GitHub - wolfgarbe/symspell_rs: SymSpell: 1 million times faster spelling correction & fuzzy search through Symmetric Delete spelling correction algorithm (original) (raw)
Rust implementation of SymSpell originally written in C#.
Spelling correction & Fuzzy search: 1 million times faster through Symmetric Delete spelling correction algorithm
The Symmetric Delete spelling correction algorithm reduces the complexity of edit candidate generation and dictionary lookup for a given Damerau-Levenshtein distance. It is six orders of magnitude faster (than the standard approach with deletes + transposes + replaces + inserts) and language independent.
Opposite to other algorithms only deletes are required, no transposes + replaces + inserts. Transposes + replaces + inserts of the input term are transformed into deletes of the dictionary term. Replaces and inserts are expensive and language dependent: e.g. Chinese has 70,000 Unicode Han characters!
The speed comes from the inexpensive delete-only edit candidate generation and the pre-calculation.
An average 5 letter word has about 3 million possible spelling errors within a maximum edit distance of 3,
but SymSpell needs to generate only 25 deletes to cover them all, both at pre-calculation and at lookup time. Magic!
If you like SymSpell, try SeekStorm - a sub-millisecond full-text search library & multi-tenancy server in Rust (Open Source).
Copyright (c) 2025 Wolf Garbe
Version: 6.7.3
Author: Wolf Garbe <wolf.garbe@seekstorm.com>
Maintainer: Wolf Garbe <wolf.garbe@seekstorm.com>
URL: https://github.com/wolfgarbe/symspell
Description: https://seekstorm.com/blog/1000x-spelling-correction/
MIT License
Copyright (c) 2025 Wolf Garbe
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated
documentation files (the "Software"), to deal in the Software without restriction, including without limitation
the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software,
and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
https://opensource.org/licenses/MIT
Single word spelling correction
Lookup provides a very fast spelling correction of single words.
- A Verbosity parameter allows to control the number of returned results:
Top: Top suggestion with the highest term frequency of the suggestions of smallest edit distance found.
Closest: All suggestions of smallest edit distance found, suggestions ordered by term frequency.
All: All suggestions within maxEditDistance, suggestions ordered by edit distance, then by term frequency. - The Maximum edit distance parameter controls up to which edit distance words from the dictionary should be treated as suggestions.
- The required Word frequency dictionary can either be directly loaded from text files (LoadDictionary) or generated from a large text corpus (CreateDictionary).
Applications
- Spelling correction,
- Query correction (10–15% of queries contain misspelled terms),
- Chatbots,
- OCR post-processing,
- Automated proofreading.
- Fuzzy search & approximate string matching
Performance (single term)
0.033 milliseconds/word (edit distance 2) and 0.180 milliseconds/word (edit distance 3) (single core on 2012 Macbook Pro)
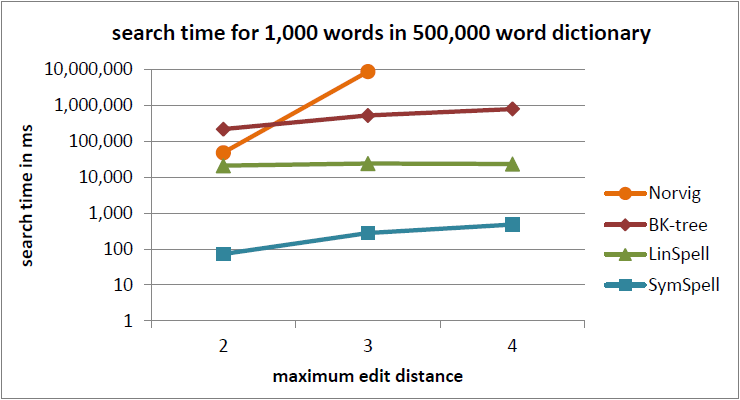
1,870 times faster than BK-tree (see Benchmark 1: dictionary size=500,000, maximum edit distance=3, query terms with random edit distance = 0...maximum edit distance, verbose=0)
1 million times faster than Norvig's algorithm (see Benchmark 2: dictionary size=29,157, maximum edit distance=3, query terms with fixed edit distance = maximum edit distance, verbose=0)
Blog Posts: Algorithm, Benchmarks, Applications
1000x Faster Spelling Correction algorithm
Fast approximate string matching with large edit distances in Big Data
Very fast Data cleaning of product names, company names & street names
Sub-millisecond compound aware automatic spelling correction
SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking
Fast Word Segmentation for noisy text
The Pruning Radix Trie — a Radix trie on steroids
Compound aware multi-word spelling correction
LookupCompound supports compound aware automatic spelling correction of multi-word input strings.
1. Compound splitting & decompounding
Lookup() assumes every input string as single term. LookupCompound also supports compound splitting / decompounding with three cases:
- mistakenly inserted space within a correct word led to two incorrect terms
- mistakenly omitted space between two correct words led to one incorrect combined term
- multiple input terms with/without spelling errors
Splitting errors, concatenation errors, substitution errors, transposition errors, deletion errors and insertion errors can by mixed within the same word.
2. Automatic spelling correction
- Large document collections make manual correction infeasible and require unsupervised, fully-automatic spelling correction.
- In conventional spelling correction of a single token, the user is presented with multiple spelling correction suggestions.
For automatic spelling correction of long multi-word text the algorithm itself has to make an educated choice.
Examples:
- whereis th elove hehad dated forImuch of thepast who couqdn'tread in sixthgrade and ins pired him
- where is the love he had dated for much of the past who couldn't read in sixth grade and inspired him (9 edits)
- in te dhird qarter oflast jear he hadlearned ofca sekretplan
- in the third quarter of last year he had learned of a secret plan (9 edits)
- the bigjest playrs in te strogsommer film slatew ith plety of funn
- the biggest players in the strong summer film slate with plenty of fun (9 edits)
- Can yu readthis messa ge despite thehorible sppelingmsitakes
- can you read this message despite the horrible spelling mistakes (9 edits)
Performance (compounds)
0.2 milliseconds / word (edit distance 2) 5000 words / second (single core on 2012 Macbook Pro)
Word Segmentation of noisy text
WordSegmentation divides a string into words by inserting missing spaces at appropriate positions.
- Misspelled words are corrected and do not prevent segmentation.
- Existing spaces are allowed and considered for optimum segmentation.
- SymSpell.WordSegmentation uses a Triangular Matrix approach instead of the conventional Dynamic Programming: It uses an array instead of a dictionary for memoization, loops instead of recursion and incrementally optimizes prefix strings instead of remainder strings.
- The Triangular Matrix approach is faster than the Dynamic Programming approach. It has a lower memory consumption, better scaling (constant O(1) memory consumption vs. linear O(n)) and is GC friendly.
- While each string of length n can be segmented into 2^n−1 possible compositions,
SymSpell.WordSegmentation has a linear runtime O(n) to find the optimum composition.
Examples:
- thequickbrownfoxjumpsoverthelazydog
- the quick brown fox jumps over the lazy dog
- itwasabrightcolddayinaprilandtheclockswerestrikingthirteen
- it was a bright cold day in april and the clocks were striking thirteen
- itwasthebestoftimesitwastheworstoftimesitwastheageofwisdomitwastheageoffoolishness
- it was the best of times it was the worst of times it was the age of wisdom it was the age of foolishness
Applications:
- Word Segmentation for CJK languages for Indexing Spelling correction, Machine translation, Language understanding, Sentiment analysis
- Normalizing English compound nouns for search & indexing (e.g. ice box = ice-box = icebox; pig sty = pig-sty = pigsty)
- Word segmentation for compounds if both original word and split word parts should be indexed.
- Correction of missing spaces caused by Typing errors.
- Correction of Conversion errors: spaces between word may get lost e.g. when removing line breaks.
- Correction of OCR errors: inferior quality of original documents or handwritten text may prevent that all spaces are recognized.
- Correction of Transmission errors: during the transmission over noisy channels spaces can get lost or spelling errors introduced.
- Keyword extraction from URL addresses, domain names, #hashtags, table column descriptions or programming variables written without spaces.
- For password analysis, the extraction of terms from passwords can be required.
- For Speech recognition, if spaces between words are not properly recognized in spoken language.
- Automatic CamelCasing of programming variables.
- Applications beyond Natural Language processing, e.g. segmenting DNA sequence into words
Performance:
4 milliseconds for segmenting an 185 char string into 53 words (single core on 2012 Macbook Pro)
Usage of SymSpell Library
Single word spelling correction
use symspell_rs::{SymSpell, Verbosity}; use std::path::Path;
let max_edit_distance_dictionary = 2; //maximum edit distance per dictionary precalculation let mut symspell: SymSpell = SymSpell::new(max_edit_distance_dictionary,None, 7, 1);
// single term dictionary let term_index = 0; //column of the term in the dictionary text file let count_index = 1; //column of the term frequency in the dictionary text file symspell.load_dictionary(Path::new("data/frequency_dictionary_en_82_765.txt"), term_index, count_index, " ");
//lookup suggestions for single-word input strings let input_term = "hous"; let suggestion_verbosity = Verbosity::Closest;//Top, Closest, All let max_edit_distance_lookup = 1; //max edit distance per lookup (maxEditDistanceLookup<=maxEditDistanceDictionary) let suggestions = symspell.lookup(input_term, suggestion_verbosity, max_edit_distance_lookup,&None,None,false); //display suggestions, edit distance and term frequency println!("{:?}", suggestions);
Compound aware multi-word spelling correction
use symspell_rs::{SymSpell, Verbosity}; use std::path::Path;
let max_edit_distance_dictionary = 2; let mut symspell = SymSpell::new(max_edit_distance_dictionary,None, 7, 1);
// single term dictionary let term_index = 0; //column of the term in the dictionary text file let count_index = 1; //column of the term frequency in the dictionary text file symspell.load_dictionary(Path::new("data/frequency_dictionary_en_82_765.txt"), term_index, count_index, " "); // bigram dictionary symspell.load_bigram_dictionary(Path::new("data/frequency_bigramdictionary_en_243_342.txt"),0,2, " ", );
//lookup suggestions for multi-word input strings (supports compound splitting & merging) let input_sentence = "whereis th elove hehad dated forImuch of thepast who couqdn'tread in sixtgrade and ins pired him"; let max_edit_distance_lookup = 2; //max edit distance per lookup (per single word, not per whole input string) let compound_suggestions = symspell.lookup_compound(input_sentence, max_edit_distance_lookup,&None,false); //display suggestions, edit distance and term frequency println!("{:?}", compound_suggestions);
Word Segmentation of noisy text
use symspell_rs::{SymSpell, Verbosity}; use std::path::Path;
let max_edit_distance_dictionary = 0; //maximum edit distance per dictionary precalculation let mut symspell = SymSpell::new(max_edit_distance_dictionary,None, 7, 1);
// single term dictionary let term_index = 0; //column of the term in the dictionary text file let count_index = 1; //column of the term frequency in the dictionary text file symspell.load_dictionary(Path::new("data/frequency_dictionary_en_82_765.txt"), term_index, count_index, " ");
//word segmentation and correction for multi-word input strings with/without spaces let input_sentence = "thequickbrownfoxjumpsoverthelazydog"; let max_edit_distance_lookup = 0; let result = symspell.word_segmentation(input_sentence, max_edit_distance_lookup); //display term and edit distance println!("{:?}", result.segmented_string);
Word Segmentation of Chinese text
use symspell_rs::{SymSpell, Verbosity}; use std::path::Path;
let max_edit_distance_dictionary = 0; //maximum edit distance per dictionary precalculation let mut symspell = SymSpell::new(max_edit_distance_dictionary,None, 7, 1);
// single term dictionary let term_index = 0; //column of the term in the dictionary text file let count_index = 1; //column of the term frequency in the dictionary text file symspell.load_dictionary(Path::new("data/frequency_dictionary_zh_cn_349_045.txt"), term_index, count_index, " ");
//word segmentation and correction for multi-word input strings with/without spaces let input_sentence = "部分居民生活水平"; let max_edit_distance_lookup = 0; let result = symspell.word_segmentation(input_sentence, max_edit_distance_lookup); //display term and edit distance println!("{:?}", result.segmented_string);
Frequency dictionary
Dictionary quality is paramount for correction quality. In order to achieve this two data sources were combined by intersection: Google Books Ngram data which provides representative word frequencies (but contains many entries with spelling errors) and SCOWL — Spell Checker Oriented Word Lists which ensures genuine English vocabulary (but contained no word frequencies required for ranking of suggestions within the same edit distance).
The frequency_dictionary_en_82_765.txt was created by intersecting the two lists mentioned below. By reciprocally filtering only those words which appear in both lists are used. Additional filters were applied and the resulting list truncated to ≈ 80,000 most frequent words.
- Google Books Ngram data (License) : Provides representative word frequencies
- SCOWL - Spell Checker Oriented Word Lists (License) : Ensures genuine English vocabulary
Dictionary file format
- Plain text file in UTF-8 encoding - without Byte Order Mark (BOM)!.
- Word and Word Frequency are separated by space or tab. Per default, the word is expected in the first column and the frequency in the second column. But with the termIndex and countIndex parameters in LoadDictionary() the position and order of the values can be changed and selected from a row with more than two values. This allows to augment the dictionary with additional information or to adapt to existing dictionaries without reformatting.
- Every word-frequency-pair in a separate line. A line is defined as a sequence of characters followed by a line feed ("\n"), a carriage return ("\r"), or a carriage return immediately followed by a line feed ("\r\n").
- Both dictionary terms and input term are expected to be in lower case.
You can build your own frequency dictionary for your language or your specialized technical domain. The SymSpell spelling correction algorithm supports languages with non-latin characters, e.g Cyrillic, Chinese or Georgian.
Frequency dictionaries in other languages
SymSpell includes an English frequency dictionary
Dictionaries for Chinese, English, French, German, Hebrew, Italian, Russian and Spanish are located here:
SymSpell.FrequencyDictionary
Frequency dictionaries in many other languages can be found here:
FrequencyWords repository
Frequency dictionaries
Frequency dictionaries
N-Gram Generator by repetitio:
This repository contains a script to generate unigrams and bigrams from Wikipedias dataset from HuggingFace for the use with the SymSpell.
https://gitlab.com/repetitio/utils/ngram-frequencies/-/tree/main?ref_type=heads
Official implementations
C#
https://github.com/wolfgarbe/symspell
NuGet package
https://www.nuget.org/packages/symspell
Rust
https://github.com/wolfgarbe/symspell_rs
Crates.io
https://crates.io/crates/symspell_rs
Ports
The following third party ports or reimplementations to other programming languages have not been tested by myself whether they are an exact port, error free, provide identical results or are as fast as the original algorithm.
Older ports target SymSpell version 3.0. But version 6.1. provides much higher speed & lower memory consumption!
WebAssembly
https://github.com/justinwilaby/spellchecker-wasm
WEB API (Docker)
https://github.com/LeonErath/SymSpellAPI (Version 6.3)
C
https://github.com/sumanpokhrel-11/symspell-c99
C++
https://github.com/AtheS21/SymspellCPP (Version 6.5)
https://github.com/erhanbaris/SymSpellPlusPlus (Version 6.1)
C#
https://github.com/wolfgarbe/symspell
Crystal
https://github.com/chenkovsky/aha/blob/master/src/aha/sym_spell.cr
Go
https://github.com/snapp-incubator/go-symspell
https://github.com/sajari/fuzzy
https://github.com/eskriett/spell
https://github.com/Trendyol/go-symspell
Haskell
https://github.com/cbeav/symspell
Java
https://github.com/MighTguY/customized-symspell (Version 6.6)
https://github.com/rxp90/jsymspell (Version 6.6)
https://github.com/Lundez/JavaSymSpell (Version 6.4)
https://github.com/rxp90/jsymspell
https://github.com/gpranav88/symspell
https://github.com/searchhub/preDict
https://github.com/jpsingarayar/SpellBlaze
Javascript
https://github.com/MathieuLoutre/node-symspell (Version 6.6, needs Node.js)
https://github.com/itslenny/SymSpell.js
https://github.com/dongyuwei/SymSpell
https://github.com/IceCreamYou/SymSpell
https://github.com/Yomguithereal/mnemonist/blob/master/symspell.js
Julia
https://github.com/Arkoniak/SymSpell.jl
Kotlin
https://github.com/Wavesonics/SymSpellKt
Objective-C
https://github.com/AmitBhavsarIphone/SymSpell (Version 6.3)
PHP
https://github.com/Jakhotiya/symspell-php
Python
https://github.com/mammothb/symspellpy (Version 6.7)
https://github.com/viig99/SymSpellCppPy (Version 6.5)
https://github.com/zoho-labs/symspell (Python bindings of Rust version)
https://github.com/ne3x7/pysymspell/ (Version 6.1)
https://github.com/Ayyuriss/SymSpell
https://github.com/ppgmg/github_public/blob/master/spell/symspell_python.py
https://github.com/rcourivaud/symspellcompound
https://github.com/Esukhia/sympound-python
https://www.kaggle.com/yk1598/symspell-spell-corrector
Ruby
https://github.com/PhilT/symspell
https://github.com/scientist-labs/spellkit
Rust
https://github.com/wolfgarbe/symspell_rs (Version 6.7.3)
https://github.com/reneklacan/symspell (Version 6.6, compiles to WebAssembly)
https://github.com/luketpeterson/fuzzy_rocks (persistent datastore backed by RocksDB)
https://github.com/daibo83/fast_symspell
https://github.com/Saphereye/symspellrs
Scala
https://github.com/semkath/symspell
Swift
https://github.com/gdetari/SymSpellSwift
Zig
https://github.com/alim-zanibekov/miara?tab=readme-ov-file#symspell
Citations
Contextual Multilingual Spellchecker for User Queries
Sanat Sharma, Josep Valls-Vargas, Tracy Holloway King, Francois Guerin, Chirag Arora (Adobe)
https://arxiv.org/abs/2305.01082
A context sensitive real-time Spell Checker with language adaptability
Prabhakar Gupta (Amazon)
https://arxiv.org/abs/1910.11242
SpeakGer: A meta-data enriched speech corpus of German state and federal parliaments
Kai-Robin Lange and Carsten Jentsch
https://arxiv.org/pdf/2410.17886
An Extended Sequence Tagging Vocabulary for Grammatical Error Correction
Stuart Mesham, Christopher Bryant, Marek Rei, Zheng Yuan
https://arxiv.org/abs/2302.05913
German Parliamentary Corpus (GERPARCOR)
Giuseppe Abrami, Mevlüt Bagci, Leon Hammerla, Alexander Mehler
https://arxiv.org/abs/2204.10422
iOCR: Informed Optical Character Recognition for Election Ballot Tallies
Kenneth U. Oyibo, Jean D. Louis, Juan E. Gilbert
https://arxiv.org/abs/2208.00865
Amazigh spell checker using Damerau-Levenshtein algorithm and N-gram
Youness Chaabi, Fadoua Ataa Allah
https://www.sciencedirect.com/science/article/pii/S1319157821001828
Survey of Query correction for Thai business-oriented information retrieval
Phongsathorn Kittiworapanya, Nuttapong Saelek, Anuruth Lertpiya, Tawunrat Chalothorn
https://ieeexplore.ieee.org/document/9376809
SymSpell and LSTM based Spell- Checkers for Tamil
Selvakumar MuruganTamil Arasan BakthavatchalamTamil Arasan BakthavatchalamMalaikannan Sankarasubbu
https://www.researchgate.net/publication/349924975_SymSpell_and_LSTM_based_Spell-_Checkers_for_Tamil
SymSpell4Burmese: Symmetric Delete Spelling Correction Algorithm (SymSpell) for Burmese Spelling Checking
Ei Phyu Phyu Mon; Ye Kyaw Thu; Than Than Yu; Aye Wai Oo
https://ieeexplore.ieee.org/document/9678171
Spell Check Indonesia menggunakan Norvig dan SymSpell
Yasir Abdur Rohman
https://medium.com/@yasirabd/spell-check-indonesia-menggunakan-norvig-dan-symspell-4fa583d62c24
Analisis Perbandingan Metode Burkhard Keller Tree dan SymSpell dalam Spell Correction Bahasa Indonesia
Muhammad Hafizh Ferdiansyah, I Kadek Dwi Nuryana
https://ejournal.unesa.ac.id/index.php/jinacs/article/download/50989/41739
Improving Document Retrieval with Spelling Correction for Weak and Fabricated Indonesian-Translated Hadith
Muhammad zaky ramadhanKemas M LhaksmanaKemas M Lhaksmana
https://www.researchgate.net/publication/342390145_Improving_Document_Retrieval_with_Spelling_Correction_for_Weak_and_Fabricated_Indonesian-Translated_Hadith
Symspell을 이용한 한글 맞춤법 교정
김희규
https://heegyukim.medium.com/symspell%EC%9D%84-%EC%9D%B4%EC%9A%A9%ED%95%9C-%ED%95%9C%EA%B8%80-%EB%A7%9E%EC%B6%A4%EB%B2%95-%EA%B5%90%EC%A0%95-3def9ca00805
Mending Fractured Texts. A heuristic procedure for correcting OCR data
Jens Bjerring-Hansen, Ross Deans Kristensen-McLachla2, Philip Diderichsen and Dorte Haltrup Hansen
https://ceur-ws.org/Vol-3232/paper14.pdf
Towards the Natural Language Processing as Spelling Correction for Offline Handwritten Text Recognition Systems
Arthur Flor de Sousa Neto; Byron Leite Dantas Bezerra; and Alejandro Héctor Toselli
https://www.mdpi.com/2076-3417/10/21/7711
When to Use OCR Post-correction for Named Entity Recognition?
Vinh-Nam Huynh, Ahmed Hamdi, Antoine Doucet
https://hal.science/hal-03034484v1/
Automatic error Correction: Evaluating Performance of Spell Checker Tools
A. Tolegenova
https://journals.sdu.edu.kz/index.php/nts/article/view/690
ZHAW-CAI: Ensemble Method for Swiss German Speech to Standard German Text
Malgorzata Anna Ulasik, Manuela Hurlimann, Bogumila Dubel, Yves Kaufmann,
Silas Rudolf, Jan Deriu, Katsiaryna Mlynchyk, Hans-Peter Hutter, and Mark Cieliebak
https://ceur-ws.org/Vol-2957/sg_paper3.pdf
Cyrillic Word Error Program Based on Machine Learning
Battumur, K., Dulamragchaa, U., Enkhbat, S., Altanhuyag, L., & Tumurbaatar, P.
https://mongoliajol.info/index.php/JIMDT/article/view/2661
Fast Approximate String Search for Wikification
Szymon Olewniczak, Julian Szymanski
https://www.iccs-meeting.org/archive/iccs2021/papers/127440334.pdf
RuMedSpellchecker: Correcting Spelling Errors for Natural Russian Language in Electronic Health Records Using Machine Learning Techniques
Dmitrii Pogrebnoi, Anastasia Funkner, Sergey Kovalchuk
https://link.springer.com/chapter/10.1007/978-3-031-36024-4_16
An Extended Sequence Tagging Vocabulary for Grammatical Error Correction
Stuart Mesham, Christopher Bryant, Marek Rei, Zheng Yuan
https://aclanthology.org/2023.findings-eacl.119.pdf
Lightning-fast adaptive immune receptor similarity search by symmetric deletion lookup
Touchchai Chotisorayuth, Andreas Tiffeau-Mayer
https://arxiv.org/html/2403.09010v1
Unveiling Disguised Toxicity: A Novel Pre-processing Module for Enhanced Content Moderation
Johnny Chan, Yuming Li
https://www.sciencedirect.com/science/article/pii/S2215016124001225
Beyond the dictionary attack: Enhancing password cracking efficiency through machine learning-induced mangling rules
Radek Hranický, Lucia Šírová, Viktor Rucký
https://www.sciencedirect.com/science/article/pii/S2666281725000046
Upcoming changes
- Utilizing the pigeonhole principle by partitioning both query and dictionary terms will result in 5x less memory consumption and 3x faster precalculation time.
- Option to preserve case (upper/lower case) of input term.
- Open source the code for creating custom frequency dictionaries in any language and size as intersection between Google Books Ngram data (Provides representative word frequencies) and SCOWL Spell Checker Oriented Word Lists (Ensures genuine English vocabulary).
SymSpell is contributed by SeekStorm - the high performance Search as a Service & search API