YANS (original) (raw)
お知らせ
2024年1月より,YANS(旧NLP若手の会)の活動は言語処理学会の若手支援事業のひとつとして実施することになりました. YANS懇親会(3月開催),YANSシンポジウム(8月~9月開催)などを通じて,自然言語処理および周辺技術に携わる若手のネットワーク構築や研究推進に取り組んでいく予定です.
Xでも情報を発信しています.YANSアカウントはこちら
- 第19回シンポジウムの受賞者一覧を公開しました (2023/09/06) new!
- プログラムの詳細を公開しました (2024/08/13)
- 発表あり参加申し込みを終了しました (2024/08/07)
- 発表なし参加申し込みを開始しました (2024/07/29)
- 発表あり参加申し込みを終了しました (2024/07/26)
- スポンサーの募集を終了しました (2024/07/19)
- 発表あり参加申し込みを開始しました (2024/07/01)
- ハッカソンについての詳細ページを公開しました (2024/07/01)
- 暫定プログラムを公開しました(2024/06/03)
- スポンサーの募集を開始しました(2024/05/27)
- 旅費補助についての詳細ページを公開しました (2024/05/20)
- スポンサーの募集についての詳細ページを公開しました(2024/05/01)
- シンポジウムの開催概要を掲載しました (2024/05/01)
- YANS懇2024のご案内を公開しました (2024/01/25)
YANSにおけるアンチハラスメントポリシーを公開しています.
YANSシンポジウム運営委員会(2024年)
委員長
- 大内 啓樹 (NAIST/サイバーエージェント)
- 佐藤 元紀 (Preferred Networks)
顧問
- 梶原 智之 (愛媛大)
委員
- 岩本 蘭 (日本IBM/慶應大)
- 小原 涼馬 (NEC)
- 勝又 智 (レトリバ)
- 栗原 健太郎 (AI Shift/サイバーエージェント)
- 小林 悟郎 (東北大)
- 鈴木 雅弘 (日興アセット/東大)
- 西田 悠人 (NAIST)
- 根石 将人 (みらい翻訳)
- 長谷川 駿 (エクサウィザーズ)
- 馬緤 美穂 (LINEヤフー)
- 松野 智紀 (みらい翻訳)
- 三田 雅人 (サイバーエージェント/都立大/東大)
- 守屋 彰二 (東北大)
- 矢田 竣太郎 (NAIST)
- 矢野 千紘 (PKSHA Technology)
- 山岸 駿秀 (マネーフォワード)
- Youmi Ma (東工大)
- 李 凌寒 (LINEヤフー/SB Intuitions)
2024年9月4日(水)〜6日(金),梅田スカイビル(大阪梅田)にて第19回言語処理若手シンポジウム(YANS2024)を開催しました。 YANS2023に引き続く現地開催となり,参加/発表とも過去最多の,411名(学生215名,社会人196名)の参加と196件の発表(学生161件,社会人35件),24社のスポンサーの皆様をむかえ,今年も大盛況でした。 ご参加いただいた皆様,ご支援いただいた皆様,どうもありがとうございました。
本シンポジウムでは,優秀な研究発表に対して奨励賞,デモ賞,スポンサー賞を授与しました。奨励賞はこれから始まる,または始まったばかりの研究を奨励することを主旨とするものであり,現時点の研究の完成度よりもアイデアの面白さ,及び新規性や発展性への期待を重視します。奨励賞およびデモ賞の選考は参加者による投票をもとに,最終的には表彰担当者による合議によって奨励賞は23件,デモ賞は1件を選出しました。スポンサー賞は産学交流の一環として各スポンサー独自の視点から19件の受賞者を選出していただきました。いずれの賞も受賞者は筆頭著者のみとなります。
今年のチュートリアルでは,国立情報学研究所の佐藤竜馬氏に「ニューラルネットワークの損失地形」を,Turing株式会社の荒居秀尚氏に「生成AIの二大潮流と自動運転」をご講演いただきました。また,招待セッションでは自然言語処理や音声,画像,人文・社会学系の分野でご活躍されている若手研究者/技術者15名をお招きし,これまでのご自身の研究についてポスター発表をしていただきました。
シンポジウム1日目の幕開けとして留学交流会が開催されました。YANS分野交流ハッカソンも開催されました。本ハッカソンでは,画像処理を始めとする自然言語処理以外の分野の学生・社会人と広く交流することを目的として,画像と言語の融合を目指すテーマが設定されました。具体的には,OpenAI APIを利用した言語芸術生成ハッカソンを行い,大喜利および川柳の2つのテーマのハッカソンが開催されました。ハッカソンには93名が参加し,各テーマについて8チームずつ,計16チームが取り組みました。 シンポジウムでは受賞チームによる最終成果発表を行い,優秀賞,審査員特別賞,YANS運営委員特別賞が贈られました。
- シンポジウムの様子
- 統計データ
- 参加報告ブログの紹介
- 発表資料等
- 受賞者
- デモ賞 (対象15件中1件)
- 奨励賞 (対象187件中23件)
- スポンサー賞 19件
* サイバーエージェント賞
* フューチャー株式会社賞
* SB Intuitions株式会社賞
* 株式会社リクルート賞
* 日本経済新聞社日経イノベーション・ラボ賞
* 株式会社PKSHA Technology賞
* シェルパ・アンド・カンパニー賞
* 株式会社エクサウィザーズ賞
* 株式会社マネーフォワード賞
* 株式会社オルツ賞
* 株式会社ELYZA賞
* Aww, Inc.賞
* 株式会社博報堂テクノロジーズ賞
* ストックマーク株式会社賞
* 株式会社IVRy賞
* Spiral.AI株式会社賞
* Turing株式会社賞
* 株式会社日立製作所賞 - ハッカソン賞
* 大喜利ハッカソン 優秀賞
* 川柳ハッカソン 優秀賞
* 大喜利ハッカソン 審査員特別賞
* 川柳ハッカソン 審査員特別賞
* 大喜利ハッカソン YANS運営委員特別賞
* 川柳ハッカソン YANS運営委員特別賞
シンポジウムの様子
1日目(2023/9/4)
シンポジウム1日目には言語処理学会30周年記念事業として留学交流会と分野交流ハッカソンが開催されました。 留学交流会では登壇者の相田さんと永田さんより在外研究や短期留学のtipsについてご講演いただきました。 ハッカソンではOpenAI APIを利用した,大喜利ハッカソンと川柳ハッカソンを行いました。 大喜利ハッカソンでは,3タイプ,具体的にはimage to text, text to text, image & text to textに対していい感じにボケるシステムの構築, 川柳ハッカソンでは,2タイプ,image to text, text to textに対してユニークな5・7・5の川柳の生成に取り組みました。 東北大の横井祥さん、SB Intuitionsの品川政太朗さん・清野舜さんの豪華三銃士をお招きし,アドバイスや評価をしていただきました。
2日目(2024/9/5)
今年のシンポジウムは411名という多くの方々にご参加いただきました。 国立情報学研究所の佐藤さんによるニューラルネットワークの損失地形に関するチュートリアルやポスター発表に加え,ラウンドテーブルやスポンサーセッション,YANSスペシャルセッションなど多くの企画が行われました!
3日目(2024/9/6)
3日目のチュートリアルでは,Turing株式会社の荒居さんより生成AIの二大潮流と自動運転についてご発表していただきました。 3日目も2日目に引き続き,多くのポスター発表があり,各所で熱心に研究の議論が交わされる場面が見られました。 目指せ国際会議!セッションでは,国際会議参加経験のあるさまざまな年代の方にライトニングトークをしていただきました。 また招待セッションでは,自然言語処理や音声,画像,人文・社会学分野で活躍されている若手研究者/技術者の方々にご自身の研究について発表していただきました。
統計データ
参加登録数の推移
2年連続の現地開催となりましたが,411名と数多くの方にご参加いただきました。 また,今年の参加者全体における学生・社会人の割合は同程度となりました。

参加登録者数の推移
発表件数の推移
今年は昨年より45件多い185件の発表がありました。これまでのシンポジウムにおいて過去最多の発表件数です。
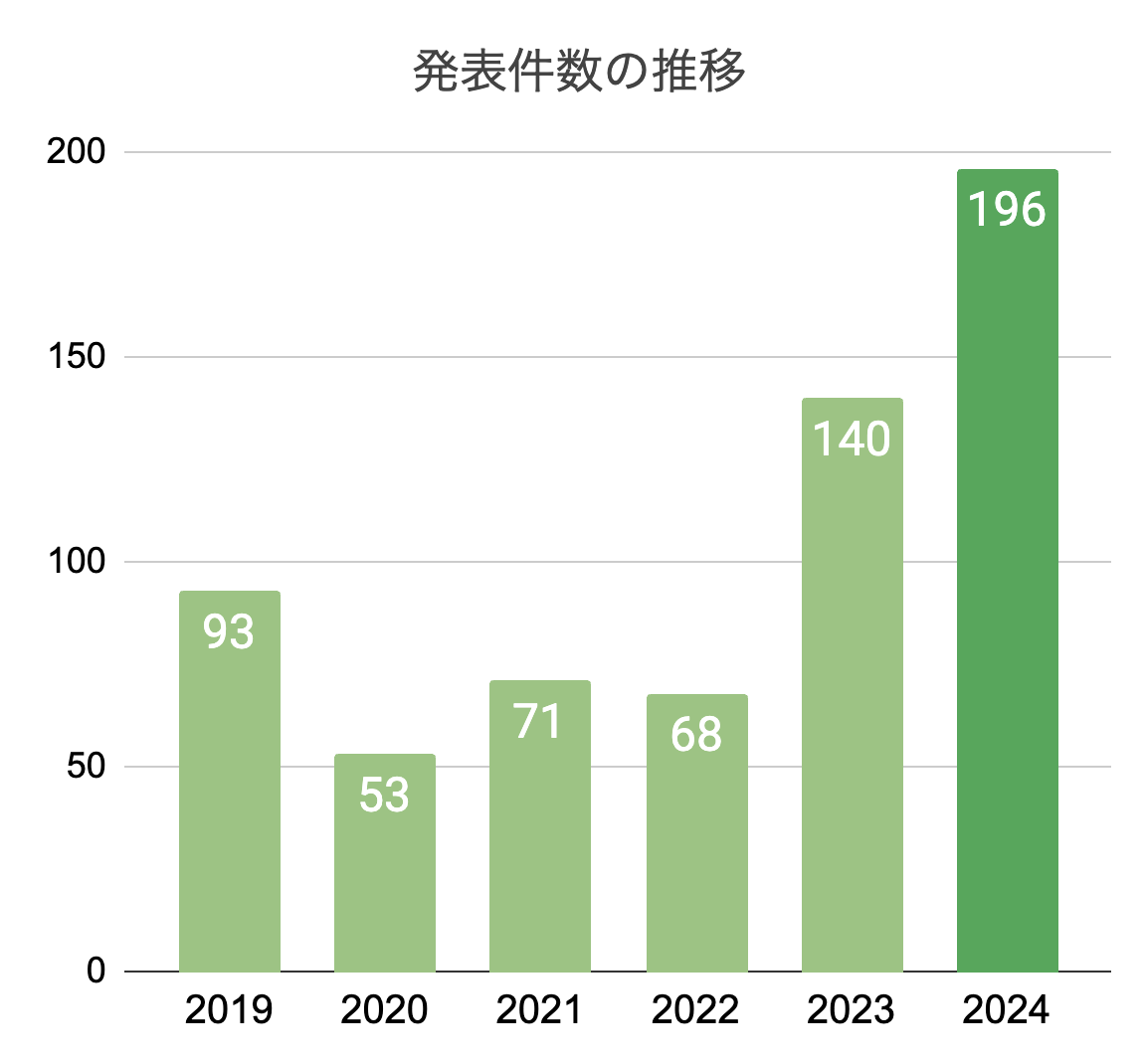
発表件数の推移
発表者の内訳
185件の発表のうち,学生は161件(全体の約8割),社会人は35件(全体の約2割)の発表がありました。
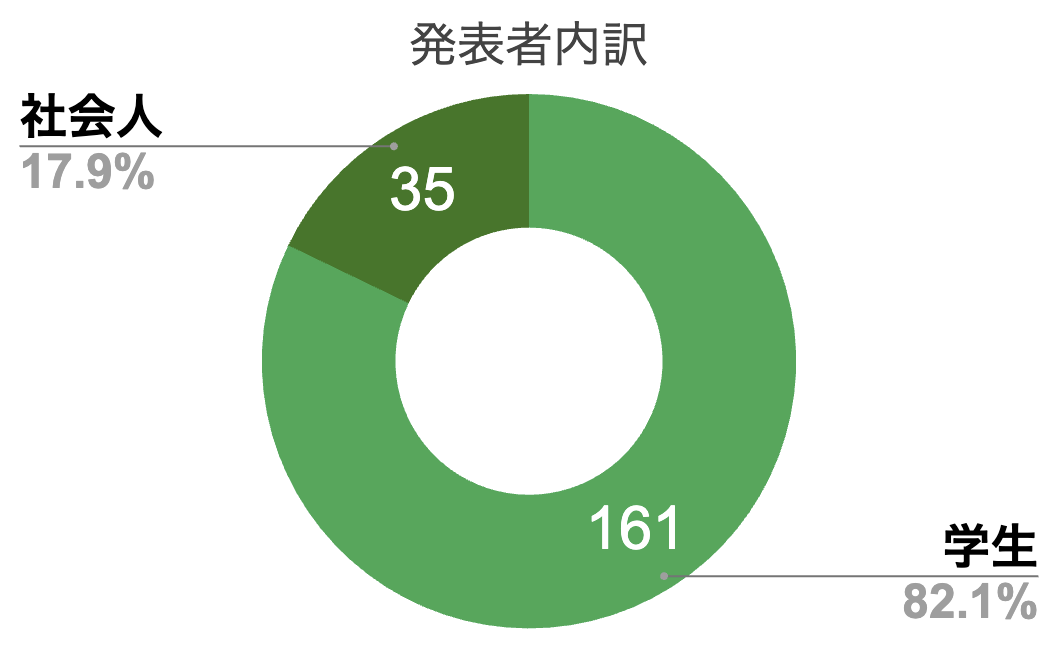
発表者の内訳
参加報告ブログの紹介
今回のシンポジウムにご参加いただいた多くの方からも参加報告ブログを書いて頂きました。 ぜひ、学生や企業の方など様々な参加者の皆さまが本シンポジウムで感じた生の感想やレポートもあわせてご覧ください。
発表資料等
オープニング・クロージング
オープニング資料
クロージング資料
チュートリアル
佐藤 竜馬 氏 (国立情報学研究所):ニューラルネットワークの損失地形
荒居 秀尚 氏 (Turing株式会社):生成AIの二大潮流と自動運転
招待セッション
| タイトル | 発表者 | 資料 |
|---|---|---|
| 難解な数値データを分かりやすく説明する言語生成技術の最前線と未来 | 石垣 達也 氏(産総研人工知能研究センター) | - |
| 人間らしい対話とは:非言語情報生成のための基盤モデル | 井上 昂治 氏(京都大学) | |
| Can AI entertain us? | 山西 良典 氏(関西大学) | |
| 日本語事前学習向けベンチマーク | 今城 健太郎 氏(Preferred Networks) | |
| 人文学と言語処理・知識処理 | 大向 一輝 氏(東京大学) | - |
| 企業でつくる、大規模言語モデル | 清野 舜 氏(SB Intuitions) | - |
| End-to-End音声基盤モデル | 小島 熙之 氏(Kotoba Technologies, Inc.) | - |
| 視覚と言語の対応ずれ問題とその解決に向けて | 品川 政太朗 氏(SB Intuitions) | |
| LLM時代の評価研究とその周辺 | 菅原 朔 氏(国立情報学研究所) | |
| Mechanistic Interpretability: 大規模言語モデル時代における自然言語処理と認知科学の交差点 | 高木 優 氏(国立情報学研究所/JST/大阪大学/情報通信研究機構) | - |
| 発話内容書き起こしを越えて音声と言語を結びつけたい | 高道 慎之介 氏(慶應義塾大学/東京大学) | - |
| クラウドソーシングとAI文字認識を駆使した「くずし字」資料の大規模テキスト化 | 橋本 雄太 氏(国立歴史民俗博物館) | |
| 形を通して意味を知る | 横井 祥 氏(東北大学/理化学研究所) | |
| 人・ロボットの移動と大規模言語モデルの接点 | 米谷 竜 氏(サイバーエージェント) | - |
| 人々の健康に資するソーシャルコンピューティング | 若宮 翔子 氏(奈良先端科学技術大学院大学) |
目指せ国際会議!
| タイトル | 発表者 | 資料 |
|---|---|---|
| ネットワーキングの極意(国際会議編) | 相田太一 氏(東京都立大学) | link |
| あぶない国際会議 | 塚越 駿 氏(名古屋大学) | link |
| はじめての国際会議~他分野編~ | 古橋 萌々香 氏(東北大学) | |
| はじめての国際会議 | 加藤 大地 氏(東京大学) | |
| ある修士学生のYANSからACLへの道のり | 赤間 怜奈 氏(東北大学/理化学研究所) | |
| 国際会議でやるべきこと3選 | 森下 睦 氏(フューチャー株式会社) |
ハッカソン
ハッカソンの概要
大喜利ハッカソン
| チーム名 | 発表資料 |
|---|---|
| チーム1 (笑いのアルゴリズム) | |
| チーム2 (YanG) | |
| チーム3 (AIPPON GRAND PRIX) | |
| チーム4 (f"{チーム名}") | |
| チーム5 (たこ焼き大好きーズ) | |
| チーム6 (ボケもコードも仕込中) | |
| チーム7 (デジタル侍笑わせ隊) | |
| チーム8 (Say*2 Do*2) |
川柳ハッカソン
| チーム名 | 発表資料 |
|---|---|
| チームA (松尾芭蕉et al.) | - |
| チームB (Baseline B) | |
| チームC ("ダブルクォーテーション") | - |
| チームD (KEY=sk-teamD) | |
| チームE (サラリーマン-4o-mini) | - |
| チームF (えふ) | |
| チームG (thymz (タイムズ)) | - |
| チームH (INT) |
受賞者
本シンポジウムでは全185件の発表に対して,1件のデモ賞,23件の奨励賞,19件のスポンサー賞が授与されました。 また分野交流ハッカソンでは,大喜利ハッカソンと川柳ハッカソンにおいて2件の優秀賞,2件の審査員特別賞,2件のYANS運営委員特別賞が授与されました。
デモ賞 (対象15件中1件)
- 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
◯ 出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研)
奨励賞 (対象187件中23件)
- 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
◯ 小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研) - 不均衡最適輸送を用いた意味変化検出
◯ 岸野 稜 (京大), 山際 宏明 (京大), 永田 亮 (甲南大/理研), 横井 祥 (東北大/理研), 下平 英寿 (京大/理研) - 学習過程における重みのマージによるモデル最適化
◯ 渡邉 一功 (早大), 河原 大輔 (早大) - 「インプレゾンビ」検出のためのデータセット構築と特徴分析
◯ 上原 慧大 (横国大), 村山 太一 (横国大) - ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
◯ 加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV) - 強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
◯ 齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - 「ふわふわ」「もったり」ってどう表現するの? ーエージェントとの豊かなコミュニケーションの実現に向けてー
◯ 肥田 京佳 (愛工大), 市川 淳貴 (愛工大), 徳久 良子 (愛工大) - 構成的汎化におけるTransformerの内部機序の分析
◯ 九門 涼真 (東大), 谷中 瞳 (東大) - LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大) - マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
◯ 尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 大規模言語モデルによる読"舌"術
◯ 坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
◯ 北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - 人間とLLMが考える"面白い”は一致するのか?
◯ 坂部 立 (一橋大), 金 輝燦 (都立大), 小町 守 (一橋大) - LLMは真面目・不真面目になれるか?
◯ 堀尾 海斗 (早大), 河原 大輔 (早大) - 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
◯ 山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研) - Multilingual LLM への指示文は本当に英語であるべきなのか?
◯ 榎本 大晟 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 小町 守 (一橋大) - Attentionに基づく大規模言語モデルのHallucination検出手法の検討
◯ 小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - 大規模言語モデルにおける相転移と自然言語の関係
◯ 中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大) - 日本語に特化した汎用テキスト埋め込みモデルの開発
◯ 塚越 駿 (名大), 笹野 遼平 (名大) - 言語モデルの日本語道徳理解能力の評価データセットの構築
◯ 竹下 昌志 (北大), ジェプカ ラファウ (北大) - ゲームの台詞を題材としたキャラクターらしさを構成する要素の検討
◯ 岩田 伸治 (サイバーエージェント), 伊原 滉也 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 馬場 惇 (サイバーエージェント), 邊土名 朝飛 (サイバーエージェント), 山﨑 眞洋 (QualiArts), 塩塚 勇気 (QualiArts), 吉本 暁文 (サイバーエージェント) - 自動運転のための言語・視覚・動作の統合データセットの構築
◯ 三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - 質問の言語表現が大規模言語モデルの回答傾向に与える影響の調査
◯ 高山 隼矢 (SB Intuitions), 大萩 雅也 (SB Intuitions), 水本 智也 (SB Intuitions), 吉川 克正 (SB Intuitions)
スポンサー賞 19件
サイバーエージェント賞
- 強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
◯ 齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大)
本研究は、LLMが生成したテキストの検出器を開発する中で、LLM自体を検出器に合わせるように学習する手法を提案しています。より強力な検出器の開発や、LLMの入力への文書透かしの挿入が主流の中で、本提案手法は、新規性があり、教育的なLLMとして有用であると感じました。弊社は独自のLLMを開発していますが、その開発過程で検討する価値の高い内容だと判断し、スポンサー賞に選定しました。 - チェックリストを利用した生成系タスクの網羅的評価
◯ 古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII)
本研究は、LLMを用いて、生成系タスクにおける網羅的な性能評価指標のリストアップと各指標に対するチェックリストの作成を行い、それを元に評価するフレームワークを提案しています。弊社の行なっている広告生成などのクリエイティブなテキスト生成にもそのまま適用でき、すぐに使ってみたいと思える方法でした。今後さらに堅牢で汎用性の高い評価フレームワークとなる期待を込めて、スポンサー賞に選定しました。
フューチャー株式会社賞
- 日本語の単語を対象とした複数時期の意味変化パターン分析
◯ 木山 朔 (都立大), 相田 太一 (都立大), 小町 守 (一橋大), 小木曽 智信 (国語研), 高村 大也 (産総研), 持橋 大地 (統数研)
本研究は日本語の単語の意味や使われ方が年代とともにどのように変化したのかを分析する手法を提案しています。 意味変化の仕方をクラスタリングすることで、コロナ禍で使われ方が変わった単語のグループが表出するなど興味深い結果が得られており、今後の発展に期待が持てます。 また、聴講者からの質問に対する補足資料の提示をタブレットを用いて行うなど、発表に対する十分な準備ができている点も高く評価しました。
SB Intuitions株式会社賞
- チェックリストを利用した生成系タスクの網羅的評価
◯ 古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII)
LLM as a Judgeでよく用いられる5段階ラベルでの評価には、評価基準の曖昧さや評価結果の解釈の困難さなど扱いづらい点があります。 本研究ではクエリごとに複数の評価軸とその評価基準となるチェックリストを半自動付与することで上記課題の解決を試みています。 弊社を含め日本語LLM構築に携わる者にとって重要な課題に取り組まれており、今後の進展への期待と応援の意味も込めて選定させていただきました。
株式会社リクルート賞
- 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
◯ 出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研)
本研究は、クエリ検索と埋め込み検索両者の弱点を克服し、マッチ判定に出現位置を考慮した単語埋め込みの類似度を用いることで、文字通りsoftgrepを実現する検索手法を提案しています。 弊社では、さまざまなサービスのレコメンドでテキストデータを扱っており、そこでは大量のテキスト群に対して用例検索を行っています。提案された手法の有用性と高速に動作する実用性を評価し、スポンサー賞に選定させていただきました。
日本経済新聞社日経イノベーション・ラボ賞
- 語順に制約されない大規模言語モデルの知識編集
◯ 石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大)
本研究では,英語をはじめとするSVO言語を前提とした大規模言語モデルの知識編集の既存手法を拡張し,任意の語順の言語に適用可能とした手法を提案しています.弊社では独自の大規模言語モデルの構築に取り組む上で経時変化する関係知識への対処が課題となっており,語順の制約を外す提案手法の発想や日本語での実験結果に大きな有用性を感じました.今後の更なる発展への期待も込めて,スポンサー賞に選定しました.
株式会社PKSHA Technology賞
- 日本語に特化した汎用テキスト埋め込みモデルの開発
◯ 塚越 駿 (名大), 笹野 遼平 (名大)
シェルパ・アンド・カンパニー賞
- LLMを用いた自由記述アンケートの質的分析
◯ 橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST)
株式会社エクサウィザーズ賞
- 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
◯ 佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大)
有価証券報告書のテーブルデータには重要な情報が含まれています。本研究では表に関するタスクデータの自動作成手法の提案しています。本手法を活用して作成したデータをShared Taskとして公開しており、他者でも利用可能かつ発展が期待されます。また我が社でもIRに関するプロダクトをリリースしており、この研究には今後とも注視していきたいと思い、スポンサー賞として選ばせていただきました。
株式会社マネーフォワード賞
- 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
◯ 山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研)
本研究では、言語の意味的・統語的な特徴を潰したコーパスでBERTの学習を行い、各特徴の獲得に必要な固有次元の測定を試みています。言語モデルの小規模化につながる観察であり、かつ学習前のモデルでも似た固有次元の傾向が見られたことは純粋に興味深いと感じます。 また発表を通して、実験を丁寧に繰り返して結果を比較していることが伝わってきました。こういった姿勢も大変評価できるものと思います。
株式会社オルツ賞
- LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大)
株式会社ELYZA賞
- Attentionに基づく大規模言語モデルのHallucination検出手法の検討
◯ 小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大)
本研究は、注意機構の挙動に基づきLLMの幻覚検出を行う手法を提案しています。モデルの内部状態に着目する本手法はローカルLLMの優位性に寄与する可能性があり、自社でLLMを開発している弊社としても注目したい技術と判断いたしました。また、手法が直感的かつシンプルであることと、その発展性について参加者間で意見が飛び交う当日の様子から将来性を評価いたしました。
Aww, Inc.賞
- 大規模言語モデルによる11種類の日本語スタイル変換の性能評価
◯ 花房 健太郎 (愛媛大), 柳本 大輝 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大)
株式会社博報堂テクノロジーズ賞
- 言語モデルは人々の意見分布をどのように予測するか
◯ 鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
ストックマーク株式会社賞
- LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
◯ 進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大)
弊社では、ビジネスドメインの専門知識を扱うLLMの開発を行っており、特定ドメインの知識の内挿や外挿について重要視しています。 本研究は、四則演算という限定的なデータを用いてLLMの外挿の可能性を実験されていて、弊社との関わりが強いなと感じました。また、実験設計が丁寧なだけでなく、attentionの当たり方が内挿と外挿で異なるという分析までされていて、非常に有用性の高い研究だと思います。
株式会社IVRy賞
- Text-to-audioにおける評価指標CLAP-Scoreの性能分析
◯ 高野 大成 (東大), 岡本 悠希 (東大), 齋藤 佑樹 (東大)
Spiral.AI株式会社賞
- LLMの"衝突回避" : LLMと制御理論の融合
◯ 宮岡 佑弥 (慶應大), 井上 正樹 (慶應大)
Turing株式会社賞
- 大規模視覚言語モデルの潜在的バイアスを利用した幻覚の抑制方法の提案
◯ 大平 颯人 (一橋大), 平澤 寅庄 (OSX), 小町 守 (一橋大)
Visual Contrastive DecodingとDirect Preference Optimizationを組み合わせ、効率的に画像の明暗やガウスノイズの強さを調整することで、大規模視覚言語モデルのハルシネーションを軽減する新たな手法を提案しています。さらに、多腕バンディットアルゴリズムを用いることで、これらの調整を最適化し、より少ない試行で高い精度を達成している点を評価しました。
株式会社日立製作所賞
- 指示数増加による大規模言語モデルの指示追従性能への悪影響
◯ 原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大)
ハッカソン賞
大喜利ハッカソン 優秀賞
- チーム8 - Say*2 Do*2
大塚晴貴(愛工大), 高橋利孔(はこだて未来大), 宮岡佑弥(慶應大), 峯悠大(NAIST), 塚越柚季(東大), 櫻井亮佑(日経新聞社)
川柳ハッカソン 優秀賞
- チームB - Baseline B
高橋侑成(東工大), 岩國巧(NAIST), 加藤大地(東大), 塩野大輝(東北大), 辻󠄀航平(NAIST), 高山隼矢(SB Intuitions)
大喜利ハッカソン 審査員特別賞
- チーム3 - AIPPON GRAND PRIX
李宰成(東北大), 進藤稜真(北大), 鈴木刀磨(NAIST), 吉見菜那(愛媛大), 髙城頌太(東大), 高橋洸丞(Stockmark)
川柳ハッカソン 審査員特別賞
- チームF - えふ
福島啓太 (愛媛大), 森江梨花 (慶應大), 武内樹治(奈良文化財研究所), 郷原聖士(NAIST), 稲岡夢人(Faber Company)
大喜利ハッカソン YANS運営委員特別賞
- チーム6 - ボケもコードも仕込中
山口真(静岡大), 岩川光一(東北大), 大平颯人(一橋大), 齋藤大輔(名工大), 斉志揚(電通大), 稲原宗能(PKSHA)
川柳ハッカソン YANS運営委員特別賞
チームG - thymz (タイムズ)
朱灏丞(東北大), 守山慧(東大), 服部翔(東工大), 樽本空宙(愛媛大), 山口智之(村田製作所)
更新履歴
- 2024/08/13: プログラム詳細を公開しました
- 2024/07/09: 招待セッションの情報を公開しました
- 2024/07/01: チュートリアルの情報を公開しました
- 2024/06/03: 暫定プログラムを公開しました
9/4(水): シンポジウム1日目 @梅田スカイビル Tower WEST 36F 「スペース36L」
[10:30-11:00] 受付 (留学交流会)
[11:00-12:00] 留学交流会
昨年に引き続きシンポジウム1日目の 9月4日(水)に留学交流会を行います。海外の大学などで、研究を行う際のtipsを紹介する講演会を行います。今回は、半年程度の比較的短期間の留学と既に職を得た若手向け在外研究についても紹介します。また、講演後に留学を考えている人と留学経験者との交流の場を提供します。講師として、東京都立大の相田さんと甲南大学の永田さんをお招きします。
登壇者: 相田 太一 氏 (東京都立大学) タイトル: 学生のための短期留学概要: 本発表では、成長するための一つのきっかけとしての海外留学について、最近留学した実体験をもとにお話しします。内容としては、留学前に必要な準備や心構え、リモート可能な情報系で留学を選ぶ理由、そして帰国後の研究への影響などを予定しています。これから留学を考えている方や、成長の機会を求めている方にとって、参考になるような情報をお届けできればと思います。
登壇者: 永田 亮 氏 (甲南大学) タイトル: 研究者キャリア初段階以降における在外研究概要: 言語処理学会30周年記念事業一環として、昨年、今年と留学支援交流会を開催しています。これまでは、主に、修士課程、博士課程の学生さんを対象にして留学に関する情報を提供してきました。本講演では、少し対象を広げて、博士研究員、助教など研究者としてのキャリアをスタートして数年以降の方を主に対象として海外で研究活動を行うための情報を提供します。例えば、学生ビザと研究者ビザの違いや取得に関してお話しします。また、英語圏以外の国での留学についてもお話しします。その過程で、学生さんにも有益な情報が提供できればと思います。
[12:30-13:00] 受付 (ハッカソン)
[13:00-20:00] YANS分野交流ハッカソン with 言語処理学会30周年記念事業
言語処理学会30周年記念事業の一環として、シンポジウム1日目の9月4日(水)に分野交流ハッカソンを開催します。自然言語処理の周辺分野(画像・音声処理など)をはじめ、人文・社会学分野も含めた幅広い分野の学生・社会人の交流を促進することが目的のひとつです。 今年のハッカソンでは、マルチモーダルデータを用いたテキスト生成リーダーボードを開催します。画像やテキストで与えられたお題に対して、機転が利いた回答を生成するタスクとなっております。 生成テキストの質などのいくつかの観点から評価し、優秀なチームを表彰します。自動評価・ハッカソン参加者の人手評価のほか、東北大の横井祥さん、SB Intuitionsの品川政太朗さん・清野舜さんの豪華三銃士による評価をします。 詳細はハッカソンのページをご確認ください。
第19回YANSシンポジウム YANS分野交流ハッカソン with 言語処理学会30周年記念事業 - YANS
9/5(木): シンポジウム2日目 @梅田スカイビル Tower WEST 10F 「アウラホール」
[09:30-10:00] 開場
[10:00-10:30] オープニング
[10:30-11:30] チュートリアル(1) 「ニューラルネットワークの損失地形」
 講演者: 佐藤 竜馬 氏 (国立情報学研究所) 概要: ニューラルネットワークの損失地形とは、パラメータ空間での損失関数の形状のことです。損失地形には、ニューラルネットワークの汎化性能や推論法則など、多くの情報が含まれていることが分かっています。このような損失地形に関する理論は近年人気を集めているモデルマージの基礎にもなっています。本講演では、平坦性、腑落ち、宝くじ仮説、モデルマージなど、損失地形にまつわる基本的な概念を紹介します。参考:佐藤竜馬『深層ニューラルネットワークの高速化』技術評論社
講演者: 佐藤 竜馬 氏 (国立情報学研究所) 概要: ニューラルネットワークの損失地形とは、パラメータ空間での損失関数の形状のことです。損失地形には、ニューラルネットワークの汎化性能や推論法則など、多くの情報が含まれていることが分かっています。このような損失地形に関する理論は近年人気を集めているモデルマージの基礎にもなっています。本講演では、平坦性、腑落ち、宝くじ仮説、モデルマージなど、損失地形にまつわる基本的な概念を紹介します。参考:佐藤竜馬『深層ニューラルネットワークの高速化』技術評論社
略歴: 1996年生まれ。2024年京都大学大学院情報学研究科博士課程修了。博士(情報学)。現在、国立情報学研究所 助教。専門分野は最適輸送、グラフニューラルネットワーク、および情報検索・推薦システム。PDF翻訳サービスReadableの開発など研究の効率化についても従事している。著書に『深層ニューラルネットワークの高速化』技術評論社、『グラフニューラルネットワーク』『最適輸送の理論とアルゴリズム』講談社がある。
[11:40-12:40] ポスターセッション (1)
トピック別の発表一覧はこちら第19回YANSシンポジウム ポスターセッション トピック別索引 - YANS
- [S1-P01] 四方向投影システムを用いた子どもたちの協働による「学びの質」の評価方法の検討
長谷川 騎平 (愛工大), 増井 辰真 (愛工大), 徳久 良子 (愛工大) - [S1-P02] 四方向投影システムを用いた「協働なぞなぞゲーム」のためのクイズ自動生成に向けて
増井 辰真 (愛工大), 長谷川 騎平 (愛工大), 徳久 良子 (愛工大) - [S1-P03] NLP J Anthology BTPPコーパス: 自然言語処理分野の論文調査支援を目的とした英日翻訳後処理コーパスの作成
中町 礼文 (janthology.jp), 西原 大貴 (janthology.jp) - [S1-P04] Vision And Languageモデルにおける異なるドメインでの継続事前学習が後段タスクに与える影響の検証
齋藤 慎一朗 (Sansan) - [S1-P05] 物語生成タスクにおける埋め込みを用いたLLMの創造性評価
福田 創 (早大), 河原 大輔 (早大) - [S1-P06] プライベート空間における人-エージェント間雑談対話データセットの構築に向けて
邊土名 朝飛 (サイバーエージェント), 岩田 伸治 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 稲本 雄太 (サイバーエージェント), 栗原 健太郎 (AI Shift) - [S1-P07] 大規模言語モデルによる機械翻訳の教師なし品質推定
樽本 空宙 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P08] 問題タイプを考慮した教師あり学習による英単語穴埋め問題の自動生成
吉見 菜那 (愛媛大), 梶原 智之 (愛媛大), 内田 諭 (九大), 荒瀬 由紀 (東工大), 二宮 崇 (愛媛大) - [S1-P09] 大規模言語モデルの継続事前学習における学習率設定の検討
朱 灏丞 (東北大), 李 宰成 (東北大), 岩川 光一 (東北大), 内藤 悠 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 彗音 (東北大/理研), 木村 昴 (東北大), 葉 夢宇 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S1-P10] 不均衡最適輸送を用いた意味変化検出
岸野 稜 (京大), 山際 宏明 (京大), 永田 亮 (甲南大/理研), 横井 祥 (東北大/理研), 下平 英寿 (京大/理研) - [S1-P11] 構成的汎化におけるTransformerの内部機序の分析
九門 涼真 (東大), 谷中 瞳 (東大) - [S1-P12] 既読文書の関係を考慮できる関係抽出
松原 拓磨 (豊田工大), 三輪 誠 (豊田工大) - [S1-P13] 言語の逐次性に普遍的性質はあるか?:parsing strategyの最適性からの分析
石井 太河 (東大), 宮尾 祐介 (東大) - [S1-P14] 日本手話における検索や解析のための柔軟な表現の獲得
井上 純大 (豊田工大), 原 大介 (豊田工大), 三輪 誠 (豊田工大) - [S1-P15] 事前学習–文脈内学習パラダイムで生じる頻度バイアスの較正
伊藤 郁海 (東北大), 鴨田 豪 (東北大), 熊谷 雄介 (博報堂DYホールディングス), 横井 祥 (東北大/理研) - [S1-P16] 学習過程における重みのマージによるモデル最適化
渡邉 一功 (早大), 河原 大輔 (早大) - [S1-P17] ゲームの台詞を題材としたキャラクターらしさを構成する要素の検討
岩田 伸治 (サイバーエージェント), 伊原 滉也 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 馬場 惇 (サイバーエージェント), 邊土名 朝飛 (サイバーエージェント), 山﨑 眞洋 (QualiArts), 塩塚 勇気 (QualiArts), 吉本 暁文 (サイバーエージェント) - [S1-P18] 児童の読解力向上を目的とした音読支援システムの開発
齊藤 新 (東京理科大), 松崎 拓也 (東京理科大) - [S1-P19] 豪雨と地震におけるクロノロジーの優先度推定
孝壽 真治 (岡山大), 竹内 孔一 (岡山大), 渡邉 暁洋 (兵庫医科大), 平山 隆浩 (岡山大), 中尾 博之 (大阪行岡医療大) - [S1-P20] 英語データセットを使ったRLHFは日本語LLMの常識道徳にどのような影響を与えるか?
陣内 佑 (サイバーエージェント) - [S1-P21] 大規模言語モデルを用いたオノマトペ付与による日本語音声データセットの拡張
小川 剛毅 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S1-P22] メンバーシップ推論攻撃によるLLMの失言しやすさの評価
丹波 光 (日本女子大), 小柳 響子 (日本女子大), 伊東 和香 (日本女子大), 倉光 君郎 (日本女子大) - [S1-P23] 強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P24] WordNetは現代英語話者の意味関係知識の反映しているか?:クラウンドソーシングによる一致度の調査
Cao Zhihan (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大) - [S1-P25] 大規模言語モデルによる日本文化に沿った指示データ生成
塩谷 泰平 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P26] 潜在拡散モデルによる画像生成における対象の配色制御による改善の試み
永井 大地 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S1-P27] 商品検索のための追加事前学習としての言い換えに基づく対照学習
杉山 誠治 (愛媛大), 近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P28] マルチモーダルモデル自動評価のための複数タスク・複数基準評価データセット
大井 聖也 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大), 井上 中順 (東工大) - [S1-P29] 教師なし条件付きテキスト埋め込みの獲得
山田 康輔 (サイバーエージェント), 張 培楠 (サイバーエージェント) - [S1-P30] 雑談対話システムにおけるユーモア応答生成
佐藤 光 (芝浦工大), 杉本 徹 (芝浦工大) - [S1-P31] 映像中の情報に基づくマルチモーダルベースの視聴者感情推定
呉 清源 (工学院大), 福田 一帆 (工学院大) - [S1-P32] 医療事故内容から背景・原因、および改善策を生成する為のデータセット構築
長谷山 優菜 (北大), 伊藤 友貴 (三井物産), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S1-P33] RAGにおけるLLMの性能の影響
阿部 晃弥 (茨大), 新納 浩幸 (茨大) - [S1-P34] 大規模言語モデルによる読"舌"術
坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S1-P35] 大規模モデルの蒸留を用いた日本語文埋め込みモデル
矢野 千紘 (PKSHA), 呉 孟超 (PKSHA), 橘 秀幸 (PKSHA), 竹川 洋都 (PKSHA), 渡邉 陽太郎 (PKSHA) - [S1-P36] 現代LLMは日本語の語用論を分かるのか?
ガンバルデッラ アンドリュー (東大) - [S1-P37] 日本語医療LLM評価ベンチマークの構築と性能分析
福島 拓也 (NAIST), 久田 祥平 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S1-P38] 指示数増加による大規模言語モデルの指示追従性能への悪影響
原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大) - [S1-P39] 大規模視覚言語モデルの謎解き能力調査
臼井 久生 (東京農工大), 木山 朔 (都立大), 古宮 嘉那子 (東京農工大) - [S1-P40] 言語モデルは人々の意見分布をどのように予測するか
鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[12:40-14:00] 昼休憩
[14:00-15:00] ポスターセッション (2)
トピック別の発表一覧はこちら第19回YANSシンポジウム ポスターセッション トピック別索引 - YANS
- [S2-P01] 「ふわふわ」「もったり」ってどう表現するの? ーエージェントとの豊かなコミュニケーションの実現に向けてー
肥田 京佳 (愛工大), 市川 淳貴 (愛工大), 徳久 良子 (愛工大) - [S2-P02] 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研) - [S2-P03] 日常会話を通じて心の健康を支援するヴァーチャルエージェントの試作
泉 健太 (SB Intuitions), Liu Lianbo (SB Intuitions), 大萩 雅也 (SB Intuitions), 山崎 天 (SB Intuitions) - [S2-P04] 大規模言語モデルの事前学習ツールjax-llmの開発とinput-methodへの応用
杉浦 一瑳 (京大) - [S2-P05] LLMを用いた自由記述アンケートの質的分析
橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST) - [S2-P06] Multilingual LLM への指示文は本当に英語であるべきなのか?
榎本 大晟 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 小町 守 (一橋大) - [S2-P07] 強化学習に基づく難易度制御を組み込んだ多肢選択式読解問題自動生成手法の開発
富川 雄斗 (電通大), 宇都 雅輝 (電通大) - [S2-P08] 大規模言語モデルの説明文生成能力における忠実性改善の試み
土井 智暉 (東大), 磯沼 大 (東大/エディンバラ大), 谷中 瞳 (東大) - [S2-P10] 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研) - [S2-P11] 拡散モデルを用いたシーングラフベースの画像編集
森 江梨花 (慶應大), 渡邊 偉志 (パナソニックコネクト), 藤松 健 (パナソニックコネクト), 嘉本 海大 (パナソニックコネクト), 青木 義満 (慶應大) - [S2-P12] データセット共有基盤を用いた参加型コードLLM開発の提案
伊東 和香 (日本女子大), 小原 有以 (日本女子大), 西潟 優羽 (日本女子大), 佐藤 美唯 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S2-P13] 画像特徴ベクトルは重みを固定した言語モデルで情報豊かなトークンである
加藤 万理子 (JAIST), 趙 羽風 (JAIST), 閻 真竺 (JAIST), 石 钰婷 (JAIST), 井之上 直也 (JAIST/理研) - [S2-P14] 対照デコーディングを用いたマルチトークン予測モデルの精度向上
髙城 頌太 (東大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大) - [S2-P15] 語順に制約されない大規模言語モデルの知識編集
石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S2-P16] A Closer Look at Task Analogies: Insights from Function and Parameter Space
吉田 晃太朗 (東工大), 楢木 悠士, 山木 良輔 (立命館大/ProPlace), 堀江 孝文 (立命館大), 清水 良太郎 (ZOZO研究所/カリフォルニア大), 斎藤 侑輝 (ZOZO研究所), 長沼 大樹 (モントリオール大/Mila/ProPlace) - [S2-P17] おやつプロジェクト: おすすめスイーツ店の個人レビュー要約
岩本 蘭 (IBM/慶應大), 大内 啓樹 (NAIST/サイバーエージェント), 金山 博 (IBM), 吉田 光男 (筑波大) - [S2-P18] オンライン動画サービスにおけるBERT及び大規模言語モデルを用いた視聴者感情の推定
菅野 祐希 (工学院大), 坂野 遼平 (一橋大) - [S2-P19] テキストおよびSNSデータを活用したフェイクニュース検出に関する検討
沈 瑋彦 (工学院大), 坂野 遼平 (一橋大) - [S2-P20] In-model anti-expertによる大規模言語モデルのハルシネーション抑制
門谷 宙 (NTT), 西田 光甫 (NTT), 西田 京介 (NTT), 齋藤 邦子 (NTT) - [S2-P21] LLMを用いた生成による階層的イベントの抽出
金児 一矢 (豊田工大), 三輪 誠 (豊田工大) - [S2-P22] 知識蒸留モデルと合意をとる頑健な行列補完を用いた高速な確率的最小ベイズリスク復号法
夏見 昂樹 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S2-P23] 敵対的学習を用いた記号的知識蒸留
日浦 隆博 (NAIST/理研), 河野 誠也 (理研/NAIST), Garcia Contreras Angel Fernando (理研), 吉野 幸一郎 (東工大/理研/NAIST) - [S2-P24] 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大) - [S2-P25] 大規模言語モデルにおけるチェックポイント平均法の有効性
岩川 光一 (東北大), 内藤 悠 (東北大), 朱 灏丞 (東北大), 李 宰成 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 慧音 (東北大/理研), 葉 夢宇 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S2-P26] ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV) - [S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討
伊原 滉也 (サイバーエージェント), 叶 穎睿 (サイバーエージェント), 田村 和範 (QualiArts), 岡 時生 (QualiArts), 水村 総之介 (QualiArts), 野村 将寛 (サイバーエージェント) - [S2-P28] 大規模言語モデルによる感情極性に着目した小説からの人物関係抽出
齋藤 大輔 (名工大), 李 晃伸 (名工大), 上乃 聖 (名工大) - [S2-P29] クローリングによるコモンクロールを補完した日本語コーパス拡充の検討
石原 慧人 (LINEヤフー), 永井 隆広 (LINEヤフー), 平田 航大 (LINEヤフー), 岸本 耀平 (LINEヤフー), 中野 佑哉 (LINEヤフー) - [S2-P30] ユーザの発話からの自我状態推定を用いた対話システムの検討
掛川 脩人 (東京電機大), 山田 剛一 (東京電機大), 増田 英孝 (東京電機大) - [S2-P31] 土木分野におけるRAGの実用化課題の整理と精度向上へ向けた検討
緒方 陸 (八千代エンジニヤリング), 岡野 将大 (八千代エンジニヤリング), 大久保 順一 (八千代エンジニヤリング), 藤井 純一郎 (八千代エンジニヤリング) - [S2-P32] 社会的価値観の融和を誘導する対話システムの開発
小林 涼太郎 (東大), 高柳 剛弘 (東大), 鈴木 雅弘 (東大), 小倉 有紀子 (北大), 坂地 泰紀 (北大) - [S2-P33] Phase Diagram of Vision Large Language Models Inference: A Perspective from Interaction across Image and Instruction
WEI Houjing (JAIST), SHI Yuting (JAIST), Cho Hakaze (JAIST), YAN Zhenzhu (JAIST), 井之上 直也 (JAIST/理研) - [S2-P34] 大規模言語モデルによる日本語テキスト平易化のためのパラレルコーパスフィルタリング
前川 大輔 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S2-P35] タスク特徴を考慮したマッチング制約下におけるアノテーション割り当て
守山 慧 (東大), 中山 功太 (NII), 馬場 雪乃 (東大) - [S2-P36] RAGを用いたLLMによる偽情報検出手法の検討
山田 美優 (東工大), 荒瀬 由紀 (東工大) - [S2-P37] X上の情報カスケードにおける情報変容のアノテーション
遠田 哲史 (東大), 吉永 直樹 (東大), 豊田 正史 (東大) - [S2-P38] 「インプレゾンビ」検出のためのデータセット構築と特徴分析
上原 慧大 (横国大), 村山 太一 (横国大) - [S2-P39] ヴェーダ語学・ヴェーダ文献学におけるRAGの活用
塚越 柚季 (東大) - [S2-P40] 人工知能ラッパーの実現に向けて
織田 宥楽 (早大), 小川 隼斗 (早大), 河原 大輔 (早大)
[15:15-16:15] スポンサーセッション
スポンサーの企業/団体における自然言語処理や関連分野の技術の活用事例などについてご紹介いただきます。
発表スポンサー一覧 (敬称略)
- 株式会社サイバーエージェント (ダイヤモンド)
- フューチャー株式会社 (プラチナ)
- SB Intuitions株式会社 (プラチナ)
- 株式会社リクルート (プラチナ)
- 日本経済新聞社日経イノベーション・ラボ (ゴールド)
- 株式会社 PKSHA Technology (ゴールド)
- シェルパ・アンド・カンパニー株式会社 (ゴールド)
- 株式会社エクサウィザーズ (ゴールド)
- 株式会社マネーフォワード (ゴールド)
- 株式会社オルツ (ゴールド)
- LINEヤフー株式会社 (ゴールド)
- 株式会社ELYZA (ゴールド)
- Aww, Inc. (ゴールド)
- 株式会社博報堂テクノロジーズ (ゴールド)
- ストックマーク株式会社 (ゴールド)
- 日本電信電話株式会社(NTT R&D) (ゴールド)
- 株式会社IVRy (ゴールド)
- Spiral.AI株式会社 (ゴールド)
- Turing株式会社 (ゴールド)
- 株式会社日立製作所 (ゴールド)
[16:30-17:35] ラウンドテーブル
参加者間の相互交流の場を提供するためにラウンドテーブルを実施します。これは、テーブルごとにトピックを決め、少人数で話をする企画です。組織や業種に関係なく、同じ興味を持った人たちとの気軽な交流を促進します。テーブルの割り当てを2回行い、様々な人と交流する機会を作ります。前半は「興味のある研究分野」、後半は「キャリア」についてお話ししながら交流していただきます。 また、ダイヤモンドスポンサー様の専用卓をご用意する予定です。
[17:50-18:50] ポスターセッション (3)
トピック別の発表一覧はこちら第19回YANSシンポジウム ポスターセッション トピック別索引 - YANS
- [S3-P01] 自己改善する辞書: Sustainable Dictionary Grooming system (SDGs)
大槻 優佳 (NAIST), 矢田 竣太郎 (NAIST), 西山 智弘 (NAIST), 工藤 紀子 (NAIST), 川端 京子 (NAIST), 藤牧 貴子 (NAIST), 永井 宥之 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P02] ラップの原則に基づく生成手法の検討
淡島 英輝 (ちゅらデータ) - [S3-P03] ユーザレビュー作成支援を目的とした対話システムの活用法の提案
田中 義規 (電通大), 稲葉 通将 (電通大) - [S3-P04] 大規模言語モデルと患者表現辞書を用いた病名予測の検証
宇都宮 和希 (工学院大), 坂野 遼平 (一橋大) - [S3-P05] 大規模言語モデルを用いた効果的な物語のあらすじ生成手法の検討
酒井 健壱 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S3-P06] 大規模言語モデルによるテキスト平易化における語彙レベルエラー検出の試み
WU XUANXIN (阪大), 荒瀬 由紀 (東工大) - [S3-P07] SelfCheckGPTはコードLLMの幻覚を見抜けるか?
前田 遥香 (日本女子大), 西潟 優羽 (日本女子大), 小柳 響子 (日本女子大), 佐藤 美唯 (日本女子大), 倉光 君郎 (日本女子大) - [S3-P08] Attentionに基づく大規模言語モデルのHallucination検出手法の検討
小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - [S3-P09] マルチエージェント協働による TRPG ゲームマスターの実現
箕成 侑音 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S3-P10] LLMの論理推論能力は図的表現の使用により改善するか:オイラー図つき三段論法データセットNeuBAROCOを用いた分析
安東 里沙子 (慶應大), 小関 健太郎 (東大/慶應大), 森下 貴允 (慶應大), 阿部 裕彦 (慶應大), 峯島 宏次 (慶應大), 岡田 光弘 (慶應大) - [S3-P11] 大規模言語モデルを用いた日本語テキスト要約の自動評価
安里 優真 (JAIST), 白井 清昭 (JAIST) - [S3-P12] Text-to-audioにおける評価指標CLAP-Scoreの性能分析
高野 大成 (東大), 岡本 悠希 (東大), 齋藤 佑樹 (東大) - [S3-P13] モデルマージによるタスクごとの性能変化の分析
瓦 祐希 (Fusic) - [S3-P14] 微分可能スタックを用いた言語創発
加藤 大地 (東大), 上田 亮 (東大), 宮尾 祐介 (東大) - [S3-P15] 大規模言語モデルによって医療テキストの固有表現処理はどこまで簡単になったか
西林 孝 (Ubie), 横井 祥 (東北大/理研) - [S3-P16] 透明性の高いハルシネーション判定手法の検討
長谷川 遼 (富士フイルムBI), 鷹合 基行 (富士フイルムBI) - [S3-P17] ステップごとの推論における情報補完のカテゴリ別分析
三浦 東子 (東北大), 谷口 雅弥 (理研), 坂口 慶祐 (東北大/理研), 乾 健太郎 (東北大/理研/MBZUAI) - [S3-P18] 障害言語モデルの「失語症らしさ」に対する標準失語症検査に基づく評価
森田 早織 (東大), 原田 宥都 (東大), 直江 大河 (昭和大), 前田 ありさ (東大), 沖村 宰 (昭和大), 大関 洋平 (東大) - [S3-P19] 平易化への_Task Arithmetic_の応用とその検証
小西 修平 (NHK) - [S3-P20] ノイズを含む日本語テキストデータにおける固有表現抽出手法の検証
尾城 奈緒子 (インテージ), 竹村 彰浩 (インテージ) - [S3-P21] 科学技術文献における知識グラフ補完を用いた効率的な知識グラフの作成
神野 倫行 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S3-P22] ESG情報抽出データセットの検討
赤部 晃一 (シェルパ・アンド・カンパニー), 前田 航希 (シェルパ・アンド・カンパニー/東工大), 栗田 修平 (NII), 小田 悠介 (シェルパ・アンド・カンパニー/NII) - [S3-P23] LLMによる項構造依存関係解析の検証: 読み時間・容認性判断データとの比較と認知モデリング
木村 一馬 (筑波大) - [S3-P24] チェックリストを利用した生成系タスクの網羅的評価
古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII) - [S3-P25] LLMを用いたCT読影レポートの撮影目的分類
峯 悠大 (NAIST), 西山 智弘 (NAIST), 谷 懿 (NAIST), 大竹 義人 (NAIST), 佐藤 嘉伸 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P26] 機械翻訳の評価指標における信頼度の評価
岩國 巧 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S3-P27] 学術論文におけるGraphical Abstract自動生成の初期検討
川田 拓朗 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S3-P28] 日本語に特化した汎用テキスト埋め込みモデルの開発
塚越 駿 (名大), 笹野 遼平 (名大) - [S3-P31] 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研) - [S3-P32] 画像とテキストの共通構造はV&Lモデルにいかなる形で埋め込まれているか
志子田 直輝 (NAIST), 横井 祥 (東北大/理研), 渡辺 太郎 (NAIST) - [S3-P33] 小規模で高性能なLLMのための高品質事前学習Webコーパスの構築
服部 翔 (東工大/産総研), 水木 栄 (東工大/産総研), 藤井 一喜 (東工大/産総研), 中村 泰士 (東工大/産総研), 大井 聖也 (東工大/産総研), Ma Youmi (東工大), 前田 航希 (東工大), 塩谷 泰平 (東工大), 齋藤 幸史郎 (東工大), 岡本 拓己 (東工大), 石田 茂樹 (東工大), 横田 理央 (東工大/産総研), 高村 大也 (産総研), 岡崎 直観 (東工大/産総研) - [S3-P34] 大規模視覚言語モデルの潜在的バイアスを利用した幻覚の抑制方法の提案
大平 颯人 (一橋大), 平澤 寅庄 (OSX), 小町 守 (一橋大) - [S3-P35] 地図情報を用いた「謎解き」の自動生成に向けて
大塚 晴貴 (愛工大), 徳久 良子 (愛工大) - [S3-P36] Sarashina-Embedding: LLMをベースにした日本語埋め込みモデルの構築
福地 成彦 (SB Intuitions), 李 聖哲 (SB Intuitions), 李 凌寒 (SB Intuitions), 大萩 雅也 (SB Intuitions), 柴田 知秀 (SB Intuitions) - [S3-P37] 和歌埋め込みモデルの構築とそれを用いた本歌取りの分析
小川 隼斗 (早大), 河原 大輔 (早大) - [S3-P38] Japanese MT-bench++: より自然なマルチターン対話設定における大規模日本語ベンチマーク
植松 拓也 (早大), 河原 大輔 (早大), 柴田 知秀 (LINEヤフー) - [S3-P39] 知識編集を用いたLLMの金融ドメイン適合手法の検討
平間 太規 (北大), 伊藤 友貴 (三井物産), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S3-P40] 採点基準を元に自律的に採点ツールの選択と適用を行う英文要約自動採点システム
藤田 晃輔 (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大)
[19:00-19:40] YANSスペシャルセッション 「ネットワーキングの極意(友達の作り方)」
学会といえばネットワーキングの場とよく言いますが、学会初心者が知り合いを増やすためにはどうすればいいのでしょうか?また、ネットワーキングの先にはどんな嬉しいことがあるのでしょうか?YANS委員とともにゆるーくお話ししましょう。
9/6(金): シンポジウム3日目 @梅田スカイビル Tower WEST 10F 「アウラホール」
[9:30-10:00] 開場
[10:00-10:30] ハッカソン報告会
シンポジウム1日目に開催したハッカソンの報告会を行います。ハッカソンの内容のダイジェストを紹介し、優秀チームにご登壇いただいてチームの取り組みについてご発表いただきます。
[10:30-11:30] チュートリアル(2) 「生成AIの二大潮流と自動運転」
 講演者: 荒居 秀尚 氏 (Turing株式会社) 概要: 自然言語処理の世界で生まれた大規模言語モデル(LLM)の関連技術と、画像生成の世界で育まれた拡散モデルの関連技術は、現在の生成AIブームにおける二大潮流である。昨今では、これらの技術を組み合わせてロボットの操作などに応用する研究も盛り上がっており、自然言語処理や画像生成にとどまらない裾野の広がりを見せている。本チュートリアルでは、視覚・言語・アクションの三つのモーダルを扱う基盤モデルの仕組みについて解説し、自動運転における応用例を紹介する。
講演者: 荒居 秀尚 氏 (Turing株式会社) 概要: 自然言語処理の世界で生まれた大規模言語モデル(LLM)の関連技術と、画像生成の世界で育まれた拡散モデルの関連技術は、現在の生成AIブームにおける二大潮流である。昨今では、これらの技術を組み合わせてロボットの操作などに応用する研究も盛り上がっており、自然言語処理や画像生成にとどまらない裾野の広がりを見せている。本チュートリアルでは、視覚・言語・アクションの三つのモーダルを扱う基盤モデルの仕組みについて解説し、自動運転における応用例を紹介する。
略歴: 2021年東京大学大学院工学系研究科修士課程修了後、株式会社リクルートで機械学習エンジニアとして推薦システムの開発やVision&Languageモデルの研究開発に携わる。2024年4月より現職にて、世界モデルやVision Language Action (VLA)モデルの研究開発に従事。
[11:40-12:40] ポスターセッション (4)
トピック別の発表一覧はこちら第19回YANSシンポジウム ポスターセッション トピック別索引 - YANS
- [S4-P01] 行動認識の粒度アライメントに基づく予定の履行認識
藤田 一天 (NAIST/理研), 吉野 幸一郎 (東工大/理研/NAIST), 河野 誠也 (理研/NAIST) - [S4-P02] 早押しクイズのための音声合成システムの開発にむけて
高田 敦嗣 (愛工大), 徳久 良子 (愛工大), 玉森 聡 (愛工大) - [S4-P03] CGとの融合:リアルタイム対話可能なバーチャルヒューマン
人見 雄太 (Aww), 佐々木 優理 (Aww), 丸田 拓和 (Aww), 片田 智大 (Aww), 甲斐 凜太郎 (Aww/東大), 木本 晴久 (Aww/茨大), 跡部 優吾 (Aww), 水落 知代 (Aww), 平川 詩恩 (Aww), 伊達 宗一郎 (Aww), ウェイ イチェン (Aww), 橋本 圭 (Aww), ジューストー 沙羅 (Aww), 守屋 貴行 (Aww) - [S4-P04] LLMの"衝突回避" : LLMと制御理論の融合
宮岡 佑弥 (慶應大), 井上 正樹 (慶應大) - [S4-P05] 人間とLLMが考える"面白い”は一致するのか?
坂部 立 (一橋大), 金 輝燦 (都立大), 小町 守 (一橋大) - [S4-P06] 言語学習支援に向けた動画生成モデルの構築
王 昊 (早大), 河原 大輔 (早大) - [S4-P07] LLMを用いた睡眠カウンセリング対話システムの検討
大橋 玲音 (愛知県立大), 我妻 信実 (愛知県立大), 中山 怜士 (愛知県立大), 野村 光 (愛知県立大), 石川 舞一 (愛知県立大), 伊藤 にい奈 (愛知県立大), 伊藤 芙久佳 (愛知県立大), 南 詩織 (愛知県立大), 金田 修香 (愛知県立大), 檜物 春佳 (愛知県立大), 中村 莉子 (愛知県立大), 西尾 優亜 (愛知県立大), 鈴木 丈慈 (愛知県立大), 坪倉 和哉 (愛知県立大), 横山 加奈 (愛知県立大) - [S4-P08] 文埋め込み次元の冪則性のZipf則による解釈
新里 顕大 (SB Intuitions), 寺前 順之介 (京大) - [S4-P09] Iterative Multimodal Fusionを用いたゼロショットの漫画キャラクター識別と話者推定
李 映萱 (東大), 日並 遼太 (Mantra), 相澤 清晴 (東大), 松井 勇佑 (東大) - [S4-P10] Filtered Direct Preference Optimization: 選好データセットの質に基づくフィルタリング手法の提案
坂本 充生 (サイバーエージェント), 森村 哲郎 (サイバーエージェント), 陣内 佑 (サイバーエージェント), 阿部 拳之 (サイバーエージェント), 蟻生 開人 (サイバーエージェント) - [S4-P11] 企業沿革のグラフ構造化に向けた企業変遷イベント抽出タスクの構築と分析
澤田 悠冶 (NAIST/理研), 大内 啓樹 (NAIST/理研/国語研), 安井 雄一郎 (日経新聞社), 寺西 裕紀 (理研/NAIST), 渡辺 太郎 (NAIST), 松本 裕治 (理研), 石井 昌之 (日経新聞社) - [S4-P12] 認知的妥当性の高い言語モデルが生成するコーパスのテキスト分析
松尾 陽平 (同志社大), 中西(大野) 義典 (同志社大) - [S4-P13] 強化学習を利用した訓練データの価値評価手法に基づく問題横断型自動採点手法
柴田 拓海 (電通大), 宇都 雅輝 (電通大) - [S4-P14] SubRegWeigh: サブワード正則化による高速アノテーション補正
辻 航平 (NAIST), 平岡 達也 (MBZUAI), 鄭 育昌 (富士通), 岩倉 友哉 (富士通) - [S4-P15] The Manga Visual Narrative Treebank
馮 思遠 (東大), 林 克彦 (東大), 小倉 甲陽 (東大), 富田 雅代 (東大), 上垣外 英剛 (NAIST) - [S4-P16] REPS: 根拠の妥当性を考慮した解答検証モデルの構築
川畑 輝 (朝日新聞社), 菅原 朔 (NII) - [S4-P17] 大規模言語モデルによる授業発話の影響推定に基づいたアドバイス生成
大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S4-P18] StaICC: 文脈内学習における分類タスクの標準的なベンチマーク
趙 羽風 (JAIST), 坂井 吉弘 (JAIST), 加藤 万理子 (JAIST), 井之上 直也 (JAIST/理研) - [S4-P19] _なぜ機械翻訳モデルの推定確率と人手評価の相関係数が低いのか?_:原因分析と改善策の検討
呂 博軒 (東工大), 上垣外 英剛 (NAIST), 船越 孝太郎 (東工大), 奥村 学 (東工大) - [S4-P20] UniDetox: Universal Social Bias Detoxification of Large Language Models
盧 慧敏 (東大), 磯沼 大 (東大/エディンバラ大), 森 純一郎 (東大/理研), 坂田 一郎 (東大) - [S4-P21] LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大) - [S4-P22] 大規模言語モデルに対する漏洩検出への敵対的なデータ隠蔽
高橋 侑成 (東工大), 馬 尤咪 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大) - [S4-P24] ローカル言語モデルの速度と応答性向上に関する技術の進展
大城 慶知 (ちゅらデータ) - [S4-P25] 日本語の単語を対象とした複数時期の意味変化パターン分析
木山 朔 (都立大), 相田 太一 (都立大), 小町 守 (一橋大), 小木曽 智信 (国語研), 高村 大也 (産総研), 持橋 大地 (統数研) - [S4-P26] パブリックアートは人を幸せにするのか
祖父江 智子 (NAIST), 伊藤 和浩 (NAIST), 古賀 千絵 (東大), 吉村 有司 (東大), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S4-P27] 質問応答による関係抽出のための有効な質問選択手法
山田 晃士 (豊田工大), 三輪 誠 (豊田工大) - [S4-P28] 掲示板テキストから得られるセンチメントを利用した日経平均株価ボラティリティ予測
中島 秀太 (一橋大), 欅 惇志 (一橋大), 渡部 敏明 (一橋大), 小町 守 (一橋大) - [S4-P29] text-to-image 拡散モデルにおける誘導 attention map を用いた画像生成手法の提案
水口 徳人 (法政大), 北田 俊輔 (法政大), 守田 竜梧 (法政大), 彌冨 仁 (法政大) - [S4-P30] Generating Explainable Recommendations of Documents through Personalized Knowledge Graphs Based on User Activity
アフザル ナヴィード (ストックマーク), 広田 航 (ストックマーク) - [S4-P31] アノテーション基準の違いを考慮した複数データセットからの固有表現抽出の学習
大井 拓 (豊田工大), 三輪 誠 (豊田工大) - [S4-P32] 語彙拡張を適用する継続事前学習における初期値学習法
李 宰成 (東北大), 吉田 倖 (東北大), 朱 灏丞 (東北大), 内藤 悠 (東北大), 岩川 光一 (東北大), 工藤 慧音 (東北大/理研), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 木村 昴 (東北大), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S4-P33] 政策質問応答システムにおけるハルシネーション抑制手法の評価
角野 為耶 (Axcreator), 稲原 宗能 (PKSHA), 宮崎 邦洋 (東大), 安野 貴博 - [S4-P34] 大規模言語モデルの知識は何に由来して記憶されるか?
西田 悠人 (NAIST/フューチャー), 岸波 洋介 (フューチャー), 藤井 諒 (フューチャー), 森下 睦 (フューチャー) - [S4-P35] Large-scale Vision Language Modelの言語タスクに及ぼす画像の影響
吉田 大城 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 林 克彦 (東大), 渡辺 太郎 (NAIST) - [S4-P36] 個人の主観評価データに基づく対話システムの発話評価手法の検討
亀山 京右 (阪大), 堅田 俊 (阪大), 駒谷 和範 (阪大) - [S4-P37] 形式証明の逆形式化を通じた自然言語証明テキストの構造解析
服部 清志 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大) - [S4-P38] 内心描写付きの対話データを用いた非著名人の性格特性再現
石倉 誠也 (東工大), 山田 寛章 (東工大), 平岡 達也 (MBZUAI), 山田 広明 (富士通), 徳永 健伸 (東工大) - [S4-P39] 応答候補の多様性を用いた参照応答集合の評価に向けて
佐藤 魁 (東北大), 吉野 幸一郎 (東工大/理研), 河野 誠也 (理研/NAIST), 赤間 怜奈 (東北大/理研)
[12:40-14:00] 昼休憩
[14:00-15:00] ポスターセッション (5)
トピック別の発表一覧はこちら第19回YANSシンポジウム ポスターセッション トピック別索引 - YANS
- [S5-P01] 書誌情報の複数項目との関係を考慮した柔軟な論文検索システム
井田 龍希 (豊田工大), 三輪 誠 (豊田工大) - [S5-P02] 単語分散表現モデルの埋め込み空間を用いた概念間探索手法の構築と大規模言語モデルの機械論的解釈可能性への応用
本田 純也 (豊橋技科大/エモスタ), 小川 修平 (エモスタ), 坂本 航太郎 (東大) - [S5-P03] LLMと音声基盤モデルを用いた音声認識
小峠 陸登 (Spiral.AI/阪大), 安立 健人 (Spiral.AI), 石川 宏輔 (Spiral.AI), 佐々木 雄一 (Spiral.AI) - [S5-P04] 自動運転のための言語・視覚・動作の統合データセットの構築
三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - [S5-P05] 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P06] Text-to-SQLのためのテーブルデータを用いたカラムフィルタリング
野口 輝 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大) - [S5-P07] 大規模言語モデルによる11種類の日本語スタイル変換の性能評価
花房 健太郎 (愛媛大), 柳本 大輝 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S5-P08] Exploring Mixed Time Systems in Large Language Models for Temporal Reasoning
孫 飛飛 (JAIST), 童 子芸 (JAIST), Nguyen Le Minh (JAIST) - [S5-P09] LLMを用いて説明文を生成する対話型映画推薦システム
麻野 健太郎 (芝浦工大), 杉本 徹 (芝浦工大) - [S5-P10] 大規模Webコーパスからの効果的な医療ドメインサンプリング法
長谷川 愛珠 (日本女子大), 小原 有以 (日本女子大), 伊東 和香 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S5-P11] LLMを用いた文書分類のためのData Augmentationの検討
小野寺 優 (茨大), 新納 浩幸 (茨大) - [S5-P12] エピソードへの主体性アノテーション:well-beingのさらなる理解に向けて
林 純子 (NAIST), 永井 宥之 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S5-P13] 作曲学習支援のための音楽と言語のマルチモーダルモデルに向けて
稲葉 達郎 (京大) - [S5-P14] 言語モデルの日本語道徳理解能力の評価データセットの構築
竹下 昌志 (北大), ジェプカ ラファウ (北大) - [S5-P15] テキスト評価におけるLLMアライメント手法の影響分析
佐藤 郁子 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 三田 雅人 (サイバーエージェント/都立大), 小町 守 (一橋大) - [S5-P16] ニューラル単語アライメントによる言い換え辞書の改善
近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S5-P17] 情報科学分野における学会発表タイトルの分野推定データセットの構築
宮田 莉奈 (愛媛大), 眞鍋 光汰 (愛媛大), 福島 啓太 (愛媛大), 花房 健太郎 (愛媛大), 高田 一慶 (愛媛大), 梶原 智之 (愛媛大), 桂井 麻里衣 (同志社大), 二宮 崇 (愛媛大) - [S5-P18] 自然言語モデルを活用した同件不具合検出システムを用いたシステムテスト品質の向上
松尾 正裕 (パナソニックITS) - [S5-P19] 人狼知能における論理的推論のためのBDI Proverと大規模言語モデルの利用
権藤 拓 (北大), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S5-P20] 機械学習用データセットの説明文における数値情報の自動抽出
嘉本 名晋 (同志社大), 長尾 浩良 (同志社大), 桂井 麻里衣 (同志社大) - [S5-P21] マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P22] 意味表現のグラフ構造を考慮したフレーズアブダクションの改良
北村 優佳 (東大), 谷中 瞳 (東大) - [S5-P23] Single promptによるhallucination事後修正
畠山 陽喜 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S5-P24] 大規模言語モデルにおけるラベル平滑化の有効性
内藤 悠 (東北大), 岩川 光一 (東北大), 朱 灏丞 (東北大), 吉田 倖 (東北大), 李 宰成 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 工藤 慧音 (東北大/理研), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S5-P25] 高品質なデータを用いた追加事前学習が大規模言語モデルに与える影響
吉田 倖 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 工藤 慧音 (東北大/理研), 矢野 一樹 (東北大), 李 宰成 (東北大), 朱 灏丞 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S5-P26] 大規模Seq2Seqモデルの分散学習
星野 智紀 (HT), 寺町 アルセーニ (HT) - [S5-P27] 授業発話の分類に基づく教員へのアドバイス生成
児嶋 祥成 (岡山理大), 大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S5-P28] SNSカウンセラー育成のためのリアルタイム対話支援システムの構築
斉 志揚 (電通大), 稲葉 通将 (電通大) - [S5-P29] ベクター画像を利用する上での大規模言語モデルでトークン数の制限を回避する手法の提案
大竹 啓永 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P30] 検索クリックログに基づくクエリ理解に特化した埋め込み
西川 荘介 (LINEヤフー), 平子 潤 (LINEヤフー), 佐野 峻平 (LINEヤフー), 浅野 広樹 (LINEヤフー), 渡邉 幸暉 (LINEヤフー), 山城 颯太 (LINEヤフー), 鍜治 伸裕 (LINEヤフー) - [S5-P31] 大規模言語モデルにおける相転移と自然言語の関係
中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大) - [S5-P32] 動機づけ面接におけるクライエントの発話分類に基づく応答生成
金子 優 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S5-P33] Enhancing Biomedical Summarization with External Knowledge Integration via Retrieval-Augmented Generation
羅 冠霆 (阪大), 荒瀬 由紀 (東工大) - [S5-P34] 歴史災害史料を対象とした地名の自動抽出
武内 樹治 (奈良文化財研究所), 大内 啓樹 (NAIST), 東山 翔平 (NICT) - [S5-P35] 質問の言語表現が大規模言語モデルの回答傾向に与える影響の調査
高山 隼矢 (SB Intuitions), 大萩 雅也 (SB Intuitions), 水本 智也 (SB Intuitions), 吉川 克正 (SB Intuitions) - [S5-P36] LLMは真面目・不真面目になれるか?
堀尾 海斗 (早大), 河原 大輔 (早大) - [S5-P37] 言語モデルの透明性ごとに適応な可能なチューニング手法の調査
中島 京太郎 (都立大), 金 輝燦 (都立大), 平澤 寅庄 (都立大), 榎本 大晟 (都立大), 小町 守 (一橋大) - [S5-P38] 視写課題の自動採点へ向けた 子供らしい文字の自動生成による OCR 精度の向上
関 歩実 (東京理科大), 松崎 拓也 (東京理科大) - [S5-P39] 多様なモダリティの属性情報をハイパーグラフにより統合したエンティティ表現の獲得
西出 隆盛 (豊田工大), 三輪 誠 (豊田工大)
[15:15-16:15] 目指せ国際会議!
国際会議での発表経験がある若手研究者/学生に登壇いただき、国際会議参加レポートLTと、パネルディスカッションを開催します。 多様な背景の研究者/学生の体験談を聞くことで、これから国際会議に挑戦するみなさんのモチベーションアップや、国際会議に対する解像度を上げることを目的としています。 パネルディスカッションではみなさんからリアルタイムに募ったテーマについてお話いただく予定です。みなさんからの質問・コメントなどお待ちしています!
[16:25-17:25] 招待ポスター
今年のテーマである「異分野交流」を促進するため、招待ポスターセッションを行います。自然言語処理分野だけでなく、音声・画像処理などの周辺分野や人文・社会学系の若手研究者や技術者複数名をお招きし、これまでの研究や展望についてポスター発表をしていただきます。 発表の概要、また発表者の略歴については以下のページをご参照下さい。
発表一覧
- [IV-P01] 難解な数値データを分かりやすく説明する言語生成技術の最前線と未来
石垣 達也 氏(産総研人工知能研究センター) - [IV-P02] 人間らしい対話とは:非言語情報生成のための基盤モデル
井上 昂治 氏(京都大学) - [IV-P03] Can AI entertain us?
山西 良典 氏(関西大学) - [IV-P04] 日本語事前学習向けベンチマーク
今城 健太郎 氏(Preferred Networks) - [IV-P05] 人文学と言語処理・知識処理
大向 一輝 氏(東京大学) - [IV-P06] 企業でつくる、大規模言語モデル
清野 舜 氏(SB Intuitions) - [IV-P07] End-to-End音声基盤モデル
小島 熙之 氏(Kotoba Technologies, Inc.) - [IV-P08] 視覚と言語の対応ずれ問題とその解決に向けて
品川 政太朗 氏(SB Intuitions) - [IV-P09] LLM時代の評価研究とその周辺
菅原 朔 氏(国立情報学研究所) - [IV-P10] Mechanistic Interpretability: 大規模言語モデル時代における自然言語処理と認知科学の交差点
高木 優 氏(国立情報学研究所/JST/大阪大学/情報通信研究機構) - [IV-P11] 発話内容書き起こしを越えて音声と言語を結びつけたい
高道 慎之介 氏(慶應義塾大学/東京大学) - [IV-P12] クラウドソーシングとAI文字認識を駆使した「くずし字」資料の大規模テキスト化
橋本 雄太 氏(国立歴史民俗博物館) - [IV-P13] 形を通して意味を知る
横井 祥 氏(東北大学/理化学研究所) - [IV-P14] 人・ロボットの移動と大規模言語モデルの接点
米谷 竜 氏(サイバーエージェント) - [IV-P15] 人々の健康に資するソーシャルコンピューティング
若宮 翔子 氏(奈良先端科学技術大学院大学)
[17:40-18:40] クロージング
- 音韻・文法・形式言語学 / 10件
- 機械学習 (統計・数理) / 4件
- 機械学習 (転移学習・ドメイン適応) / 10件
- 機械学習 (マルチタスク・その他) / 8件
- LLM構築 / 14件
- LLM分析 / 40件
- LLM応用 / 63件
- 言語モデル・ニューラルネットワーク (LLM除く) / 13件
- モデル解釈・可視化 / 17件
- 評価指標・品質推定 / 18件
- 少数データ・データ拡張 / 7件
- 言語資源・アノテーション / 26件
- 単語分割・形態素解析 / 1件
- 埋め込み表現 / 22件
- 構文解析・意味解析・共参照解析 / 7件
- 情報抽出・知識獲得 / 27件
- 読解・含意・質問応答 / 7件
- 文書分類 / 6件
- 感情分析・評判分析 / 9件
- 検索・推薦 / 14件
- 自然言語生成 / 23件
- 機械翻訳 / 4件
- 要約 / 6件
- 誤り訂正 / 4件
- 談話理解・対話 / 19件
- マルチモーダル / 31件
- 多言語・Multi/Cross-Lingual / 7件
- 応用 (Webサービス・ソーシャルメディア) / 10件
- 応用 (教育) / 13件
- 応用 (産業・法律・知的財産) / 1件
- 応用 (心理・生物・医療) / 16件
- 応用 (科学研究支援) / 5件
- 倫理・バイアス・プライバシー / 6件
音韻・文法・形式言語学 / 10件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P13] 言語の逐次性に普遍的性質はあるか?:parsing strategyの最適性からの分析
石井 太河 (東大), 宮尾 祐介 (東大) - [S1-P21] 大規模言語モデルを用いたオノマトペ付与による日本語音声データセットの拡張
小川 剛毅 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S1-P34] 大規模言語モデルによる読"舌"術
坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P40] 人工知能ラッパーの実現に向けて
織田 宥楽 (早大), 小川 隼斗 (早大), 河原 大輔 (早大)
[17:50-18:50] ポスターセッション (3)
- [S3-P02] ラップの原則に基づく生成手法の検討
淡島 英輝 (ちゅらデータ) - [S3-P14] 微分可能スタックを用いた言語創発
加藤 大地 (東大), 上田 亮 (東大), 宮尾 祐介 (東大) - [S3-P23] LLMによる項構造依存関係解析の検証: 読み時間・容認性判断データとの比較と認知モデリング
木村 一馬 (筑波大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P02] 早押しクイズのための音声合成システムの開発にむけて
高田 敦嗣 (愛工大), 徳久 良子 (愛工大), 玉森 聡 (愛工大) - [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大) - [S4-P37] 形式証明の逆形式化を通じた自然言語証明テキストの構造解析
服部 清志 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大)
機械学習 (統計・数理) / 4件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P15] 事前学習–文脈内学習パラダイムで生じる頻度バイアスの較正
伊藤 郁海 (東北大), 鴨田 豪 (東北大), 熊谷 雄介 (博報堂DYホールディングス), 横井 祥 (東北大/理研)
[14:00-15:00] ポスターセッション (2)
- [S2-P10] 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P10] Filtered Direct Preference Optimization: 選好データセットの質に基づくフィルタリング手法の提案
坂本 充生 (サイバーエージェント), 森村 哲郎 (サイバーエージェント), 陣内 佑 (サイバーエージェント), 阿部 拳之 (サイバーエージェント), 蟻生 開人 (サイバーエージェント)
[14:00-15:00] ポスターセッション (5)
- [S5-P31] 大規模言語モデルにおける相転移と自然言語の関係
中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大)
機械学習 (転移学習・ドメイン適応) / 10件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P04] Vision And Languageモデルにおける異なるドメインでの継続事前学習が後段タスクに与える影響の検証
齋藤 慎一朗 (Sansan) - [S1-P09] 大規模言語モデルの継続事前学習における学習率設定の検討
朱 灏丞 (東北大), 李 宰成 (東北大), 岩川 光一 (東北大), 内藤 悠 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 彗音 (東北大/理研), 木村 昴 (東北大), 葉 夢宇 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研)
[14:00-15:00] ポスターセッション (2)
- [S2-P16] A Closer Look at Task Analogies: Insights from Function and Parameter Space
吉田 晃太朗 (東工大), 楢木 悠士 (), 山木 良輔 (立命館大/ProPlace), 堀江 孝文 (立命館大), 清水 良太郎 (ZOZO研究所/カリフォルニア大), 斎藤 侑輝 (ZOZO研究所), 長沼 大樹 (モントリオール大/Mila/ProPlace)
[17:50-18:50] ポスターセッション (3)
- [S3-P13] モデルマージによるタスクごとの性能変化の分析
瓦 祐希 (Fusic) - [S3-P37] 和歌埋め込みモデルの構築とそれを用いた本歌取りの分析
小川 隼斗 (早大), 河原 大輔 (早大) - [S3-P39] 知識編集を用いたLLMの金融ドメイン適合手法の検討
平間 太規 (北大), 伊藤 友貴 (三井物産), 坂地 泰紀 (北大), 野田 五十樹 (北大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P13] 強化学習を利用した訓練データの価値評価手法に基づく問題横断型自動採点手法
柴田 拓海 (電通大), 宇都 雅輝 (電通大) - [S4-P32] 語彙拡張を適用する継続事前学習における初期値学習法
李 宰成 (東北大), 吉田 倖 (東北大), 朱 灏丞 (東北大), 内藤 悠 (東北大), 岩川 光一 (東北大), 工藤 慧音 (東北大/理研), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 木村 昴 (東北大), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P10] 大規模Webコーパスからの効果的な医療ドメインサンプリング法
長谷川 愛珠 (日本女子大), 小原 有以 (日本女子大), 伊東 和香 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S5-P37] 言語モデルの透明性ごとに適応な可能なチューニング手法の調査
中島 京太郎 (都立大), 金 輝燦 (都立大), 平澤 寅庄 (都立大), 榎本 大晟 (都立大), 小町 守 (一橋大)
機械学習 (マルチタスク・その他) / 8件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P14] 日本手話における検索や解析のための柔軟な表現の獲得
井上 純大 (豊田工大), 原 大介 (豊田工大), 三輪 誠 (豊田工大) - [S1-P18] 児童の読解力向上を目的とした音読支援システムの開発
齊藤 新 (東京理科大), 松崎 拓也 (東京理科大)
[14:00-15:00] ポスターセッション (2)
- [S2-P11] 拡散モデルを用いたシーングラフベースの画像編集
森 江梨花 (慶應大), 渡邊 偉志 (パナソニックコネクト), 藤松 健 (パナソニックコネクト), 嘉本 海大 (パナソニックコネクト), 青木 義満 (慶應大) - [S2-P35] タスク特徴を考慮したマッチング制約下におけるアノテーション割り当て
守山 慧 (東大), 中山 功太 (NII), 馬場 雪乃 (東大)
[17:50-18:50] ポスターセッション (3)
- [S3-P14] 微分可能スタックを用いた言語創発
加藤 大地 (東大), 上田 亮 (東大), 宮尾 祐介 (東大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P04] LLMの"衝突回避" : LLMと制御理論の融合
宮岡 佑弥 (慶應大), 井上 正樹 (慶應大) - [S4-P09] Iterative Multimodal Fusionを用いたゼロショットの漫画キャラクター識別と話者推定
李 映萱 (東大), 日並 遼太 (Mantra), 相澤 清晴 (東大), 松井 勇佑 (東大) - [S4-P21] LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大)
LLM構築 / 14件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P16] 学習過程における重みのマージによるモデル最適化
渡邉 一功 (早大), 河原 大輔 (早大)
[14:00-15:00] ポスターセッション (2)
- [S2-P04] 大規模言語モデルの事前学習ツールjax-llmの開発とinput-methodへの応用
杉浦 一瑳 (京大) - [S2-P12] データセット共有基盤を用いた参加型コードLLM開発の提案
伊東 和香 (日本女子大), 小原 有以 (日本女子大), 西潟 優羽 (日本女子大), 佐藤 美唯 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S2-P20] In-model anti-expertによる大規模言語モデルのハルシネーション抑制
門谷 宙 (NTT), 西田 光甫 (NTT), 西田 京介 (NTT), 齋藤 邦子 (NTT) - [S2-P29] クローリングによるコモンクロールを補完した日本語コーパス拡充の検討
石原 慧人 (LINEヤフー), 永井 隆広 (LINEヤフー), 平田 航大 (LINEヤフー), 岸本 耀平 (LINEヤフー), 中野 佑哉 (LINEヤフー)
[17:50-18:50] ポスターセッション (3)
- [S3-P04] 大規模言語モデルと患者表現辞書を用いた病名予測の検証
宇都宮 和希 (工学院大), 坂野 遼平 (一橋大) - [S3-P33] 小規模で高性能なLLMのための高品質事前学習Webコーパスの構築
服部 翔 (東工大/産総研), 水木 栄 (東工大/産総研), 藤井 一喜 (東工大/産総研), 中村 泰士 (東工大/産総研), 大井 聖也 (東工大/産総研), Ma Youmi (東工大), 前田 航希 (東工大), 塩谷 泰平 (東工大), 齋藤 幸史郎 (東工大), 岡本 拓己 (東工大), 石田 茂樹 (東工大), 横田 理央 (東工大/産総研), 高村 大也 (産総研), 岡崎 直観 (東工大/産総研)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P04] LLMの"衝突回避" : LLMと制御理論の融合
宮岡 佑弥 (慶應大), 井上 正樹 (慶應大) - [S4-P10] Filtered Direct Preference Optimization: 選好データセットの質に基づくフィルタリング手法の提案
坂本 充生 (サイバーエージェント), 森村 哲郎 (サイバーエージェント), 陣内 佑 (サイバーエージェント), 阿部 拳之 (サイバーエージェント), 蟻生 開人 (サイバーエージェント) - [S4-P32] 語彙拡張を適用する継続事前学習における初期値学習法
李 宰成 (東北大), 吉田 倖 (東北大), 朱 灏丞 (東北大), 内藤 悠 (東北大), 岩川 光一 (東北大), 工藤 慧音 (東北大/理研), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 木村 昴 (東北大), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P10] 大規模Webコーパスからの効果的な医療ドメインサンプリング法
長谷川 愛珠 (日本女子大), 小原 有以 (日本女子大), 伊東 和香 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S5-P24] 大規模言語モデルにおけるラベル平滑化の有効性
内藤 悠 (東北大), 岩川 光一 (東北大), 朱 灏丞 (東北大), 吉田 倖 (東北大), 李 宰成 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 工藤 慧音 (東北大/理研), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S5-P25] 高品質なデータを用いた追加事前学習が大規模言語モデルに与える影響
吉田 倖 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 工藤 慧音 (東北大/理研), 矢野 一樹 (東北大), 李 宰成 (東北大), 朱 灏丞 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S5-P26] 大規模Seq2Seqモデルの分散学習
星野 智紀 (HT), 寺町 アルセーニ (HT)
LLM分析 / 40件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P20] 英語データセットを使ったRLHFは日本語LLMの常識道徳にどのような影響を与えるか?
陣内 佑 (サイバーエージェント) - [S1-P22] メンバーシップ推論攻撃によるLLMの失言しやすさの評価
丹波 光 (日本女子大), 小柳 響子 (日本女子大), 伊東 和香 (日本女子大), 倉光 君郎 (日本女子大) - [S1-P34] 大規模言語モデルによる読"舌"術
坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S1-P36] 現代LLMは日本語の語用論を分かるのか?
ガンバルデッラ アンドリュー (東大) - [S1-P38] 指示数増加による大規模言語モデルの指示追従性能への悪影響
原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大) - [S1-P39] 大規模視覚言語モデルの謎解き能力調査
臼井 久生 (東京農工大), 木山 朔 (都立大), 古宮 嘉那子 (東京農工大) - [S1-P40] 言語モデルは人々の意見分布をどのように予測するか
鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P05] LLMを用いた自由記述アンケートの質的分析
橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST) - [S2-P06] Multilingual LLM への指示文は本当に英語であるべきなのか?
榎本 大晟 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 小町 守 (一橋大) - [S2-P08] 大規模言語モデルの説明文生成能力における忠実性改善の試み
土井 智暉 (東大), 磯沼 大 (東大/エディンバラ大), 谷中 瞳 (東大) - [S2-P10] 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研) - [S2-P15] 語順に制約されない大規模言語モデルの知識編集
石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S2-P16] A Closer Look at Task Analogies: Insights from Function and Parameter Space
吉田 晃太朗 (東工大), 楢木 悠士 (), 山木 良輔 (立命館大/ProPlace), 堀江 孝文 (立命館大), 清水 良太郎 (ZOZO研究所/カリフォルニア大), 斎藤 侑輝 (ZOZO研究所), 長沼 大樹 (モントリオール大/Mila/ProPlace) - [S2-P25] 大規模言語モデルにおけるチェックポイント平均法の有効性
岩川 光一 (東北大), 内藤 悠 (東北大), 朱 灏丞 (東北大), 李 宰成 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 慧音 (東北大/理研), 葉 夢宇 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S2-P33] Phase Diagram of Vision Large Language Models Inference: A Perspective from Interaction across Image and Instruction
WEI Houjing (JAIST), SHI Yuting (JAIST), Cho Hakaze (JAIST), YAN Zhenzhu (JAIST), 井之上 直也 (JAIST/理研) - [S2-P36] RAGを用いたLLMによる偽情報検出手法の検討
山田 美優 (東工大), 荒瀬 由紀 (東工大)
[17:50-18:50] ポスターセッション (3)
- [S3-P04] 大規模言語モデルと患者表現辞書を用いた病名予測の検証
宇都宮 和希 (工学院大), 坂野 遼平 (一橋大) - [S3-P08] Attentionに基づく大規模言語モデルのHallucination検出手法の検討
小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - [S3-P10] LLMの論理推論能力は図的表現の使用により改善するか:オイラー図つき三段論法データセットNeuBAROCOを用いた分析
安東 里沙子 (慶應大), 小関 健太郎 (東大/慶應大), 森下 貴允 (慶應大), 阿部 裕彦 (慶應大), 峯島 宏次 (慶應大), 岡田 光弘 (慶應大) - [S3-P13] モデルマージによるタスクごとの性能変化の分析
瓦 祐希 (Fusic) - [S3-P17] ステップごとの推論における情報補完のカテゴリ別分析
三浦 東子 (東北大), 谷口 雅弥 (理研), 坂口 慶祐 (東北大/理研), 乾 健太郎 (東北大/理研/MBZUAI) - [S3-P23] LLMによる項構造依存関係解析の検証: 読み時間・容認性判断データとの比較と認知モデリング
木村 一馬 (筑波大) - [S3-P31] 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研) - [S3-P33] 小規模で高性能なLLMのための高品質事前学習Webコーパスの構築
服部 翔 (東工大/産総研), 水木 栄 (東工大/産総研), 藤井 一喜 (東工大/産総研), 中村 泰士 (東工大/産総研), 大井 聖也 (東工大/産総研), Ma Youmi (東工大), 前田 航希 (東工大), 塩谷 泰平 (東工大), 齋藤 幸史郎 (東工大), 岡本 拓己 (東工大), 石田 茂樹 (東工大), 横田 理央 (東工大/産総研), 高村 大也 (産総研), 岡崎 直観 (東工大/産総研)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P16] REPS: 根拠の妥当性を考慮した解答検証モデルの構築
川畑 輝 (朝日新聞社), 菅原 朔 (NII) - [S4-P18] StaICC: 文脈内学習における分類タスクの標準的なベンチマーク
趙 羽風 (JAIST), 坂井 吉弘 (JAIST), 加藤 万理子 (JAIST), 井之上 直也 (JAIST/理研) - [S4-P21] LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大) - [S4-P22] 大規模言語モデルに対する漏洩検出への敵対的なデータ隠蔽
高橋 侑成 (東工大), 馬 尤咪 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大) - [S4-P24] ローカル言語モデルの速度と応答性向上に関する技術の進展
大城 慶知 (ちゅらデータ) - [S4-P33] 政策質問応答システムにおけるハルシネーション抑制手法の評価
角野 為耶 (Axcreator), 稲原 宗能 (PKSHA), 宮崎 邦洋 (東大), 安野 貴博 () - [S4-P34] 大規模言語モデルの知識は何に由来して記憶されるか?
西田 悠人 (NAIST/フューチャー), 岸波 洋介 (フューチャー), 藤井 諒 (フューチャー), 森下 睦 (フューチャー) - [S4-P35] Large-scale Vision Language Modelの言語タスクに及ぼす画像の影響
吉田 大城 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 林 克彦 (東大), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (5)
- [S5-P07] 大規模言語モデルによる11種類の日本語スタイル変換の性能評価
花房 健太郎 (愛媛大), 柳本 大輝 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S5-P08] Exploring Mixed Time Systems in Large Language Models for Temporal Reasoning
孫 飛飛 (JAIST), 童 子芸 (JAIST), Nguyen Le Minh (JAIST) - [S5-P14] 言語モデルの日本語道徳理解能力の評価データセットの構築
竹下 昌志 (北大), ジェプカ ラファウ (北大) - [S5-P15] テキスト評価におけるLLMアライメント手法の影響分析
佐藤 郁子 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 三田 雅人 (サイバーエージェント/都立大), 小町 守 (一橋大) - [S5-P21] マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P31] 大規模言語モデルにおける相転移と自然言語の関係
中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大) - [S5-P35] 質問の言語表現が大規模言語モデルの回答傾向に与える影響の調査
高山 隼矢 (SB Intuitions), 大萩 雅也 (SB Intuitions), 水本 智也 (SB Intuitions), 吉川 克正 (SB Intuitions)
LLM応用 / 63件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P07] 大規模言語モデルによる機械翻訳の教師なし品質推定
樽本 空宙 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P15] 事前学習–文脈内学習パラダイムで生じる頻度バイアスの較正
伊藤 郁海 (東北大), 鴨田 豪 (東北大), 熊谷 雄介 (博報堂DYホールディングス), 横井 祥 (東北大/理研) - [S1-P19] 豪雨と地震におけるクロノロジーの優先度推定
孝壽 真治 (岡山大), 竹内 孔一 (岡山大), 渡邉 暁洋 (兵庫医科大), 平山 隆浩 (岡山大), 中尾 博之 (大阪行岡医療大) - [S1-P22] メンバーシップ推論攻撃によるLLMの失言しやすさの評価
丹波 光 (日本女子大), 小柳 響子 (日本女子大), 伊東 和香 (日本女子大), 倉光 君郎 (日本女子大) - [S1-P23] 強化学習を用いた、言語理解能力を維持したLLM検出器の性能向上
齋藤 幸史郎 (東工大), 小池 隆斗 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P25] 大規模言語モデルによる日本文化に沿った指示データ生成
塩谷 泰平 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P26] 潜在拡散モデルによる画像生成における対象の配色制御による改善の試み
永井 大地 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S1-P29] 教師なし条件付きテキスト埋め込みの獲得
山田 康輔 (サイバーエージェント), 張 培楠 (サイバーエージェント) - [S1-P34] 大規模言語モデルによる読"舌"術
坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S1-P37] 日本語医療LLM評価ベンチマークの構築と性能分析
福島 拓也 (NAIST), 久田 祥平 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S1-P38] 指示数増加による大規模言語モデルの指示追従性能への悪影響
原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大)
[14:00-15:00] ポスターセッション (2)
- [S2-P03] 日常会話を通じて心の健康を支援するヴァーチャルエージェントの試作
泉 健太 (SB Intuitions), Liu Lianbo (SB Intuitions), 大萩 雅也 (SB Intuitions), 山崎 天 (SB Intuitions) - [S2-P05] LLMを用いた自由記述アンケートの質的分析
橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST) - [S2-P07] 強化学習に基づく難易度制御を組み込んだ多肢選択式読解問題自動生成手法の開発
富川 雄斗 (電通大), 宇都 雅輝 (電通大) - [S2-P14] 対照デコーディングを用いたマルチトークン予測モデルの精度向上
髙城 頌太 (東大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大) - [S2-P15] 語順に制約されない大規模言語モデルの知識編集
石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S2-P17] おやつプロジェクト: おすすめスイーツ店の個人レビュー要約
岩本 蘭 (IBM/慶應大), 大内 啓樹 (NAIST/サイバーエージェント), 金山 博 (IBM), 吉田 光男 (筑波大) - [S2-P18] オンライン動画サービスにおけるBERT及び大規模言語モデルを用いた視聴者感情の推定
菅野 祐希 (工学院大), 坂野 遼平 (一橋大) - [S2-P21] LLMを用いた生成による階層的イベントの抽出
金児 一矢 (豊田工大), 三輪 誠 (豊田工大) - [S2-P24] 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大) - [S2-P26] ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV) - [S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討
伊原 滉也 (サイバーエージェント), 叶 穎睿 (サイバーエージェント), 田村 和範 (QualiArts), 岡 時生 (QualiArts), 水村 総之介 (QualiArts), 野村 将寛 (サイバーエージェント) - [S2-P28] 大規模言語モデルによる感情極性に着目した小説からの人物関係抽出
齋藤 大輔 (名工大), 李 晃伸 (名工大), 上乃 聖 (名工大) - [S2-P31] 土木分野におけるRAGの実用化課題の整理と精度向上へ向けた検討
緒方 陸 (八千代エンジニヤリング), 岡野 将大 (八千代エンジニヤリング), 大久保 順一 (八千代エンジニヤリング), 藤井 純一郎 (八千代エンジニヤリング) - [S2-P39] ヴェーダ語学・ヴェーダ文献学におけるRAGの活用
塚越 柚季 (東大)
[17:50-18:50] ポスターセッション (3)
- [S3-P02] ラップの原則に基づく生成手法の検討
淡島 英輝 (ちゅらデータ) - [S3-P03] ユーザレビュー作成支援を目的とした対話システムの活用法の提案
田中 義規 (電通大), 稲葉 通将 (電通大) - [S3-P07] SelfCheckGPTはコードLLMの幻覚を見抜けるか?
前田 遥香 (日本女子大), 西潟 優羽 (日本女子大), 小柳 響子 (日本女子大), 佐藤 美唯 (日本女子大), 倉光 君郎 (日本女子大) - [S3-P09] マルチエージェント協働による TRPG ゲームマスターの実現
箕成 侑音 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S3-P11] 大規模言語モデルを用いた日本語テキスト要約の自動評価
安里 優真 (JAIST), 白井 清昭 (JAIST) - [S3-P15] 大規模言語モデルによって医療テキストの固有表現処理はどこまで簡単になったか
西林 孝 (Ubie), 横井 祥 (東北大/理研) - [S3-P20] ノイズを含む日本語テキストデータにおける固有表現抽出手法の検証
尾城 奈緒子 (インテージ), 竹村 彰浩 (インテージ) - [S3-P23] LLMによる項構造依存関係解析の検証: 読み時間・容認性判断データとの比較と認知モデリング
木村 一馬 (筑波大) - [S3-P24] チェックリストを利用した生成系タスクの網羅的評価
古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII) - [S3-P25] LLMを用いたCT読影レポートの撮影目的分類
峯 悠大 (NAIST), 西山 智弘 (NAIST), 谷 懿 (NAIST), 大竹 義人 (NAIST), 佐藤 嘉伸 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P27] 学術論文におけるGraphical Abstract自動生成の初期検討
川田 拓朗 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S3-P39] 知識編集を用いたLLMの金融ドメイン適合手法の検討
平間 太規 (北大), 伊藤 友貴 (三井物産), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S3-P40] 採点基準を元に自律的に採点ツールの選択と適用を行う英文要約自動採点システム
藤田 晃輔 (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P03] CGとの融合:リアルタイム対話可能なバーチャルヒューマン
人見 雄太 (Aww), 佐々木 優理 (Aww), 丸田 拓和 (Aww), 片田 智大 (Aww), 甲斐 凜太郎 (Aww/東大), 木本 晴久 (Aww/茨大), 跡部 優吾 (Aww), 水落 知代 (Aww), 平川 詩恩 (Aww), 伊達 宗一郎 (Aww), ウェイ イチェン (Aww), 橋本 圭 (Aww), ジューストー 沙羅 (Aww), 守屋 貴行 (Aww) - [S4-P05] 人間とLLMが考える"面白い”は一致するのか?
坂部 立 (一橋大), 金 輝燦 (都立大), 小町 守 (一橋大) - [S4-P09] Iterative Multimodal Fusionを用いたゼロショットの漫画キャラクター識別と話者推定
李 映萱 (東大), 日並 遼太 (Mantra), 相澤 清晴 (東大), 松井 勇佑 (東大) - [S4-P10] Filtered Direct Preference Optimization: 選好データセットの質に基づくフィルタリング手法の提案
坂本 充生 (サイバーエージェント), 森村 哲郎 (サイバーエージェント), 陣内 佑 (サイバーエージェント), 阿部 拳之 (サイバーエージェント), 蟻生 開人 (サイバーエージェント) - [S4-P16] REPS: 根拠の妥当性を考慮した解答検証モデルの構築
川畑 輝 (朝日新聞社), 菅原 朔 (NII) - [S4-P17] 大規模言語モデルによる授業発話の影響推定に基づいたアドバイス生成
大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S4-P30] Generating Explainable Recommendations of Documents through Personalized Knowledge Graphs Based on User Activity
アフザル ナヴィード (ストックマーク), 広田 航 (ストックマーク) - [S4-P33] 政策質問応答システムにおけるハルシネーション抑制手法の評価
角野 為耶 (Axcreator), 稲原 宗能 (PKSHA), 宮崎 邦洋 (東大), 安野 貴博 () - [S4-P34] 大規模言語モデルの知識は何に由来して記憶されるか?
西田 悠人 (NAIST/フューチャー), 岸波 洋介 (フューチャー), 藤井 諒 (フューチャー), 森下 睦 (フューチャー) - [S4-P35] Large-scale Vision Language Modelの言語タスクに及ぼす画像の影響
吉田 大城 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 林 克彦 (東大), 渡辺 太郎 (NAIST) - [S4-P38] 内心描写付きの対話データを用いた非著名人の性格特性再現
石倉 誠也 (東工大), 山田 寛章 (東工大), 平岡 達也 (MBZUAI), 山田 広明 (富士通), 徳永 健伸 (東工大)
[14:00-15:00] ポスターセッション (5)
- [S5-P02] 単語分散表現モデルの埋め込み空間を用いた概念間探索手法の構築と大規模言語モデルの機械論的解釈可能性への応用
本田 純也 (豊橋技科大/エモスタ), 小川 修平 (エモスタ), 坂本 航太郎 (東大) - [S5-P04] 自動運転のための言語・視覚・動作の統合データセットの構築
三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - [S5-P06] Text-to-SQLのためのテーブルデータを用いたカラムフィルタリング
野口 輝 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大) - [S5-P08] Exploring Mixed Time Systems in Large Language Models for Temporal Reasoning
孫 飛飛 (JAIST), 童 子芸 (JAIST), Nguyen Le Minh (JAIST) - [S5-P09] LLMを用いて説明文を生成する対話型映画推薦システム
麻野 健太郎 (芝浦工大), 杉本 徹 (芝浦工大) - [S5-P18] 自然言語モデルを活用した同件不具合検出システムを用いたシステムテスト品質の向上
松尾 正裕 (パナソニックITS) - [S5-P19] 人狼知能における論理的推論のためのBDI Proverと大規模言語モデルの利用
権藤 拓 (北大), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S5-P21] マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P23] Single promptによるhallucination事後修正
畠山 陽喜 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S5-P27] 授業発話の分類に基づく教員へのアドバイス生成
児嶋 祥成 (岡山理大), 大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S5-P28] SNSカウンセラー育成のためのリアルタイム対話支援システムの構築
斉 志揚 (電通大), 稲葉 通将 (電通大) - [S5-P29] ベクター画像を利用する上での大規模言語モデルでトークン数の制限を回避する手法の提案
大竹 啓永 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P36] LLMは真面目・不真面目になれるか?
堀尾 海斗 (早大), 河原 大輔 (早大) - [S5-P37] 言語モデルの透明性ごとに適応な可能なチューニング手法の調査
中島 京太郎 (都立大), 金 輝燦 (都立大), 平澤 寅庄 (都立大), 榎本 大晟 (都立大), 小町 守 (一橋大)
言語モデル・ニューラルネットワーク (LLM除く) / 13件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P09] 大規模言語モデルの継続事前学習における学習率設定の検討
朱 灏丞 (東北大), 李 宰成 (東北大), 岩川 光一 (東北大), 内藤 悠 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 彗音 (東北大/理研), 木村 昴 (東北大), 葉 夢宇 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研) - [S1-P11] 構成的汎化におけるTransformerの内部機序の分析
九門 涼真 (東大), 谷中 瞳 (東大) - [S1-P13] 言語の逐次性に普遍的性質はあるか?:parsing strategyの最適性からの分析
石井 太河 (東大), 宮尾 祐介 (東大) - [S1-P31] 映像中の情報に基づくマルチモーダルベースの視聴者感情推定
呉 清源 (工学院大), 福田 一帆 (工学院大)
[14:00-15:00] ポスターセッション (2)
- [S2-P04] 大規模言語モデルの事前学習ツールjax-llmの開発とinput-methodへの応用
杉浦 一瑳 (京大) - [S2-P25] 大規模言語モデルにおけるチェックポイント平均法の有効性
岩川 光一 (東北大), 内藤 悠 (東北大), 朱 灏丞 (東北大), 李 宰成 (東北大), 吉田 倖 (東北大), 矢野 一樹 (東北大), 工藤 慧音 (東北大/理研), 葉 夢宇 (東北大), 木村 昴 (東北大), 塩野 大輝 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研)
[17:50-18:50] ポスターセッション (3)
- [S3-P01] 自己改善する辞書: Sustainable Dictionary Grooming system (SDGs)
大槻 優佳 (NAIST), 矢田 竣太郎 (NAIST), 西山 智弘 (NAIST), 工藤 紀子 (NAIST), 川端 京子 (NAIST), 藤牧 貴子 (NAIST), 永井 宥之 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P14] 微分可能スタックを用いた言語創発
加藤 大地 (東大), 上田 亮 (東大), 宮尾 祐介 (東大) - [S3-P16] 透明性の高いハルシネーション判定手法の検討
長谷川 遼 (富士フイルムBI), 鷹合 基行 (富士フイルムBI) - [S3-P31] 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P08] 文埋め込み次元の冪則性のZipf則による解釈
新里 顕大 (SB Intuitions), 寺前 順之介 (京大) - [S4-P12] 認知的妥当性の高い言語モデルが生成するコーパスのテキスト分析
松尾 陽平 (同志社大), 中西(大野) 義典 (同志社大) - [S4-P24] ローカル言語モデルの速度と応答性向上に関する技術の進展
大城 慶知 (ちゅらデータ)
モデル解釈・可視化 / 17件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P02] 四方向投影システムを用いた「協働なぞなぞゲーム」のためのクイズ自動生成に向けて
増井 辰真 (愛工大), 長谷川 騎平 (愛工大), 徳久 良子 (愛工大) - [S1-P11] 構成的汎化におけるTransformerの内部機序の分析
九門 涼真 (東大), 谷中 瞳 (東大) - [S1-P40] 言語モデルは人々の意見分布をどのように予測するか
鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P08] 大規模言語モデルの説明文生成能力における忠実性改善の試み
土井 智暉 (東大), 磯沼 大 (東大/エディンバラ大), 谷中 瞳 (東大) - [S2-P15] 語順に制約されない大規模言語モデルの知識編集
石垣 龍馬 (東京電機大), 鈴木 順大 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S2-P16] A Closer Look at Task Analogies: Insights from Function and Parameter Space
吉田 晃太朗 (東工大), 楢木 悠士 (), 山木 良輔 (立命館大/ProPlace), 堀江 孝文 (立命館大), 清水 良太郎 (ZOZO研究所/カリフォルニア大), 斎藤 侑輝 (ZOZO研究所), 長沼 大樹 (モントリオール大/Mila/ProPlace) - [S2-P33] Phase Diagram of Vision Large Language Models Inference: A Perspective from Interaction across Image and Instruction
WEI Houjing (JAIST), SHI Yuting (JAIST), Cho Hakaze (JAIST), YAN Zhenzhu (JAIST), 井之上 直也 (JAIST/理研) - [S2-P36] RAGを用いたLLMによる偽情報検出手法の検討
山田 美優 (東工大), 荒瀬 由紀 (東工大)
[17:50-18:50] ポスターセッション (3)
- [S3-P08] Attentionに基づく大規模言語モデルのHallucination検出手法の検討
小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - [S3-P13] モデルマージによるタスクごとの性能変化の分析
瓦 祐希 (Fusic) - [S3-P16] 透明性の高いハルシネーション判定手法の検討
長谷川 遼 (富士フイルムBI), 鷹合 基行 (富士フイルムBI)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P04] LLMの"衝突回避" : LLMと制御理論の融合
宮岡 佑弥 (慶應大), 井上 正樹 (慶應大) - [S4-P12] 認知的妥当性の高い言語モデルが生成するコーパスのテキスト分析
松尾 陽平 (同志社大), 中西(大野) 義典 (同志社大) - [S4-P21] LLMはなぜ算数が苦手なのか? Transformerの外挿能力に関する分析
進藤 稜真 (北大), 竹下 昌志 (北大), ジェプカ ラファウ (北大), 伊藤 敏彦 (北大) - [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大)
[14:00-15:00] ポスターセッション (5)
- [S5-P02] 単語分散表現モデルの埋め込み空間を用いた概念間探索手法の構築と大規模言語モデルの機械論的解釈可能性への応用
本田 純也 (豊橋技科大/エモスタ), 小川 修平 (エモスタ), 坂本 航太郎 (東大) - [S5-P05] 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
評価指標・品質推定 / 18件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P05] 物語生成タスクにおける埋め込みを用いたLLMの創造性評価
福田 創 (早大), 河原 大輔 (早大) - [S1-P07] 大規模言語モデルによる機械翻訳の教師なし品質推定
樽本 空宙 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P28] マルチモーダルモデル自動評価のための複数タスク・複数基準評価データセット
大井 聖也 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大), 井上 中順 (東工大) - [S1-P38] 指示数増加による大規模言語モデルの指示追従性能への悪影響
原田 憲旺 (東大), 山崎 友大 (京大), 谷口 仁慈 (琉球大), 小島 武 (東大), 岩澤 有祐 (東大), 松尾 豊 (東大)
[14:00-15:00] ポスターセッション (2)
- [S2-P22] 知識蒸留モデルと合意をとる頑健な行列補完を用いた高速な確率的最小ベイズリスク復号法
夏見 昂樹 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討
伊原 滉也 (サイバーエージェント), 叶 穎睿 (サイバーエージェント), 田村 和範 (QualiArts), 岡 時生 (QualiArts), 水村 総之介 (QualiArts), 野村 将寛 (サイバーエージェント) - [S2-P36] RAGを用いたLLMによる偽情報検出手法の検討
山田 美優 (東工大), 荒瀬 由紀 (東工大)
[17:50-18:50] ポスターセッション (3)
- [S3-P06] 大規模言語モデルによるテキスト平易化における語彙レベルエラー検出の試み
WU XUANXIN (阪大), 荒瀬 由紀 (東工大) - [S3-P11] 大規模言語モデルを用いた日本語テキスト要約の自動評価
安里 優真 (JAIST), 白井 清昭 (JAIST) - [S3-P12] Text-to-audioにおける評価指標CLAP-Scoreの性能分析
高野 大成 (東大), 岡本 悠希 (東大), 齋藤 佑樹 (東大) - [S3-P24] チェックリストを利用した生成系タスクの網羅的評価
古橋 萌々香 (東北大/NII), 中山 功太 (NII), 児玉 貴志 (NII), 菅原 朔 (NII), 関根 聡 (NII/理研), 宮尾 祐介 (東大/NII) - [S3-P26] 機械翻訳の評価指標における信頼度の評価
岩國 巧 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P05] 人間とLLMが考える"面白い”は一致するのか?
坂部 立 (一橋大), 金 輝燦 (都立大), 小町 守 (一橋大) - [S4-P18] StaICC: 文脈内学習における分類タスクの標準的なベンチマーク
趙 羽風 (JAIST), 坂井 吉弘 (JAIST), 加藤 万理子 (JAIST), 井之上 直也 (JAIST/理研) - [S4-P39] 応答候補の多様性を用いた参照応答集合の評価に向けて
佐藤 魁 (東北大), 吉野 幸一郎 (東工大/理研), 河野 誠也 (理研/NAIST), 赤間 怜奈 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P15] テキスト評価におけるLLMアライメント手法の影響分析
佐藤 郁子 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 三田 雅人 (サイバーエージェント/都立大), 小町 守 (一橋大) - [S5-P23] Single promptによるhallucination事後修正
畠山 陽喜 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大) - [S5-P31] 大規模言語モデルにおける相転移と自然言語の関係
中石 海 (東大), 西川 宜彦 (北里大), 福島 孝治 (東大)
少数データ・データ拡張 / 7件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P21] 大規模言語モデルを用いたオノマトペ付与による日本語音声データセットの拡張
小川 剛毅 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大)
[14:00-15:00] ポスターセッション (2)
- [S2-P23] 敵対的学習を用いた記号的知識蒸留
日浦 隆博 (NAIST/理研), 河野 誠也 (理研/NAIST), Garcia Contreras Angel Fernando (理研), 吉野 幸一郎 (東工大/理研/NAIST) - [S2-P29] クローリングによるコモンクロールを補完した日本語コーパス拡充の検討
石原 慧人 (LINEヤフー), 永井 隆広 (LINEヤフー), 平田 航大 (LINEヤフー), 岸本 耀平 (LINEヤフー), 中野 佑哉 (LINEヤフー) - [S2-P34] 大規模言語モデルによる日本語テキスト平易化のためのパラレルコーパスフィルタリング
前川 大輔 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大)
[17:50-18:50] ポスターセッション (3)
- [S3-P21] 科学技術文献における知識グラフ補完を用いた効率的な知識グラフの作成
神野 倫行 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P31] アノテーション基準の違いを考慮した複数データセットからの固有表現抽出の学習
大井 拓 (豊田工大), 三輪 誠 (豊田工大)
[14:00-15:00] ポスターセッション (5)
- [S5-P11] LLMを用いた文書分類のためのData Augmentationの検討
小野寺 優 (茨大), 新納 浩幸 (茨大)
言語資源・アノテーション / 26件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P03] NLP J Anthology BTPPコーパス: 自然言語処理分野の論文調査支援を目的とした英日翻訳後処理コーパスの作成
中町 礼文 (janthology.jp), 西原 大貴 (janthology.jp) - [S1-P06] プライベート空間における人-エージェント間雑談対話データセットの構築に向けて
邊土名 朝飛 (サイバーエージェント), 岩田 伸治 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 稲本 雄太 (サイバーエージェント), 栗原 健太郎 (AI Shift) - [S1-P24] WordNetは現代英語話者の意味関係知識の反映しているか?:クラウンドソーシングによる一致度の調査
Cao Zhihan (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大) - [S1-P25] 大規模言語モデルによる日本文化に沿った指示データ生成
塩谷 泰平 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P28] マルチモーダルモデル自動評価のための複数タスク・複数基準評価データセット
大井 聖也 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大), 井上 中順 (東工大) - [S1-P32] 医療事故内容から背景・原因、および改善策を生成する為のデータセット構築
長谷山 優菜 (北大), 伊藤 友貴 (三井物産), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S1-P37] 日本語医療LLM評価ベンチマークの構築と性能分析
福島 拓也 (NAIST), 久田 祥平 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P23] 敵対的学習を用いた記号的知識蒸留
日浦 隆博 (NAIST/理研), 河野 誠也 (理研/NAIST), Garcia Contreras Angel Fernando (理研), 吉野 幸一郎 (東工大/理研/NAIST) - [S2-P29] クローリングによるコモンクロールを補完した日本語コーパス拡充の検討
石原 慧人 (LINEヤフー), 永井 隆広 (LINEヤフー), 平田 航大 (LINEヤフー), 岸本 耀平 (LINEヤフー), 中野 佑哉 (LINEヤフー) - [S2-P35] タスク特徴を考慮したマッチング制約下におけるアノテーション割り当て
守山 慧 (東大), 中山 功太 (NII), 馬場 雪乃 (東大) - [S2-P37] X上の情報カスケードにおける情報変容のアノテーション
遠田 哲史 (東大), 吉永 直樹 (東大), 豊田 正史 (東大)
[17:50-18:50] ポスターセッション (3)
- [S3-P01] 自己改善する辞書: Sustainable Dictionary Grooming system (SDGs)
大槻 優佳 (NAIST), 矢田 竣太郎 (NAIST), 西山 智弘 (NAIST), 工藤 紀子 (NAIST), 川端 京子 (NAIST), 藤牧 貴子 (NAIST), 永井 宥之 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P22] ESG情報抽出データセットの検討
赤部 晃一 (シェルパ・アンド・カンパニー), 前田 航希 (シェルパ・アンド・カンパニー/東工大), 栗田 修平 (NII), 小田 悠介 (シェルパ・アンド・カンパニー/NII) - [S3-P27] 学術論文におけるGraphical Abstract自動生成の初期検討
川田 拓朗 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S3-P33] 小規模で高性能なLLMのための高品質事前学習Webコーパスの構築
服部 翔 (東工大/産総研), 水木 栄 (東工大/産総研), 藤井 一喜 (東工大/産総研), 中村 泰士 (東工大/産総研), 大井 聖也 (東工大/産総研), Ma Youmi (東工大), 前田 航希 (東工大), 塩谷 泰平 (東工大), 齋藤 幸史郎 (東工大), 岡本 拓己 (東工大), 石田 茂樹 (東工大), 横田 理央 (東工大/産総研), 高村 大也 (産総研), 岡崎 直観 (東工大/産総研) - [S3-P38] Japanese MT-bench++: より自然なマルチターン対話設定における大規模日本語ベンチマーク
植松 拓也 (早大), 河原 大輔 (早大), 柴田 知秀 (LINEヤフー)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P11] 企業沿革のグラフ構造化に向けた企業変遷イベント抽出タスクの構築と分析
澤田 悠冶 (NAIST/理研), 大内 啓樹 (NAIST/理研/国語研), 安井 雄一郎 (日経新聞社), 寺西 裕紀 (理研/NAIST), 渡辺 太郎 (NAIST), 松本 裕治 (理研), 石井 昌之 (日経新聞社) - [S4-P14] SubRegWeigh: サブワード正則化による高速アノテーション補正
辻 航平 (NAIST), 平岡 達也 (MBZUAI), 鄭 育昌 (富士通), 岩倉 友哉 (富士通) - [S4-P15] The Manga Visual Narrative Treebank
馮 思遠 (東大), 林 克彦 (東大), 小倉 甲陽 (東大), 富田 雅代 (東大), 上垣外 英剛 (NAIST) - [S4-P18] StaICC: 文脈内学習における分類タスクの標準的なベンチマーク
趙 羽風 (JAIST), 坂井 吉弘 (JAIST), 加藤 万理子 (JAIST), 井之上 直也 (JAIST/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P04] 自動運転のための言語・視覚・動作の統合データセットの構築
三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - [S5-P12] エピソードへの主体性アノテーション:well-beingのさらなる理解に向けて
林 純子 (NAIST), 永井 宥之 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S5-P14] 言語モデルの日本語道徳理解能力の評価データセットの構築
竹下 昌志 (北大), ジェプカ ラファウ (北大) - [S5-P16] ニューラル単語アライメントによる言い換え辞書の改善
近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S5-P17] 情報科学分野における学会発表タイトルの分野推定データセットの構築
宮田 莉奈 (愛媛大), 眞鍋 光汰 (愛媛大), 福島 啓太 (愛媛大), 花房 健太郎 (愛媛大), 高田 一慶 (愛媛大), 梶原 智之 (愛媛大), 桂井 麻里衣 (同志社大), 二宮 崇 (愛媛大) - [S5-P34] 歴史災害史料を対象とした地名の自動抽出
武内 樹治 (奈良文化財研究所), 大内 啓樹 (NAIST), 東山 翔平 (NICT)
単語分割・形態素解析 / 1件
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P14] SubRegWeigh: サブワード正則化による高速アノテーション補正
辻 航平 (NAIST), 平岡 達也 (MBZUAI), 鄭 育昌 (富士通), 岩倉 友哉 (富士通)
埋め込み表現 / 22件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P05] 物語生成タスクにおける埋め込みを用いたLLMの創造性評価
福田 創 (早大), 河原 大輔 (早大) - [S1-P10] 不均衡最適輸送を用いた意味変化検出
岸野 稜 (京大), 山際 宏明 (京大), 永田 亮 (甲南大/理研), 横井 祥 (東北大/理研), 下平 英寿 (京大/理研) - [S1-P27] 商品検索のための追加事前学習としての言い換えに基づく対照学習
杉山 誠治 (愛媛大), 近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P29] 教師なし条件付きテキスト埋め込みの獲得
山田 康輔 (サイバーエージェント), 張 培楠 (サイバーエージェント) - [S1-P35] 大規模モデルの蒸留を用いた日本語文埋め込みモデル
矢野 千紘 (PKSHA), 呉 孟超 (PKSHA), 橘 秀幸 (PKSHA), 竹川 洋都 (PKSHA), 渡邉 陽太郎 (PKSHA)
[14:00-15:00] ポスターセッション (2)
- [S2-P02] 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研) - [S2-P10] 人の言語を模倣するのに必要十分な言語モデルの大きさはどれだけか
山本 悠士 (東京理科大), 上田 亮 (東大), 唐木田 亮 (産総研), 横井 祥 (東北大/理研) - [S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討
伊原 滉也 (サイバーエージェント), 叶 穎睿 (サイバーエージェント), 田村 和範 (QualiArts), 岡 時生 (QualiArts), 水村 総之介 (QualiArts), 野村 将寛 (サイバーエージェント)
[17:50-18:50] ポスターセッション (3)
- [S3-P28] 日本語に特化した汎用テキスト埋め込みモデルの開発
塚越 駿 (名大), 笹野 遼平 (名大) - [S3-P31] 層同士の接続可能性と各層が影響を与える部分空間の重なり度合いの関係性
小林 春斗 (東北大), 原 知正 (東北大), 鴨田 豪 (東北大), 横井 祥 (東北大/理研) - [S3-P32] 画像とテキストの共通構造はV&Lモデルにいかなる形で埋め込まれているか
志子田 直輝 (NAIST), 横井 祥 (東北大/理研), 渡辺 太郎 (NAIST) - [S3-P36] Sarashina-Embedding: LLMをベースにした日本語埋め込みモデルの構築
福地 成彦 (SB Intuitions), 李 聖哲 (SB Intuitions), 李 凌寒 (SB Intuitions), 大萩 雅也 (SB Intuitions), 柴田 知秀 (SB Intuitions) - [S3-P37] 和歌埋め込みモデルの構築とそれを用いた本歌取りの分析
小川 隼斗 (早大), 河原 大輔 (早大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P08] 文埋め込み次元の冪則性のZipf則による解釈
新里 顕大 (SB Intuitions), 寺前 順之介 (京大) - [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大) - [S4-P25] 日本語の単語を対象とした複数時期の意味変化パターン分析
木山 朔 (都立大), 相田 太一 (都立大), 小町 守 (一橋大), 小木曽 智信 (国語研), 高村 大也 (産総研), 持橋 大地 (統数研) - [S4-P32] 語彙拡張を適用する継続事前学習における初期値学習法
李 宰成 (東北大), 吉田 倖 (東北大), 朱 灏丞 (東北大), 内藤 悠 (東北大), 岩川 光一 (東北大), 工藤 慧音 (東北大/理研), 塩野 大輝 (東北大), 葉 夢宇 (東北大), 木村 昴 (東北大), 矢野 一樹 (東北大), 佐々木 翔大 (サイバーエージェント/東北大), 斉藤 いつみ (東北大/理研), 赤間 怜奈 (東北大/理研), 鈴木 潤 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P01] 書誌情報の複数項目との関係を考慮した柔軟な論文検索システム
井田 龍希 (豊田工大), 三輪 誠 (豊田工大) - [S5-P02] 単語分散表現モデルの埋め込み空間を用いた概念間探索手法の構築と大規模言語モデルの機械論的解釈可能性への応用
本田 純也 (豊橋技科大/エモスタ), 小川 修平 (エモスタ), 坂本 航太郎 (東大) - [S5-P05] 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P30] 検索クリックログに基づくクエリ理解に特化した埋め込み
西川 荘介 (LINEヤフー), 平子 潤 (LINEヤフー), 佐野 峻平 (LINEヤフー), 浅野 広樹 (LINEヤフー), 渡邉 幸暉 (LINEヤフー), 山城 颯太 (LINEヤフー), 鍜治 伸裕 (LINEヤフー) - [S5-P39] 多様なモダリティの属性情報をハイパーグラフにより統合したエンティティ表現の獲得
西出 隆盛 (豊田工大), 三輪 誠 (豊田工大)
構文解析・意味解析・共参照解析 / 7件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P13] 言語の逐次性に普遍的性質はあるか?:parsing strategyの最適性からの分析
石井 太河 (東大), 宮尾 祐介 (東大)
[17:50-18:50] ポスターセッション (3)
- [S3-P23] LLMによる項構造依存関係解析の検証: 読み時間・容認性判断データとの比較と認知モデリング
木村 一馬 (筑波大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P23] Derivational Probing:言語モデルにおける統語構造構築の解明
染谷 大河 (東大), 吉田 遼 (東大), 谷中 瞳 (東大), 大関 洋平 (東大) - [S4-P25] 日本語の単語を対象とした複数時期の意味変化パターン分析
木山 朔 (都立大), 相田 太一 (都立大), 小町 守 (一橋大), 小木曽 智信 (国語研), 高村 大也 (産総研), 持橋 大地 (統数研) - [S4-P37] 形式証明の逆形式化を通じた自然言語証明テキストの構造解析
服部 清志 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大)
[14:00-15:00] ポスターセッション (5)
- [S5-P06] Text-to-SQLのためのテーブルデータを用いたカラムフィルタリング
野口 輝 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大) - [S5-P22] 意味表現のグラフ構造を考慮したフレーズアブダクションの改良
北村 優佳 (東大), 谷中 瞳 (東大)
情報抽出・知識獲得 / 27件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P04] Vision And Languageモデルにおける異なるドメインでの継続事前学習が後段タスクに与える影響の検証
齋藤 慎一朗 (Sansan) - [S1-P10] 不均衡最適輸送を用いた意味変化検出
岸野 稜 (京大), 山際 宏明 (京大), 永田 亮 (甲南大/理研), 横井 祥 (東北大/理研), 下平 英寿 (京大/理研) - [S1-P12] 既読文書の関係を考慮できる関係抽出
松原 拓磨 (豊田工大), 三輪 誠 (豊田工大)
[14:00-15:00] ポスターセッション (2)
- [S2-P18] オンライン動画サービスにおけるBERT及び大規模言語モデルを用いた視聴者感情の推定
菅野 祐希 (工学院大), 坂野 遼平 (一橋大) - [S2-P19] テキストおよびSNSデータを活用したフェイクニュース検出に関する検討
沈 瑋彦 (工学院大), 坂野 遼平 (一橋大) - [S2-P21] LLMを用いた生成による階層的イベントの抽出
金児 一矢 (豊田工大), 三輪 誠 (豊田工大) - [S2-P23] 敵対的学習を用いた記号的知識蒸留
日浦 隆博 (NAIST/理研), 河野 誠也 (理研/NAIST), Garcia Contreras Angel Fernando (理研), 吉野 幸一郎 (東工大/理研/NAIST) - [S2-P24] 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大) - [S2-P28] 大規模言語モデルによる感情極性に着目した小説からの人物関係抽出
齋藤 大輔 (名工大), 李 晃伸 (名工大), 上乃 聖 (名工大)
[17:50-18:50] ポスターセッション (3)
- [S3-P15] 大規模言語モデルによって医療テキストの固有表現処理はどこまで簡単になったか
西林 孝 (Ubie), 横井 祥 (東北大/理研) - [S3-P17] ステップごとの推論における情報補完のカテゴリ別分析
三浦 東子 (東北大), 谷口 雅弥 (理研), 坂口 慶祐 (東北大/理研), 乾 健太郎 (東北大/理研/MBZUAI) - [S3-P20] ノイズを含む日本語テキストデータにおける固有表現抽出手法の検証
尾城 奈緒子 (インテージ), 竹村 彰浩 (インテージ) - [S3-P21] 科学技術文献における知識グラフ補完を用いた効率的な知識グラフの作成
神野 倫行 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S3-P22] ESG情報抽出データセットの検討
赤部 晃一 (シェルパ・アンド・カンパニー), 前田 航希 (シェルパ・アンド・カンパニー/東工大), 栗田 修平 (NII), 小田 悠介 (シェルパ・アンド・カンパニー/NII) - [S3-P32] 画像とテキストの共通構造はV&Lモデルにいかなる形で埋め込まれているか
志子田 直輝 (NAIST), 横井 祥 (東北大/理研), 渡辺 太郎 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P11] 企業沿革のグラフ構造化に向けた企業変遷イベント抽出タスクの構築と分析
澤田 悠冶 (NAIST/理研), 大内 啓樹 (NAIST/理研/国語研), 安井 雄一郎 (日経新聞社), 寺西 裕紀 (理研/NAIST), 渡辺 太郎 (NAIST), 松本 裕治 (理研), 石井 昌之 (日経新聞社) - [S4-P14] SubRegWeigh: サブワード正則化による高速アノテーション補正
辻 航平 (NAIST), 平岡 達也 (MBZUAI), 鄭 育昌 (富士通), 岩倉 友哉 (富士通) - [S4-P27] 質問応答による関係抽出のための有効な質問選択手法
山田 晃士 (豊田工大), 三輪 誠 (豊田工大) - [S4-P30] Generating Explainable Recommendations of Documents through Personalized Knowledge Graphs Based on User Activity
アフザル ナヴィード (ストックマーク), 広田 航 (ストックマーク) - [S4-P31] アノテーション基準の違いを考慮した複数データセットからの固有表現抽出の学習
大井 拓 (豊田工大), 三輪 誠 (豊田工大) - [S4-P34] 大規模言語モデルの知識は何に由来して記憶されるか?
西田 悠人 (NAIST/フューチャー), 岸波 洋介 (フューチャー), 藤井 諒 (フューチャー), 森下 睦 (フューチャー)
[14:00-15:00] ポスターセッション (5)
- [S5-P01] 書誌情報の複数項目との関係を考慮した柔軟な論文検索システム
井田 龍希 (豊田工大), 三輪 誠 (豊田工大) - [S5-P16] ニューラル単語アライメントによる言い換え辞書の改善
近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S5-P20] 機械学習用データセットの説明文における数値情報の自動抽出
嘉本 名晋 (同志社大), 長尾 浩良 (同志社大), 桂井 麻里衣 (同志社大) - [S5-P34] 歴史災害史料を対象とした地名の自動抽出
武内 樹治 (奈良文化財研究所), 大内 啓樹 (NAIST), 東山 翔平 (NICT) - [S5-P38] 視写課題の自動採点へ向けた 子供らしい文字の自動生成による OCR 精度の向上
関 歩実 (東京理科大), 松崎 拓也 (東京理科大) - [S5-P39] 多様なモダリティの属性情報をハイパーグラフにより統合したエンティティ表現の獲得
西出 隆盛 (豊田工大), 三輪 誠 (豊田工大)
読解・含意・質問応答 / 7件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P02] 四方向投影システムを用いた「協働なぞなぞゲーム」のためのクイズ自動生成に向けて
増井 辰真 (愛工大), 長谷川 騎平 (愛工大), 徳久 良子 (愛工大)
[14:00-15:00] ポスターセッション (2)
- [S2-P07] 強化学習に基づく難易度制御を組み込んだ多肢選択式読解問題自動生成手法の開発
富川 雄斗 (電通大), 宇都 雅輝 (電通大)
[17:50-18:50] ポスターセッション (3)
- [S3-P09] マルチエージェント協働による TRPG ゲームマスターの実現
箕成 侑音 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S3-P10] LLMの論理推論能力は図的表現の使用により改善するか:オイラー図つき三段論法データセットNeuBAROCOを用いた分析
安東 里沙子 (慶應大), 小関 健太郎 (東大/慶應大), 森下 貴允 (慶應大), 阿部 裕彦 (慶應大), 峯島 宏次 (慶應大), 岡田 光弘 (慶應大) - [S3-P38] Japanese MT-bench++: より自然なマルチターン対話設定における大規模日本語ベンチマーク
植松 拓也 (早大), 河原 大輔 (早大), 柴田 知秀 (LINEヤフー)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P27] 質問応答による関係抽出のための有効な質問選択手法
山田 晃士 (豊田工大), 三輪 誠 (豊田工大)
[14:00-15:00] ポスターセッション (5)
- [S5-P22] 意味表現のグラフ構造を考慮したフレーズアブダクションの改良
北村 優佳 (東大), 谷中 瞳 (東大)
文書分類 / 6件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P19] 豪雨と地震におけるクロノロジーの優先度推定
孝壽 真治 (岡山大), 竹内 孔一 (岡山大), 渡邉 暁洋 (兵庫医科大), 平山 隆浩 (岡山大), 中尾 博之 (大阪行岡医療大)
[14:00-15:00] ポスターセッション (2)
- [S2-P05] LLMを用いた自由記述アンケートの質的分析
橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST)
[17:50-18:50] ポスターセッション (3)
- [S3-P25] LLMを用いたCT読影レポートの撮影目的分類
峯 悠大 (NAIST), 西山 智弘 (NAIST), 谷 懿 (NAIST), 大竹 義人 (NAIST), 佐藤 嘉伸 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P12] 認知的妥当性の高い言語モデルが生成するコーパスのテキスト分析
松尾 陽平 (同志社大), 中西(大野) 義典 (同志社大) - [S4-P13] 強化学習を利用した訓練データの価値評価手法に基づく問題横断型自動採点手法
柴田 拓海 (電通大), 宇都 雅輝 (電通大)
[14:00-15:00] ポスターセッション (5)
- [S5-P11] LLMを用いた文書分類のためのData Augmentationの検討
小野寺 優 (茨大), 新納 浩幸 (茨大)
感情分析・評判分析 / 9件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P31] 映像中の情報に基づくマルチモーダルベースの視聴者感情推定
呉 清源 (工学院大), 福田 一帆 (工学院大)
[14:00-15:00] ポスターセッション (2)
- [S2-P17] おやつプロジェクト: おすすめスイーツ店の個人レビュー要約
岩本 蘭 (IBM/慶應大), 大内 啓樹 (NAIST/サイバーエージェント), 金山 博 (IBM), 吉田 光男 (筑波大) - [S2-P18] オンライン動画サービスにおけるBERT及び大規模言語モデルを用いた視聴者感情の推定
菅野 祐希 (工学院大), 坂野 遼平 (一橋大) - [S2-P28] 大規模言語モデルによる感情極性に着目した小説からの人物関係抽出
齋藤 大輔 (名工大), 李 晃伸 (名工大), 上乃 聖 (名工大) - [S2-P30] ユーザの発話からの自我状態推定を用いた対話システムの検討
掛川 脩人 (東京電機大), 山田 剛一 (東京電機大), 増田 英孝 (東京電機大)
[17:50-18:50] ポスターセッション (3)
- [S3-P05] 大規模言語モデルを用いた効果的な物語のあらすじ生成手法の検討
酒井 健壱 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P26] パブリックアートは人を幸せにするのか
祖父江 智子 (NAIST), 伊藤 和浩 (NAIST), 古賀 千絵 (東大), 吉村 有司 (東大), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S4-P28] 掲示板テキストから得られるセンチメントを利用した日経平均株価ボラティリティ予測
中島 秀太 (一橋大), 欅 惇志 (一橋大), 渡部 敏明 (一橋大), 小町 守 (一橋大)
[14:00-15:00] ポスターセッション (5)
- [S5-P21] マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
検索・推薦 / 14件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P15] 事前学習–文脈内学習パラダイムで生じる頻度バイアスの較正
伊藤 郁海 (東北大), 鴨田 豪 (東北大), 熊谷 雄介 (博報堂DYホールディングス), 横井 祥 (東北大/理研) - [S1-P27] 商品検索のための追加事前学習としての言い換えに基づく対照学習
杉山 誠治 (愛媛大), 近藤 里咲 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S1-P33] RAGにおけるLLMの性能の影響
阿部 晃弥 (茨大), 新納 浩幸 (茨大) - [S1-P35] 大規模モデルの蒸留を用いた日本語文埋め込みモデル
矢野 千紘 (PKSHA), 呉 孟超 (PKSHA), 橘 秀幸 (PKSHA), 竹川 洋都 (PKSHA), 渡邉 陽太郎 (PKSHA)
[14:00-15:00] ポスターセッション (2)
- [S2-P02] 柔らかいgrep/KWICに向けて:高速単語列マッチングの埋め込み表現による連続化
出口 祥之 (NAIST), 鴨田 豪 (東北大), 松下 祐介 (京大), 慶田 開 (京大), 和賀 正樹 (京大), 横井 祥 (東北大/理研) - [S2-P24] 有価証券報告書を対象とした質問応答タスクのデータセット構築とLLMを用いた手法の評価
佐藤 栄作 (小樽商大), 木村 泰知 (小樽商大) - [S2-P26] ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV)
[17:50-18:50] ポスターセッション (3)
- [S3-P28] 日本語に特化した汎用テキスト埋め込みモデルの開発
塚越 駿 (名大), 笹野 遼平 (名大) - [S3-P36] Sarashina-Embedding: LLMをベースにした日本語埋め込みモデルの構築
福地 成彦 (SB Intuitions), 李 聖哲 (SB Intuitions), 李 凌寒 (SB Intuitions), 大萩 雅也 (SB Intuitions), 柴田 知秀 (SB Intuitions)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P30] Generating Explainable Recommendations of Documents through Personalized Knowledge Graphs Based on User Activity
アフザル ナヴィード (ストックマーク), 広田 航 (ストックマーク)
[14:00-15:00] ポスターセッション (5)
- [S5-P01] 書誌情報の複数項目との関係を考慮した柔軟な論文検索システム
井田 龍希 (豊田工大), 三輪 誠 (豊田工大) - [S5-P09] LLMを用いて説明文を生成する対話型映画推薦システム
麻野 健太郎 (芝浦工大), 杉本 徹 (芝浦工大) - [S5-P18] 自然言語モデルを活用した同件不具合検出システムを用いたシステムテスト品質の向上
松尾 正裕 (パナソニックITS) - [S5-P30] 検索クリックログに基づくクエリ理解に特化した埋め込み
西川 荘介 (LINEヤフー), 平子 潤 (LINEヤフー), 佐野 峻平 (LINEヤフー), 浅野 広樹 (LINEヤフー), 渡邉 幸暉 (LINEヤフー), 山城 颯太 (LINEヤフー), 鍜治 伸裕 (LINEヤフー)
自然言語生成 / 23件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P01] 四方向投影システムを用いた子どもたちの協働による「学びの質」の評価方法の検討
長谷川 騎平 (愛工大), 増井 辰真 (愛工大), 徳久 良子 (愛工大) - [S1-P02] 四方向投影システムを用いた「協働なぞなぞゲーム」のためのクイズ自動生成に向けて
増井 辰真 (愛工大), 長谷川 騎平 (愛工大), 徳久 良子 (愛工大) - [S1-P30] 雑談対話システムにおけるユーモア応答生成
佐藤 光 (芝浦工大), 杉本 徹 (芝浦工大) - [S1-P33] RAGにおけるLLMの性能の影響
阿部 晃弥 (茨大), 新納 浩幸 (茨大) - [S1-P40] 言語モデルは人々の意見分布をどのように予測するか
鈴木 刀磨 (NAIST), 片山 歩希 (NAIST), 郷原 聖士 (NAIST), 辻本 陵 (NAIST), 中谷 響 (NAIST), 林 和樹 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P08] 大規模言語モデルの説明文生成能力における忠実性改善の試み
土井 智暉 (東大), 磯沼 大 (東大/エディンバラ大), 谷中 瞳 (東大) - [S2-P22] 知識蒸留モデルと合意をとる頑健な行列補完を用いた高速な確率的最小ベイズリスク復号法
夏見 昂樹 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S2-P30] ユーザの発話からの自我状態推定を用いた対話システムの検討
掛川 脩人 (東京電機大), 山田 剛一 (東京電機大), 増田 英孝 (東京電機大) - [S2-P34] 大規模言語モデルによる日本語テキスト平易化のためのパラレルコーパスフィルタリング
前川 大輔 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大) - [S2-P40] 人工知能ラッパーの実現に向けて
織田 宥楽 (早大), 小川 隼斗 (早大), 河原 大輔 (早大)
[17:50-18:50] ポスターセッション (3)
- [S3-P06] 大規模言語モデルによるテキスト平易化における語彙レベルエラー検出の試み
WU XUANXIN (阪大), 荒瀬 由紀 (東工大) - [S3-P19] 平易化への_Task Arithmetic_の応用とその検証
小西 修平 (NHK)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P01] 行動認識の粒度アライメントに基づく予定の履行認識
藤田 一天 (NAIST/理研), 吉野 幸一郎 (東工大/理研/NAIST), 河野 誠也 (理研/NAIST) - [S4-P02] 早押しクイズのための音声合成システムの開発にむけて
高田 敦嗣 (愛工大), 徳久 良子 (愛工大), 玉森 聡 (愛工大) - [S4-P17] 大規模言語モデルによる授業発話の影響推定に基づいたアドバイス生成
大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S4-P19] _なぜ機械翻訳モデルの推定確率と人手評価の相関係数が低いのか?_:原因分析と改善策の検討
呂 博軒 (東工大), 上垣外 英剛 (NAIST), 船越 孝太郎 (東工大), 奥村 学 (東工大) - [S4-P24] ローカル言語モデルの速度と応答性向上に関する技術の進展
大城 慶知 (ちゅらデータ) - [S4-P37] 形式証明の逆形式化を通じた自然言語証明テキストの構造解析
服部 清志 (東京理科大), 松崎 拓也 (東京理科大), 藤原 誠 (東京理科大)
[14:00-15:00] ポスターセッション (5)
- [S5-P09] LLMを用いて説明文を生成する対話型映画推薦システム
麻野 健太郎 (芝浦工大), 杉本 徹 (芝浦工大) - [S5-P13] 作曲学習支援のための音楽と言語のマルチモーダルモデルに向けて
稲葉 達郎 (京大) - [S5-P19] 人狼知能における論理的推論のためのBDI Proverと大規模言語モデルの利用
権藤 拓 (北大), 坂地 泰紀 (北大), 野田 五十樹 (北大) - [S5-P27] 授業発話の分類に基づく教員へのアドバイス生成
児嶋 祥成 (岡山理大), 大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S5-P33] Enhancing Biomedical Summarization with External Knowledge Integration via Retrieval-Augmented Generation
羅 冠霆 (阪大), 荒瀬 由紀 (東工大)
機械翻訳 / 4件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P07] 大規模言語モデルによる機械翻訳の教師なし品質推定
樽本 空宙 (愛媛大), 梶原 智之 (愛媛大), 二宮 崇 (愛媛大)
[14:00-15:00] ポスターセッション (2)
- [S2-P22] 知識蒸留モデルと合意をとる頑健な行列補完を用いた高速な確率的最小ベイズリスク復号法
夏見 昂樹 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
[17:50-18:50] ポスターセッション (3)
- [S3-P26] 機械翻訳の評価指標における信頼度の評価
岩國 巧 (NAIST), 出口 祥之 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P19] _なぜ機械翻訳モデルの推定確率と人手評価の相関係数が低いのか?_:原因分析と改善策の検討
呂 博軒 (東工大), 上垣外 英剛 (NAIST), 船越 孝太郎 (東工大), 奥村 学 (東工大)
要約 / 6件
9/5(木): シンポジウム2日目
[14:00-15:00] ポスターセッション (2)
- [S2-P05] LLMを用いた自由記述アンケートの質的分析
橋本 清斗 (NAIST), 荒牧 英治 (NAIST), 若宮 翔子 (NAIST), 矢田 竣太郎 (NAIST), 工藤 紀子 (NAIST)
[17:50-18:50] ポスターセッション (3)
- [S3-P05] 大規模言語モデルを用いた効果的な物語のあらすじ生成手法の検討
酒井 健壱 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S3-P11] 大規模言語モデルを用いた日本語テキスト要約の自動評価
安里 優真 (JAIST), 白井 清昭 (JAIST) - [S3-P40] 採点基準を元に自律的に採点ツールの選択と適用を行う英文要約自動採点システム
藤田 晃輔 (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P01] 行動認識の粒度アライメントに基づく予定の履行認識
藤田 一天 (NAIST/理研), 吉野 幸一郎 (東工大/理研/NAIST), 河野 誠也 (理研/NAIST)
[14:00-15:00] ポスターセッション (5)
- [S5-P33] Enhancing Biomedical Summarization with External Knowledge Integration via Retrieval-Augmented Generation
羅 冠霆 (阪大), 荒瀬 由紀 (東工大)
誤り訂正 / 4件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P18] 児童の読解力向上を目的とした音読支援システムの開発
齊藤 新 (東京理科大), 松崎 拓也 (東京理科大)
[17:50-18:50] ポスターセッション (3)
- [S3-P08] Attentionに基づく大規模言語モデルのHallucination検出手法の検討
小笠 雄也 (阪大), 梶原 智之 (愛媛大), 荒瀬 由紀 (東工大) - [S3-P16] 透明性の高いハルシネーション判定手法の検討
長谷川 遼 (富士フイルムBI), 鷹合 基行 (富士フイルムBI)
9/6(金): シンポジウム3日目
[14:00-15:00] ポスターセッション (5)
- [S5-P23] Single promptによるhallucination事後修正
畠山 陽喜 (東京電機大), 酒造 正樹 (東京電機大), 前田 英作 (東京電機大)
談話理解・対話 / 19件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P01] 四方向投影システムを用いた子どもたちの協働による「学びの質」の評価方法の検討
長谷川 騎平 (愛工大), 増井 辰真 (愛工大), 徳久 良子 (愛工大) - [S1-P02] 四方向投影システムを用いた「協働なぞなぞゲーム」のためのクイズ自動生成に向けて
増井 辰真 (愛工大), 長谷川 騎平 (愛工大), 徳久 良子 (愛工大) - [S1-P06] プライベート空間における人-エージェント間雑談対話データセットの構築に向けて
邊土名 朝飛 (サイバーエージェント), 岩田 伸治 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 稲本 雄太 (サイバーエージェント), 栗原 健太郎 (AI Shift) - [S1-P17] ゲームの台詞を題材としたキャラクターらしさを構成する要素の検討
岩田 伸治 (サイバーエージェント), 伊原 滉也 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 馬場 惇 (サイバーエージェント), 邊土名 朝飛 (サイバーエージェント), 山﨑 眞洋 (QualiArts), 塩塚 勇気 (QualiArts), 吉本 暁文 (サイバーエージェント)
[14:00-15:00] ポスターセッション (2)
- [S2-P01] 「ふわふわ」「もったり」ってどう表現するの? ーエージェントとの豊かなコミュニケーションの実現に向けてー
肥田 京佳 (愛工大), 市川 淳貴 (愛工大), 徳久 良子 (愛工大) - [S2-P03] 日常会話を通じて心の健康を支援するヴァーチャルエージェントの試作
泉 健太 (SB Intuitions), Liu Lianbo (SB Intuitions), 大萩 雅也 (SB Intuitions), 山崎 天 (SB Intuitions) - [S2-P30] ユーザの発話からの自我状態推定を用いた対話システムの検討
掛川 脩人 (東京電機大), 山田 剛一 (東京電機大), 増田 英孝 (東京電機大) - [S2-P32] 社会的価値観の融和を誘導する対話システムの開発
小林 涼太郎 (東大), 高柳 剛弘 (東大), 鈴木 雅弘 (東大), 小倉 有紀子 (北大), 坂地 泰紀 (北大)
[17:50-18:50] ポスターセッション (3)
- [S3-P02] ラップの原則に基づく生成手法の検討
淡島 英輝 (ちゅらデータ) - [S3-P03] ユーザレビュー作成支援を目的とした対話システムの活用法の提案
田中 義規 (電通大), 稲葉 通将 (電通大) - [S3-P38] Japanese MT-bench++: より自然なマルチターン対話設定における大規模日本語ベンチマーク
植松 拓也 (早大), 河原 大輔 (早大), 柴田 知秀 (LINEヤフー)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P07] LLMを用いた睡眠カウンセリング対話システムの検討
大橋 玲音 (愛知県立大), 我妻 信実 (愛知県立大), 中山 怜士 (愛知県立大), 野村 光 (愛知県立大), 石川 舞一 (愛知県立大), 伊藤 にい奈 (愛知県立大), 伊藤 芙久佳 (愛知県立大), 南 詩織 (愛知県立大), 金田 修香 (愛知県立大), 檜物 春佳 (愛知県立大), 中村 莉子 (愛知県立大), 西尾 優亜 (愛知県立大), 鈴木 丈慈 (愛知県立大), 坪倉 和哉 (愛知県立大), 横山 加奈 (愛知県立大) - [S4-P15] The Manga Visual Narrative Treebank
馮 思遠 (東大), 林 克彦 (東大), 小倉 甲陽 (東大), 富田 雅代 (東大), 上垣外 英剛 (NAIST) - [S4-P36] 個人の主観評価データに基づく対話システムの発話評価手法の検討
亀山 京右 (阪大), 堅田 俊 (阪大), 駒谷 和範 (阪大) - [S4-P38] 内心描写付きの対話データを用いた非著名人の性格特性再現
石倉 誠也 (東工大), 山田 寛章 (東工大), 平岡 達也 (MBZUAI), 山田 広明 (富士通), 徳永 健伸 (東工大) - [S4-P39] 応答候補の多様性を用いた参照応答集合の評価に向けて
佐藤 魁 (東北大), 吉野 幸一郎 (東工大/理研), 河野 誠也 (理研/NAIST), 赤間 怜奈 (東北大/理研)
[14:00-15:00] ポスターセッション (5)
- [S5-P08] Exploring Mixed Time Systems in Large Language Models for Temporal Reasoning
孫 飛飛 (JAIST), 童 子芸 (JAIST), Nguyen Le Minh (JAIST) - [S5-P28] SNSカウンセラー育成のためのリアルタイム対話支援システムの構築
斉 志揚 (電通大), 稲葉 通将 (電通大) - [S5-P32] 動機づけ面接におけるクライエントの発話分類に基づく応答生成
金子 優 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大)
マルチモーダル / 31件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P04] Vision And Languageモデルにおける異なるドメインでの継続事前学習が後段タスクに与える影響の検証
齋藤 慎一朗 (Sansan) - [S1-P06] プライベート空間における人-エージェント間雑談対話データセットの構築に向けて
邊土名 朝飛 (サイバーエージェント), 岩田 伸治 (サイバーエージェント), 佐藤 志貴 (サイバーエージェント), 稲本 雄太 (サイバーエージェント), 栗原 健太郎 (AI Shift) - [S1-P14] 日本手話における検索や解析のための柔軟な表現の獲得
井上 純大 (豊田工大), 原 大介 (豊田工大), 三輪 誠 (豊田工大) - [S1-P26] 潜在拡散モデルによる画像生成における対象の配色制御による改善の試み
永井 大地 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S1-P28] マルチモーダルモデル自動評価のための複数タスク・複数基準評価データセット
大井 聖也 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大), 井上 中順 (東工大) - [S1-P34] 大規模言語モデルによる読"舌"術
坂上 温紀 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S1-P39] 大規模視覚言語モデルの謎解き能力調査
臼井 久生 (東京農工大), 木山 朔 (都立大), 古宮 嘉那子 (東京農工大)
[14:00-15:00] ポスターセッション (2)
- [S2-P01] 「ふわふわ」「もったり」ってどう表現するの? ーエージェントとの豊かなコミュニケーションの実現に向けてー
肥田 京佳 (愛工大), 市川 淳貴 (愛工大), 徳久 良子 (愛工大) - [S2-P03] 日常会話を通じて心の健康を支援するヴァーチャルエージェントの試作
泉 健太 (SB Intuitions), Liu Lianbo (SB Intuitions), 大萩 雅也 (SB Intuitions), 山崎 天 (SB Intuitions) - [S2-P11] 拡散モデルを用いたシーングラフベースの画像編集
森 江梨花 (慶應大), 渡邊 偉志 (パナソニックコネクト), 藤松 健 (パナソニックコネクト), 嘉本 海大 (パナソニックコネクト), 青木 義満 (慶應大) - [S2-P13] 画像特徴ベクトルは重みを固定した言語モデルで情報豊かなトークンである
加藤 万理子 (JAIST), 趙 羽風 (JAIST), 閻 真竺 (JAIST), 石 钰婷 (JAIST), 井之上 直也 (JAIST/理研) - [S2-P33] Phase Diagram of Vision Large Language Models Inference: A Perspective from Interaction across Image and Instruction
WEI Houjing (JAIST), SHI Yuting (JAIST), Cho Hakaze (JAIST), YAN Zhenzhu (JAIST), 井之上 直也 (JAIST/理研)
[17:50-18:50] ポスターセッション (3)
- [S3-P12] Text-to-audioにおける評価指標CLAP-Scoreの性能分析
高野 大成 (東大), 岡本 悠希 (東大), 齋藤 佑樹 (東大) - [S3-P22] ESG情報抽出データセットの検討
赤部 晃一 (シェルパ・アンド・カンパニー), 前田 航希 (シェルパ・アンド・カンパニー/東工大), 栗田 修平 (NII), 小田 悠介 (シェルパ・アンド・カンパニー/NII) - [S3-P27] 学術論文におけるGraphical Abstract自動生成の初期検討
川田 拓朗 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大) - [S3-P32] 画像とテキストの共通構造はV&Lモデルにいかなる形で埋め込まれているか
志子田 直輝 (NAIST), 横井 祥 (東北大/理研), 渡辺 太郎 (NAIST) - [S3-P34] 大規模視覚言語モデルの潜在的バイアスを利用した幻覚の抑制方法の提案
大平 颯人 (一橋大), 平澤 寅庄 (OSX), 小町 守 (一橋大) - [S3-P35] 地図情報を用いた「謎解き」の自動生成に向けて
大塚 晴貴 (愛工大), 徳久 良子 (愛工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P03] CGとの融合:リアルタイム対話可能なバーチャルヒューマン
人見 雄太 (Aww), 佐々木 優理 (Aww), 丸田 拓和 (Aww), 片田 智大 (Aww), 甲斐 凜太郎 (Aww/東大), 木本 晴久 (Aww/茨大), 跡部 優吾 (Aww), 水落 知代 (Aww), 平川 詩恩 (Aww), 伊達 宗一郎 (Aww), ウェイ イチェン (Aww), 橋本 圭 (Aww), ジューストー 沙羅 (Aww), 守屋 貴行 (Aww) - [S4-P06] 言語学習支援に向けた動画生成モデルの構築
王 昊 (早大), 河原 大輔 (早大) - [S4-P09] Iterative Multimodal Fusionを用いたゼロショットの漫画キャラクター識別と話者推定
李 映萱 (東大), 日並 遼太 (Mantra), 相澤 清晴 (東大), 松井 勇佑 (東大) - [S4-P15] The Manga Visual Narrative Treebank
馮 思遠 (東大), 林 克彦 (東大), 小倉 甲陽 (東大), 富田 雅代 (東大), 上垣外 英剛 (NAIST) - [S4-P29] text-to-image 拡散モデルにおける誘導 attention map を用いた画像生成手法の提案
水口 徳人 (法政大), 北田 俊輔 (法政大), 守田 竜梧 (法政大), 彌冨 仁 (法政大) - [S4-P35] Large-scale Vision Language Modelの言語タスクに及ぼす画像の影響
吉田 大城 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 林 克彦 (東大), 渡辺 太郎 (NAIST)
[14:00-15:00] ポスターセッション (5)
- [S5-P03] LLMと音声基盤モデルを用いた音声認識
小峠 陸登 (Spiral.AI/阪大), 安立 健人 (Spiral.AI), 石川 宏輔 (Spiral.AI), 佐々木 雄一 (Spiral.AI) - [S5-P04] 自動運転のための言語・視覚・動作の統合データセットの構築
三輪 敬太 (Turing/東大), 荒居 秀尚 (Turing), 佐々木 謙人 (Turing/筑波大), 渡辺 晃平 (Turing), 山口 祐 (Turing/慶應大) - [S5-P13] 作曲学習支援のための音楽と言語のマルチモーダルモデルに向けて
稲葉 達郎 (京大) - [S5-P21] マルチモーダル大規模言語モデルは非言語コミュニケーションを理解しているか?
尾崎 慎太郎 (NAIST), 林 和樹 (NAIST), 大羽 未悠 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P29] ベクター画像を利用する上での大規模言語モデルでトークン数の制限を回避する手法の提案
大竹 啓永 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P38] 視写課題の自動採点へ向けた 子供らしい文字の自動生成による OCR 精度の向上
関 歩実 (東京理科大), 松崎 拓也 (東京理科大) - [S5-P39] 多様なモダリティの属性情報をハイパーグラフにより統合したエンティティ表現の獲得
西出 隆盛 (豊田工大), 三輪 誠 (豊田工大)
多言語・Multi/Cross-Lingual / 7件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P20] 英語データセットを使ったRLHFは日本語LLMの常識道徳にどのような影響を与えるか?
陣内 佑 (サイバーエージェント) - [S1-P25] 大規模言語モデルによる日本文化に沿った指示データ生成
塩谷 泰平 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大) - [S1-P36] 現代LLMは日本語の語用論を分かるのか?
ガンバルデッラ アンドリュー (東大)
[14:00-15:00] ポスターセッション (2)
- [S2-P06] Multilingual LLM への指示文は本当に英語であるべきなのか?
榎本 大晟 (都立大), 金 輝燦 (都立大), 陳 宙斯 (一橋大), 小町 守 (一橋大) - [S2-P39] ヴェーダ語学・ヴェーダ文献学におけるRAGの活用
塚越 柚季 (東大)
9/6(金): シンポジウム3日目
[14:00-15:00] ポスターセッション (5)
- [S5-P05] 多言語モデルの埋め込み表現の理解に向けた独立成分分析による可視化
北野 雄士 (NAIST), 西田 悠人 (NAIST), 坂上 温紀 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S5-P18] 自然言語モデルを活用した同件不具合検出システムを用いたシステムテスト品質の向上
松尾 正裕 (パナソニックITS)
応用 (Webサービス・ソーシャルメディア) / 10件
9/5(木): シンポジウム2日目
[14:00-15:00] ポスターセッション (2)
- [S2-P17] おやつプロジェクト: おすすめスイーツ店の個人レビュー要約
岩本 蘭 (IBM/慶應大), 大内 啓樹 (NAIST/サイバーエージェント), 金山 博 (IBM), 吉田 光男 (筑波大) - [S2-P26] ABEMA検索におけるLLMを用いた0件ヒット問題に対する実験と評価
加藤 駿 (慶應大), 犬塚 眞太郎 (サイバーエージェント), 中野 修平 (AbemaTV) - [S2-P27] 『IDOLY PRIDE』におけるライブスコアを用いたアイドル埋め込み評価手法の検討
伊原 滉也 (サイバーエージェント), 叶 穎睿 (サイバーエージェント), 田村 和範 (QualiArts), 岡 時生 (QualiArts), 水村 総之介 (QualiArts), 野村 将寛 (サイバーエージェント) - [S2-P37] X上の情報カスケードにおける情報変容のアノテーション
遠田 哲史 (東大), 吉永 直樹 (東大), 豊田 正史 (東大) - [S2-P38] 「インプレゾンビ」検出のためのデータセット構築と特徴分析
上原 慧大 (横国大), 村山 太一 (横国大)
[17:50-18:50] ポスターセッション (3)
- [S3-P03] ユーザレビュー作成支援を目的とした対話システムの活用法の提案
田中 義規 (電通大), 稲葉 通将 (電通大) - [S3-P19] 平易化への_Task Arithmetic_の応用とその検証
小西 修平 (NHK)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P03] CGとの融合:リアルタイム対話可能なバーチャルヒューマン
人見 雄太 (Aww), 佐々木 優理 (Aww), 丸田 拓和 (Aww), 片田 智大 (Aww), 甲斐 凜太郎 (Aww/東大), 木本 晴久 (Aww/茨大), 跡部 優吾 (Aww), 水落 知代 (Aww), 平川 詩恩 (Aww), 伊達 宗一郎 (Aww), ウェイ イチェン (Aww), 橋本 圭 (Aww), ジューストー 沙羅 (Aww), 守屋 貴行 (Aww) - [S4-P26] パブリックアートは人を幸せにするのか
祖父江 智子 (NAIST), 伊藤 和浩 (NAIST), 古賀 千絵 (東大), 吉村 有司 (東大), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST)
[14:00-15:00] ポスターセッション (5)
- [S5-P30] 検索クリックログに基づくクエリ理解に特化した埋め込み
西川 荘介 (LINEヤフー), 平子 潤 (LINEヤフー), 佐野 峻平 (LINEヤフー), 浅野 広樹 (LINEヤフー), 渡邉 幸暉 (LINEヤフー), 山城 颯太 (LINEヤフー), 鍜治 伸裕 (LINEヤフー)
応用 (教育) / 13件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P01] 四方向投影システムを用いた子どもたちの協働による「学びの質」の評価方法の検討
長谷川 騎平 (愛工大), 増井 辰真 (愛工大), 徳久 良子 (愛工大) - [S1-P03] NLP J Anthology BTPPコーパス: 自然言語処理分野の論文調査支援を目的とした英日翻訳後処理コーパスの作成
中町 礼文 (janthology.jp), 西原 大貴 (janthology.jp) - [S1-P08] 問題タイプを考慮した教師あり学習による英単語穴埋め問題の自動生成
吉見 菜那 (愛媛大), 梶原 智之 (愛媛大), 内田 諭 (九大), 荒瀬 由紀 (東工大), 二宮 崇 (愛媛大) - [S1-P18] 児童の読解力向上を目的とした音読支援システムの開発
齊藤 新 (東京理科大), 松崎 拓也 (東京理科大)
[14:00-15:00] ポスターセッション (2)
- [S2-P04] 大規模言語モデルの事前学習ツールjax-llmの開発とinput-methodへの応用
杉浦 一瑳 (京大) - [S2-P07] 強化学習に基づく難易度制御を組み込んだ多肢選択式読解問題自動生成手法の開発
富川 雄斗 (電通大), 宇都 雅輝 (電通大)
[17:50-18:50] ポスターセッション (3)
- [S3-P40] 採点基準を元に自律的に採点ツールの選択と適用を行う英文要約自動採点システム
藤田 晃輔 (東工大), 山田 寛章 (東工大), 徳永 健伸 (東工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P06] 言語学習支援に向けた動画生成モデルの構築
王 昊 (早大), 河原 大輔 (早大) - [S4-P13] 強化学習を利用した訓練データの価値評価手法に基づく問題横断型自動採点手法
柴田 拓海 (電通大), 宇都 雅輝 (電通大) - [S4-P17] 大規模言語モデルによる授業発話の影響推定に基づいたアドバイス生成
大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大)
[14:00-15:00] ポスターセッション (5)
- [S5-P13] 作曲学習支援のための音楽と言語のマルチモーダルモデルに向けて
稲葉 達郎 (京大) - [S5-P27] 授業発話の分類に基づく教員へのアドバイス生成
児嶋 祥成 (岡山理大), 大西 朔永 (岡山理大), 椎名 広光 (岡山理大), 保森 智彦 (岡山理大) - [S5-P38] 視写課題の自動採点へ向けた 子供らしい文字の自動生成による OCR 精度の向上
関 歩実 (東京理科大), 松崎 拓也 (東京理科大)
応用 (産業・法律・知的財産) / 1件
9/5(木): シンポジウム2日目
[14:00-15:00] ポスターセッション (2)
- [S2-P31] 土木分野におけるRAGの実用化課題の整理と精度向上へ向けた検討
緒方 陸 (八千代エンジニヤリング), 岡野 将大 (八千代エンジニヤリング), 大久保 順一 (八千代エンジニヤリング), 藤井 純一郎 (八千代エンジニヤリング)
応用 (心理・生物・医療) / 16件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P19] 豪雨と地震におけるクロノロジーの優先度推定
孝壽 真治 (岡山大), 竹内 孔一 (岡山大), 渡邉 暁洋 (兵庫医科大), 平山 隆浩 (岡山大), 中尾 博之 (大阪行岡医療大) - [S1-P37] 日本語医療LLM評価ベンチマークの構築と性能分析
福島 拓也 (NAIST), 久田 祥平 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST)
[14:00-15:00] ポスターセッション (2)
- [S2-P03] 日常会話を通じて心の健康を支援するヴァーチャルエージェントの試作
泉 健太 (SB Intuitions), Liu Lianbo (SB Intuitions), 大萩 雅也 (SB Intuitions), 山崎 天 (SB Intuitions) - [S2-P32] 社会的価値観の融和を誘導する対話システムの開発
小林 涼太郎 (東大), 高柳 剛弘 (東大), 鈴木 雅弘 (東大), 小倉 有紀子 (北大), 坂地 泰紀 (北大)
[17:50-18:50] ポスターセッション (3)
- [S3-P01] 自己改善する辞書: Sustainable Dictionary Grooming system (SDGs)
大槻 優佳 (NAIST), 矢田 竣太郎 (NAIST), 西山 智弘 (NAIST), 工藤 紀子 (NAIST), 川端 京子 (NAIST), 藤牧 貴子 (NAIST), 永井 宥之 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S3-P04] 大規模言語モデルと患者表現辞書を用いた病名予測の検証
宇都宮 和希 (工学院大), 坂野 遼平 (一橋大) - [S3-P15] 大規模言語モデルによって医療テキストの固有表現処理はどこまで簡単になったか
西林 孝 (Ubie), 横井 祥 (東北大/理研) - [S3-P18] 障害言語モデルの「失語症らしさ」に対する標準失語症検査に基づく評価
森田 早織 (東大), 原田 宥都 (東大), 直江 大河 (昭和大), 前田 ありさ (東大), 沖村 宰 (昭和大), 大関 洋平 (東大) - [S3-P25] LLMを用いたCT読影レポートの撮影目的分類
峯 悠大 (NAIST), 西山 智弘 (NAIST), 谷 懿 (NAIST), 大竹 義人 (NAIST), 佐藤 嘉伸 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P07] LLMを用いた睡眠カウンセリング対話システムの検討
大橋 玲音 (愛知県立大), 我妻 信実 (愛知県立大), 中山 怜士 (愛知県立大), 野村 光 (愛知県立大), 石川 舞一 (愛知県立大), 伊藤 にい奈 (愛知県立大), 伊藤 芙久佳 (愛知県立大), 南 詩織 (愛知県立大), 金田 修香 (愛知県立大), 檜物 春佳 (愛知県立大), 中村 莉子 (愛知県立大), 西尾 優亜 (愛知県立大), 鈴木 丈慈 (愛知県立大), 坪倉 和哉 (愛知県立大), 横山 加奈 (愛知県立大) - [S4-P31] アノテーション基準の違いを考慮した複数データセットからの固有表現抽出の学習
大井 拓 (豊田工大), 三輪 誠 (豊田工大)
[14:00-15:00] ポスターセッション (5)
- [S5-P10] 大規模Webコーパスからの効果的な医療ドメインサンプリング法
長谷川 愛珠 (日本女子大), 小原 有以 (日本女子大), 伊東 和香 (日本女子大), 相馬 菜生 (日本女子大), 倉光 君郎 (日本女子大) - [S5-P12] エピソードへの主体性アノテーション:well-beingのさらなる理解に向けて
林 純子 (NAIST), 永井 宥之 (NAIST), 矢田 竣太郎 (NAIST), 若宮 翔子 (NAIST), 荒牧 英治 (NAIST) - [S5-P28] SNSカウンセラー育成のためのリアルタイム対話支援システムの構築
斉 志揚 (電通大), 稲葉 通将 (電通大) - [S5-P32] 動機づけ面接におけるクライエントの発話分類に基づく応答生成
金子 優 (名工大), 上乃 聖 (名工大), 李 晃伸 (名工大) - [S5-P39] 多様なモダリティの属性情報をハイパーグラフにより統合したエンティティ表現の獲得
西出 隆盛 (豊田工大), 三輪 誠 (豊田工大)
応用 (科学研究支援) / 5件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P03] NLP J Anthology BTPPコーパス: 自然言語処理分野の論文調査支援を目的とした英日翻訳後処理コーパスの作成
中町 礼文 (janthology.jp), 西原 大貴 (janthology.jp)
[17:50-18:50] ポスターセッション (3)
- [S3-P21] 科学技術文献における知識グラフ補完を用いた効率的な知識グラフの作成
神野 倫行 (NAIST), 林 和樹 (NAIST), 坂井 優介 (NAIST), 上垣外 英剛 (NAIST), 渡辺 太郎 (NAIST) - [S3-P27] 学術論文におけるGraphical Abstract自動生成の初期検討
川田 拓朗 (法政大), 根本 颯汰 (法政大), 北田 俊輔 (法政大), 彌冨 仁 (法政大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P28] 掲示板テキストから得られるセンチメントを利用した日経平均株価ボラティリティ予測
中島 秀太 (一橋大), 欅 惇志 (一橋大), 渡部 敏明 (一橋大), 小町 守 (一橋大)
[14:00-15:00] ポスターセッション (5)
- [S5-P17] 情報科学分野における学会発表タイトルの分野推定データセットの構築
宮田 莉奈 (愛媛大), 眞鍋 光汰 (愛媛大), 福島 啓太 (愛媛大), 花房 健太郎 (愛媛大), 高田 一慶 (愛媛大), 梶原 智之 (愛媛大), 桂井 麻里衣 (同志社大), 二宮 崇 (愛媛大)
倫理・バイアス・プライバシー / 6件
9/5(木): シンポジウム2日目
[11:40-12:40] ポスターセッション (1)
- [S1-P20] 英語データセットを使ったRLHFは日本語LLMの常識道徳にどのような影響を与えるか?
陣内 佑 (サイバーエージェント) - [S1-P22] メンバーシップ推論攻撃によるLLMの失言しやすさの評価
丹波 光 (日本女子大), 小柳 響子 (日本女子大), 伊東 和香 (日本女子大), 倉光 君郎 (日本女子大) - [S1-P25] 大規模言語モデルによる日本文化に沿った指示データ生成
塩谷 泰平 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大)
9/6(金): シンポジウム3日目
[11:40-12:40] ポスターセッション (4)
- [S4-P20] UniDetox: Universal Social Bias Detoxification of Large Language Models
盧 慧敏 (東大), 磯沼 大 (東大/エディンバラ大), 森 純一郎 (東大/理研), 坂田 一郎 (東大) - [S4-P22] 大規模言語モデルに対する漏洩検出への敵対的なデータ隠蔽
高橋 侑成 (東工大), 馬 尤咪 (東工大), 金子 正弘 (MBZUAI/東工大), 岡崎 直観 (東工大)
[14:00-15:00] ポスターセッション (5)
[S5-P14] 言語モデルの日本語道徳理解能力の評価データセットの構築
竹下 昌志 (北大), ジェプカ ラファウ (北大)-
- 「難解な数値データを分かりやすく説明する言語生成技術の最前線と未来」 石垣 達也 氏(産総研人工知能研究センター)
- 「人間らしい対話とは:非言語情報生成のための基盤モデル」 井上 昂治 氏(京都大学)
- 「日本語事前学習向けベンチマーク」 今城 健太郎 氏(Preferred Networks)
- 「人文学と言語処理・知識処理」 大向 一輝 氏(東京大学)
- 「企業でつくる、大規模言語モデル」 清野 舜 氏(SB Intuitions)
- 「End-to-End音声基盤モデル」 小島 熙之 氏(Kotoba Technologies, Inc.)
- 「視覚と言語の対応ずれ問題とその解決に向けて」 品川 政太朗 氏(SB Intuitions)
- 「LLM時代の評価研究とその周辺」 菅原 朔 氏(国立情報学研究所)
- 「Mechanistic Interpretability: 大規模言語モデル時代における自然言語処理と認知科学の交差点」 高木 優 氏(国立情報学研究所/JST/大阪大学/情報通信研究機構)
- 「発話内容書き起こしを越えて音声と言語を結びつけたい」 高道 慎之介 氏(慶應義塾大学/東京大学)
- 「クラウドソーシングとAI文字認識を駆使した「くずし字」資料の大規模テキスト化」 橋本 雄太 氏(国立歴史民俗博物館)
- 「Can AI entertain us?」 山西 良典 氏(関西大学)
- 「形を通して意味を知る」 横井 祥 氏(東北大学/理化学研究所)
- 「人・ロボットの移動と大規模言語モデルの接点」 米谷 竜 氏(サイバーエージェント)
- 「人々の健康に資するソーシャルコンピューティング」 若宮 翔子 氏(奈良先端科学技術大学院大学)
招待ポスター
今年のテーマである「異分野交流」を促進するため,招待講演セッションを行います.自然言語処理分野だけでなく,音声・画像処理などの周辺分野や人文・社会学系の若手研究者や技術者複数名をお招きし,これまでの研究や展望についてポスター発表をしていただきます.
※講演者の追加などありましたら,改めて告知いたします.
「難解な数値データを分かりやすく説明する言語生成技術の最前線と未来」
石垣 達也 氏(産総研人工知能研究センター)

概要: 株価の値動きやセンサーデータ、ゲームのプレイデータなど、世の中の多くの事象は数値列として表現されています。しかし、このような数値列はそのままでは人間にとって理解が難しく、活用されずに蓄積され続けています。本講演ポスターでは、「難解な数値データを分かりやすい言葉で説明する言語生成技術」と題し、最新の大規模言語モデルがどのようにして複雑な数値データを扱うかについて解説します。特に、リアルタイムに数値データを理解し言語生成する手法を、レーシングゲーム(アセットコルサ)や格闘ゲーム (スマッシュブラザーズ)を対象としたゲーム実況生成の事例を通じて議論します。技術解説に加え、大学や企業の研究者とは異なる国立研究開発法人(国研)の研究者としてのキャリアについてもご紹介します。
略歴: 国立研究開発法人産業技術総合研究所人工知能研究センター研究員。2019年、東京工業大学にて博士号 (工学)。東京工業大学 未来産業技術研究所研究員を経て、2020年より現職で自然言語処理、特に数値データからの言語生成の研究に従事。言語処理学会論文誌編集委員 (2024-)・全国大会プログラム委員 (2023, 2024)、情報処理学会自然言語処理研究会運営委員 (2022-2024)、人工知能学会全国大会運営委員 (2024)、INLG2024現地議長。
「人間らしい対話とは:非言語情報生成のための基盤モデル」
井上 昂治 氏(京都大学)

概要: 大規模言語モデル(LLM)の発展により、人間と見間違えるほどの人工知能による対話が可能になりつつある。しかし、私たちの日常の対話と本当に同じだろうか?本発表では、対話を構成する要素のうち「非言語情報」に焦点をあて、これまで取り組んできたターンテイキング、相槌、笑いを予測および生成するシステムについて紹介する。さらに、これらを生成するための統一的な基盤モデルの実現についても議論し、「人間らしい対話とは何か」という本質的な問いに挑む。
略歴: 京都大学情報学研究科助教。2018年 同研究科 博士後期課程 研究指導認定退学。博士(情報学)。2023年 スウェーデン王立工科大学 客員研究員。同年 仏経済紙レゼコー等による「2022年 世界の発明トップ10」に選出。
「日本語事前学習向けベンチマーク」
今城 健太郎 氏(Preferred Networks)

概要: 大規模言語モデル(以下LLM)向けのベンチマークは、回答テンプレートの違いによって結果が大きく変化するため、事前学習モデルの能力を十分に引き出して評価することが難しい。また、選択肢問題を使ったベンチマークでは、特に小さいモデルや学習初期段階のモデルが選択肢問題を理解できないケースがあり、性能の比較が難しい。本研究では、日本語事前学習モデルをより良く評価する手法について検討する。
略歴: 2013年京都大学情報学研究科修士課程修了。在学中にAtCoder社を創業し、卒業後にグーグル株式会社に入社。2018年よりPreferred Networksにてエンジニア。現在は金融関連の研究開発や大規模言語モデルの研究開発に携わっている。
「人文学と言語処理・知識処理」
大向 一輝 氏(東京大学)

概要: 情報技術の役割は、人間や社会に役立つシステムを開発・提供することにありますが、その過程で対象の本質的な性質や特徴が浮き彫りになるという側面も持ち合わせています。一方、人文学は人間のコミュニケーションや文化の理解に重点を置いた学問体系であり、その取り組みの中で得られた知見や洞察がシステムの設計・普及のプロセスに貢献できる可能性があると考えています。本発表では、両者の学際的な研究事例を紹介するとともに、言語処理・知識処理技術と人文学がいかに相互補完し、相乗効果を生み出し得るかについて議論します。
略歴: 2005年総合研究大学院大学博士後期課程修了。博士(情報学)。同年国立情報学研究所助手、2007年同助教、2009年同准教授を経て、2019年より東京大学大学院人文社会系研究科准教授。人文情報学、ウェブ情報学、学術コミュニケーションの研究教育に従事。
「企業でつくる、大規模言語モデル」
清野 舜 氏(SB Intuitions)

概要: 現在、大規模言語モデルの研究開発には大学だけでなく、様々な企業が精力的に取り組んでいる。 本発表では、企業での大規模言語モデル開発の最前線から得られた知見を共有する。 特に、大学と企業における研究開発の本質的な違いについて、大規模言語モデル開発というテーマがもたらす影響について議論する。
略歴: 2022年 東北大学大学院にて博士号を取得(情報科学)。2019年より理化学研究所革新知能統合研究センターにて勤務したのち、 2022年にLINE株式会社 (現: LINEヤフー株式会社) に入社。2024年よりSB Intuitions株式会社に転籍。主に大規模言語モデルの研究開発に従事。
「End-to-End音声基盤モデル」
小島 熙之 氏(Kotoba Technologies, Inc.)

概要: End-to-Endの音声基盤モデルは、AIと人間のlow-latency/seamlessなコミュニケーションを実現する為に必要不可欠な物です。音声におけるこうした基盤技術の開発は、テキストにおけるLLMと比べて技術的な発展が遅れてきた背景がありました。今回の発表では、大量のGPU計算資源を投入してKotoba Technologiesが開発する音声基盤モデルに関して発表します。
略歴: Kotoba Technologies co-founder & CEO、Fugaku-LLM co-founder、コーネル大学CS PhD
「視覚と言語の対応ずれ問題とその解決に向けて」
品川 政太朗 氏(SB Intuitions)

概要: Vision and Languageは視覚と言語を紐づけることで問題解決を行う研究分野であり,Vision-Language Models (VLM)と呼ばれる深層学習モデル構築の方法論を発展させてきた.発表者がこの分野で特に面白いと考えているのが,視覚と言語がVLM内でずれて対応付けられるという点である.広くVLMが社会に浸透するためには,対話的相互作用の中でこの対応ずれをすり合わせられる機能が必要である.本発表では,その相互作用のデザインからVLMを考えることや,視覚と言語の紐づきを強化する方法論についての研究を紹介し,視覚と言語の対応ずれ問題の面白さをお伝えしたい.
略歴: 2013年東北大学工学部卒業.2015年同大学大学院情報科学研究科修士課程修了.2020年奈良先端科学技術大学院大学博士後期課程修了.博士(工学).2020年同大学助教を経て2024年よりSB Intuitions株式会社に所属.マルチモーダル基盤モデルの研究開発に従事.
「LLM時代の評価研究とその周辺」
菅原 朔 氏(国立情報学研究所)

概要: LLM は様々なタスクで目覚ましい性能を示していますが、その出力を正確に評価する・説明することは容易ではありません。とくに LLM が非常に賢く振る舞う状況においては、哲学や心理学といった人文科学的な視点も重要かもしれません。本発表では、評価方法・説明性の観点から発表者がこれまで取り組んできたデータセット分析やベンチマーク構築の試みを紹介しながら、今後のシステム評価の発展の方向性を分野横断的に考えてみます。
略歴: 国立情報学研究所コンテンツ科学研究系助教。2020年3月東京大学大学院情報理工学系研究科博士課程修了。2020年4月より現職。博士(情報理工学)。
「Mechanistic Interpretability: 大規模言語モデル時代における自然言語処理と認知科学の交差点」
高木 優 氏(国立情報学研究所/JST/大阪大学/情報通信研究機構)

概要: 自然言語は人間の脳から生まれています。私たちの研究室では、様々な知覚・認知体験下での脳活動予測モデル構築を通じて、人間の脳を理解することを目指しています。それと同時に、人間の脳活動を通じて、機械学習モデルが世界をどのように表現しているかを理解することも目指しています。本発表では、大規模言語モデル時代において、認知科学と自然言語処理がどのように融合しつつあるのかを紹介します。
略歴: 国立情報学研究所 大規模言語モデル研究開発センター 特任准教授 兼 JSTさきがけ研究者 兼 大阪大学大学院生命機能研究科招へい准教授 兼 NICT 特別研究員 。2018年奈良先端科学技術大学院大学情報科学研究科博士課程修了(ATR連携講座、基幹講座:松本裕治研究室)。2018年から2020年までオックスフォード大学客員研究員 (うち1年間は東京大学医学部附属病院特任研究員を兼務)。2020年から2021年までJSPS海外特別研究員(スタンフォード大学)兼 東京大学大学院人文社会研究科特任研究員。2021年から2023年まで大阪大学大学院生命機能研究科助教。2024年より現職。機械学習と認知神経科学の融合研究に従事。
「発話内容書き起こしを越えて音声と言語を結びつけたい」
高道 慎之介 氏(慶應義塾大学/東京大学)

概要: 音声を自然言語で説明する有名な技術は音声認識(発話内容書き起こし)である.しかしながら,昨今のLLMの進化を鑑みれば,もっと多くの音声情報を自然言語で記述できるはずである.本講演では,どんな情報を記述できそうか,音声だからこその問題は何かについて,著者の研究を踏まえ整理する.
略歴: 2011年に長岡技術科学大学を卒業.2013年・2016年それぞれに奈良先端科学技術大学院大学 博士前期・後期課程を修了.2024年より慶應義塾大学 准教授(現職).博士(工学).音声合成変換,音声信号処理の研究に従事.
「クラウドソーシングとAI文字認識を駆使した「くずし字」資料の大規模テキスト化」
橋本 雄太 氏(国立歴史民俗博物館)

概要: 日本国内には江戸時代以前から伝来する20億点以上の文字資料が保存されていると推測されているが、その大部分は現代人に読解困難な「くずし字」で筆記されており、デジタルテキストとして利用可能な資料はごく僅かに過ぎない。そこで人文情報学やDigital Humanitiesと呼ばれる分野では、クラウドソーシングやAI文字認識などの情報学的手法を駆使してこれら文字資料をテキスト化する試みが進められてきた。本発表では、8,000人以上の参加者を集め3,600万字の資料のテキスト化を実現した「みんなで翻刻」(https://honkoku.org/)プロジェクトを中心に、「くずし字」テキスト化研究の現況を紹介する。
略歴: 国立歴史民俗博物館研究部准教授。2013年京都大学大学院文学研究科情報・史料学専修博士後期課程編入。2017年より国立歴史民俗博物館テニュアトラック助教。2023年より現職。
「Can AI entertain us?」
山西 良典 氏(関西大学)

概要: AI技術によって様々な知的課題が解決されてきており,知性の秘密は解き明かされつつある.では,我々はどのようなエンタテインメントコンテンツを「おもしろい」「たのしい」と感じるのだろうか?2024年夏時点では,「感性の秘密」は未だ明かされていない部分が多い.エンタテインメントへの直感的な評価には,多くの暗黙的な認知や処理が潜んでいるものと考えられる.エンタテインメントが人を「楽しませる」メカニズムを解明できれば,エンタテインメントのおもしろさの向上のみならず,様々な知的活動すらも楽しくするエッセンスを加えることが可能になるかもしれない.本発表では,エンタテインメントへの計算機科学的アプローチを紹介する.
略歴: 2012年名古屋工業大学大学院工学研究科情報工学専攻修了.博士(工学).同年より立命館大学情報理工学部にて,助手,特任助教,助教,講師.この間,University of Brtish Columbia(カナダ)にて客員助教.2020年,関西大学総合情報学部准教授.2024年より,同教授,現在に至る.2023年よりIFIP TC14日本代表.音楽,漫画,ゲーム,飲食などの文化や芸術コンテンツを対象とした計算機科学研究を専門とし,漫画家や声優,ゲーム企業との産学芸連携にも多く取り組む.
「形を通して意味を知る」
横井 祥 氏(東北大学/理化学研究所)

概要: モデルの形を通して言葉の意味を知るための一連の研究を紹介します。深層学習以後の自然言語処理の顕著な特徴のひとつは、生コーパスを用いた自己教師あり学習というアプローチにあります。このやり方が成功を収めた以上、「意味」がデータに統計的にある程度埋め込まれているであろうこと、そしてこの情報が損失関数を通してモデルに転写されているであろうことは認めざるを得ません。最近の自然言語処理のもうひとつの特徴は、言語の持つ離散性を隠蔽してこれらを連続的に扱うというパラダイムにあります。こちらは副次効果として、モデルに対する幾何的な手続きを一気に容易にしました。いまのモデルは長さや広がりといった直感的なを見方を受け入れてくれるということです。以上を踏まえると、意味↔︎データ↔︎モデルをできるだけ精確に繋ぎ合わせることで「形を通して意味を知る」ことができる、そういう面白い時代が突如到来したと言えます。こんな気持ちで取り組んでいる各種研究をご紹介します。
略歴: 東北大学大学院情報科学研究科助教.2020年東北大学大学院情報科学研究科博士課程修了,のち現職.理化学研究所AIPセンター客員研究員兼任.自然言語処理・機械学習に関する研究,特に自然言語の埋込表現に関する研究に従事.
「人・ロボットの移動と大規模言語モデルの接点」
米谷 竜 氏(サイバーエージェント)

概要: 人物やモバイルロボットの移動経路に関する研究において大規模言語モデルを活用する取り組みを紹介する。最初の事例では、オペレータの言語指示を反映した環境のコストマップを予測することで、指示に即したロボットの移動経路を生成するアルゴリズムについて述べる(言語→経路)。別の事例では、買い物客の移動経路を手掛かりに、購買の背後にある意図や選考を文章化して説明する技術を紹介する(経路→言語)。両技術の基盤となる人物行動計測やロボット経路計画技術についても簡単に解説する。
略歴: 2013年 京都大学 博士後期課程 修了。2014-2018年 東京大学生産技術研究所 助教、2019-2023年 オムロンサイニックエックス シニアリサーチャー/PIを経て、2023年よりサイバーエージェント AI Lab リサーチサイエンティスト。2024年より慶應義塾大学 特任准教授。
「人々の健康に資するソーシャルコンピューティング」
若宮 翔子 氏(奈良先端科学技術大学院大学)

概要: ソーシャルメディアやスマートフォンの発達により,場所と連動した人々が発信する様々なデータが利用可能である.本発表では,主にウェブ,ソーシャルメディアやクラウドソーシングを通して得られるデータを活用し,健康増進やウェルビーイングに貢献するためのナビゲーションや可視化に関する研究を中心に紹介する.また,これらのデータを活用する上での課題や,現在進行中のプロジェクトについても紹介する.
略歴: 2013年兵庫県立大学大学院環境人間学研究科博士後期課程修了.博士(環境人間学).京都産業大学コンピュータ理工学部研究員,奈良先端科学技術大学院大学研究推進機構博士研究員,同特任助教を経て,2020年4月より同大学先端科学技術研究科准教授.ソーシャルコンピューティングや自然言語処理の医療応用に関する研究に従事.
重要日程
2024年度のYANSハッカソンは終了しました。ありがとうございました。
このページの最後にハッカソンの開催報告を追記しました。タスクの詳細などはそちらをご覧ください。YANS運営委員特別賞の表彰状も添付しています。
ハッカソンの参加申込期間: YANS参加申込期間と同じです。日程はシンポジウムの概要ページをご確認くださいタスク概要の共有日: 開催1週間前を目安に参加者用Slackで配信します。ハッカソン当日: 2024年9月4日(水)13:00 – 20:00受付開始時間は12:30〜です。
ハッカソンの概要
言語処理学会30周年記念事業の一環として、シンポジウム前日(1日目)の9月4日(水)に分野交流ハッカソンを行います。画像処理をはじめとする自然言語処理以外の分野の学生・社会人と広く交流することを目的として、YANSシンポジウム会場と同じ会場にてオンサイトのみで実施します。
今年のハッカソンでは、マルチモーダルデータを用いたテキスト生成リーダーボードを開催します。画像やテキストで与えられたお題に対して、機転が利いた回答を行えるようなモデルを作っていただきます。当日にはモデル構築に必要なデータセットなどを共有する予定ですが、必要に応じてハッカソン中にアノテーションや追加でデータセットを構築することもOKです。
また、アドバイザーとして東北大の横井祥さん、SB Intuitionsの品川政太朗さん・清野舜さんの豪華三銃士をお招きします。ハッカソンの時間中は三銃士に質問することもできますので、この機会に交流してください。
評価は、自動評価、ハッカソン参加者の人手評価のほか、三銃士による評価も行います。また、取り組み内容の発表の良さや、ハッカソン中に実施したアノテーション・データセット構築の取り組みも評価に加えます。
学生・社会人問わず、ふるってご参加ください。自然言語処理の若手研究者はもちろん、普段は自然言語処理以外の分野でご活躍されている方や、これをきっかけに自然言語処理に触れてみたい、交流を広げたい、といった方も大歓迎です。 また、ハッカソン・コンペなどに参加したことがない方でも大歓迎です。優秀チームには表彰もありますので、ぜひチャレンジしてください!
参加までの流れ
参加申し込み
YANS2024参加の発表・聴講参加申し込み時に、ハッカソン参加者希望者枠のチケットをご購入ください。ハッカソン参加者数は定員がございますので、お早めにお申し込みください。
※ ハッカソンの参加に際して、シンポジウムの参加費以外に追加で費用は発生いたしません。
※ ハッカソンを希望されない方は、ハッカソン参加希望枠のチケットをご購入されないようお願いいたします。
※ チーム編成は、参加者に対して事前に行うアンケートの回答を踏まえて運営側で実施します。事前にチームを組んだ上でのご参加はできません。
参加同意書の提出および参加者アンケートへの回答
ハッカソンの円滑な運営のため、参加同意および参加者アンケートへの回答にご協力ください。参加同意書は以下の通りです。ハッカソンの参加申込時に参加同意をいただけない方はハッカソンに参加できませんので、ご承知おきください。 参加者アンケートでは、開発経験やメインの研究領域などを伺います。この回答内容はチームの振り分けなどに利用します。
タスク概要の共有(ガイダンス)
ハッカソン開催日の1週間前ごろを目安に、参加者用Slackにてガイダンス用資料を配信します。それまでに参加者用Slackへ招待しますので、ご参加をお願いいたします。
また、ガイダンスの連絡の際に、テーマおよびチームの振り分けについても発表します。ハッカソン当日までに必ずご確認ください。
ハッカソン当日
ハッカソンはシンポジウム前日(1日目)の9月4日(火)の13:00から、オンサイトにて開催します。 受付開始は12:30からです。
ハッカソンのタスク内容
いくつかの評価メトリックを用いたコンペ形式の競争になります。 各チームへOpenAI APIのキーを提供しますので、これを用いて公開データに基づく自然言語生成タスクに挑戦していただきます。取り組んでいただくテーマの詳細はガイダンス時にお知らせしますが、お題となる画像やテキストを入力として、それに対する機転の利いた回答をテキストで返すようなタスクに挑戦いただきます。 公開データは当日に運営から提供する予定です。また、これに加えてハッカソンの時間内で提供データに対する追加アノテーションや新たなデータセットを構築することも認めます。
各チームの取り組みをいくつかの観点で評価をして、以下の3種類の賞を授与する予定です。各賞を授与するチーム数などは、ハッカソン参加者の人数を踏まえて後日決定します。
- 優秀賞: タスクの評価メトリックを用いて提出システムを評価し、スコアが高いチームに授与します。
- 審査員特別賞: 手法の独創性・取り組み内容の発表の面白さなどを踏まえて評価します。
- YANS運営委員特別賞: 取り組みの独自性、データへの向き合い方などを踏まえて評価します。
データセット賞: 提供データに追加でアノテーションを実施したチームや、新たなデータセットを構築したチームなどがいた場合は、そのチームの中で特に優れた取り組みをしたチームに対して授与します。
そのほかの注意点
以下の通りです。その他の詳細はガイダンスでお伝えします。
- Google Colabが使用できる端末(ノートPC等)をお持ちください。
- 各チームに対して生成AIサービスのAPIキーを提供します。
- API利用にはUsage Limitを設けます。この範囲内でかかる費用は運営で負担します。この範囲を超えて自費で使うことは認めません。
- 生成AIサービスはOpenAI APIの利用を想定していますが、その他サービスに変更する可能性もあります
開催報告
概要
「言語芸術生成ハッカソン」として、OpenAI APIを使った大喜利・川柳の生成タスクを提供しました。 大喜利・川柳でそれぞれ8チーム、合計16チーム・93名が参加しました。
各チームは4時間の中で、方針決定・開発・発表スライド作成、の全てを行いました。 運営委員会からは、システムの性能確認用としてLLM-as-a-judgeによる評価ができるリーダーボードや、三銃士によるアドバイスなどを提供し、開発を支援しました。
開発時間終了後は、各チームから3分のスライド発表や参加者全員によるライブ人手評価を行いました。 当日の各チームの発表スライドはYANSの開催報告記事に掲載しますので、そちらをご覧ください。
詳細
事前ガイダンス(タスク詳細、賞の選定方法などの説明)
当日ガイダンス(全体進行、リーダーボードの使い方などの説明)
各タスクで提供したデータは以下に公開しています。 リーダーボード上では、テストデータ100件の参照回答とのPairwise評価を実施しました。
ライブ人手評価では、YANS運営委員から集めた画像やお題に対する回答を評価しました。こちらの画像データ・参照回答も公開しています。
- 大喜利
- 川柳
結果
クロージングで、優秀賞・審査員特別賞・YANS運営委員特別賞を発表しました。
リーダーボードの結果やライブ人手評価の結果もこちらに記載しています。
YANS運営委員特別賞の受賞チームに対する表彰状は以下のとおりです。 受賞おめでとうございます。
シンポジウムで発表予定の一部の学生に旅費を補助いたします.
ご応募を予定している学生の方は,以下の内容をご覧になり,事前に指導教員の許可を得てからお申し込みください.
多様な発表者のご応募をお待ちしております.
申し込み期間
2024年6月10日(月) 12:00 - 2024年6月24日(月) 15:00
通知:2024年6月28日(金) 7月1日(月)までに返信の必要あり
募集要項
以下の条件を満たす学生の皆さんのご応募をお待ちしております.応募者多数の場合は抽選にて補助対象者を決定いたします.
- YANSシンポジウムで発表する第一著者の学生
- 所属する研究室から旅費などが支援されない
補助内容
- 参加費
- 往復交通費
- 宿泊費 (9月4日,5日分の宿泊費を,1泊13,000円を上限とした実費精算で支給します.前後泊が必要な場合その分も支給いたします.留学交流会は4日11:00-12:00,ハッカソンは4日午後からの開催ですので,ご予定が合えばぜひご参加ください.)
往復交通費と宿泊費込みで一人当たり最大7万円を助成予定です.
申し込みフォーム
記入事項:発表タイトル,発表概要(200文字程度),梅田スカイビルまでの旅程と想定旅費 ,旅程が正当・合理的である旨の説明文,前泊,後泊の必要性とその理由,申し込み理由(所属機関から旅費支援を受けられない理由)
旅費補助を受給した学生の皆様にはご自身のブログにて参加報告を書いていただきます.詳細は採択後にご連絡します.
ご質問等ございましたら,**yans2024committee@googlegroups.com** までご連絡ください.
YANSでは、自然言語処理および関連分野の若手研究者・若手技術者の交流を促進し、若手のアクティビティを高めることを目的とし、年に一度シンポジウムを開催しております。2022年には265名、2023年には300名の参加をいただいており、若手研究者、特に学生の交流の場として大変盛況となっております。参加者の交流を促進するため、交流企画を積極的に行っているのが特徴です。
YANSシンポジウムでは学生の参加を推奨しており、同分野で頑張る仲間とのつながり、また将来のキャリア形成の参考となる若手研究者・技術者や企業様との交流を持てるよう、できるだけ参加にかかる費用を抑えるようにしております。このような事情ですので、YANSシンポジウムのスポンサーを通してご支援をいただければ大変ありがたく存じます。
第19回YANSシンポジウムのスポンサーにお申し込みいただけるご担当者様は、募集要項をお読みいただき、 スポンサー登録システムよりお申し込みください。
お申込みは先着順とさせていただきます。支援企業・団体様と参加者の交流機会を担保するため、お申し込み多数の場合には、締め切り日を繰り上げさせていただくこともございます。 できましたらお早めのお申し込みをお願い申し上げます。
過去のシンポジウムにご支援いただいた企業・団体様は以下のリンクよりご参照いただけます。また過去のシンポジウムの開催報告も掲載しておりますので、よろしければご参照ください。
- 第18回シンポジウム(2023年)スポンサー企業・後援団体様
- 第17回シンポジウム(2022年)スポンサー企業・後援団体様 ※ オンライン開催
- 第14回シンポジウム(2019年)スポンサー企業・後援団体様
※ 2021年および2020年はオンライン開催のためスポンサー募集なし
以上、よろしくご検討下さいますよう、お願い申し上げます。
YANS運営委員会(2024年)委員長
大内 啓樹、佐藤 元紀
受付期間
2024年5月27日(月)12:00 〜 2024年7月19日(金)15:00
※スポンサー募集の申し込みは終了しました.
募集要項
ご応募いただく企業・団体様は、自然言語処理技術を製品開発にご活用されている、もしくは自然言語処理研究に取り組まれていることを原則といたします。ご支援いただきました資金は、主に参加者交流促進のためのイベント企画運営および参加者の経済的負担を軽減する目的で使用させていただきます。
申し込み必要事項
- 企業名・団体名:こちらのお名前に基づいて請求書を発行させていただきます
- 支援種別:「
ダイヤモンド」「プラチナ」 「ゴールド」 「シルバー」の4つの種別の中からご希望の種別を選択してください。 - ご担当者様の情報:氏名・部署名・メールアドレス・電話番号をご入力ください。
- 掲載名称:企業名・団体名をフリガナとともにご入力ください。(Webサイトに掲載します)
- ロゴ画像:横450px・縦200px以上のなるべく大きなサイズの画像(形式:PNG, JPEG, GIF)をご用意ください。(Webサイトに掲載します)
- URL:最大1件のURLをご用意ください(ロゴ画像からリンクいたします)
- お振込時期
※ スポンサー様の無料招待枠での参加者に関しては申し込み後にメールにてお伺いします。
支援種別
※スポンサー募集の申し込みは終了しました.
| 種別 | 上限 | 料金 | ロゴ | ブース | 招待 | 口頭発表 | スポンサー賞 | スポンサーツアー | 交流企画 |
|---|---|---|---|---|---|---|---|---|---|
| 1枠 | 100万円 | 大+看板 | 2つ | 3名 | 10分 | 2件 | ○ | ○ | |
| 3枠 | 30万円 | 大 | 1つ | 2名 | 5分 | 1件 | ○ | − | |
| 16枠 | 20万円 | 小 | 1つ | 1名 | 1分 | 1件 | ○ | − | |
| 20枠 | 5万円 | 小 | - | 1名 | − | − | − | − |
※料金は全て消費税10%込
※取り消し線が引かれている種別については既に募集を締め切っております。
特典
1)ロゴ
YANSのスポンサーページに、御社のロゴを掲載いたします。ロゴの大きさはスポンサーの種類により異なります。同一種別のスポンサー内での掲載順序はお申し込み順とさせていただきます。Webサイトからは、ご希望のリンク先1ヶ所に対するリンクを張ることができます。
2)ブース
本会議期間中(9月5日、6日の2日間)、スポンサーブースをご利用いただけます。ダイヤモンドスポンサー様は隣接する2ブースをご利用いただけます。プラチナ・ゴールドスポンサー様は1ブースをご利用いただけます。また、スポンサーブースのより一層の活性化のためにスポンサーツアーを実施いたします。恐れ入りますが、ブース担当者はシンポジウム参加者に限定させていただきます。
3)招待
参加費を無料とさせていただきます。ご招待させていただく人数はスポンサーの種別により異なります。恐れ入りますが、宿泊費や交通費などその他の諸費に関しましてはご負担ください。
4)スポンサーセッション
当日ご参加くださる社員様に、口頭発表を行っていただきます。スポンサー様で取り組まれておられる自然言語処理や機械学習関連技術の活用に関する話題を中心にお話しいただけます。社員募集やアルバイト・インターン募集に関する告知を行っていただくことも可能です。発表時間はスポンサーの種別により異なります。恐れ入りますが、プログラム編成の都合上、ご発表いただく時間帯はこちらで指定させていただきます。
5)スポンサー賞
ポスター発表を行った学生に対し、スポンサー賞を授与していただきます。副賞をスポンサー様よりご用意いただき、授与していただくことも可能です。授与の件数はスポンサーの種別により異なります。スポンサー賞授与式は、シンポジウム最終日のクロージングでの実施を予定しております。また、Webサイトに受賞理由を掲載します。スポンサー賞の詳細は別途ご連絡させていただきます。
6)スポンサーツアー
参加者にスポンサー様のことをよりよく知ってもらうため、会期中にスポンサーツアーを開催します。このツアーでは、シンポジウムの参加者からツアーへの参加希望を募り、委員が案内役となってダイヤモンド・プラチナ・ゴールドスポンサー様のブースを回ります。
7)参加者交流企画
参加者間の相互交流の場を提供するために、参加者交流企画を開催します。交流企画の中で、希望者にはダイヤモンドスポンサー様と交流できる機会を提供する予定です。 詳細は別途ご連絡させていただきます。
ご質問等ございましたら、**yans-secretariat@anlp.jp** までご連絡ください。
第19回YANSシンポジウム(YANS2024)開催概要
開催日:2024年9月4日(水) - 6日(金)
会場:梅田スカイビルアウラホール(大阪府大阪市北区大淀中1-1-88 梅田スカイビル)
9/4(水) 留学交流会・ハッカソン:梅田スカイビル「スペース36L」
9/5(木) - 6日(金) 本会議:梅田スカイビル「アウラホール」
※ シンポジウム1日目の9月4日は留学交流会とハッカソンを開催します. シンポジウム2・3日目の9月5日と9月6日は本会議(チュートリアル・ポスター発表・各種企画)を開催します.
※ 9/4(水)と9/5(木) - 6日(金)は梅田スカイビル内の異なる会場で行います
※ 合宿形式ではございません.
YANSシンポジウムのうち4日は留学交流会とハッカソンのみを開催し、本会議は5日と6日の2日間で開催します。スポンサーの皆様と参加者の皆様の濃密な交流の場を提供するべく準備を進めております。
近年のシンポジウム参加者は300名を超え、ご参加くださる方が年々増加していることから、スポンサー制度に関して料金体系や特典を見直しました。制度の詳細につきましては、上記のスポンサー募集要項をご確認ください。