Data Partitioning Techniques in System Design (original) (raw)
Last Updated : 22 May, 2026
The process of splitting a dataset into more manageable, smaller pieces in order to improve efficiency, scalability, and performance is known as data partitioning.
- It can be accomplished by either vertical partitioning, which separates data into columns, or horizontal partitioning, which divides data into rows according to particular criteria.
- This method is especially helpful in databases, big data processing frameworks, and machine learning applications since it enables quicker query execution, simpler management of massive datasets, and better resource use.
**Example: In a sales database, records can be partitioned by year, where one partition stores sales data for 2023 and another for 2024.
Real-World Examples
Some real-world examples of data partitioning are:
- **E-commerce Platforms: Customer data is partitioned by region (e.g., North America, Europe) to optimize shipping, inventory, and localized marketing, improving performance and user experience.
- **Banking and Finance: Transaction data is partitioned by account type or date (e.g., daily) for faster processing, reporting, and more efficient fraud detection.
- **Social Media: User data is split by demographics or interests to enable targeted ads and content, enhancing relevance and system efficiency.
Importance
Data partitioning is essential for several reasons:
- **Performance Improvement: By breaking data into smaller segments, systems can access only the relevant partitions, leading to faster query execution and reduced load times.
- **Scalability: As datasets grow, partitioning allows for easier management and distribution across multiple servers or storage systems, enabling horizontal scaling.
- **Efficient Resource Utilization: It helps optimize the use of resources by allowing systems to focus processing power on specific partitions rather than the entire dataset.
- **Enhanced Manageability: Smaller partitions are easier to back up, restore, and maintain, facilitating better data governance and maintenance practices.
Methods of Data Partitioning
The main methods of Data Partitioning are:
1. Horizontal Partitioning/Sharding
Horizontal Partitioning divides data by rows, but all partitions may still exist on the same server. When these horizontal partitions are placed across multiple servers, the approach is called Sharding.
Sharding is a special case of horizontal partitioning that provides true horizontal scalability and high availability by distributing partitions across multiple machines.
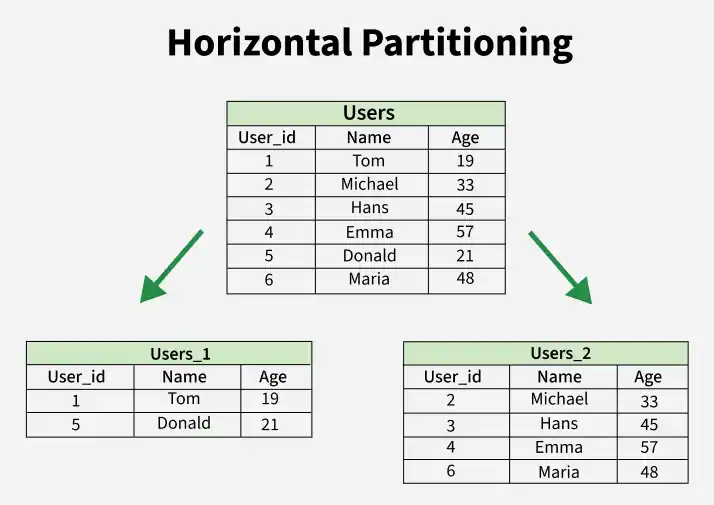
Horizontal Partitioning
Advantages
Horizontal partitioning divides a table into multiple parts by distributing rows across different partitions or servers.
- **Scalability: Allows parallel processing of large datasets across multiple nodes.
- **Load Balancing: Distributes workload evenly, reducing system bottlenecks.
- **Fault Tolerance: Each partition works independently, improving reliability during failures.
Disadvantages
Despite its scalability benefits, it introduces some complexity in database operations.
- **Complex Joins: Joins across multiple partitions can be slower and harder to manage.
- **Data Skew: Uneven data distribution may cause certain partitions to handle more load than others.
2. Vertical Partitioning
Vertical partitioning divides a dataset based on columns (attributes) instead of rows. Each partition contains only a subset of columns for all rows, depending on access patterns. It is useful when different columns are accessed more frequently or independently.
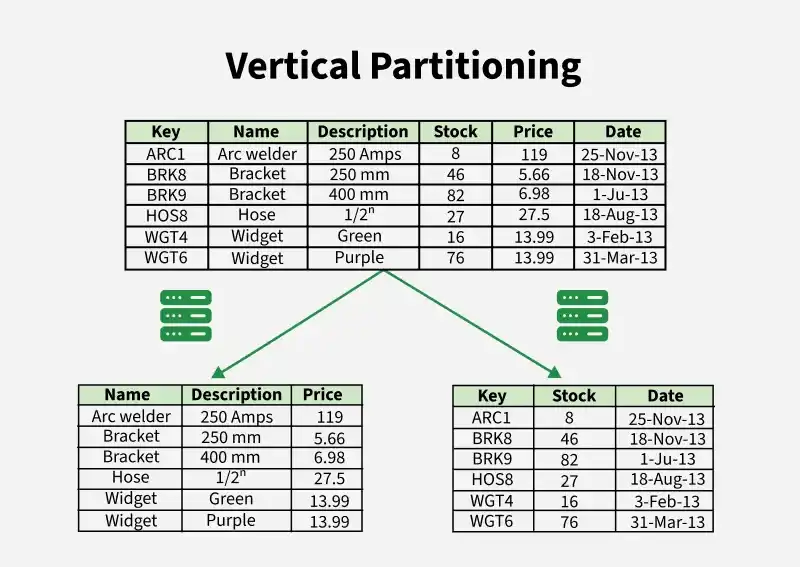
Vertical Partitioning
Advantages
Vertical partitioning divides a table by separating columns into different partitions based on usage or functionality.
- **Better Query Performance: Reduces data read by isolating frequently accessed columns.
- **Efficient Retrieval: Fetches only needed columns, saving I/O and storage.
- **Easier Schema Changes: Simplifies adding or removing columns.
Disadvantages
Although useful for column-level optimization, it can introduce additional query complexity.
- **Query Complexity: Queries may need to access multiple partitions.
- **Slower Joins: Combining data from different partitions adds overhead.
- **Limited Scalability: Not ideal for datasets with rapidly growing columns.
3. Key-based Partitioning
Divides data based on a specific key or attribute, with each partition holding all data related to that key. Common in distributed systems for uniform data distribution and efficient key-based lookups.
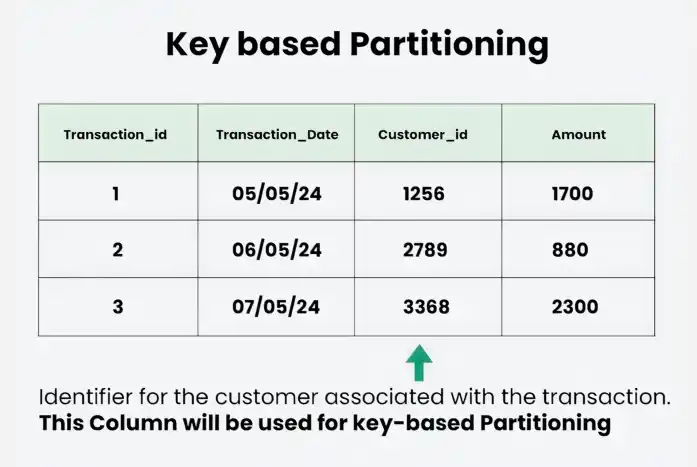
Key Based Partitioning
Advantages
Key-based partitioning distributes data across partitions using a specific key, usually through a hashing mechanism.
- **Even Distribution: Stores data with the same key together for efficient lookups.
- **Scalability: Enables parallel processing across partitions.
- **Load Balancing: Distributes workload to avoid performance bottlenecks.
Disadvantages
Improper key selection can lead to uneven workloads and performance issues.
- **Data Skew: Uneven key access can create hotspots.
- **Limited Flexibility: Less efficient for range or multi-key queries.
- **Partition Overhead: Requires careful management as data or key patterns evolve.
4. Range Partitioning
The dataset is divided using range partitioning based on a preset range of values. For example, if your dataset has timestamps, you can divide it according to a specific time range. Range partitioning might be useful when you have data with natural ordering and wish to distribute it evenly based on the range of values.
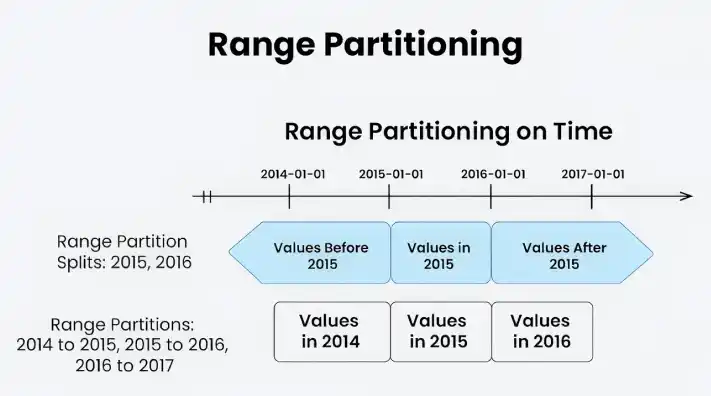
Range Partitioning
Advantages
Range partitioning divides data into partitions based on specific value ranges such as dates, IDs, or numbers.
- **Natural Ordering: Ideal for data with an inherent range-based structure.
- **Efficient Range Queries: Quickly locates data within specified value ranges.
- **Simplified Query Planning: System easily identifies relevant partitions for range conditions.
Disadvantages
Improper range design can lead to uneven data distribution and management challenges.
- **Data Skew: Uneven data across ranges can affect performance.
- **Growth Management: Adding or adjusting ranges requires ongoing maintenance.
- **Complex Joins: Joins and non-contiguous range queries can be slower and harder to manage.
5. Hash-based Partitioning
Hash partitioning uses a hash function to map data into different partitions. The hash value determines which partition the data belongs to, enabling even distribution and faster lookup. It helps with load balancing by spreading data randomly across partitions and improves data retrieval performance by reducing hotspots.
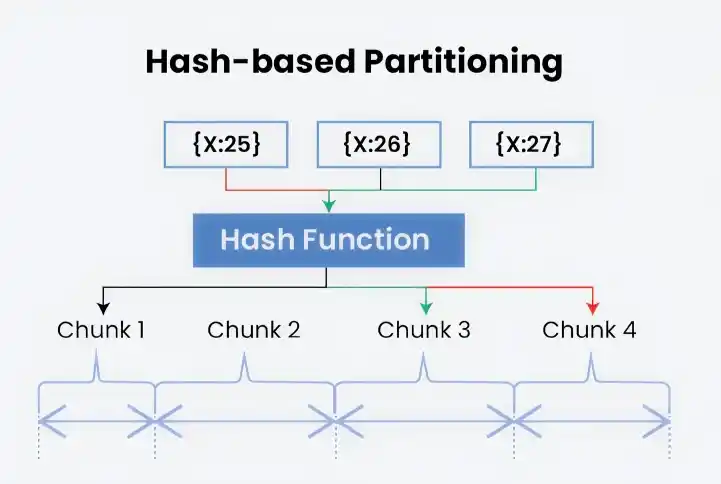
Hash-Based Partitioning
Advantages
Hash-based partitioning distributes data across partitions using a hash function applied to a specific key.
- **Even Distribution: Randomized hashing spreads data uniformly across partitions.
- **Scalability: Supports parallel processing across multiple nodes.
- **Simplicity: Easy to implement and doesn’t rely on data order.
Disadvantages
Although effective for distribution, it can introduce limitations in query flexibility.
- **Inefficient Lookups: Poor performance for key-based or range queries.
- **Possible Imbalances: Hashing may not always ensure perfect load distribution.
- **Maintenance Overhead: Scaling may require repartitioning and rehashing data.
6. Round-Robin Partitioning
Data is cyclically and equally distributed among partitions in round-robin partitioning. Regardless of the properties of the data, each split is sequentially assigned the next accessible data item. Implementing round-robin partitioning is simple and can offer a minimal degree of load balancing.
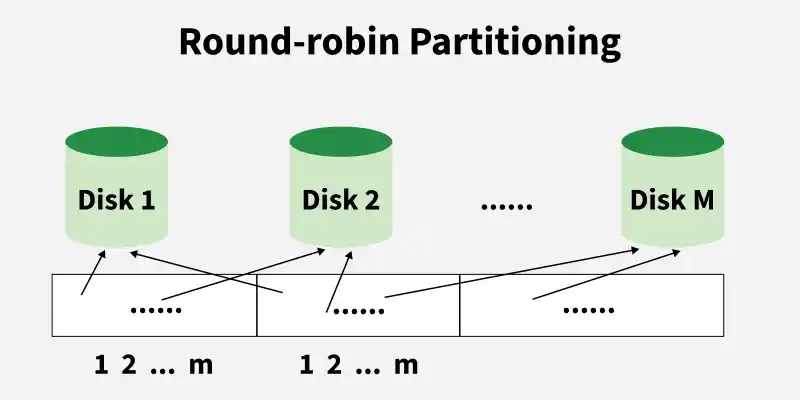
Round Robin Partitioning
Advantages
Round-robin partitioning distributes records sequentially across partitions without using any specific key.
- **Even Data Distribution: Ensures near-uniform distribution of records across partitions.
- **Simple Implementation: Very easy to implement; no hashing or key logic required.
- **Good Load Balancing: Works well for write-heavy workloads and parallel processing.
Disadvantages
Because it does not use a partitioning key, it can make data retrieval less efficient.
- **Inefficient Lookups: Poor performance for key-based or range queries.
- **No Data Locality: Related records may be spread across different partitions.
- **Limited Query Optimization: Not suitable for analytical queries that depend on grouping or ranges.