Dirichlet Process Mixture Models (DPMMs) (original) (raw)
Last Updated : 16 Apr, 2026
Dirichlet Process Mixture Models (DPMMs) is a flexible clustering method that can automatically decide the number of clusters based on the data. Unlike traditional methods like K-means which require you to specify the number of clusters. It offers a probabilistic and nonparametric approach to clustering which allows the model to figure out number of groups on its own based complexity of the data.
Concepts in DPMMs
To understand DPMMs it's important to understand two key concepts:
1. Beta Distribution
The Beta distribution models probabilities for two possible outcomes such as success or failure. It is defined by two parameters α and β that shape the distribution. The probability density function (PDF) is given by:
f(x,\alpha,\beta) = \frac{x^{\alpha-1}(1-x)^{\beta-1}}{\Beta(\alpha,\beta)}
Where B(α, β) is the beta function.
2. Dirichlet Distribution
The Dirichlet distribution is a generalization of the Beta distribution for multiple outcomes. It represents the probabilities of different categories like rolling a dice with unknown probabilities for each side. The PDF of the Dirichlet distribution is:
f(p,\alpha) = \frac{1}{B(\alpha)}\Pi_{i=1}^{k}p_i^{\alpha_i -1}
**Where:
- p = (p1, p2, …, pk) are the probabilities of K categories
- Each pi ≥ 0 and ∑ pi = 1
- α = (α1, α2, …, αk) are positive shape values
- B(α) is the beta function
Effect of α
- Higher α -> probabilities near the mean
- Equal α -> symmetric shape
- Different α -> skewed shape
Dirichlet Process (DP)
A Dirichlet Process is a stochastic process that generates probability distributions over infinite categories. It enables clustering without specifying the number of clusters in advance. The Dirichlet Process is defined as:
DP(α,G_0 )
**Where:
- **α: Concentration parameter controlling cluster diversity.
- **G₀: Base distribution representing the prior belief about cluster parameters.
Stick-Breaking Process
The stick-breaking process is a method to generate probabilities from a Dirichlet Process. The concept is shown in the image below:

Stick-Breaking Process
**Steps
- Start with a stick of length 1.
- Break the first piece using Beta(1, α) -> this is p1.
- Break the next piece from the remaining stick -> gives p2.
- Keep repeating to get p3, p4 and so on. The pieces will add up close to 1.
Mathematically this can be expressed as
p1 = β(1,α)
p2 = β(1, α) ∗(1 - p1)
p3 = β(1, α) ∗(1 - p1 -p2)
For each categories sample we also sample μ from our base distribution. This becomes our cluster parameters.
How DPMMs Work
DPMM is an extension of Gaussian Mixture Models where the number of clusters is not fixed. It uses the Dirichlet Process as a prior for the mixture components.
Steps in the Process
**1. Initialize: Assign random clusters to data points.
**2. Iterate for Each Data Point:
- Pick one point.
- Keep all other assignments fixed.
- Compute the probability of placing this point in: an existing cluster or a new cluster.
**3. Update: Assign the point to whichever option has the higher probability.
**4. Repeat: Continue until the cluster assignments stop changing.
Assignment Probabilities
1. Assigning to an existing cluster k
P(\text{existing cluster } k)=\frac{n_k}{n-1+\alpha} \Nu (\mu,1)
2. Assigning to a new cluster
P(\text{new cluster})=\frac{\alpha}{n-1+\alpha}\Nu(0,1)
Where:
- nk: Number of points in cluster k.
- α: Concentration parameter.
- N(μ, σ): Gaussian distribution.
DPMM is an extension of Gaussian Mixture Models where the number of clusters is not fixed. It uses the Dirichlet Process as a prior for the mixture components.
Implementing Dirichlet Process Mixture Models using Sklearn
Now let us implement DPMM process in scikit learn and we'll use the Mall Customers Segmentation Data. Let's understand this step-by-step:
**Step 1: Import Libraries and Load Dataset
In this step we will import all the necessary libraries. This dataset contains customer information, including age, income and spending score. You can download the dataset from here.
Python `
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.mixture import BayesianGaussianMixture from sklearn.decomposition import PCA
data = pd.read_csv('/content/Mall_Customers (1).csv') print(data.head())
`
**Output:
Dataset
**Step 2: Feature Selection
In this step we select features that are likely to influence customer clusters.
Python `
X = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']].values
`
**Step 3: Dimensionality Reduction
We will use PCA algorithm to reduces the data's dimensions to 2 for easy visualization.
Python `
pca = PCA(n_components=2) X_pca = pca.fit_transform(X)
`
**Step 4: Fit Bayesian Gaussian Mixture Model
The model can automatically deactivate unnecessary components up to a specified maximum number of clusters (n_components).
Python `
dpmm = BayesianGaussianMixture(
n_components=10,
covariance_type='full',
weight_concentration_prior_type='dirichlet_process',
weight_concentration_prior=1e-2,
random_state=42
)
dpmm.fit(X) labels = dpmm.predict(X)
`
**Step 5: Visualization
Clusters are visualized with different colors making patterns easier to interpret.
Python `
plt.figure(figsize=(8, 6)) plt.scatter(X_pca[:, 0], X_pca[:, 1], c=labels, cmap=plt.cm.Paired, edgecolors='k', s=100, linewidth=1.5) plt.title('Dirichlet Process Mixture Model Clustering') plt.xlabel('PCA Component 1') plt.ylabel('PCA Component 2') plt.grid(True) plt.show()
`
**Output:
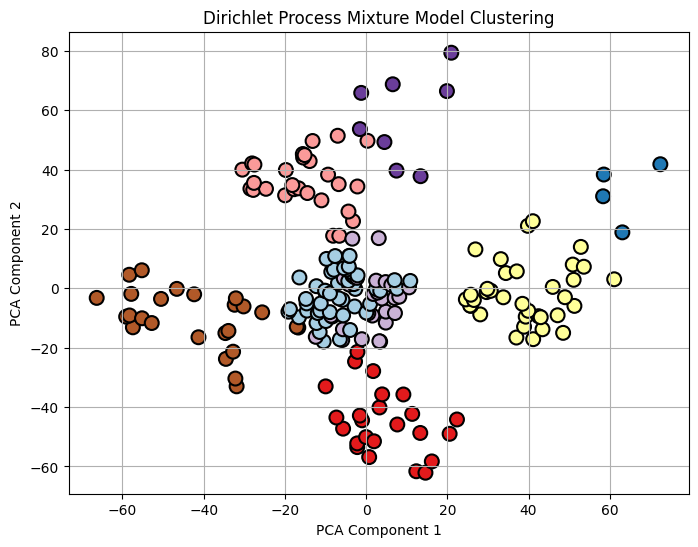
DPMM
The clustering of mall customers using DPMM highlights distinct groups where average customers in the center and extreme spenders on the edges. Overlapping clusters suggest some customers share similar behaviors.
You can download the complete code from here.
Advantages over Traditional Methods
- One of the primary advantage of DPMMs is their ability to automatically determine the number of clusters in the data. Traditional methods often require the pre-specification of the number of clusters like in k-means which can be challenging in real-world applications.
- It operate within a probabilistic framework allowing for the quantification of uncertainty. Traditional methods often provide "hard" assignments of data points to clusters while DPMMs give probabilistic cluster assignments capturing the uncertainty inherent in the data.
- DPMMs find applications in a wide range of fields including natural language processing, computer vision, bioinformatics and finance. Their flexibility makes them applicable to diverse datasets and problem domains.
Applications of DPMMs
- **Customer Segmentation: Group customers without fixing the number of clusters.
- **Topic Modeling: Detect topics in text when the number of topics is unknown.
- **Image Segmentation: Divide images into regions, useful in medical and object tasks.
- **Speaker Clustering: Identify different speakers in audio data.
- **Bioinformatics: Cluster genes, proteins or cells with unknown structure.