Vector databases or pure grep? Teams are split on the right retrieval architecture for agents. The reality? You need both. Semantic search for a fast first pass; grep and file reads for surgical precision when top-k chunks cut off mid-answer. On June 29, our Head of
Our CEO Jerry Liu is joining founders from LangChain, CrewAI, and others at @databricks #DataAISummit today for a panel on the The Agentic Stack — what the stack looks like, where it's headed, and what happens when agents become the primary consumers of infrastructure, not
How much can good documentation save an AI agent in cost and time? Turns out, a lot. We built a custom skill that teaches Claude how to parse PDFs more efficiently, then used real usage traces to find where it was wasting time and money (re-reading the same file over and over,
Contracts are where business commitments live, but most organizations still manage them manually, searching PDFs for renewal dates, chasing down payment terms, and hoping nothing slips through the cracks. The problem isn't just volume. Legacy OCR treats contracts like flat text,
LlamaIndex 🦙 reposted As frontier models (e.g. Fable 5) continue to push the task horizon of knowledge work automation, it becomes ever more important for humans to be able to audit decisions back to the source context. It is extremely easy for agents to cite an entire document or document page, but Parsing a document accurately is one thing. Proving where every value came from is another. When a compliance team reviews an AI extraction, or an auditor needs to sign off on a figure pulled from a financial filing, "it came from this document" isn't enough. They need to see
LlamaIndex 🦙 reposted LiteParse, our open-source/Rust-based doc parser, runs so quickly that Claude Fable 5 doesn't think it's real 🔥 It is the fastest document parsing solution on the planet and a great choice for your AI document workloads. Check it out: github.com/run-llama/lite… LiteParse runs so fast that Claude Fable 5 doesn't think its real
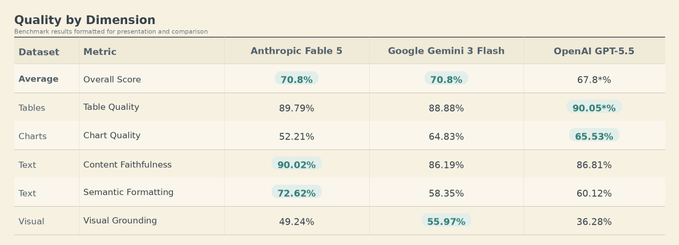
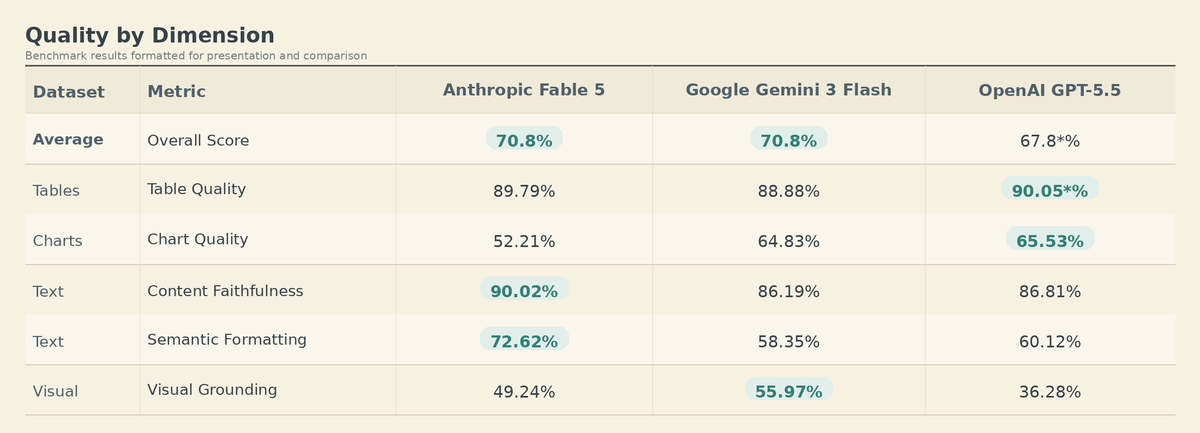
LlamaIndex 🦙 reposted Claude Fable 5 thinks document parsing is beneath it It is absolutely crushing on all reasoning-intensive/long horizon benchmarks: SWE-Bench Pro, FrontierCode, GDPval, Runescape, etc. But for document understanding tasks, it is roughly equivalent with Gemini 3 Flash in Day 0 Anthropic Fable 5 in ParseBench: We tested the model's advancements when it comes to document understanding. The model clearly peaks when it comes to adherence to the original text: 📃 Content faithfulness: 90.02% vs 86.19% (Gemini 3 Flash) and 86.81% (GPT-5.5) 🔢 Semantic
Day 0 Anthropic Fable 5 in ParseBench: We tested the model's advancements when it comes to document understanding. The model clearly peaks when it comes to adherence to the original text: 📃 Content faithfulness: 90.02% vs 86.19% (Gemini 3 Flash) and 86.81% (GPT-5.5) 🔢 Semantic
Parsing a document accurately is one thing. Proving where every value came from is another. When a compliance team reviews an AI extraction, or an auditor needs to sign off on a figure pulled from a financial filing, "it came from this document" isn't enough. They need to see
The Agent Open: AI's Pickleball Tournament 🏓 Come put your code and backhand to the test and embrace the full Open experience. Custom built out courts. Stadium seating. Exhibition matches by AI leaders. Fresh agent merch. Every infra startup you love, all in one place.
Most AI pipelines are only as good as the data we provide them with, and that usually means PDFs or other unstructured documents. Contracts, invoices, reports... All have special layout, language, and context mixed together, and getting reliable structured data out of them is
LlamaIndex 🦙 reposted We're presenting ParseBench at CVPR 2026! ParseBench is the most comprehensive document understanding benchmark for VLMs. ✅ It contains 2k pages of real-world enterprise documents ✅ It has comprehensive evaluation metrics around tables, charts, visual grounding, semantic We're presenting ParseBench at CVPR 2026 today. 🦙 Come learn why document understanding is an AGI-complete problem (an agent can't act on a doc it can't correctly read, and reading a real enterprise table is harder than it looks). The first doc-parsing benchmark built for AI