Tree Based Machine Learning Algorithms (original) (raw)
Last Updated : 2 May, 2026
Tree based algorithms are important in machine learning as they mimic human decision making using a structured approach. They build models as decision trees, where data is split step by step based on features until a final prediction is made.

Tree based algorithms
Key components include:
- **Internal Nodes: Represent decisions based on features
- **Branches: Show the outcome of each decision
- **Leaf Nodes: Provide the final prediction
- **Feature Selection: Chooses the best feature at each step
- **Easy to Understand: Transparent and widely used in real world applications
Working of Tree based Algorithms
- **Feature Splitting: Select the most informative feature using criteria like Gini or Entropy.
- **Recursive Partitioning: Split the dataset into subsets and repeat the process.
- **Stopping Criteria: Stop splitting when maximum depth or minimum samples are reached.
- **Prediction: Assign class (classification) or average value (regression) at leaf nodes.
1. Decision Tree
A Decision Tree is the core of tree based algorithms, creating a structured flow by splitting data into smaller subsets using mathematical rules. Advanced models like Random Forest and Gradient Boosting are built on this foundation. The structural elements include:
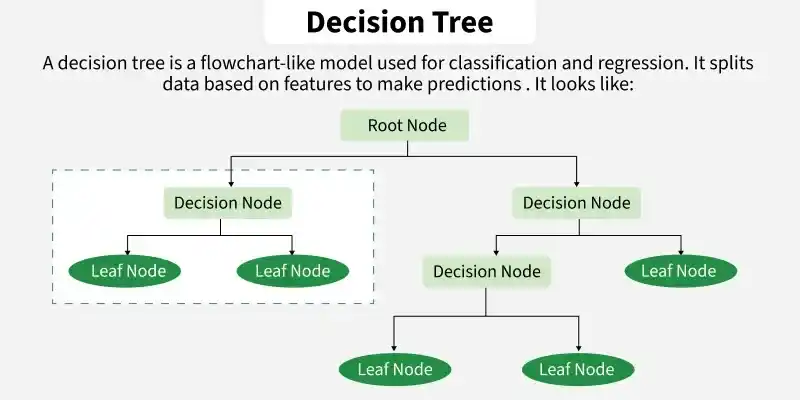
Decision Tree
- Starting point of the tree. It contains the full dataset before any split.
- A feature based rule (e.g., Age > 30?) that splits data into smaller groups.
- Final node that gives the prediction class label (classification) or average value (regression).
- Mathematical rule used to choose the best feature for splitting.
Decision Tree Implementation
Here we implement Decision tree using sklearn. We can also switch between Gini and Entropy using the criterion parameter.
- Loads the Breast Cancer dataset using load_breast_cancer() to get features (X) and labels (y).
- Creates a DecisionTreeClassifier using Gini impurity, with max_depth=2 for simplicity and random_state=42 for consistent results.
- Trains the model using clf.fit(X, y).
- Visualizes the learned decision rules using tree.plot_tree(..., filled=True) with color-coded nodes. Python `
from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn import tree import matplotlib.pyplot as plt
data = load_breast_cancer() X, y = data.data, data.target
clf = DecisionTreeClassifier(criterion='gini', random_state=42,max_depth=2)
clf.fit(X, y)
plt.figure(figsize=(12,8)) tree.plot_tree(clf, feature_names=data.feature_names, filled=True) plt.show()
`
**Output:
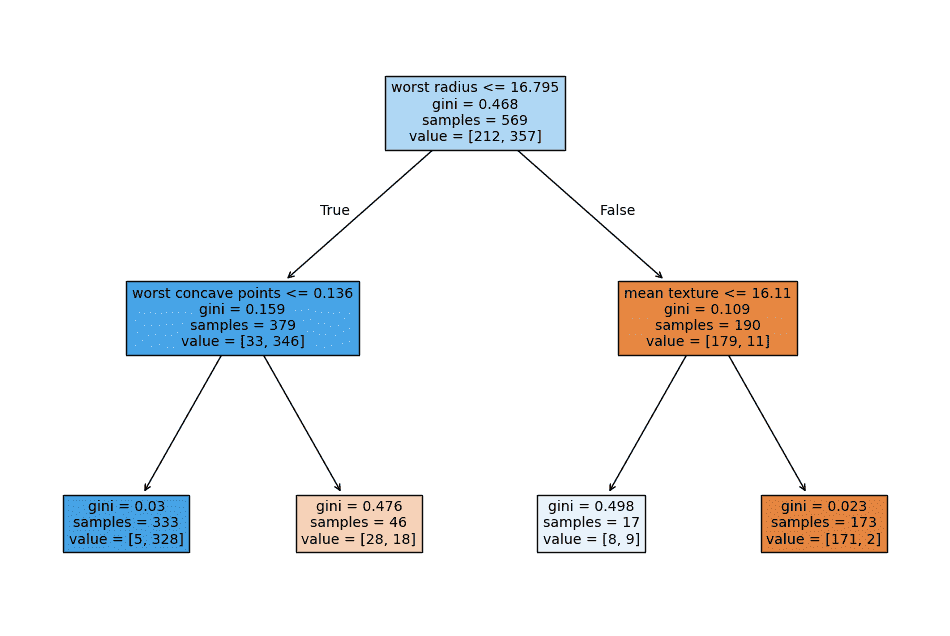
Decision Tree
- **Each Node Info: Shows split rule, Gini value, number of samples, and class distribution [class0, class1]
- **Initial Split: Tree first splits based on worst radius
- **Further Splits: Data is divided step by step into smaller subsets
- **Gini Value: Lower Gini in leaf nodes indicates more confident predictions
- **Model Depth: With max_depth = 2, the tree is small and easy to interpret
2. Random Forest
Random Forest is an Ensemble Learning Technique that builds multiple decision trees and combines their outputs to give more stable and accurate predictions.
- Reduces overfitting by using multiple trees
- Improves accuracy via combined predictions
- Handles large and noisy data effectively
- Adds randomness to improve generalization
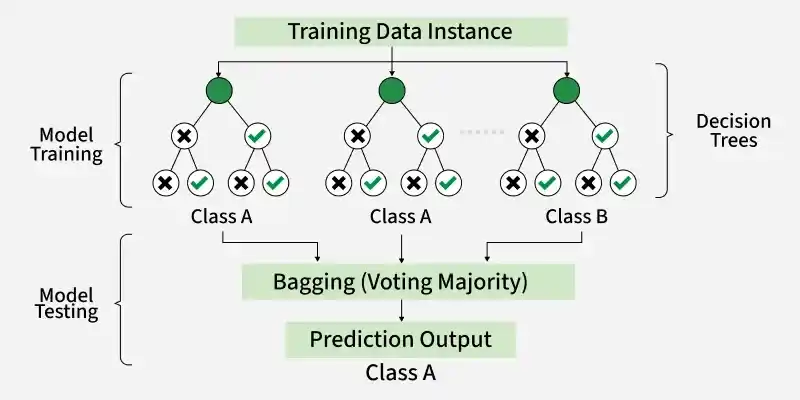
Random Forest
Random Forest Implementation
This code trains a Random Forest Classifier on the Breast Cancer dataset and evaluates its performance.
**1. RandomForestClassifier(n_estimators=100, random_state=42):
- Builds 100 decision trees.
- random_state=42 ensures reproducible results.
**2. rf.fit(X_train, y_train): trains the model on training data.
**3. rf.predict(X_test): generates predictions on test data.
**4. accuracy_score(...): calculates how many predictions were correct.
Python `
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
predictions = rf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.96
3. Gradient Boosting
In Gradient Boosting trees are built one after another, and each new tree learns from the errors of previous trees. It improves the model step by step using gradient descent.
- Uses weak learners like small, shallow trees
- Each tree corrects errors from previous ones
- Learns gradually with a learning rate
- High accuracy but requires tuning to prevent overfitting
Gradient Boosting Implementation
- **n_estimators: number of boosting stages (more trees = more learning).
- **learning_rate: controls how much each tree contributes.
- **max_depth: controls complexity of individual trees. Python `
from sklearn.ensemble import GradientBoostingClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 )
gb = GradientBoostingClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42
)
gb.fit(X_train, y_train)
predictions = gb.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.956
4. XGBoost
XGBoost (Extreme Gradient Boosting) is an optimized version of gradient boosting that focuses on speed, scalability and high performance. It enhances traditional boosting by adding system-level optimizations and regularization.
- Uses both L1 and L2 regularization to reduce overfitting.
- Supports parallel processing, making it faster than traditional Gradient Boosting.
- Handles missing values automatically.
- Includes built in tree pruning to control model complexity.
- Widely used in real world applications and ML competitions due to strong accuracy.
XGBoost Implementation
- XGBClassifier(n_estimators=100, learning_rate=0.1).
- Builds 100 boosted trees with learning rate 0.1.
- random_state=42 ensures reproducibility.
- model.fit(X_train, y_train) trains the model. Python `
from xgboost import XGBClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 )
model = XGBClassifier( n_estimators=100, learning_rate=0.1, random_state=42, use_label_encoder=False, eval_metric='logloss' )
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.956
5. AdaBoost
AdaBoost (Adaptive Boosting) combines multiple weak learners into a strong model by focusing more on difficult samples at each step. It adjusts data weights instead of correcting errors like Gradient Boosting.
- All samples start with equal weights
- Misclassified samples receive higher weights
- Uses weak learners like decision stumps (depth = 1 trees)
- Models are weighted based on accuracy
- Final prediction via weighted voting (classification) or weighted sum (regression)
- Sensitive to noisy data and outliers
AdaBoost Implementation
- AdaBoostClassifier(n_estimators=100, learning_rate=1.0)
- Builds 100 weak learners sequentially.
- fit() trains model. Python `
from sklearn.ensemble import AdaBoostClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 )
model = AdaBoostClassifier( n_estimators=100, learning_rate=1.0, random_state=42 )
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.973
6. LightGBM
LightGBM (Light Gradient Boosting Machine) is a high performance boosting framework built to handle large scale and high dimensional data efficiently. It improves traditional Gradient Boosting by optimizing both speed and memory usage.
- Uses histogram based learning, which groups continuous feature values into bins to significantly speed up training.
- Grows trees leaf wise (best first) instead of level wise, allowing it to reduce loss more effectively and often achieve higher accuracy.
- Designed for low memory consumption, making it suitable for large datasets.
- Supports parallel and GPU learning for faster computation.
- Performs exceptionally well when dealing with large datasets and many features.
- Because of aggressive leaf wise growth, it may overfit if parameters like max_depth or num_leaves are not properly tuned.
LightGBM Implementation
- **LGBMClassifier(n_estimators=100, learning_rate=0.1): Efficient gradient boosting with fast training.
- **fit(): training.
- **predict(): predictions. Python `
from lightgbm import LGBMClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 )
model = LGBMClassifier( n_estimators=100, learning_rate=0.1, random_state=42 )
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.964
7. CatBoost
CatBoost (Categorical Boosting) is a Gradient Boosting algorithm designed to efficiently handle datasets with categorical features. It reduces the need for complex preprocessing while maintaining strong predictive performance.
- Automatically processes categorical variables without requiring manual encoding like one hot encoding.
- Uses ordered boosting, which helps reduce prediction shift and target leakage during training.
- Implements efficient encoding techniques that improve stability and accuracy.
- Requires minimal hyperparameter tuning compared to other boosting algorithms.
- Works especially well on structured and tabular data common in business and real world applications.
- Provides consistent performance even with complex categorical relationships.
CatBoost Implementation
- **CatBoostClassifier(iterations=100, learning_rate=0.1): Handles categorical features efficiently.
- **fit(): Training.
- **predict(): Predictions. Python `
from catboost import CatBoostClassifier from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
data = load_breast_cancer() X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 )
model = CatBoostClassifier( iterations=100, learning_rate=0.1, random_state=42, verbose=0 )
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
`
**Output:
Accuracy: 0.964
Advantages
- Simple and practical for real-world problems.
- Step-by-step structure makes them easy to interpret.
- Suitable for both classification and regression tasks.
- Automatically identifies important features and non-linear patterns.
- Transparent decision-making builds trust and aids analysis.
**Limitations
- Prone to overfitting if trees grow too deep.
- Sensitive to small changes in data, causing instability.
- Ensemble methods increase complexity and reduce interpretability.