Names, Documents and Concepts (original) (raw)
Four Uses of a URL: Name, Concept, Web Location and Document Instance
David Booth dbooth@w3.org, W3C Fellow / Hewlett-Packard Revision:1.29Revision: 1.29 Revision:1.29 of Date:2003/01/2806:13:02Date: 2003/01/28 06:13:02 Date:2003/01/2806:13:02 by Author:dboothAuthor: dbooth Author:dbooth
This document: http://www.w3.org/2002/11/dbooth-names/dbooth-names_clean.htm
Abstract
URLs can be used to identify abstract concepts or other things that do not exist directly on the Web. This is sensible, but it means that the same URL might be used in conjunction with four different (but related) things: a name, a concept, a Web location or a document instance. Somehow, we need conventions for denoting these four different uses. Two approaches are available: different names or different context. The "different names" approach requires new URI schemes or conventions; the "different context" approach requires syntactic conventions for indicating the intended context.
Status of This Document
This document represents the views of the author only. It has no official status. Comments are invited.
Table of Contents
- What Needs to Be Identified?
- One URL and Four Kinds of Things
- Making Statements About These Four Kinds of Subjects
- General Approaches to Identifying Things: Names Versus Contexts
- Implications for URLs
- Generalizing
- Conclusions
- Acknowledgements
- Footnotes
What Needs to Be Identified?
One objective of the Semantic Web is to allow "anyone to say anything about anything" in a globally unambiguous, machine-processable format. This means that we need a way to unambiguously identify anything that anyone might ever want to talk about, including things that do not exist directly on the Web, such as people, cars, houses, etc., and things that are entirely abstract concepts, such as color or size, or the concept of love. How can this be done?
For convenience, we can subdivide the universe into the following kinds of things:
- Things that exist on the Web; and
- Things that do not exist on the Web. We can further subdivide these into:
- Physical objects (e.g., cars, people, buildings); and
- Abstract concepts (e.g., size, color, or the concept of love)
Things that exist on the Web are already indicated by URLs, so that category is easy. But how should physical objects and abstract concepts be identified?
Using URLs to Identify Physical Objects and Abstract Concepts
One established practice is to also use URLs to indirectly identify things that are not on the Web. For example, an abstract concept can be indirectly identified by placing a document at the URL that_describes_ that concept. Although this technique seems practical, an issue has arisen because of the ambiguity that it may create. (See the W3C's Technical Architecture Group (TAG) issue httpRange-14.) The central question is what such a URL is actually identifying: the concept or the _description_of the concept. The issue gets further muddied by the fact that some of the terms commonly used in this discussion -- such as "resource" and "document" -- are ambiguous in their common usage.
As an example, suppose I wish to talk about a specific concept of love, and I choose the name"http://x.org/love" to refer to this particular concept (assuming I own the Internet domain "x.org"). For the moment, let's just assume that this name is a string that conforms to URL syntax, and ignore the question of whether it really *is* a URL according to RFC2396. In what other ways might I legitimately wish to use that same URL-like string? To help others understand the particular concept that I'm trying to identify, I could also provide a Web location where you can get a document instance that describes this particular concept. In other words, I could set up a Web server such that if you type "http://x.org/love" into your browser, my server will return adocument instance corresponding to the Web locationindicated by "http://x.org/love". Since the concept of love cannot be directly placed on the Web anyway, it seems natural to use the same or a very similar URL-like string for this purpose. (Strictly speaking, there is no requirement to make information about the concept available on the Web at http://x.org/love, but doing so is a major help to others, analogous to the "View Source" effect.) However, this also causes confusion if I use the same URL-like string for both purposes. If someone mentions the URL, "http://x.org/love", how do you know if they're talking about theconcept, the Web location, a particular document instance, or even the name "http://x.org/love" itself?
One URL and Four Kinds of Things
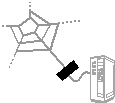
In short, there are at least four distinct but related things that we might commonly like to indicate in conjunction with this same URL "http://x.org/love" (whose primary purpose is to identify a particular concept of love), because we may need to talk about them separately. We can illustrate them as:
| 1. Name | 2. Concept | 3. Web Location | 4. Document Instance(s) |
|---|---|---|---|
| http://x.org/love | 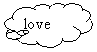 |
 |
 |
They are:
- The name "http://x.org/love" itself. (The quote marks are not a part of the name.) It is simply a string that conforms to the URL syntax specified in RFC2396.
- A particular concept of love. (For clarity, in this example it is a concept. However, the example could be generalized to other things that are not directly on the Web, such as cars and people. If so, it would probably be better to use a more general word than "concept".)
- A Web location, which is a logical source of document instances that describe the concept of love. The Web location is the abstract interface or endpoint from which document instances can be obtained. This Web location might be associated with a particular server, a file on a server, or an executable program that creates and returns the description dynamically. It may return the same or a different document instance each time it is queried. Physically, the document instances that correspond to http://x.org/love may be provided by a server that corresponds to http://x.org, but logically I am viewing http://x.org as a different Web location than http://x.org/love, because the two indicate different logical sources of document instances. Thus I am viewing each different (canonicalized, absolute) URL as identifying a different "Web location". So http://x.org, http://x.org/love and http://x.org/love/maternal would all indicate different "Web locations".
- Adocument instance that describes the concept of love, obtained at a particular point in time from the Web location http://x.org/love. Because there may be many of these document instances over time (as the description of love is updated on the server, for example), we should be more specific about what kind of document instance we might wish to indicate, such as:
- The current document instance(illustrated in green above), which refers (ambiguously) to any document instance that was or could be obtained at or near the time of discussion. Although this designation may be imprecise, it is often used.
- A particular document instance. The HTTP protocol allows each one to be uniquely identified (in conjunction with the URL) by an "Etag" in the document header. If we wish to refer to a particular document instance, we could either indicate that document instance using its Etag (in conjunction with the URL), or we could store that document instance at another Web location, and use the URL of that Web location to refer to it. (And don't change it!) Therefore, in this discussion of using URLs to indicate different things, we won't further consider this case.
(Incidentally, Roy Fielding refers to document instances as "representations", which is enlightening if you're talking about content negotiation, but in this context I think the term "document instance" is clearer.)
Of these four, the TAG has been concerned about distinguishing the Web location from theconcept.
Making Statements About These Four Kinds of Subjects
All four of these things are legitimate subjects of statements that we should be able to make if we allow "anyone to say anything about anything" on the Semantic Web. In English, we might make ambiguous statements like:
"http://x.org/love contains three forward slashes."
"http://x.org/love makes the world go round."
"http://x.org/love has the document you seek."
"http://x.org/love is a good description of the concept of love."
meaning:
| Subject | Verb | Object |
|---|---|---|
| http://x.org/love (the name) | contains | three forward slashes |
| http://x.org/love (the concept) | makes | the world go round |
| http://x.org/love (the Web Location) | has | the document you seek |
| http://x.org/love (the document instance) | is | a good description of the concept of love |
But for the Semantic Web, in which these statements would be expressed in a machine-processable format, we need the subject (name, concept, Web location or document instance) to be unambiguous. Furthermore, these four subjects are closely related, and we often need to switch from talking about one to talking about another. For example, given the name "http://x.org/love", at various different points we may wish to refer to: (1) the nameitself; (2) the concept that it identifies; (3) the Web location where a description of that concept can be found; or (4) a document instance that is obtained from that Web location. Hence, we need some way of clearly distinguishing these four uses of the URL, while still keeping their relatedness evident.
It is important to note that it is perfectly possible to use an entirely different URL to denote each of these four things. The only reason we wish to use the same URL (or similar URLs) in expressions for all four things is because they are closely related, and we therefore want to be able to easily switch from talking about one to talking about another. This is an essential requirement behind the "View Source" effect.
General Approaches to Identifying Things: Names Versus Contexts
If we look at this problem in the abstract, there are two general approaches we can take to identifying different things:
- Use different names to refer to different things; or
- Use different context to distinguish the different uses, while using the same name.
For example, suppose we wish to use the name "Fred" to refer to a particular person:
 |
|---|
 |
Sometimes we need to refer to this person, and sometimes we need to refer to the name itself, as we did in the previous sentence.
Approach A: Different Context
One of the clearest ways to indicatedifferent context is to use the syntactic convention of placing quote marks around the name when we wish to refer to the name itself, rather than the person. The quote marks mean: in this context I am talking about the name itself, rather than the thing to which the name refers. So for example, if we write
"Fred"
then we are referring to the name (as a string), whereas if we write
Fred
then we are referring to the person. Of course, other conventions can also be used to indicate context -- not just syntactic conventions -- but there's a trade off between the flexibility of the convention and the machine sophistication that is required to understand it.
Approach B: Different Names
The other approach we could take is to use different names to distinguish between the name "Fred" and the person, Fred. For example, we could adopt the convention of writing the name "name:Fred" when we wish to refer to the name "Fred", but continue to write the name "Fred" when we wish to refer to the person, Fred. Of course, at some point we may also wish to refer to the name "name:Fred" itself, so we may need to write "name📛Fred" for this purpose, and so on. So we have:
 |
|---|
 |
This convention of prefixing "name:" to a name means that the name should not be entirely opaque, because we want to be able to easily navigate from the name "name:Fred" to the name "Fred" to the person. In other words, when we see a name such as "name:Fred" that begins with "name:", we need to know: (a) that we are referring to the name "Fred" rather than the person Fred; and (b) that we can strip off the "name:" part to refer to the person Fred.
Implications for URLs
In one sense, there isn't much difference between these two approaches (name prefixes versus syntactic context indicators), because we could simply think of the "name:" prefix as being a syntactic context indicator (analogous to quote marks) instead of being part of the name; or we could even think of the quote marks around the name "Fred" as being a part of a new name instead of indicating the syntactic context for the name. Either way, we need conventions for distinguishing between the various uses of the name. However, if we consider this in the context of URLs (or URIs) as names, then there are practical consequences.
If we use different names to distinguish these four uses of a URL -- name, concept, Web Location or document instance -- then we would have to establish new URI syntax or conventions. For example, if we assume that "http://x.org/love" denotes a Web location, then we might define a new URI scheme to identify things like physical objects and abstract concepts that might not be on the Web, such as "thing://x.org/love". (See discussion in TAG minutes, which focuses on the distinction between a concept and a Web location.) A positive of this approach is that URLs would have the same meaning in any context. A negative is that the syntax and conventions for URIs are well established; it would be unpleasant to change them.
On the other hand, if we use syntactic context to distinguish these four uses, then the convention depends on the language that you're using to talk about them. Each language could use whatever syntactic conventions it finds most convenient. (Of course, this is both a plus and a minus!)
The two approaches are not mutually exclusive though. We could use a mixture. For example, we could use quote marks (i.e., context) to refer to a URL as a name, but use a new URI scheme to refer to a concept.
Just for illustration purposes, here are some hypothetical conventions, using both approaches. (See also Larry Masinter's suggestion for using urn:tdb::.)
| | 1. Name | 2. Concept | 3. Web Location | 4. Document Instance(s) | | | --------------------------------------------------------------- | --------------------------------------- | ------------------------------------------ | ------------------------ | ------------------------------------------- | | Approach A: Different Names (i.e., name indicates meaning) | name:thing://x.org/love | thing:http://x.org/love thing://x.org/love | http://x.org/love | get:http://x.org/love | | Approach B: Different Context (i.e., context indicates meaning) | "http://x.org/love" 'http://x.org/love' | (http://x.org/love) @http://x.org/love | http://x.org/love | GET http://x.org/love `http://x.org/love\` |
Side note: Although a hash mark "http://x.org/love#" has historically been used in RDF to distinguish the concept from the Web location, this convention does not seem like such a good choice to me, because a hash mark can legitimately appear in a URI reference to delimit the fragment identifier, such as:
so this may cause a (natural) confusion of whether it is intending to denote a concept, a Web (sub)location or perhaps a portion of a document instance. (See also Sandro Hawke's proposal for RDF, which is an "odd mixture" of both approaches.)
Enabling the View Source Effect
Whichever approach is used, it seems to me that the resulting notational conventions for these four kinds of things must be closely related in order to achieve the "View Source" effect. For example, they must all involve (in part) some form of the string "http://x.org/love", so that one can easily convert an expression that denotes one of them into an expression that denotes another. For example, if "@http://x.org/love" denotes the concept and "http://x.org/love" denotes the Web location, then the expression that denotes the concept can be easily transformed into the expression that denotes the Web location by removing the "@". The "View Source" effect critically depends on the existence of such a (simple) transformation. More precisely, it requires that there be a simple transformation available to convert from an expression denoting the concept to an expression denoting a document instance. [Hmm, I need to re-think this, because I'm really not sure it's correct. Perhaps I'm making too many assumptions about what kind of language would be used.]
[Note: I'm really not sure this next conclusion is correct either. Any suggestions?] Therefore, being agnostic (within a given language) about which of these four things the URL denotes is not a viable solution, because it would prevent the "View Source" effect. Specifically, if the language itself provides no way of indicating whether a particular expression is identifying the concept or the Web location, then no such transformation is possible and the "View Source" effect would not be achieved. Even though any given user of the language might adopt his/her own personal conventions for distinguishing between the concept and the Web location, and thus might not see any problem in having no language-defined conventions, the objective of the Semantic Web is to allow statements that were written by a previously unknown party (whose personal conventions are therefore unknown) to be properly understood.
Pros and Cons of "Different Name" Versus "Different Context"
As far as I can tell, the "different names" and "different context" approaches have the following pros and cons.
| Different Names | Different Context |
|---|---|
| Pro: Easier to know what a given URL identifies. Consistent meaning across languages. Con: Difficult to achieve, because it requires people to agree on which of these four things a URL_should_ indicate. | Pro: More "robust", in the sense that it does not require everyone to agree on which of these four things a URL should indicate, thus side-stepping the httpRange-14issue. Con: Each Semantic Web language must specify what convention is used to denote each these four things that it uses. |
Generalizing
So far, I've been discussing the use of URLs to identify abstract concepts, as outlined in "What needs to be identified?" above. Can these principles be generalized to also cover physical objects that are not on the Web andthings on the Web? In other words, suppose you choose to use a URL to identify a particular thing in the universe, whether it's a physical or an abstract thing. What other things are you also likely to want to reference in conjunction with that same URL? Are the categories similar to the four described for abstract concepts? Yes.
The case of identifying physical objects that are not on the Web is very similar to the case of identifying abstract concepts. However, the case of identifying things on the Web requires more explanation, because we need to more clearly define what we mean by a "thing on the Web". Here are two options.
Option 1: One possibility is to define "things on the Web" as merely being a "Web locations". This would have the benefit of simplicity, because it would directly correspond to one of the four kinds of things already described above. However, that definition may not correspond very well with people's intuition of "something that is on the Web".
Option 2: Another possibility is to define a "thing on the Web" as an abstract entity that is accessed via its Web location. I.e., its Web location acts as its interface or endpoint through which the entity is accessed. There are two convenient and intuitive ways to think of this entity:
- An abstract document, which may be changed over time, such that different document instances might be obtained from the Web location at different times. (You could also think of this "abstract document" as representing the abstract set of all document instances that could ever be retrieved from the Web location.) Colloquially, this is what people usually mean when they talk about a "document".
- A device or machine, which again is an abstraction that may correspond to a physical device or machine, or perhaps a portion of a machine. An example might be a video camera that can be accessed and controlled via its Web location.
Summary of Generalization
The table below summarizes how these ideas can be generalized to cover other things in the universe, such asphysical objects and things on the Web.
| | Four Kinds of Things Related by the Same URL | | | | | |
| ----------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------- | ------------ | ----------------- | ----------------- |
| Primary Thing to Be Identified | Related Things that Might Be Identified Using the Same URL | | | | |
| Things on the Web (Option 1) | Web locations | a Web location  | name | Web location | document instance |
| Things on the Web (Option 2) | Abstract Documents | an abstract document
| name | Web location | document instance |
| Things on the Web (Option 2) | Abstract Documents | an abstract document  | name | Web location | document instance |
| Devices | a device
| name | Web location | document instance |
| Devices | a device  | name | Web location | document instance | |
| Things not on the Web | Physical Objects | a physical object
| name | Web location | document instance | |
| Things not on the Web | Physical Objects | a physical object  | name | Web location | document instance |
| Abstract Concepts | a concept
| name | Web location | document instance |
| Abstract Concepts | a concept  | name | Web location | document instance | |
| name | Web location | document instance | |
Relationship to Terms Defined in RFC2396
Unfortunately, I do not have a good term that encompasses all of the things in the column labeled "Primary Thing to Be Identified" above. Sandro Hawke uses the term "subject" in his proposal for addressing this problem in RDF, and that might be the best we can do, though I'm still hoping for something more intuitively suggestive.
RFC2396 uses the terms "resource" and "representation" to refer to certain Web notions, so it's natural to ask how those terms relate to the Four Kinds of Things that I have described. Unfortunately, I find the RFC2396 definition of "resource" to be hopelessly confusing, as I have detailed at length in "What Part of 'Resource' Don't I Understand?", so I really can't say how it relates. This confusion about the concept of "resource" seems to be the root of the TAG's httpRange-14 issue. Some contend that "resources" are the things in the column labeled "Primary Thing to Be Identified" above, and I believe others contend that "resources" are either what I call "Web locations" or what I called "abstract documents" above (I'm not entirely sure which). See Tim Berners-Lee's message summarizing his and Roy Fielding's positions.
I am quite certain that the RFC2396 notion of a "representation" is essentially the same as what I call a "document instance". I prefer the term "document instance" because I find it more intuitive, but that's a matter of personal taste and context, because the term "representation" was intended to cover more cases than "document instance".
Conclusions
One point seems clear. In using URLs to identify concepts (such as "http://x.org/love"),**we need conventions for denoting each of these four things**: name, concept, Web location and document instance.
What to do? If we follow the "different names " approach, then the URL _itself_should have well-defined meaning, and we should be able to determine from the URL specification whether "http://x.org/love" denotes a name, a concept, a Web location or a document instance. One possibility is to assume that a URL by itself always denotes a Web location. (Indeed, my reading of the URI specification, RFC 2396, does seem to indicate this interpretation, but it's a bit unclear.) The vast majority of URL references today are inside HTML "" tags. Such a reference appears to denote aWeb location from which a document instance might be obtained. So from that point of view, it may make sense to say that a URL by itself always denotes a Web location, and if you want to use it to denote a concept (or a person or a car) then you must use a new URI convention for this purpose.
The other approach is to always rely on syntactic context to indicate the meaning of a URL. In other words, the interpretation of a URL depends on the language of the statement in which that URL appears. For example, we might declare that a URL written in one kind of statement always denotes aconcept, while a URL written in another kind of statement always denotes a Web location.
In any case, if we wish to create a Semantic Web in which statements are unambiguous and machine processable, then any machine-processable language that uses URLs mustclearly specify which of these four things is intended when a URL is written in that language. But for sanity across languages, it would be nice to have some common conventions.
Acknowledgements
Thanks to Sandro Hawke and Dan Connolly for clarifying discussions on these concepts.
Footnotes
The "View Source" Effect
The "View Source" effect refers to the ability in a Web browser to view the HTML source code that was used to display the current page. Since almost every browser has this capability, and HTML is fairly simple, this technique has been an easy and ubiquitous way to learn HTML. The effect of this is widely believed to have been a big factor in the explosive success of the Web.
Etag
The "Etag" is an HTTP header field. Its value is an arbitrary string (a timestamp or hash code, perhaps) that is different for each different document instance. It allows the client to quickly determine whether a different document instance is available from the Web location. See http://www.ietf.org/rfc/rfc2616.txt.
Other Conventions for Indicating Context
Simple syntactic conventions are the easiest for a machine to understand but the least flexible. Operator type signatures are a more flexible way of indicating context but require a more sophisticated processing model. Conventions that depend on deeper semantic understanding (or out-of-band knowledge) require the smartest machine.
| Context Convention | Example | Explanation |
|---|---|---|
| 1. Syntactic Indicators | "Fred" | Quote marks indicate that "Fred" denotes a name. |
| 2. Datatypes | concatenate(Fred, erick) | Type signature of "concatenate()" indicates that "Fred" denotes a name. |
| 3. Arbitrary Semantics | Fred is a nice name. | Other semantic knowledge indicates that "Fred" denotes a name. |