Database Sharding System Design (original) (raw)
Last Updated : 1 May, 2026
Database sharding is a technique used to scale databases by distributing data across multiple servers. It helps improve performance and handle large datasets efficiently.
- Data is split into smaller parts called shards, each stored on a different database instance to distribute load.
- It reduces pressure on a single database, improving query performance and scalability.
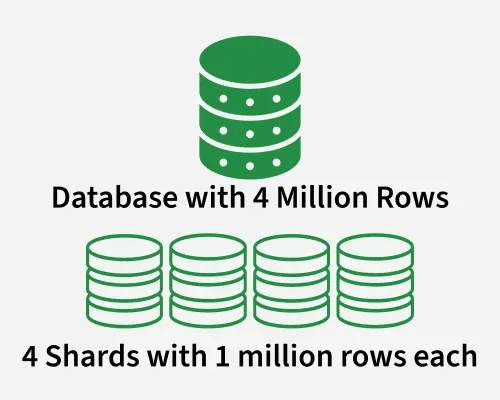
It is basically a database architecture pattern in which we split a large dataset into smaller chunks (logical shards) and we store/distribute these chunks in different machines/database nodes (physical shards).
- Each chunk/partition is known as a "shard" and each shard has the same database schema as the original database.
- We distribute the data in such a way that each row appears in exactly one shard.
- It's a good mechanism to improve the scalability of an application.
Methods of Sharding
Sharding can be done using Range-based, Hash-based, Directory-based, or Geographic-based partitioning to distribute data across multiple servers.
1. Key Based Sharding
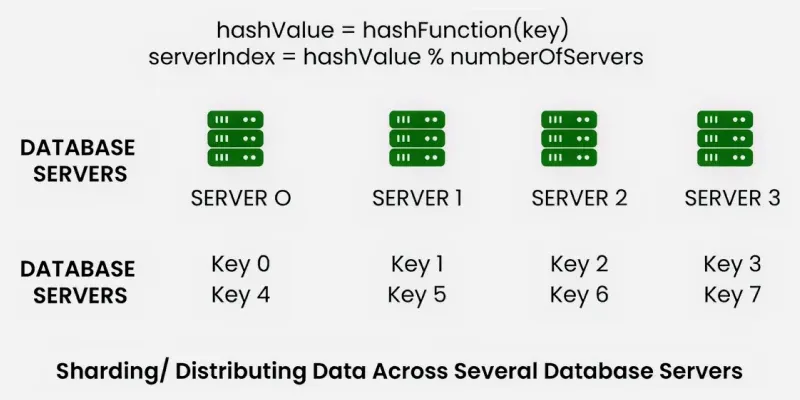
Key Based Sharding is a technique, also known as hash-based sharding. Here, we take the value of an entity such as customer ID, customer email, IP address of a client, zip code, etc and we use this value as an input of the hash function. This process generates a hash value which is used to determine which shard we need to use to store the data.
- We need to keep in mind that the values entered into the hash function should all come from the **same column (shard key) just to ensure that data is placed in the correct order and in a consistent manner.
- Basically, shard keys act like a primary key or a unique identifier for individual rows.
**Example: You have 3 database servers and each request has an application id which is incremented by 1 every time a new application is registered.
To determine which server data should be placed on, we perform a modulo operation on these applications id with the number 3. Then the remainder is used to identify the server to store our data.
Advantages
Key-based sharding helps distribute data across shards using a hashing mechanism.
- **Key Assignment: Assigns each key to a specific shard, ensuring uniform and consistent data distribution.
- **Range Query Optimization: Can be optimized to efficiently handle queries over consecutive key ranges.
Disadvantages
Despite its efficiency, improper shard key selection can cause performance issues.
- **Uneven Data Distribution: Can occur if the sharding key isn’t well-distributed.
- **Scalability Limitation: Scalability may be limited when certain keys receive heavy traffic or data is skewed.
2. Horizontal or Range Based Sharding
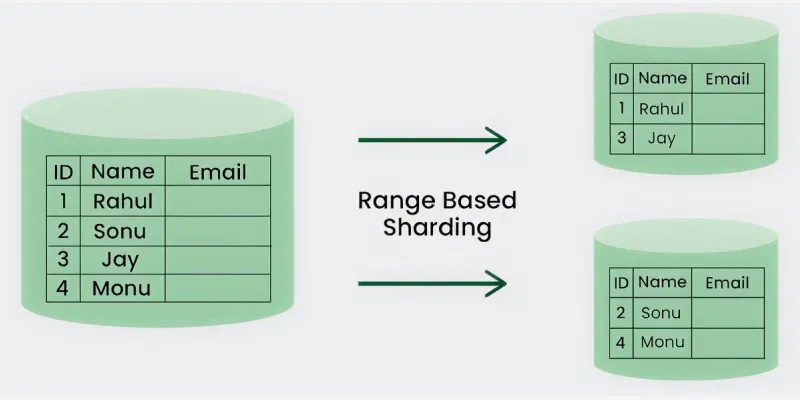
In Horizontal or Range Based Sharding, we divide the data by separating it into different parts based on the range of a specific value within each record. Let's say you have a database of your online customers' names and email information. You can split this information into two shards.
- In one shard you can keep the info of customers whose first name starts with A-P.
- In another shard, keep the information of the rest of the customers.
**Example: In a customer database, one shard may store records where names start with A–P, while another shard stores records where names start with Q–Z.
Advantages
Horizontal or range-based sharding distributes data across multiple shards based on specific value ranges.
- **Scalability: Horizontal or range-based sharding allows for seamless scalability by distributing data across multiple shards, accommodating growing datasets.
- **Improved Performance: Data distribution among shards enhances query performance through parallelization, ensuring faster operations with smaller subsets of data handled by each shard.
Disadvantages
Managing and querying data across multiple shards can introduce additional complexity.
- **Complex Querying Across Shards: Coordinating queries involving multiple shards can be challenging.
- **Uneven Data Distribution: Poorly managed data distribution may lead to uneven workloads among shards.
3. Vertical Sharding
Vertical sharding divides a database by separating columns of a table into different shards or tables. Each shard stores a specific set of columns related to a particular feature or functionality. This helps distribute workload and manage large tables more efficiently.
- Each shard contains a subset of columns while rows remain logically related to the same entity.
- Different features of an entity can be stored on separate machines to improve performance and manageability.
**Example: On Twitter users might have a profile, number of followers, and some tweets posted by his/her own. We can place the user profiles on one shard, followers in the second shard, and tweets on a third shard.
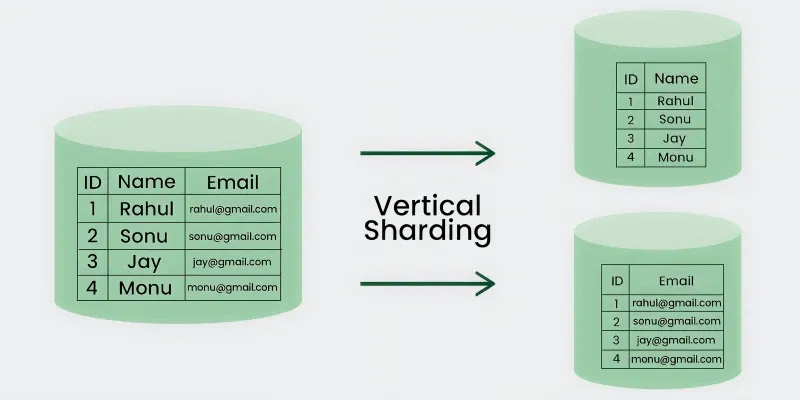
Advantages
Vertical sharding divides a database by separating columns into different shards based on functionality.
- **Query Performance: Vertical sharding can improve query performance by allowing each shard to focus on a specific subset of columns. This specialization enhances the efficiency of queries that involve only a subset of the available columns.
- **Simplified Queries: Queries that require a specific set of columns can be simplified, as they only need to interact with the shard containing the relevant columns.
Disadvantages
Splitting columns across shards can introduce operational and workload challenges.
- **Potential for Hotspots: Certain shards may become hotspots if they contain highly accessed columns, leading to uneven distribution of workloads.
- **Challenges in Schema Changes: Making changes to the schema, such as adding or removing columns, may be more challenging in a vertically sharded system. Changes can impact multiple shards and require careful coordination.
4. Directory-Based Sharding
In Directory-Based Sharding, we create and maintain a lookup service or lookup table for the original database. Basically we use a shard key for lookup table and we do mapping for each entity that exists in the database. This way we keep track of which database shards hold which data.
**Example: A user database may use a lookup table that maps each user ID to the specific shard where that user’s data is stored. When a request is made, the system first checks the lookup table and then routes the query to the correct shard.
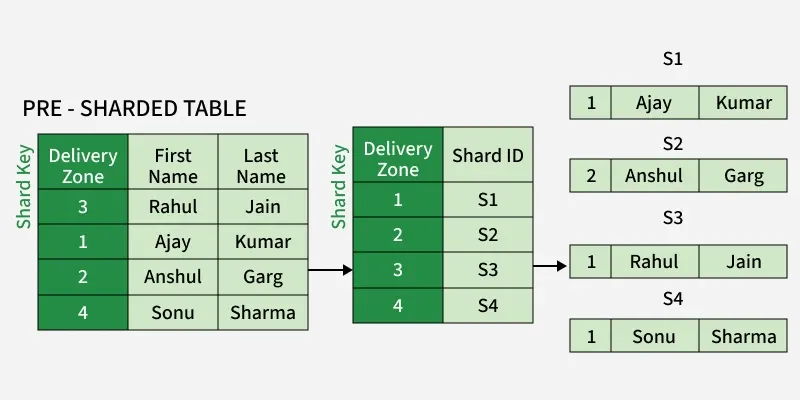
The lookup table holds a static set of information about where specific data can be found.
In the above image, you can see that we have used the delivery zone as a shard key:
- Firstly the client application queries the lookup service to find out the shard (database partition) on which the data is placed.
- When the lookup service returns the shard it queries/updates that shard.
Advantages
Directory-based sharding uses a central lookup service that keeps track of where each piece of data is stored.
- **Flexible Data Distribution: Directory-based sharding allows for flexible data distribution, where the central directory can dynamically manage and update the mapping of data to shard locations.
- **Efficient Query Routing: Queries can be efficiently routed to the appropriate shard using the information stored in the directory. This results in improved query performance.
- **Dynamic Scalability: The system can dynamically scale by adding or removing shards without requiring changes to the application logic.
Disadvantages
While flexible, this approach introduces dependency on the central directory.
- **Centralized Point of Failure: The central directory represents a single point of failure. If the directory becomes unavailable or experiences issues, it can disrupt the entire system, impacting data access and query routing.
- **Increased Latency: Query routing through a central directory introduces an additional layer, potentially leading to increased latency compared to other sharding strategies.
Ways to optimize database sharding for even data distribution
Here are some simple ways to optimize database sharding for even data distribution:
- **Use Consistent Hashing: This helps distribute data more evenly across all shards by using a hashing function that assigns records to different shards based on their key values.
- **Choose a Good Sharding Key: Picking a well-balanced sharding key is crucial. A key that doesn’t create hotspots ensures that data spreads out evenly across all servers.
- **Range-Based Sharding with Caution: If using range-based sharding, make sure the ranges are properly defined so that one shard doesn’t get overloaded with more data than others.
- **Regularly Monitor and Rebalance: Keep an eye on data distribution and rebalance shards when necessary to avoid uneven loads as data grows.
- **Automate Sharding Logic: Implement automation tools or built-in database features that automatically distribute data and handle sharding to maintain balance across shards.
Alternatives to database sharding
Below are some of the alternatives to database sharding:
- **Vertical Scaling: Vertical Scaling means upgrading the same server by adding more CPU, RAM, or storage to handle more load, but it has a fixed hardware limit so it can’t scale forever.
- **Replication: Replication means creating database copies on multiple servers for load balancing and high availability, but replicas may face synchronization issues.
- **Partitioning: Partitioning means splitting data into smaller parts within the same server to improve performance for large datasets without using multiple servers.
- **Caching: Caching means storing frequently used data in Redis/Memcached to reduce database load and speed up responses.
- **CDNs: CDNs mean using a Content Delivery Network for read-heavy data to reduce direct database access and deliver content faster.