AngelikaLanger.com - Effective Java - Angelika Langer Training/Consulting (original) (raw)
Effective Java
| Java 8 Übersicht über das Stream API in Java 8 Java Magazin, Mai 2014 Klaus Kreft & Angelika Langer | Dies ist die Überarbeitung eines Manuskripts für einen Artikel, der im Rahmen einer Kolumne mit dem Titel "Effective Java" im Java Magazin erschienen ist. Die übrigen Artikel dieser Serie sind ebenfalls verfügbar (click here). |
|---|

Mit Java 8 ist das java.util Package des JDK um das Stream API erweitert worden. Dies ist eine Erweiterung des Collection-Frameworks um eine Schnittstelle im Stil der funktionalen Programmierung, die unter anderem die Parallelisierung von Zugriffen auf Collection-Elemente vereinfacht. Wir wollen in diesem Beitrag einen Überblick über das Stream API geben und uns in den nachfolgenden Beiträgen die Benutzung und die Interna genauer ansehen.
Vom Iterator zur Stream-Operation
Traditionell erfolgt der Zugriff auf die Elemente einer Collection in einer Schleife mit Hilfe eines Iterators (oder einer for-each-Schleife, die intern einen Iterator verwendet). Hier ist ein Beispiel:
List words = …;
for (String s : words) {
if (s.length()>0)
System.out.println(s);
Bei dieser Schleife ist fest verdrahtet,_wie_die Elemente in der Liste besucht werden (z.B. mit welchem Thread in welcher Reihenfolge) und was mit den Elementen gemacht wird (z.B. Länge prüfen und ggf. ausdrucken). Das machen Java-Entwickler seit Jahrzehnten so und eigentlich ist daran auch nichts auszusetzen. Der einzige Nachteil ist, dass sich eine solche Schleife nicht gut parallelisieren lässt.
In Java 8 mit den neuen Schnittstellen im JDK sieht die gleiche Funktionalität deshalb so aus:
List words = …;
words.forEach(s -> {
if (s.length()>0)
System.out.println(s);
Hier wird anstelle einer for-each-Schleife die neue forEach-Methode der Liste aufgerufen. Dieser Methode wird - in unserem Beispiel als Lambda-Ausdruck [1]- die Funktionalität übergeben, die auf alle Elemente der Liste angewandt werden soll. Wie die Elemente der Liste besucht werden, verbirgt sich in der Implementierung der forEach-Methode der Liste. Es wird also getrennt in Wie und Was gemacht werden soll. Wie auf die Elemente zugegriffen wird, bestimmt die forEach-Methode der Liste. Was mit den Elementen gemacht wird, übergibt der Benutzer an die forEach-Methode. Mit dieser Trennung ist es nun relativ einfach, den Elementzugriff zu parallelisieren. Dazu muss lediglich die forEach-Methode entsprechend implementiert werden. Für den Benutzer ist das sehr bequem, denn für ihn ändert sich fast nichts.
Konkret sieht es im JDK so aus, dass parallelisierbare Collection-Operationen über sogenannte Streams zur Verfügung stehen. Streams sind eine neue Abstraktion im java.utilPackage. Ihre Schnittstelle ist durch das Interface java.util.stream.Streambeschrieben. Neben der schon erwähnten forEach-Methode gibt es zahlreiche weitere Operationen, z.B. filter, count, sorted, und viele andere, die uns im Weiteren noch ansehen werden. Die Streams gibt es in zwei Varianten, als sequentielle und parallele Streams. Um die Funktionalität aus unserem Beispiel parallel ablaufen zu lassen, müssen wir aus der Liste einen parallelen Stream erzeugen.
Schauen wir uns zunächst einmal an, wie man einen sequentiellen Stream bekommt. Das geht mit Hilfe der Methode stream, die es für alle Collections gibt:
List words = …;
words.stream()
.forEach(s -> {
if (s.length()>0)
System.out.println(s);
Hier funktioniert alles noch sequentiell, so als würden wird das forE a ch()direkt auf der Liste aufrufen. Wenn wir nun die Funktionalität parallel ablaufen lassen wollen, müssen wir einen parallelen Stream anstelle eines sequentiellen Streams verwenden. Das geht so:
List words = …;
words.parallelS tream()
.forEach(s -> {
if (s.length()>0)
System.out.println(s);
Und mehr ist nicht zu tun für den parallelen Zugriff auf die Elemente einer Sequenz. Der vollständige Source-Code für das Beispiel findet sind im Anhang (siehe " Source-Code-Beispiel Nr. 1"). Es bleibt noch festzustellen, dass sich die Ausgabe des Programms durch die Benutzung eines parallelen Streams statt eines sequentiellen Streams ändert: Die Strings werden nicht mehr in der Reihenfolge ausgegeben in der sie in der Liste stehen.
Elementare Stream-Operationen: filter, map, reduce
Die forEach-Methode ist natürlich nicht die einzige Stream-Operation. Es gibt im Stream-Interface insgesamt ca. 40 Methoden. Sehen wir uns nun einige davon an.
Eine elementare Operation auf Sequenzen ist das Filtern. Dafür haben Streams eine filter-Methode, der das Kriterium übergeben werden muss, nach dem die Elemente bewertet werden. Zum Beispiel hätten wir unser obiges Beispiel so formulieren können:
List words = …;
words.stream()
.filter(s->s.length()>0)
.forEach(System.out::println);
In dieser Formulierung wird klarer deutlich, dass die Operation, die wir der forEach-Methode übergeben hatten, aus zwei Aspekten besteht, nämlich zuerst einer Bewertung des jeweiligen Elements und anschließend - falls die Bewertung positiv ausgefallen ist - der Ausgabe des Elements.
Eine weitere elementare Operation auf Sequenzen ist das Abbilden der Elemente auf etwas anderes. Dafür gibt es die map-Methode. Ihr wird die jeweilige Abbildungsvorschrift übergeben. Hier ist ein Beispiel:
List words = …;
words.stream()
.filter(s->s.length()>0)
.map(String::toUpperCase)
.forEach(System.out::println);
Die Worte werden nun nach dem Filtern auf die entsprechende Strings in Großbuchstaben abgebildet, die anschließend ausgegeben werden.
Die dritte der elementaren Operation auf Sequenzen ist das Reduzieren aller Sequenzelemente auf ein einziges Ergebnis. Hier ist ein Beispiel:
List words = …;
String giantString = words.stream()
.filter(s->s.length()>0)
.map(String::toUpperCase)
.reduce("",(s1,s2)->s1+" "+s2);
System.out.println(giantString);
Hier wird aus den gefilterten, in Großbuchstaben verwandelten Worten ein langer String zusammengesetzt, indem die einzelnen Worte anfangend mit einem leeren String sukzessive konkateniert werden. Es gibt eine deutlich effizientere Möglichkeit, diese String-Konkatenation zu bewerkstelligen, wie wir später sehen werden. Aber es ist ein Beispiel für die Reduktion einer ganzen Liste von Strings auf einen einzigen String.
Intermediäre und Terminale Stream-Operationen
Die obigen Beispiele zeigen, dass es üblich ist, Ketten von Stream-Operationen zu bilden. Diesen Programmierstil bezeichnet man als Fluent Programming. Das Stream-API ist bewusst so gestaltet, dass man solche Ketten von Operationen bilden kann. Das funktioniert, weil viele Stream-Operationen wieder einen Stream als Returnwert zurückgeben. Auf diesen Result-Stream kann dann die nächste Stream-Operation angewandt werden, solange bis der Returnwert eben kein Stream mehr ist.
Die Stream-Operationen, die wieder Streams zurückgeben, werden als intermediäre (engl. intermediate) Operationen bezeichnet, im Unterschied zu den terminalen (engl. terminal) Operationen, mit denen die Kette endet.
In unseren obigen Beispielen sind filterund map intermediäre Operation; hingegen sind forEach und reduceterminale Operationen.
Die intermediären Operationen unterscheiden sich von den terminalen Operationen nicht nur durch den Returntyp, sondern auch dadurch, dass die intermediären Operationen verzögert (engl. lazy) und die terminalen Operationen sofort (engl. eager) ausgeführt werden. Es ist also nicht so, dass in einer filter-map-reduce-Kette als erstes die filter-Methode aufgerufen wird, die das Ergebnis des Filterns in einem neuen Stream zwischenspeichert, auf dem dann die map-Methode arbeitet, die wieder einen neuen Stream produziert, den anschließend die reduce-Methode reduziert. So schreibt man es zwar als Entwickler hin und so liest man auch den Code, aber intern läuft es anders ab.
Tatsächlich geht die Abarbeitung erst dann los, wenn die terminale Operation aufgerufen wird. Der Algorithmus besucht dann jeweils ein Element in der Sequenz und wendet darauf die gesamte Kette von filter-map-reduce an. Veranschaulichen wir es uns an einem Beispiel:
String[] txt = { "State", "of", "the", "Lambda", "Libraries", "Edition"};
int sum = Arrays.stream(txt)
.filter(s -> s.length() > 3)
.map(String::length)
.reduce(0, Integer::sum);
Wir haben ein Array von Strings, erzeugen daraus einen Stream von Strings, filtern die längeren Strings heraus, bilden sie auf ihre Stringlänge ab und summieren die Stringlängen.
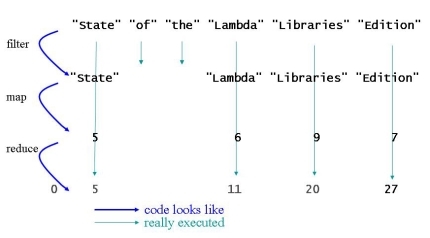
Abbildung 1: Vertikale Abarbeitung der Stream-Operationen
Der Source-Code legt eine horizontale Abarbeitung der filter-map-reduce-Kette nahe. Tatsächlich wird aber vertikal in einer Pipeline abgearbeitet: Das erste Element in der Sequenz wird besucht und gemäß der filter-Operation bewertet. Da seine Stringlänge >3 ist, wird es der nächsten Operation in der Kette (der map-Operation) vorgelegt und auf die Stringlänge abgebildet. Die Stringlänge wird auf den Anfangswert0 der Reduktion aufaddiert. Dann wird das zweite Element der Sequenz besucht, bewertet und als zu kurz verworfen. Die nachfolgenden Operationen mapund reduce werden für dieses Element gar nicht mehr ausgeführt. Dasselbe passiert mit dem dritten Element in der Sequenz. Das vierte Element ist wieder lang genug, wird auf seine Länge abgebildet und seine Stringlänge wird auf das Ergebnis des vorangegangenen Reduktionsschritts aufaddiert. So geht es weiter, bis die gesamte Sequenz abgearbeitet ist und als Ergebnis 27herauskommt.
Die vertikale Abarbeitung der Stream-Operationen in einer Pipeline hat mehrere Performance-Vorteile:
• Die Elemente werden nur genau einmal besucht.
• Es müssen keine Zwischenergebnisse gespeichert werden.
• Die Abarbeitung ist effizient parallelisierbar.
Prinzipiell könnte man auch eine horizontalen Abarbeitung parallelisieren, aber es ist schwer vorstellbar, dass es dadurch schneller wird, denn die Threads müssten sich nach jedem kleinen Arbeitsschritt zwecks Abspeichern des Zwischenergebnisses synchronisieren. Die vertikale, parallele Abarbeitung hingegen ist effizient, da jeder Thread auf einer Teilmenge der Elemente die gesamte Kette der Operationen abarbeitet und lediglich für die terminale Operation (reduc e()) die Teilergebnisse zusammengeführt werden müssen. Es gibt sogar terminale Operation, wie forEach(), für die das Zusammenführen gar nicht nötig ist.
Was ist ein Stream im Unterschied zu einer Collection?
Wenn man sich die oben veranschaulichte vertikale Abarbeitung der Stream-Operationen ansieht, dann ist klar, dass ein Stream etwas anderes ist als eine Collection (oder ein Array). Streams und Collections ist gemeinsam, dass sie beide Sequenzen von Elementen darstellen. Die Interna und Schnittstellen sind aber grundverschieden.
Eine Collection (oder ein Array) legt die Elemente in den internen Datenstrukturen (Array, verkettete Knoten, sortierte Binärbäume, etc.) ab. Ein Stream hingegen speichert keine Elemente ab. Ein Stream hält lediglich einen Verweis auf eine unterliegende Datenstruktur mit Elementen, nämlich die Collection oder das Array, das die Ausgangssequenz bildet. Zusätzlich zur unterliegenden Collection enthält ein Stream eine Liste der Operationen, die auf den Elementen der unterliegenden Collection ausgeführt werden sollen; das sind die sogenannten pending operations. Eine intermediäre Operation führt wie oben geschildert keine Funktionalität auf den Sequenzelementen aus, sondern fügt einem Stream lediglich eine weitere unerledigte Operation hinzu. Erst die terminale Operation stößt die Abarbeitung aller unerledigten Operationen an.
Ein wesentlicher Unterschied zwischen Collections und Streams ist also: Collections (und Arrays) sind Datenspeicher; Streams sind nur ein Verweis auf einen Datenspeicher zusammen mit einer Liste von unerledigten Aufgaben.
Terminale Operationen konsumieren den Stream
Dass die Streams recht abstrakte, künstliche Gebilde sind, merkt man beispielsweise, wenn man auf die Idee kommt, zwei terminale Operationen auf einen Stream anzuwenden. Versuchen wir es einmal:
String[] txt = { "State", "of", "the", "Lambda", "Libraries", "Edition"};
Stream lengths = Arrays.stream(txt)
.filter(s -> s.length() > 3)
.map(String::length);
lengths.forEach(System.out::println);
int sum = lengths.reduce(0, Integer::sum); // <= IllegalStateException
Wir merken uns den Stream, den die letzte intermediäre Operation liefert. Auf diesem Stream rufen wir die terminalen Operationen forEach und reduceauf. Die erste terminale Operation funktioniert wie erwartet, aber die zweite scheitert mit einer IllegalStateExceptionwegen "stream has already been operated upon or closed". Das liegt daran, dass eine terminale Operation den Stream konsumiert. Nach einer terminalen Operation ist der Stream nicht wieder verwendbar.
Solche Fehler können passieren, wenn Referenzvariablen auf die Streams angelegt werden. Wenn man hingegen den Fluent-Programming-Stil verwendet, dann steht ganz automatisch nur eine einzige terminale Operation am Ende der Kette. Die forEach-Methode zum Beispiel liefert void zurück. Darauf kann keine reduce-Methode aufgerufen werden. Falls man es dennoch versucht, merkt es sofort der Compiler. Deshalb ist es günstig, sich den Fluent-Programming-Stil anzugewöhnen; gewisse Fehler werden damit automatisch vermieden.
Was machen wir denn nun in unserem Beispiel? Unser Versuch, vor der Reduktion das Ergebnis von filterund map auszugeben, ist gescheitert. Eigentlich wollten wir uns vergewissern, dass die filter-map-Kette so funktioniert hat, wie wir es uns vorgestellt haben. Die Frage ist: Wie kann man Zwischenergebnisse ausgeben, ohne den Stream zu konsumieren? Dafür muss eine intermediäre Operation verwendet werden: anstelle von forEachverwendet wir peek.
String[] txt = { "State", "of", "the", "Lambda", "Libraries", "Edition"};
int sum = Arrays.stream(txt)
.filter(s -> s.length() > 3)
.map(String::length)
.peek(System.out::println)
.reduce(0, Integer::sum);
Die peek-Methode liefert die Sequenzelemente an die Funktion, die übergeben wurde (in unserem Beispiel System.out::println). Die Elemente sind dann aber nicht konsumiert, sondern werden anschließend an die nachfolgende Operation in der Kette übergeben (in unserem Beispiel an reduce).
Wenn mit peeknach jeder intermediären Operation das Zwischenergebnis ausgegeben wird, dann wird sogar die vertikale Abarbeitung sichtbar.
String[] txt = { "State", "of", "the", "Lambda", "Libraries", "Edition"};
int sum = Arrays.stream(txt)
.filter(s -> s.length() > 3)
.peek(System.out::println)
.map(String::length)
.peek(System.out::println)
.reduce(0, Integer::sum);
Es kommt nämlich nicht heraus:
State
Lambda
Libraries
Edition
5
6
9
sondern es kommt dies heraus:
State
5
Lambda
6
Libraries
9
Edition
Zusammenfassung
Wir haben uns in diesem Beitrag einen ersten Eindruck davon verschafft, was Streams sind. Sie sind im Unterschied zu Collections keine Datenspeicher, sondern Abstraktionen, die einen Verweis auf eine Collection haben zusammen mit einer Liste von unerledigten Operationen. Die Stream-Operationen werden vertikal abgearbeitet, d.h. intermediäre Operationen werden gesammelt und erst beim Auftreten einer terminalen Operation ausgeführt. Die parallele Ausführung von Stream-Operationen ist einfach zu erreichen, indem parallele anstelle von sequentiellen Streams verwendet werden.
Das Stream-API betreffend haben wir einige elementare Operationen (forEach, filter, map, reduce, und peek) kennen gelernt. Im nächsten Beitrag schauen wir uns die übrigen Stream-Operationen an.
| Source-Code-Beispiel Nr. 1 |
|---|
| public class Example { private static List makeWords(String filename) { List words = null; try { words = Arrays.asList( new String(Files.readAllBytes(Paths.get(filename))) .split("[^\\p{L}]") // Split into words; nonletters are delimiters ); } catch (IOException e) { e.printStackTrace(); } return words; } private static void test(String filename) { List words = makeWords(filename); words.parallelStream() .forEach(s -> { if (s.length()>0) System.out.println(Thread.currentThread().getName()+": "+s); } ); } public static void main(String... args) { String filename = "text.txt"; test(filename); } } |
| Auszug aus dem Output des Programms bei Ablauf auf einer Dual-Core-Plattform: main: Puffer main: initialisieren main: d main: h ForkJoinPool.commonPool-worker-1: Dynamische main: Initialwert ForkJoinPool.commonPool-worker-1: Allokation main: kopieren ForkJoinPool.commonPool-worker-1: von ForkJoinPool.commonPool-worker-1: Ressourcen |
Literaturverweise

Die gesamte Serie über Java 8:
| If you are interested to hear more about this and related topics you might want to check out the following seminar: |
|
|---|---|
Seminar  Lambdas & Streams - Java 8 Language Features and Stream API & Internals 3 day seminar (open enrollment and on-site) Java 8 - Lambdas & Stream, New Concurrency Utilities, Date/Time API 4 day seminar (open enrollment and on-site) Effective Java - Advanced Java Programming Idioms 4 day seminar (open enrollment and on-site) Lambdas & Streams - Java 8 Language Features and Stream API & Internals 3 day seminar (open enrollment and on-site) Java 8 - Lambdas & Stream, New Concurrency Utilities, Date/Time API 4 day seminar (open enrollment and on-site) Effective Java - Advanced Java Programming Idioms 4 day seminar (open enrollment and on-site) |
Related Reading  Lambda & Streams Tutorial & Reference In-Depth Coverage of all aspects of lambdas & streams Lambdas in Java 8 Conference Presentation at JFokus 2012 (slides) Lambda & Streams Tutorial & Reference In-Depth Coverage of all aspects of lambdas & streams Lambdas in Java 8 Conference Presentation at JFokus 2012 (slides)  Lambdas in Java 8 Conference Presentation at JavaZone 2012 (video) Lambdas in Java 8 Conference Presentation at JavaZone 2012 (video) |