Cluster Analysis (original) (raw)
Last Updated : 8 Apr, 2026
Cluster analysis (clustering) groups similar data points so that items within the same cluster are more alike than those in different clusters. It is widely used in e-commerce for customer segmentation to enable personalized recommendations and improved user experiences.
**Cluster analysis is useful for:
- Scalability depends on the algorithm, some methods like k-means scale well, while others (e.g., hierarchical clustering) do not.
- Works effectively with high-dimensional data.
- Supports numerical data as well as categorical data.
- Most clustering algorithms are sensitive to noise and require preprocessing; missing data must be handled before clustering.
- Produces results that are easy to interpret and apply in real world scenarios.
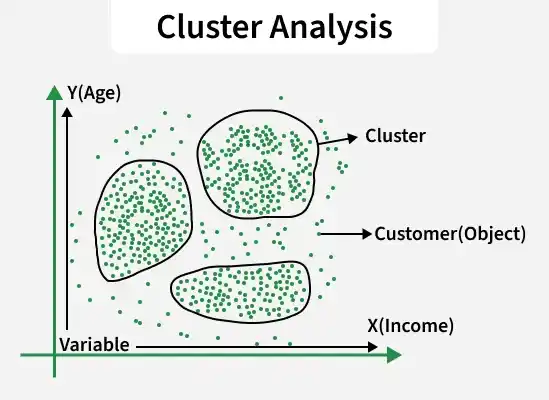
Cluster Analysis
Distance Metrics in Cluster Analysis
Distance metrics are simple mathematical formulas to figure out how similar or different two data points are. Type of distance metrics we choose plays a big role in deciding clustering results. Some of the common metrics are:
- **Euclidean Distance****:** It is the most widely used distance metric and finds the straight-line distance between two points.
- **Manhattan Distance****:** It measures the distance between two points based on grid-like path. It adds the absolute differences between the values.
- **Cosine Similarity: This method checks the angle between two points instead of looking at the distance. It’s used in text data to see how similar two documents are.
- **Jaccard Index: A statistical tool used for comparing the similarity of sample sets. It’s mostly used for yes/no type data or categories.
Types of Clustering Techniques
Clustering can be broadly classified into several methods. The choice of method depends on the type of data and the problem you're solving.
1. Partitioning Methods
- Partitioning Methods divide the data into k groups (clusters) where each data point belongs to only one group. These methods are used when you already know how many clusters you want to create. A common example is K-means clustering.
- K-means clustering assigns each data point to the nearest center and repeatedly updates the centers as the mean of assigned points until they stabilize.
2. Hierarchical Methods
Hierarchical clustering builds a tree-like structure of clusters known as a dendrogram that represents the merging or splitting of clusters. It can be divided into:
- **Agglomerative Approach (Bottom-up): Agglomerative Approach starts with individual points and merges similar ones. Like a family tree where relatives are grouped step by step.
- **Divisive Approach (Top-down): It starts with one big cluster and splits it repeatedly into smaller clusters. For example, classifying animals into broad categories like mammals, reptiles, etc and further refining them.
3. Density-Based Methods
- Density-based clustering group data points that are densely packed together and treat regions with fewer data points as noise or outliers. This method is particularly useful when clusters are irregular in shape.
- For example, it can be used in fraud detection as it identifies unusual patterns of activity by grouping similar behaviors together.
4. Grid-Based Methods
- Grid-Based Methods divide data space into grids making clustering efficient. This makes the clustering process faster because it reduces the complexity by limiting the number of calculations needed and is useful for large datasets.
- Climate researchers often use grid-based methods to analyze temperature variations across different geographical regions. By dividing the area into grids they can more easily identify temperature patterns and trends.
5. Model-Based Methods
- Model-based clustering groups data by assuming it comes from a mix of distributions. Gaussian Mixture Models (GMM) are commonly used and assume the data is formed by several overlapping normal distributions.
- GMM is commonly used in voice recognition systems as it helps to distinguish different speakers by modeling each speaker’s voice as a Gaussian distribution.
6. Constraint-Based Methods
- It uses User-defined constraints to guide the clustering process. These constraints may specify certain relationships between data points such as which points should or should not be in the same cluster.
- In healthcare, clustering groups patients based on genetic similarities while also incorporating lifestyle factors to create more accurate and meaningful clusters.
Impact of Data on Clustering Techniques
Clustering methods must be chosen and adapted based on the type of data being analyzed as different data types require different similarity measures and algorithms.
1. Numerical Data
Numerical data consists of measurable values such as age, income or temperature. Distance-based algorithms like k-means, DBSCAN and hierarchical clustering work well because they rely on numerical distance calculations.
For example a fitness app can cluster users using average daily steps and heart rate to identify fitness levels.
2. Categorical Data
Categorical data includes non-numerical attributes such as gender, product categories or survey responses. Algorithms like k-modes or hierarchical clustering with appropriate similarity measures are more suitable.
For example customers can be grouped based on preferred shopping categories such as electronics, fashion or home appliances.
3. Mixed Data
Mixed data contains both numerical and categorical features which require specialized or hybrid approaches. Algorithms such as k-prototypes or distance measures like Gower distance are commonly used.
For example, clustering customers based on income (numerical) and shopping preferences (categorical) can be effectively handled using the k-prototypes method.
Applications
- **Market Segmentation: Groups customers based on behavior to enable targeted marketing
- **Image Segmentation: In computer vision it can be used to group pixels in an image to detect objects like faces, cars or animals.
- **Biological Classification: Clusters genes or proteins to study diseases
- **Document Classification: It is used by search engines to categorize web pages for better search results.
- **Anomaly Detection: Cluster Analysis is used for outlier detection to identify rare data points that do not belong to any cluster.
Limitations
- **Choosing the Number of Clusters: Methods like K-means requires user to specify the number of clusters before starting which can be difficult to guess correctly.
- **Scalability: Some algorithms like hierarchical clustering does not scale well with large datasets.
- **Cluster Shape: Many algorithms assume clusters are round or evenly shaped which doesn’t always match real-world data.
- **Handling Noise and Outliers: They are sensitive to noise and outliers which can affect the results.