requirements
This section describes the core capabilities related to data handling and processing in the system.
- **Real-Time Data Processing: Enables instant decision-making using stream processing and event-driven architecture (e.g., pricing, recommendations, fraud detection).
- **Efficient Indexing: Improves query performance by creating indexes based on access patterns.
- **Database Engine: Selection of suitable databases like MySQL, PostgreSQL, or Amazon Aurora based on use cases.
- **Query Processing: Ensures fast data retrieval using query optimization, caching, parallel processing, and distributed queries.
2. Non-Functional Requirements
This section defines system qualities like performance, reliability, scalability, and security.
- **High Availability: Ensures 24/7 uptime using multi-AZ deployment, load balancing, failover, and multi-region replication.
- **Data Integrity: Maintains accuracy and consistency using validation checks and integrity constraints.
- **Security: Protects data using encryption (at rest & in transit), IAM, and authentication mechanisms.
- **Redundancy & Disaster Recovery: Uses replication, backups, and failover strategies to prevent data loss.
- **Data Partitioning: Splits large datasets into smaller parts for better scalability and faster access.
2. Capacity Estimation
Accurately estimating capacity is a critical step in designing Amazon's database to ensure the system can handle current and future user demands. This process involves predicting the expected traffic, data volume, and resource requirements to create an architecture that is both scalable and performant.
More than 295 million visitors per month on Amazon
Amazon sells about 150,000 products per day in India
Total Product Sell in a month in India = 150,000 * 30 = 4,500,000
3. Use-case Diagram
A Use Case Diagram for Amazon’s database would visualize the various interactions and functionalities as far as Amazon’s e-commerce platform is concerned. Use Case Diagrams usually focus on the interaction of end users.
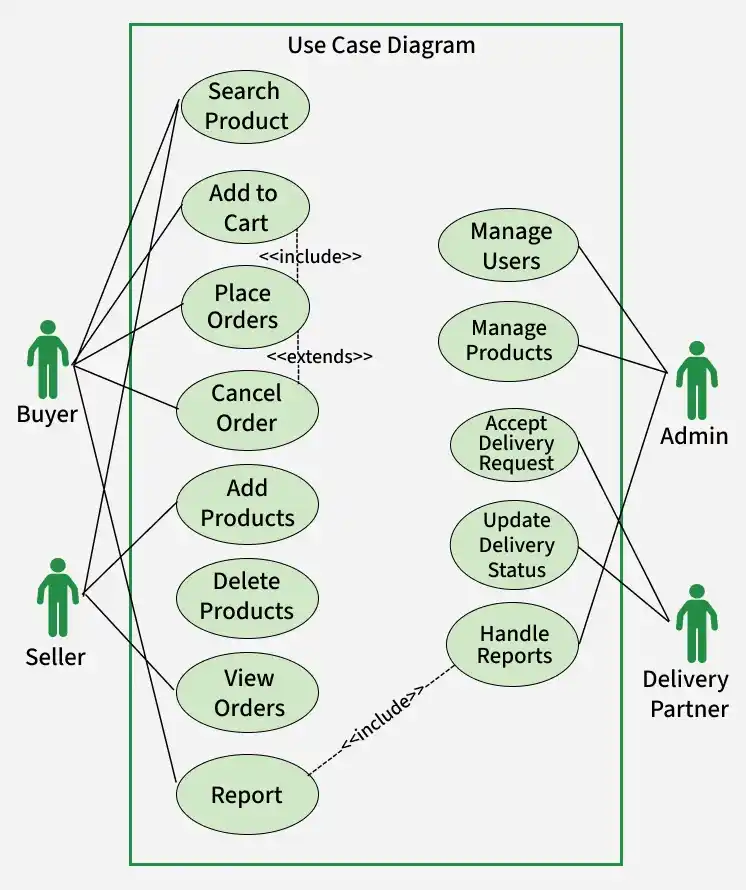
Use Case Diagram
4. Database design and diagram
Design a relational database that includes tables for customers, orders, products, reviews, payments, etc. establish relationships between tables using primary and foreign keys. Here's a simplified example of tables:
- Customers (Customer_ID, name, email, address, ...)
- Orders (Order_ID, Customer_ID, Order_Date, Total_Amount, ...)
- Products (Product_ID, name, description, price, ...)
- Reviews (Review_ID, product_ID, Customer_ID, rating, comment, ...)
- Payments (Payment_ID, Order_ID, Customer_ID,Payment_Date, amount, ...)
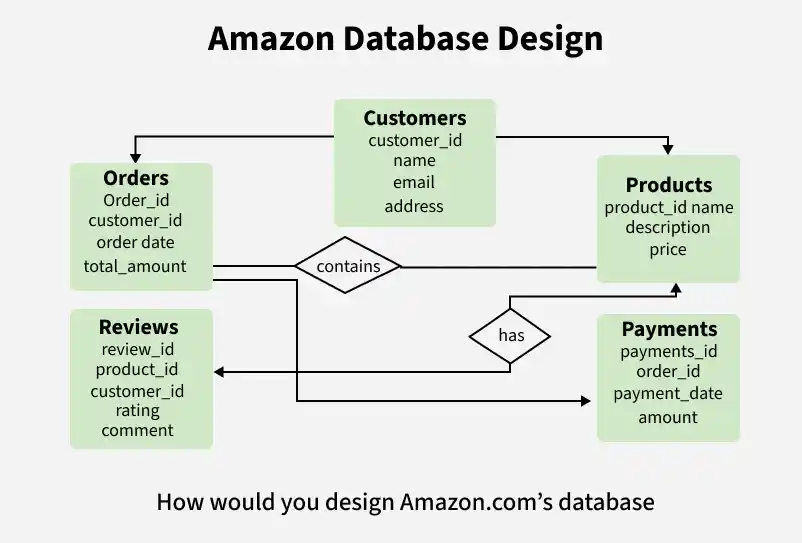
Database Design
Chosen approach for Amazon's Database
Relational databases are preferred for designing Amazon's database because they offer strong data integrity, ACID compliance, complex query support, and consistent performance, ensuring the reliability and delicacy required for critical functions like fiscal deals and order processing, which are fundamental to Amazon's e- commerce platform.
**1. Structured Data
Relational databases excel at handling structured data, which comprises a significant portion of Amazon's database, including product catalogs, customer information, and transaction records.
**2. ACID Compliance
Relational databases provide strong ACID (Atomicity, Consistency, Isolation, Durability) guarantees, ensuring transactional integrity and data consistency, which is crucial for financial transactions and order processing on Amazon.
**3. Data Integrity
Relational databases enforce referential integrity constraints, ensuring that data relationships are maintained correctly. This is essential for maintaining the accuracy of product catalogs, user profiles, and order histories
**4. Complex Queries
Amazon's database must support complex queries, such as product searches, personalized recommendations, and sales analytics. Relational databases offer robust SQL query capabilities for these requirements.
**5. Consistent Performance
Relational databases can provide consistent and predictable performance for a wide range of operations, which is essential for delivering a seamless shopping experience to millions of users.
**6. Scalability Options
Relational databases like Amazon RDS offer options for horizontal and vertical scaling to accommodate growing data and user traffic. They can be combined with caching layers and load balancing for improved scalability.
**7. Security
Relational databases offer robust security features, including access control, encryption, and authentication mechanisms, which are vital for protecting user data and sensitive information.
5. Scalability for Designing Amazon's Database
The key to maintaining high performance in the face of growing data and web traffic is to scale the database accordingly. With the growth of Amazon comes the need for scalable database management across multiple servers. On how to efficiently scale a database, here is a detailed guide.
Data Center-Wide Partition
This section explains how data is distributed across multiple data centers for reliability and performance.
- Data is distributed across multiple physical locations to ensure high availability and disaster recovery.
- Global distribution helps achieve low latency and reliable service.
Partitioning
This section describes how large datasets are divided for better scalability.
- Large databases are split into smaller partitions (shards) across multiple servers.
- Enables efficient data access, scalability, and faster recovery for specific data ranges.
Command Query Responsibility Segregation (CQRS)
This section explains how read and write operations are separated for optimization.
- Separates read and write operations to improve performance and scalability.
- Optimizes queries for heavy read workloads while maintaining efficient writes.
Vertical Scaling
This section describes scaling by upgrading a single server’s resources.
- Increases server capacity by upgrading CPU, RAM, or storage.
- Useful for handling sudden traffic spikes without major architectural changes.
Query Optimization
This section explains techniques to improve database query performance.
- Uses indexing, caching, and query rewriting to speed up data retrieval.
- Optimizes execution plans to maintain efficiency as data grows.
6. Advantages of Horizontal Scaling
Amazon's need to handle massive amounts of user traffic and data, horizontal scaling is a robust solution. It allows Amazon to distribute the load, handle traffic spikes, and ensure high availability. As Amazon's customer base and data continue to grow, horizontal scaling enables the platform to seamlessly accommodate increasing demands while maintaining responsiveness and reliability.
In Amazon's Context
- Amazon's vast e-commerce platform encounters varying levels of user activity, from routine shopping to major sales events.
- Distributing the load across a multitude of servers enables Amazon to efficiently process user requests, prevent bottlenecks, and provide a seamless shopping experience even during peak times.
- Handling traffic spikes is crucial for events like Black Friday, where sudden surges in user activity occur. Horizontal scaling allows Amazon to scale out rapidly and handle the influx of traffic while maintaining performance.
- High availability is essential for Amazon's reputation and customer trust. By ensuring that its application remains available even when individual servers face issues, Amazon prevents disruptions and delivers a reliable platform for users to shop and interact.
Remember that while horizontal scaling is a powerful approach, the specific choice depends on your application's unique requirements and constraints. Careful planning, monitoring, and optimization are essential to ensuring the successful implementation of horizontal scaling.
7. Bottleneck conditions
Bottleneck conditions are the critical points in a system where performance suffers, causing overall efficiency to decline. For complex systems like Amazon.com, relating and addressing Bottleneck conditions is key to delivering a seamless user experience and upholding high functionality. Conditions can emerge due to factors like limitations, algorithm restraints, or altered demand and they call for strategic measures to ensure system reliability and receptiveness.
- **High Query Load: User queries in the form of product searches, recommendations, and reviews are handled by Amazon. The pressure of peak hours or events like Prime Day forces database servers to operate at full capacity, leading to poor performance.
- **Network Latency: Latency in the network can have an impact on performance in a distributed environment like Amazon's. Delays in data retrieval can occur due to slow communication between application servers and the database. Network architecture optimization and CDN use can help address latency problems.
- **Data Inconsistencies: By replicating its database, Amazon ensures data availability and distribution across multiple servers. Consistency and data updates in replicas are a challenge, but vital. At Amazon, sophisticated synchronization methods and accuracy protocols are used to minimize inconsistencies in data representation.
- **Inefficient Indexing: Vital for fast query execution is efficient indexing. When it comes to optimizing queries, Amazon's case highlights the importance of well-chosen indexes for a extensive product database. User experience suffers due to slow query execution times or database scans caused by poor indexing strategies. By using careful indexing design and continuous monitoring, Amazon ensures efficient query execution despite database growth.
- **Scaling Limitations: If the chosen scaling strategy does not match with the application's growth path, it can cause capacity constraints and impact the system's efficiency in handling more traffic. Accommodating future demands is the reason Amazon carefully asséesses growth patters, uѕer behavior, and teсhnologісal advaгnсements.
- **Software Bottlenecks: Software-related bottlenecks can slow down amazon's database performance and cause issues if not identified and addressed properly. Bottlenecks are minimized by continuously refining software development practices, optimizing code and using query tuning at Amazon.
8. Components
This section describes the key components involved in building an e-commerce system like Amazon.
1. Relational Database Management System (RDBMS)
Amazon can use an RDBMS like MySQL, PostgreSQL, or Amazon RDS to store structured data. Interacts with all other components to store, retrieve, and manage data across different tables (customers, orders, products, etc.).
2. Load Balancers
Distribute incoming traffic across multiple application servers to prevent overloading and ensure even distribution. Balances the load among different application server instances to maintain responsiveness.
3. Application Servers
Handle user requests, process business logic, and interact with the database. Interact with the database to retrieve product information, process orders, and manage user accounts. Utilize load balancers to ensure uniform distribution of incoming requests.
4. Customer Interaction
Customers interact with the system through web interfaces, mobile apps, or other client applications. They send requests to application servers, which process the requests and retrieve data from the database tables as needed.
5. Order Processing
When a customer places an order, the application server collects the necessary order details, including the customer's ID and the product details, and inserts them into the Orders table. This represents a relationship between Customers and Orders, as one customer can have multiple orders.
6. Product Display
To display products, the application server queries the Products table to fetch product information such as names, descriptions, and prices. This retrieval process establishes a relationship between Customers and Products, as customers browse and potentially purchase products.
7. Review Submission
Customers can submit product reviews and ratings. When this happens, the application server records these reviews in the Reviews table. This relates Customers, Products, and Reviews, as customers provide reviews for specific products.
8. Payment Processing
After a customer confirms an order, the payment gateway interacts with the Payments table to record payment details, including the order ID and payment amount. This establishes a relationship between Orders and Payments, as each payment is associated with a specific order.