setvaropts - Set variable import options - MATLAB (original) (raw)
Main Content
Set variable import options
Syntax
Description
[opts](#bvetpkh-1%5Fsep%5Fshared-opts) = setvaropts([opts](#bvetpkh-1%5Fsep%5Fshared-opts),[Name,Value](#namevaluepairarguments)) updates all the variables in the opts object based on the specifications in the Name,Value arguments and returns theopts object.
[opts](#bvetpkh-1%5Fsep%5Fshared-opts) = setvaropts([opts](#bvetpkh-1%5Fsep%5Fshared-opts),[selection](#mw%5F8b2628c3-ea16-4234-88b0-859bd39b2c77),[Name,Value](#namevaluepairarguments)) updates and returns opts for the variables specified in theselection argument, based on the specifications in theName,Value arguments.
Examples
Set Options for Selected Variables
Create an import options object, set the options for selected variables, and import the data using the tailored options and the readtable function.
Create an options object for the spreadsheet patients.xls.
opts = detectImportOptions('patients.xls');
Set the FillValue property for the Smoker, Diastolic, and Systolic variables.
opts = setvaropts(opts,'Smoker','FillValue',false); opts = setvaropts(opts,{'Diastolic','Systolic'},'FillValue',0);
Select the variables you want to import.
opts.SelectedVariableNames = {'Smoker','Diastolic','Systolic'};
Import the variables and display a summary.
T = readtable('patients.xls',opts); summary(T)
T: 100x3 table
Variables:
Smoker: logical (34 true)
Diastolic: double
Systolic: doubleStatistics for applicable variables:
NumMissing Min Median Max Mean Std
Diastolic 0 68 81.5000 99 82.9600 6.9325
Systolic 0 109 122 138 122.7800 6.7128 Set Options for Numeric Data Containing Missing or Incomplete Records
Importing data that has missing or incomplete fields requires recognizing the missing instances and deciding how the missing instances will be imported. Use importOptions to capture both these decisions and fetch the data using readtable.
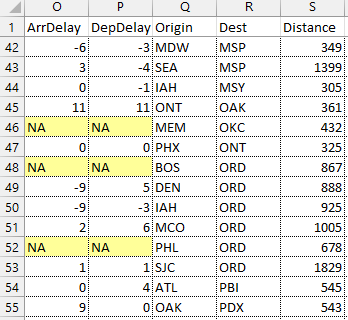
Create an import options object for the file, update properties that control the import of missing data, and then use readtable to import the data. Note that the dataset airlinesmall_subset.csv has two numeric variables ArrDelay and DepDelay, that contain missing data indicated by NA.
Create an import options object from the file.
opts = detectImportOptions("airlinesmall_subset.csv");
Use the TreatAsMissing property to specify the characters in the data that are place holders for missing instances. In this example, the two numeric variables ArrDelay and DepDelay contain missing fields that contain the text NA.
opts = setvaropts(opts,["ArrDelay","DepDelay"],"TreatAsMissing","NA");
Specify the action for the importing function to take when importing missing instances. See ImportOptions properties page for more options.
opts.MissingRule = "fill";
Specify the value to use when the importing function finds a missing instance. Here the missing instances in variables ArrDelay and DepDelay are replaced by 0.
opts = setvaropts(opts,["ArrDelay","DepDelay"],"FillValue",0);
Select the variables you want to work with and import them using readtable.
opts.SelectedVariableNames = ["ArrDelay","DepDelay"]; T = readtable("airlinesmall_subset.csv",opts);
Examine the values in ArrDelay and DepDelay. Verify that the importing function replaced the missing values denoted by NA.
ans=14×2 table ArrDelay DepDelay ________ ________
3 -4
0 -1
11 11
0 0
0 0
0 0
-9 5
-9 -3
2 6
0 0
1 1
0 4
9 0
-2 4 Set Options for Hexadecimal and Binary Numbers
The readtable function automatically detects hexadecimal and binary numbers with the 0x and 0b prefixes. To import such numbers when they do not have prefixes, use an import options object.
Create an import options object for the file hexAndBinary.txt. Its third column has hexadecimal numbers without the 0x prefix.
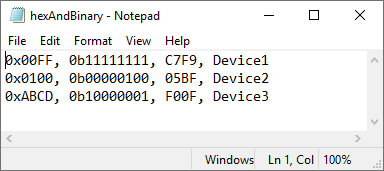
opts = detectImportOptions('hexAndBinary.txt')
opts = DelimitedTextImportOptions with properties:
Format Properties: Delimiter: {','} Whitespace: '\b\t ' LineEnding: {'\n' '\r' '\r\n'} CommentStyle: {} ConsecutiveDelimitersRule: 'split' LeadingDelimitersRule: 'keep' TrailingDelimitersRule: 'ignore' EmptyLineRule: 'skip' Encoding: 'UTF-8'
Replacement Properties: MissingRule: 'fill' ImportErrorRule: 'fill' ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more} VariableTypes: {'auto', 'auto', 'char' ... and 1 more} SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more} VariableOptions: [1-by-4 matlab.io.VariableImportOptions] Access VariableOptions sub-properties using setvaropts/getvaropts VariableNamingRule: 'modify'
Location Properties: DataLines: [1 Inf] VariableNamesLine: 0 RowNamesColumn: 0 VariableUnitsLine: 0 VariableDescriptionsLine: 0 To display a preview of the table, use preview
To specify that the third column should be imported as hexadecimal values, despite the lack of a prefix, use the setvaropts function. Set the variable type of the third variable to int32. Set the number system for importing the third column to hex.
opts = setvaropts(opts,3,'NumberSystem','hex','Type','int32')
opts = DelimitedTextImportOptions with properties:
Format Properties: Delimiter: {','} Whitespace: '\b\t ' LineEnding: {'\n' '\r' '\r\n'} CommentStyle: {} ConsecutiveDelimitersRule: 'split' LeadingDelimitersRule: 'keep' TrailingDelimitersRule: 'ignore' EmptyLineRule: 'skip' Encoding: 'UTF-8'
Replacement Properties: MissingRule: 'fill' ImportErrorRule: 'fill' ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype VariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more} VariableTypes: {'auto', 'auto', 'int32' ... and 1 more} SelectedVariableNames: {'Var1', 'Var2', 'Var3' ... and 1 more} VariableOptions: [1-by-4 matlab.io.VariableImportOptions] Access VariableOptions sub-properties using setvaropts/getvaropts VariableNamingRule: 'modify'
Location Properties: DataLines: [1 Inf] VariableNamesLine: 0 RowNamesColumn: 0 VariableUnitsLine: 0 VariableDescriptionsLine: 0 To display a preview of the table, use preview
Read the file and import the first three columns as numeric values. The readtable function automatically detects that the first and second columns contain hexadecimal and binary values. The import options object specifies that the third column also contains hexadecimal values.
T = readtable('hexAndBinary.txt',opts)
T=3×4 table
Var1 Var2 Var3 Var4
_____ ____ _____ ___________
255 255 51193 {'Device1'}
256 4 1471 {'Device2'}
43981 129 61455 {'Device3'}Set Options When Importing Text Data
Use the setvaropts function to update properties that control the import of text data. First, get the import options object for the file. Next, examine and update the options for the text variables. Finally, import the variables using the readtable function.
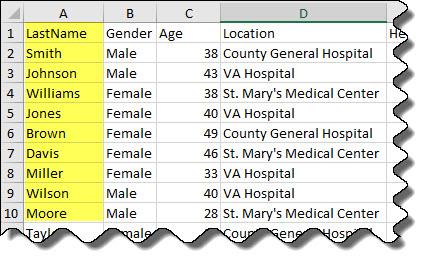
Preview the data in patients.xls. Notice the text data in the column LastName. Only a preview of the first 10 rows is shown here.
Get the import options object.
opts = detectImportOptions('patients.xls');
Get and examine the VariableImportOptions for variable LastName.
getvaropts(opts,'LastName')
ans = TextVariableImportOptions with properties:
Variable Properties: Name: 'LastName' Type: 'char' FillValue: '' TreatAsMissing: {} QuoteRule: 'remove' Prefixes: {} Suffixes: {} EmptyFieldRule: 'missing'
String Options: WhitespaceRule: 'trim'
Set the data type of the variable to string.
opts = setvartype(opts,'LastName','string');
Set the FillValue property of the variable to replace missing values with 'NoName'.
opts = setvaropts(opts,'LastName','FillValue','NoName');
Select, read, and display a preview of the first 10 rows of the variable.
opts.SelectedVariableNames = 'LastName'; T = readtable('patients.xls',opts); T.LastName(1:10)
ans = 10x1 string "Smith" "Johnson" "Williams" "Jones" "Brown" "Davis" "Miller" "Wilson" "Moore" "Taylor"
Set Options When Importing Logical Data
Use the setvaropts function to update properties that control the import of logical data. First, get the import options object for the file. Next, examine and update the options for the logical variables. Finally, import the variables using the readtable function.
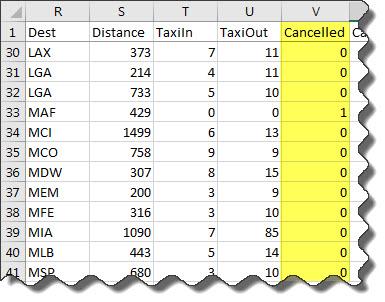
Preview the data in airlinesmall_subset.xlsx. Notice the logical data in the column Cancelled. Only a preview of rows 30 to 40 is shown here.
Get the import options object.
opts = detectImportOptions('airlinesmall_subset.xlsx');
Get and examine the VariableImportOptions for variable Cancelled.
getvaropts(opts,'Cancelled')
ans = NumericVariableImportOptions with properties:
Variable Properties: Name: 'Cancelled' Type: 'double' FillValue: NaN TreatAsMissing: {} QuoteRule: 'remove' Prefixes: {} Suffixes: {} EmptyFieldRule: 'missing'
Numeric Options: ExponentCharacter: 'eEdD' DecimalSeparator: '.' ThousandsSeparator: '' TrimNonNumeric: 0 NumberSystem: 'decimal'
Set the data type of the variable to logical.
opts = setvartype(opts,'Cancelled','logical');
Set the FillValue property of the variable to replace missing values with true.
opts = setvaropts(opts,'Cancelled','FillValue',true);
Select, read, and display a summary of the variable.
opts.SelectedVariableNames = 'Cancelled'; T = readtable('airlinesmall_subset.xlsx',opts); summary(T)
T: 1338x1 table
Variables:
Cancelled: logical (29 true)Import Date and Time Data
Use DatetimeVariableImportOptions properties to control the import of datetime data. First, get the ImportOptions object for the file. Next, examine and update the VariableImportOptions for the datetime variables. Finally, import the variables using readtable.
Preview of data in outages.csv. Notice the date and time data in the columns OutageTime and RestorationTime. Only the first 10 rows are shown here.
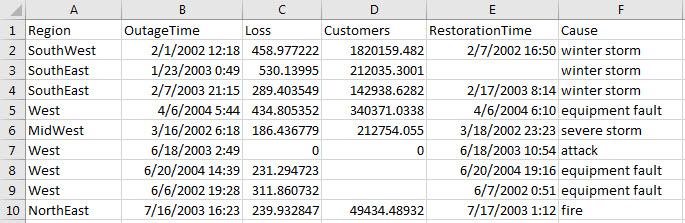
Get the import options object.
opts = detectImportOptions('outages.csv');
Get and examine the VariableImportOptions for datetime variables OutageTime and RestorationTime.
varOpts = getvaropts(opts,{'OutageTime','RestorationTime'})
varOpts = 1x2 DatetimeVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
DatetimeFormat
DatetimeLocale
TimeZone
InputFormatSet the FillValue property of the variables to replace missing values with current date and time.
opts = setvaropts(opts,{'OutageTime','RestorationTime'},... 'FillValue','now');
Select, read, and preview the two variables. Notice the missing value in the second row of RestorationTime has been filled with current date and time.
opts.SelectedVariableNames = {'OutageTime','RestorationTime'}; T = readtable('outages.csv',opts); T(1:10,:)
ans=10×2 table OutageTime RestorationTime ________________ ________________
2002-02-01 12:18 2002-02-07 16:50
2003-01-23 00:49 2025-01-23 01:44
2003-02-07 21:15 2003-02-17 08:14
2004-04-06 05:44 2004-04-06 06:10
2002-03-16 06:18 2002-03-18 23:23
2003-06-18 02:49 2003-06-18 10:54
2004-06-20 14:39 2004-06-20 19:16
2002-06-06 19:28 2002-06-07 00:51
2003-07-16 16:23 2003-07-17 01:12
2004-09-27 11:09 2004-09-27 16:37Set Options When Importing Categorical Data
Use the setvaropts function to update properties that control the import of categorical data. First, get the import options object for the file. Next, examine and update the options for the categorical variables. Finally, import the variables using the readtable function.
Preview the data in outages.csv. Notice the categorical data in the columns Region and Cause. This table shows only the first 10 rows.
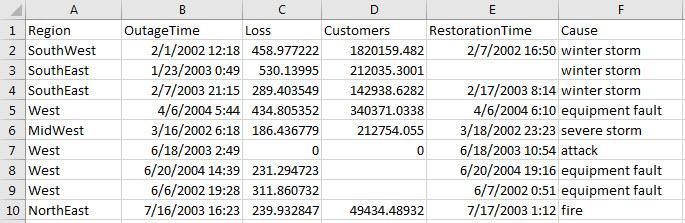
Get the import options object.
opts = detectImportOptions('outages.csv');
Get and examine the options for the variables Region and Cause.
getvaropts(opts,{'Region','Cause'})
ans = 1x2 TextVariableImportOptions array with properties:
Name
Type
FillValue
TreatAsMissing
QuoteRule
Prefixes
Suffixes
EmptyFieldRule
WhitespaceRuleSet the data type of the variables to categorical.
opts = setvartype(opts,{'Region','Cause'},'categorical');
Set the FillValue property of the variables to replace missing values with category name 'Miscellaneous'. Set TreatAsMissing property to 'unknown'.
opts = setvaropts(opts,{'Region','Cause'},... 'FillValue','Miscellaneous',... 'TreatAsMissing','unknown');
Select, read, and display a summary of the two variables.
opts.SelectedVariableNames = {'Region','Cause'}; T = readtable('outages.csv',opts); summary(T)
T: 1468x2 table
Variables:
Region: categorical (5 categories)
Cause: categorical (10 categories)Statistics for applicable variables:
NumMissing
Region 0
Cause 0 Remove Prefix or Suffix Characters from Variables
Import tabular data containing variables that have unwanted prefix and suffix characters. First, create an import options object and preview the data. Then, select the variables of interest and set their variable types and properties to remove the unwanted characters. Finally, import the data of interest.
Create import options for the file and preview the table.
filename = 'pref_suff_trim.csv'; opts = detectImportOptions(filename); preview(filename,opts)
Warning: Column headers from the file were modified to make them valid MATLAB identifiers before creating variable names for the table. The original column headers are saved in the VariableDescriptions property. Set 'VariableNamingRule' to 'preserve' to use the original column headers as table variable names.
ans=8×5 table Time DayOfWeek Power Total_Fees Temperature _________________________ _________________ ______________ ___________ _____________
{'Timestamp:1/1/06 0:00'} {'& Sun %20'} {'54.5448 MW'} {'$1.23' } {'-7.2222 C'}
{'Timestamp:1/2/06 1:00'} {'& Thu %20'} {'.3898 MW' } {'$300.00'} {'-7.3056 C'}
{'Timestamp:1/3/06 2:00'} {'& Sun %20'} {'51.6344 MW'} {'£2.50' } {'-7.8528 C'}
{'Timestamp:1/4/06 3:00'} {'& Sun %20'} {'51.5597 MW'} {'$0.00' } {'-8.1778 C'}
{'Timestamp:1/5/06 4:00'} {'& Wed %20'} {'51.7148 MW'} {'¥4.00' } {'-8.9343 C'}
{'Timestamp:1/6/06 5:00'} {'& Sun %20'} {'52.6898 MW'} {'$0.00' } {'-8.7556 C'}
{'Timestamp:1/7/06 6:00'} {'& Mon %20'} {'55.341 MW' } {'$50.70' } {'-8.0417 C'}
{'Timestamp:1/8/06 7:00'} {'& Sat %20'} {'57.9512 MW'} {'$0.00' } {'-8.2028 C'}Select variables of interest, specify their types, and examine their variable import options values.
opts.SelectedVariableNames = {'Time','Total_Fees','Temperature'}; opts = setvartype(opts,'Time','datetime'); opts = setvaropts(opts,'Time','InputFormat','MM/dd/uu HH:mm'); % Specify datetime format opts = setvartype(opts,{'Total_Fees','Temperature'},'double'); getvaropts(opts,{'Time','Total_Fees','Temperature'})
ans = 1×3 VariableImportOptions array with properties:
Variable Options: (1) | (2) | (3) Name: 'Time' | 'Total_Fees' | 'Temperature' Type: 'datetime' | 'double' | 'double' FillValue: NaT | NaN | NaN TreatAsMissing: {} | {} | {} EmptyFieldRule: 'missing' | 'missing' | 'missing' QuoteRule: 'remove' | 'remove' | 'remove' Prefixes: {} | {} | {} Suffixes: {} | {} | {}
To access sub-properties of each variable, use getvaroptsSet the Prefixes, Suffixes, and TrimNonNumeric properties of variable import options to remove 'Timestamp:' from the variable Time, remove suffix 'C' from variable Temperature, and remove all nonnumeric characters from variable Total_Fees. Preview the table with the new import options.
opts = setvaropts(opts,'Time','Prefixes','Timestamp:'); opts = setvaropts(opts,'Temperature','Suffixes','C'); opts = setvaropts(opts,'Total_Fees','TrimNonNumeric',true); preview(filename,opts)
ans=8×3 table Time Total_Fees Temperature ______________ __________ ___________
01/01/06 00:00 1.23 -7.2222
01/02/06 01:00 300 -7.3056
01/03/06 02:00 2.5 -7.8528
01/04/06 03:00 0 -8.1778
01/05/06 04:00 4 -8.9343
01/06/06 05:00 0 -8.7556
01/07/06 06:00 50.7 -8.0417
01/08/06 07:00 0 -8.2028 Import the data using readtable.
T = readtable(filename,opts);
Manage Import of Empty Fields
Create an import options object for a file containing empty fields. Use the EmptyFieldRule parameter to manage the import of empty fields in your data. First, preview the data, and then set the EmptyFieldRule parameter for a specific variable. Finally, set EmptyFieldRule for all the variables and import the data.
Create an import options object for a file containing empty fields. Get the first eight rows of the table using the preview function. The default value for EmptyFieldRule is 'missing'. Therefore, the importing function treats empty fields as missing and replaces them with the FillValue value for that variable. Using VariableOptions for the third variable, preview the data. Here, the preview function imports the empty fields in the third variable as NaNs.
filename = 'DataWithEmptyFields.csv'; opts = detectImportOptions(filename); opts.VariableOptions(3) % Display the Variable Options for the 3rd Variable
ans = NumericVariableImportOptions with properties:
Variable Properties: Name: 'Double' Type: 'double' FillValue: NaN TreatAsMissing: {} QuoteRule: 'remove' Prefixes: {} Suffixes: {} EmptyFieldRule: 'missing'
Numeric Options: ExponentCharacter: 'eEdD' DecimalSeparator: '.' ThousandsSeparator: '' TrimNonNumeric: 0 NumberSystem: 'decimal'
ans=8×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ __________ ________ __________
{'abc' } {'a' } 1 01/14/0018 {'TRUE' } 00:00:01 {'abc' }
{0x0 char} {'b' } 2 01/21/0018 {'FALSE' } 09:00:01 {'def' }
{'ghi' } {0x0 char} 3 01/31/0018 {'TRUE' } 02:00:01 {'ghi' }
{'jkl' } {'a' } NaN 02/23/2018 {'FALSE' } 03:00:01 {'jkl' }
{'mno' } {'a' } 4 NaT {'FALSE' } 04:00:01 {'mno' }
{'pqr' } {'b' } 5 01/23/0018 {0x0 char} 05:00:01 {'pqr' }
{'stu' } {'b' } 5 03/23/0018 {'FALSE' } NaN {'stu' }
{0x0 char} {'a' } 6 03/24/2018 {'TRUE' } 07:00:01 {0x0 char}Set EmptyFieldRule for the second variable in the table. First, select the variable, and then set EmptyFieldRule to 'auto'. Here, the readtable function imports empty fields of the categorical variable as <undefined>.
opts.SelectedVariableNames = 'Categorical'; opts = setvartype(opts,'Categorical','categorical'); opts = setvaropts(opts,'Categorical','EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×1 table Categorical ___________
a
b
<undefined>
a
a
b
b
a
a
<undefined>Next, set the EmptyFieldRule parameter for all the variables in the table. First, update the data types of the variables appropriately. For this example, set the data type of the fifth and seventh variables to logical and string, respectively. Then, set EmptyFieldRule for all the variables to 'auto'. The importing function imports the empty fields based on data type of the variable. Here, the readtable function imports empty fields of the logical variable as 0 and empty fields of the categorical variable as <undefined>.
VariableNames = opts.VariableNames; opts.SelectedVariableNames = VariableNames; % select all variables opts = setvartype(opts,{'Logical','String'},{'logical','string'}); opts = setvaropts(opts,VariableNames,'EmptyFieldRule','auto'); T = readtable(filename,opts)
T=10×7 table
Text Categorical Double Datetime Logical Duration String
__________ ___________ ______ __________ _______ ________ _________
{'abc' } a 1 01/14/0018 true 00:00:01 "abc"
{0x0 char} b 2 01/21/0018 false 09:00:01 "def"
{'ghi' } <undefined> 3 01/31/0018 true 02:00:01 "ghi"
{'jkl' } a NaN 02/23/2018 false 03:00:01 "jkl"
{'mno' } a 4 NaT false 04:00:01 "mno"
{'pqr' } b 5 01/23/0018 false 05:00:01 "pqr"
{'stu' } b 5 03/23/0018 false NaN "stu"
{0x0 char} a 6 03/24/2018 true 07:00:01 ""
{0x0 char} a 7 03/25/2018 true 08:00:01 <missing>
{'xyz' } <undefined> NaN NaT true 06:00:01 "xyz" In addition to 'missing' and 'auto', you can also set the EmptyFieldRule parameter to 'error'. When you set it to 'error', the readtable function imports empty fields by following the procedure specified in the ImportErrorRule parameter.
Input Arguments
File import options, specified as a SpreadsheetImportOptions, DelimitedTextImportOptions, or a FixedWidthImportOptions object created by the detectImportOptions function. The opts object contains properties that control the data import process, such as variable properties, data location properties, replacement rules, and others.
selection — Selected variables
character vector | string scalar | cell array of character vector | string array | array of indices | logical array
Selected variables, specified as a character vector, string scalar, cell array of character vectors, string array, array of numeric indices, or a logical array.
Variable names (or indices) must be a subset of the names contained in theVariableNames property of the opts object.
Example: 'Height'
Example: {'Height','LastName'}
Example: [5 9]
Data Types: char | string | cell | uint64 | logical
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose Name in quotes.
Example: opts = setvaropts(opts,'Weight','FillValue',0) sets theFillValue for the variable Weight to0.
Common Options for All Variable Types
Type — Data type of variables
'char' | 'string' | 'single' | 'double' | 'int8' | 'int16' | ...
Data type of variables, specified as a data type listed in the table.
| Data Type | Description |
|---|---|
| 'char''string' | Text. |
| 'single''double' | Single- or double-precision floating point numbers. |
| 'int8','int16','int32','int64''uint8','uint16','uint32','uint64' | Signed or unsigned integers, stored as 8-, 16-, 32-, or 64-bit integers.The integer data types do not define values corresponding to the floating-point numbers NaN,-Inf, and+Inf. Therefore when you import floating-point data as an array of integers, the importing function converts the undefined floating-point numbers:NaN is converted to0.-Inf is converted to the smallest integer for the specified integer data type using the intmin function.+Inf is converted to the largest integer for the specified integer data type using the intmax function. |
| 'logical' | True or false values (for example,true, false,1, or0). |
| 'datetime' | Dates and times that specify points in time (for example, 2019-12-10 09:12:56 specifying December 10, 2019, 9:12:56 a.m.). |
| 'duration' | Lengths of time (for example,05:13:45 specifying 5 hours, 13 minutes, and 45 seconds). |
| 'categorical' | Numeric or text data that specify categories (for example, 'red','green', and'blue' specifying the names of three categories). |
FillValue — Replacement value for missing data
character vector | string scalar | scalar numeric value | true | false
Replacement value for missing data, depending on the type of the variable, specified as a character vector, string scalar, scalar numeric, or a logical value true orfalse.
| Type of Variable | Description |
|---|---|
| Text | Replacement text specified as a character vector or string scalar.Example: 'not applicable' |
| Numeric | Scalar numeric to replace missing instancesThe importing function converts the input forFillValue to the data type specified by the Type property of the variable. For example, ifType property value isuint8, then the importing function also converts the value of theFillValue property touint8.Example: 0 |
| Logical | true orfalse.Example: false |
| Datetime | Character vector or string scalar, or a scalar value representing date and time data. For more information on validdatetime inputs, see thedatetime function page.Example: 'now' sets the missing datetime instances to the current date and time.Example: [1998 12 1] sets the missing datetime instances to the date December 1st, 1998. |
| Duration | Character vector or string scalar, or a scalar value representing duration data. For more information on valid duration inputs, see the duration function page.Example: '12:30:16' sets the missing duration instances to the duration of 12 hours, 30 minutes, and 16 seconds. |
| Categorical | Character vector or string scalar containing the name to use for the replacement category.Example: 'Miscellaneous' assigns the category name Miscellaneous to missing instances in the categorical data. |
To direct the import of data that is missing, unconvertible, or that causes errors, use these four properties together: FillValue, TreatAsMissing, MissingRule, and ErrorRule. The importing function uses the value specified in the FillValue property when:
- Data is unconvertible or matches a value in
TreatAsMissing. MissingRuleor theErrorRuleis set tofill.
Text to interpret as missing data, specified as a character vector, string scalar, cell array of character vectors, or string array.
When the importing function finds missing instances, it uses the specification in the MissingRule property to determine the appropriate action.
Example: 'TreatAsMissing',{'NA','TBD'} instructs the importing function to treat any occurrence of NA or TBD as a missing fields.
Data Types: char | string | cell
Process to manage double quotation marks in the data, specified as one of the values in this table.
| Quote Rule | Process |
|---|---|
| 'remove' | After removing leading white space, if double quotes (") surround characters, then the importing function removes both the opening double quote and the next occurring double quote, which would be interpreted as the closing double quote.Example:"The" Example Text is imported asThe Example Text.Example: The "Example" Text is imported as The "Example" Text.If two sets of double quotes ("") surround characters, then the importing function removes the first two occurrences.Example: ""abc"" is imported as abc"".Example: "The" "Example" Text is imported as The "Example" Text.Example: The "Example" "Text" is imported as The "Example" "Text".If a pair of opening and closing quotes surrounding characters is followed by a single lone unpaired double quotes, then the importing function ignores the lone unpaired double quote.Example:"abc"" is imported asabc".Example: "abc"def" is imported asabcdef".Escaped double quotes within an outer pair of double quotes will be replaced with singular double quotes.Example:"The ""Example"" ""Text""" is imported asThe "Example" "Text". |
| 'keep' | Retain all quotation marks. |
| 'error' | Report an error when converting data which begins with a double quotation mark ("). Use this setting if the field should never be quoted. |
Data Types: char | string
EmptyFieldRule — Procedure to manage empty fields
'missing' (default) | 'error' | 'auto'
Procedure to manage empty fields in the data, specified as one of these values:
'missing'— Treat empty fields asmissingvalues and follow the procedure specified in theMissingRuleproperty.'error'— Treat empty fields as import errors and follow the procedure specified in theImportErrorRuleproperty.'auto'— Import empty fields based on the data type of the variable. Import an empty text value as an empty (zero length) character vector or string. Import an empty categorical value as an undefined categorical value. Import all other data types using the procedure specified by theImportErrorRuleproperty.
Example: opts = setvaropts(opts,'RestorationTime','EmptyFieldRule','auto');
Data Types: char | string
Prefixes — Text to remove from prefix position
character vector | cell array of character vectors | string scalar | string array
Text to remove from the prefix position of a variable value, specified as a character vector, cell array of character vectors, string scalar, or string array.
Example: opts = setvaropts(opts,'Var1','Prefixes','$') sets thePrefixes option for the variableVar1. If Var1 contains a value of '$500', then readtable reads it as '500'.
Data Types: char | string | cell
Suffixes — Text to remove from suffix position
character vector | cell array of character vectors | string scalar | string array
Text to remove from the suffix position of a variable value, specified as a character vector, cell array of character vectors, string scalar, or string array.
Example: opts = setvaropts(opts,'Var1','Suffixes','/-') sets theSuffixes option for the variableVar1. If Var1 contains a value of '$500/-' , then readtable reads it as '$500'.
Data Types: char | string | cell
Text Variable Options
Procedure to manage leading and trailing white spaces when importing text data, specified as one of the values in the table.
| White Space Rule | Process |
|---|---|
| 'trim' | Remove any leading or trailing white spaces from the text. Interior white space is unaffected.Example: ' World Time ' is imported as 'World Time' |
| 'trimleading' | Remove only the leading white spaces. Example: ' World Time ' is imported as 'World Time ' |
| 'trimtrailing' | Remove only the trailing white spaces. Example: ' World Time ' is imported as ' World Time' |
| 'preserve' | Preserve white spaces.Example: ' World Time ' is imported as ' World Time ' |
Data Types: char | string
Numeric Variable Options
Characters indicating the exponent, specified as a character vector or string scalar. The importing function uses the ExponentCharacter property to recognize the characters indicating the exponent for a number expressed in the scientific notation.
Example: If varOpts.ExponentCharacter = 'a', then the importing function imports the text "1.2a3" as the number 1200.
Data Types: char | string
Characters indicating the decimal separator in numeric variables, specified as a character vector or string scalar. The importing function uses the characters specified in theDecimalSeparator name-value pair to distinguish the integer part of a number from the decimal part.
When converting to integer data types, numbers with a decimal part are rounded to the nearest integer.
Example: If name-value pair is specified as 'DecimalSeparator',',', then the importing function imports the text "3,14159" as the number3.14159.
Data Types: char | string
Characters that indicate the thousands grouping in numeric variables, specified as a character vector or string scalar. The thousands grouping characters act as visual separators, grouping the number at every three place values. The importing function uses the characters specified in the ThousandsSeparator name-value pair to interpret the numbers being imported.
Example: If name-value pair is specified as'ThousandsSeparator',',', then the importing function imports the text "1,234,000" as 1234000.
Data Types: char | string
TrimNonNumeric — Remove nonnumeric characters
false (default) | true
Remove nonnumeric characters from a numeric variable, specified as a logical true or false.
Example: If name-value pair is specified as 'TrimNonNumeric',true, then the importing function reads '$500/-' as500.
Data Types: logical
NumberSystem — System for interpreting numeric variables
'decimal' (default) | 'hex' | 'binary'
System for interpreting numeric variables, specified as'decimal', 'hex', or'binary'.
| Value of'NumberSystem' | Description |
|---|---|
| 'decimal' | Treats input numeric variables as having decimal values.Interprets values as having the data type specified by the 'Type' name-value pair, or 'double' if'Type' is not specified. |
| 'hex' | Treats input numeric variables as having hexadecimal (base-16) values. Input values can have '0x' or'0X' as prefixes, but the prefixes are not required.Interprets values as having the integer data type specified by the'Type' name-value pair. |
| 'binary' | Treats input numeric variables as having binary (base-2) values. Input values can have'0b' or '0B' as prefixes, but the prefixes are not required.Interprets values as having the integer data type specified by the 'Type' name-value pair. |
Logical Variable Options
Text to treat as the logical value true, specified as a character vector, string scalar, cell array of character vectors, or a string array.
Example: If varOpts.TrueSymbols = {'t','TRUE'}, then the importing function imports any fields containing t or TRUE as the logical value true.
Data Types: char | string | cell
Text to treat as the logical value false, specified as a character vector, string scalar, cell array of character vectors, or a string array.
Example: If varOpts.FalseSymbols = {'f','FALSE'}, then the importing function imports any fields containing f or FALSE as the logical value false.
Data Types: char | string | cell
Indicator to match case, specified as a logical value true or false.
To interpret the input data as missing, true, or false, the importing function matches the data to values specified in TreatAsMissing, TrueSymbols, and FalseSymbols.
Datetime Variable Options
Display format, specified as a character vector or string scalar. TheDatetimeFormat property controls the display format of dates and times in the output. Specify DatetimeFormat as one of these values.
| Value of DatetimeFormat | Description |
|---|---|
| 'default' | Use the default display format. |
| 'defaultdate' | Use the default display format for datetime values created without time components. |
| 'preserveinput' | Use the format specified by the input format,InputFormat. |
| Custom formats | Use the letters A-Z anda-z to construct a custom value forDatetimeFormat. These letters correspond to the Unicode® Locale Data Markup Language (LDML) standard for dates. You can include non-ASCII or nonletter characters such as a hyphen, space, or colon to separate the fields. To include the letters A-Z and a-z as literal characters in the format, enclose them with single quotes. |
The factory default format depends on your system locale. To change the default display format, see Default datetime Format.
Data Types: char | string
Format of the input text representing dates and times, specified as a character vector or string scalar that contains letter identifiers.
This table shows several common input formats and examples of the formatted input for the date, Saturday, April 19, 2014 at 9:41:06 PM in New York City.
| Value of InputFormat | Example |
|---|---|
| 'yyyy-MM-dd' | 2014-04-19 |
| 'dd/MM/yyyy' | 19/04/2014 |
| 'dd.MM.yyyy' | 19.04.2014 |
| 'yyyy年 MM月 dd日' | 2014年 04月 19日 |
| 'MMMM d, yyyy' | April 19, 2014 |
| 'eeee, MMMM d, yyyy h:mm a' | Saturday, April 19, 2014 9:41 PM |
| 'MMMM d, yyyy HH:mm:ss Z' | April 19, 2014 21:41:06 -0400 |
| 'yyyy-MM-dd''T''HH:mmXXX' | 2014-04-19T21:41-04:00 |
For a complete list of valid letter identifiers, see the Format property for datetime arrays.
Example: 'InputFormat','eeee, MMMM d, yyyy HH:mm:ss'
Data Types: char | string
Locale to interpret dates, specified as a character vector or string scalar. TheDatetimeLocale value determines how the importing function interprets text that represents dates and times.
Set the DatetimeLocale to one of these values:
'system'— Specify your system locale.- Character vector or string scalar — Use the form
_`xx`__ _`YY`_, wherexxis a lowercase ISO 639-1 two-letter code that specifies a language, andYYis an uppercase ISO 3166-1 alpha-2 code that specifies a country.
This table lists some common values for the locale.
| Locale | Language | Country |
|---|---|---|
| 'de_DE' | German | Germany |
| 'en_GB' | English | United Kingdom |
| 'en_US' | English | United States |
| 'es_ES' | Spanish | Spain |
| 'fr_FR' | French | France |
| 'it_IT' | Italian | Italy |
| 'ja_JP' | Japanese | Japan |
| 'ko_KR' | Korean | Korea |
| 'nl_NL' | Dutch | Netherlands |
| 'zh_CN' | Chinese (simplified) | China |
Example: varOpts.DatetimeLocale = 'de_DE' sets the date time locale to German.
Note
The Locale value determines how input values are interpreted. The display format and language is specified by the Locale option in the Datetime format section of the Preferences window. To change the default datetime locale, see Set Command Window Preferences.
Data Types: char | string
TimeZone — Time zone
'' (default) | character vector | string scalar
Time zone, specified as a character vector or string scalar. The value of TimeZone specifies the time zone that the importing function uses to interpret the input data.TimeZone also specifies the time zone of the output array. If the input data are character vectors that include a time zone, then the importing function converts all values to the specified time zone.
TimeZone use any of these values:
'', to create “unzoned” datetime values that do not belong to a specific time zone.- A time zone region from the IANA Time Zone Database; for example,
'America/Los_Angeles'. The name of a time zone region accounts for the current and historical rules for standard and daylight offsets from UTC that are observed in a geographic region. - An ISO 8601 character vector of the form
+HH:mmor-HH:mm. For example,'+01:00', specifies a time zone that is a fixed offset from UTC. 'UTC', to create datetime values in Coordinated Universal Time.'UTCLeapSeconds', to create datetime values in Coordinated Universal Time that account for leap seconds.
This table lists some common names of time zone regions from the IANA Time Zone Database.
| Value ofTimeZone | UTC Offset | UTC DST Offset |
|---|---|---|
| 'Africa/Johannesburg' | +02:00 | +02:00 |
| 'America/Chicago' | −06:00 | −05:00 |
| 'America/Denver' | −07:00 | −06:00 |
| 'America/Los_Angeles' | −08:00 | −07:00 |
| 'America/New_York' | −05:00 | −04:00 |
| 'America/Sao_Paulo' | −03:00 | −02:00 |
| 'Asia/Hong_Kong' | +08:00 | +08:00 |
| 'Asia/Kolkata' | +05:30 | +05:30 |
| 'Asia/Tokyo' | +09:00 | +09:00 |
| 'Australia/Sydney' | +10:00 | +11:00 |
| 'Europe/London' | +00:00 | +01:00 |
| 'Europe/Zurich' | +01:00 | +02:00 |
Datetime arrays with no specified TimeZone cannot be compared or combined with arrays that have theirTimeZone property set to a specific time zone.
Data Types: char | string
Categorical Variable Options
Expected categories, specified as a cell array of character vectors or string array containing a list of category names.
Names in the input fields must match one of the names specified in theCategories property to avoid a conversion error.
Example: varOpts.Categories = {'BareLand','Forest','Water','Roads','Buildings'};
Category protection indicator, specified as a logical true orfalse. The categories of ordinal categorical arrays are always protected. If the Ordinal property is set to true, then the default value for Protected is true. Otherwise, the value for Protected is false. For more information on categorical arrays, see the categorical function reference page.
Mathematical ordering indicator, specified as either false, true, 0, or 1. For more information on categorical arrays, see the categorical function reference page.
Duration Variable Options
InputFormat — Format of input text
character vector | string scalar
Format of the input text representing duration data, specified as a character vector or string array.
Specify InputFormat as any of the following formats, where dd, hh,mm, and ss represent days, hours, minutes, and seconds, respectively:
'dd:hh:mm:ss''hh:mm:ss''mm:ss''hh:mm'- Any of the first three formats, with up to nine
Scharacters to indicate fractional second digits, such as'hh:mm:ss.SSSS'
Example: varOpts.InputFormat = 'dd:hh:mm:ss'
Data Types: char | string
DurationFormat — Display format for duration data
character vector | string scalar
Display format for duration data, specified as a character vector or string scalar.
For numbers with time units, specify one of these values:
'y'— Fixed-length years, where 1 year equals 365.2425 days'd'— Fixed-length days, where 1 day equals 24 hours'h'— Hours'm'— Minutes's'— Seconds
For the digital timer, specify one of these formats:
'dd:hh:mm:ss''hh:mm:ss''mm:ss''hh:mm'- Any of the first three formats, with up to nine
Scharacters to indicate fractional second digits, such as'hh:mm:ss.SSSS'
Example: DurationFormat can be either a single number with time units (such as 0.5 yr) or a digital timer (such as 10:30:15 for 10 hours, 30 minutes, and 15 seconds).
Data Types: char | string
DecimalSeparator — Characters separating fractional seconds
. (default) | character vector | string scalar
Characters separating fractional seconds, specified as a character vector or string scalar. The importing function uses theDecimalSeparator property to distinguish the integer part of the duration value from the fractional seconds part.
Data Types: char | string
FieldSeparator — Characters indicating field separation
: (default) | character vector | string scalar
Characters indicating field separation in the duration data, specified as a character vector or string scalar.
Data Types: char | string
Version History
Introduced in R2016b