rlContinuousGaussianRewardFunction - Stochastic Gaussian reward function approximator object for neural network-based
environment - MATLAB ([original](https://www.mathworks.com/help/reinforcement-learning/ref/rl.function.rlcontinuousgaussianrewardfunction.html)) ([raw](?raw))Stochastic Gaussian reward function approximator object for neural network-based environment
Since R2022a
Description
When creating a neural network-based environment using rlNeuralNetworkEnvironment, you can specify the reward function approximator using an rlContinuousDeterministicRewardFunction object. Do so when you do not know a ground-truth reward signal for your environment and you expect the reward signal to be stochastic.
The reward function object uses a deep neural network as internal approximation model to predict the reward signal for the environment given one of the following input combinations.
- Observations, actions, and next observations
- Observations and actions
- Actions and next observations
- Next observations
To specify a deterministic reward function approximator, use an rlContinuousDeterministicRewardFunction object.
Creation
Syntax
Description
`rwdFcnAppx` = rlContinuousGaussianRewardFunction([net](#mw%5Fab5cba26-3b3e-42e7-944b-2acd6b734165),`observationInfo`,`actionInfo`,[Name=Value](#namevaluepairarguments)) creates a stochastic reward function using the deep neural networknet and sets the ObservationInfo andActionInfo properties.
When creating a reward function you must specify the names of the deep neural network inputs using one of the following combinations of name-value pair arguments.
- ObservationInputNames, ActionInputNames, and NextObservationInputNames
ObservationInputNamesandActionInputNamesActionInputNamesandNextObservationInputNamesNextObservationInputNames
You must also specify the names of the deep neural network outputs using theRewardMeanOutputName andRewardStandardDeviationOutputName name-value pair arguments.
You can also specify the UseDevice property using an optional name-value pair argument. For example, to use a GPU for prediction, specifyUseDevice="gpu".
Input Arguments
net — Deep neural network
dlnetwork object
Deep neural network with a scalar output value, specified as adlnetwork object.
The input layer names for this network must match the input names specified using the ObservationInputNames, ActionInputNames, and NextObservationInputNames. The dimensions of the input layers must match the dimensions of the corresponding observation and action specifications in ObservationInfo and ActionInfo, respectively.
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Example: ObservationInputNames="velocity"
ObservationInputNames — Observation input layer names
string | string array
Observation input layer names, specified as a string or string array. SpecifyObservationInputNames when you expect the reward signal to depend on the current environment observation.
The number of observation input names must match the length ofObservationInfo and the order of the names must match the order of the specifications in ObservationInfo.
ActionInputNames — Action input layer names
string | string array
Action input layer names, specified as a string or string array. SpecifyActionInputNames when you expect the reward signal to depend on the current action value.
The number of action input names must match the length ofActionInfo and the order of the names must match the order of the specifications in ActionInfo.
NextObservationInputNames — Next observation input layer names
string | string array
Next observation input layer names, specified as a string or string array. Specify NextObservationInputNames when you expect the reward signal to depend on the next environment observation.
The number of next observation input names must match the length ofObservationInfo and the order of the names must match the order of the specifications in ObservationInfo.
RewardMeanOutputName — Reward mean output layer name
string
Reward mean output layer name, specified as a string.
RewardStandardDeviationOutputName — Reward standard deviation output layer name
string
Reward standard deviation output layer name, specified as a string.
Properties
ObservationInfo — Observation specifications
rlNumericSpec object | array of rlNumericSpec objects
Observation specifications, specified as an rlNumericSpec object or an array of such objects. Each element in the array defines the properties of an environment observation channel, such as its dimensions, data type, and name.
When you create the approximator object, the constructor function sets theObservationInfo property to the input argumentobservationInfo.
You can extract observationInfo from an existing environment, function approximator, or agent using getObservationInfo. You can also construct the specifications manually using rlNumericSpec.
Example: [rlNumericSpec([2 1]) rlNumericSpec([1 1])]
ActionInfo — Action specifications
rlFiniteSetSpec object | rlNumericSpec object
Action specifications, specified either as an rlFiniteSetSpec (for discrete action spaces) or rlNumericSpec (for continuous action spaces) object. This object defines the properties of the environment action channel, such as its dimensions, data type, and name.
Note
For this approximator object, only one action channel is allowed.
When you create the approximator object, the constructor function sets theActionInfo property to the input argumentactionInfo.
You can extract ActionInfo from an existing environment or agent using getActionInfo. You can also construct the specifications manually usingrlFiniteSetSpec or rlNumericSpec.
Example: rlNumericSpec([2 1])
Normalization — Normalization method
"none" (default) | string array
Normalization method, returned as an array in which each element (one for each input channel defined in the observationInfo andactionInfo properties, in that order) is one of the following values:
"none"— Do not normalize the input."rescale-zero-one"— Normalize the input by rescaling it to the interval between 0 and 1. The normalized input Y is (_U_–Min)./(UpperLimit–LowerLimit), where U is the nonnormalized input. Note that nonnormalized input values lower thanLowerLimitresult in normalized values lower than 0. Similarly, nonnormalized input values higher thanUpperLimitresult in normalized values higher than 1. Here,UpperLimitandLowerLimitare the corresponding properties defined in the specification object of the input channel."rescale-symmetric"— Normalize the input by rescaling it to the interval between –1 and 1. The normalized input Y is 2(_U_–LowerLimit)./(UpperLimit–LowerLimit) – 1, where U is the nonnormalized input. Note that nonnormalized input values lower thanLowerLimitresult in normalized values lower than –1. Similarly, nonnormalized input values higher thanUpperLimitresult in normalized values higher than 1. Here,UpperLimitandLowerLimitare the corresponding properties defined in the specification object of the input channel.
Note
When you specify the Normalization property ofrlAgentInitializationOptions, normalization is applied only to the approximator input channels corresponding to rlNumericSpec specification objects in which both theUpperLimit and LowerLimit properties are defined. After you create the agent, you can use setNormalizer to assign normalizers that use any normalization method. For more information on normalizer objects, see rlNormalizer.
Example: "rescale-symmetric"
UseDevice — Computation device used for training and simulation
"cpu" (default) | "gpu"
Computation device used to perform operations such as gradient computation, parameter update and prediction during training and simulation, specified as either"cpu" or "gpu".
The "gpu" option requires both Parallel Computing Toolbox™ software and a CUDA® enabled NVIDIA® GPU. For more information on supported GPUs see GPU Computing Requirements (Parallel Computing Toolbox).
You can use gpuDevice (Parallel Computing Toolbox) to query or select a local GPU device to be used with MATLAB®.
Note
Training or simulating an agent on a GPU involves device-specific numerical round-off errors. Because of these errors, you can get different results on a GPU and on a CPU for the same operation.
To speed up training by using parallel processing over multiple cores, you do not need to use this argument. Instead, when training your agent, use an rlTrainingOptions object in which the UseParallel option is set to true. For more information about training using multicore processors and GPUs for training, see Train Agents Using Parallel Computing and GPUs.
Example: "gpu"
Learnables — Learnable parameters of approximator object
cell array of dlarray objects
Learnable parameters of the approximator object, specified as a cell array ofdlarray objects. This property contains the learnable parameters of the approximation model used by the approximator object.
Example: {dlarray(rand(256,4)),dlarray(rand(256,1))}
State — State of approximator object
cell array of dlarray objects
State of the approximator object, specified as a cell array ofdlarray objects. For dlnetwork-based models, this property contains the Value column of theState property table of the dlnetwork model. The elements of the cell array are the state of the recurrent neural network used in the approximator (if any), as well as the state for the batch normalization layer (if used).
For model types that are not based on a dlnetwork object, this property is an empty cell array, since these model types do not support states.
Example: {dlarray(rand(256,1)),dlarray(rand(256,1))}
Object Functions
Examples
Create Stochastic Reward Function and Predict Reward
Create an environment interface and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec.
env = rlPredefinedEnv("CartPole-Continuous"); obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
Create a deep neural network. The network has two input channels, one for the current action and one for the next observations. The single output channel is for the predicted reward value.
% Define paths. statePath = featureInputLayer(obsInfo.Dimension(1),Name="obs"); actionPath = featureInputLayer(actInfo.Dimension(1),Name="action"); nextStatePath = featureInputLayer(obsInfo.Dimension(1),Name="nextObs"); commonPath = [ concatenationLayer(1,3,Name="concat") fullyConnectedLayer(32,Name="fc") reluLayer(Name="relu1") fullyConnectedLayer(32,Name="fc2") ]; meanPath = [ reluLayer(Name="rewardMeanRelu") fullyConnectedLayer(1,Name="rewardMean") ]; stdPath = [ reluLayer(Name="rewardStdRelu") fullyConnectedLayer(1,Name="rewardStdFc") softplusLayer(Name="rewardStd") ];
% Create dlnetwork object and add layers. rwdNet = dlnetwork(); rwdNet = addLayers(rwdNet,statePath); rwdNet = addLayers(rwdNet,actionPath); rwdNet = addLayers(rwdNet,nextStatePath); rwdNet = addLayers(rwdNet,commonPath); rwdNet = addLayers(rwdNet,meanPath); rwdNet = addLayers(rwdNet,stdPath);
% Connect layers. rwdNet = connectLayers(rwdNet,"nextObs","concat/in1"); rwdNet = connectLayers(rwdNet,"action","concat/in2"); rwdNet = connectLayers(rwdNet,"obs","concat/in3"); rwdNet = connectLayers(rwdNet,"fc2","rewardMeanRelu"); rwdNet = connectLayers(rwdNet,"fc2","rewardStdRelu");
% Plot network. plot(rwdNet)
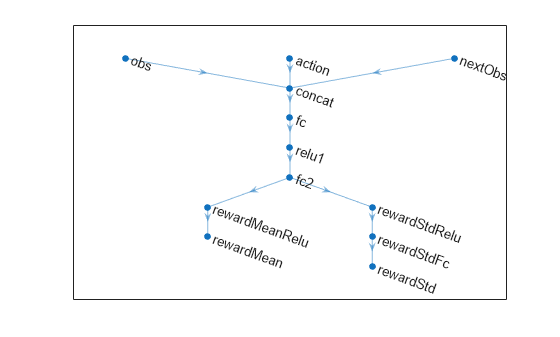
Initialize network and display the number of weights.
rwdNet = initialize(rwdNet); summary(rwdNet)
Initialized: true
Number of learnables: 1.4k
Inputs: 1 'obs' 4 features 2 'action' 1 features 3 'nextObs' 4 features
Create a stochastic reward function object.
rwdFncAppx = rlContinuousGaussianRewardFunction(... rwdNet,obsInfo,actInfo,... ObservationInputNames="obs",... ActionInputNames="action", ... NextObservationInputNames="nextObs", ... RewardMeanOutputNames="rewardMean", ... RewardStandardDeviationOutputNames="rewardStd");
Using this reward function object, you can predict the next reward value based on the current action and next observation. For example, predict the reward for a random action and next observation. The reward value is sampled from a Gaussian distribution with the mean and standard deviation output by the reward network.
obs = rand(obsInfo.Dimension); act = rand(actInfo.Dimension); nextObs = rand(obsInfo.Dimension(1),1); predRwd = predict(rwdFncAppx,{obs},{act},{nextObs})
You can obtain the mean value and standard deviation of the Gaussian distribution for the predicted reward using evaluate.
predRwdDist = evaluate(rwdFncAppx,{obs,act,nextObs})
predRwdDist=1×2 cell array {[-0.0995]} {[0.6195]}
Version History
Introduced in R2022a
See Also
Functions
Objects
- rlNeuralNetworkEnvironment | rlContinuousDeterministicTransitionFunction | rlContinuousGaussianTransitionFunction | rlIsDoneFunction | rlMBPOAgent | rlMBPOAgentOptions