carlos (@_carlosejimenez) on X (original) (raw)


i like ai, philosophy, and politics


Can LMs 🤖 replace programmers 🧑💻? - Not yet! Our new benchmark, SWE-bench, tests models on solving real issues from GitHub. Claude 2 & GPT-4 get <5% acc. 🔗 See our leaderboard, paper, code, data: swebench.com🧵
SWE-bench Lite is a smaller & slightly easier *subset* of SWE-bench, with 23 dev / 300 test examples (full SWE-bench is 225 dev / 2,294 test). We hopes this makes SWE-bench evals easier. Special thanks to
@JiayiiGeng
for making this happen. Download here: swebench.com/lite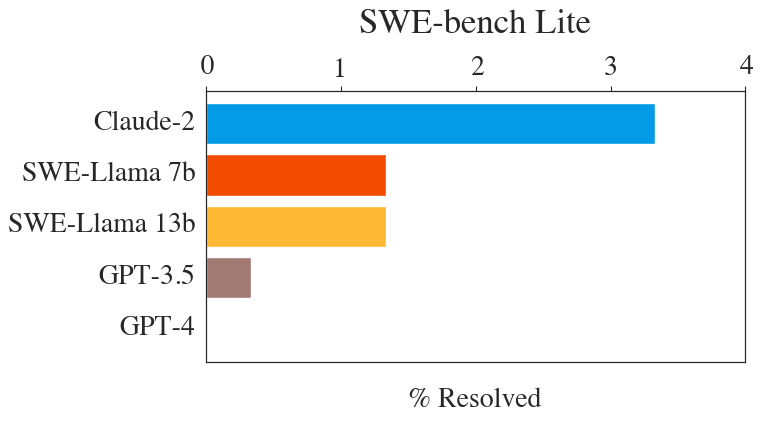
SWE-bench is at ICLR 2024 today! 🇦🇹 Oral presentation @ Halle A 8-9, 3:45 pm CEST Poster session @ Halle B Poster 98, 4:30-6:30 CEST Looking forward to seeing you there!
Can LMs 🤖 replace programmers 🧑💻? - Not yet! Our new benchmark, SWE-bench, tests models on solving real issues from GitHub. Claude 2 & GPT-4 get <5% acc. 🔗 See our leaderboard, paper, code, data: swebench.com🧵
Replying to @_carlosejimenez
We use issues from Django, Matplotlib, scikit-learn and other popular Python projects. The mean repository size is 438k *lines* of code, so current models must rely on retrieval methods to solve these issues, as the entire codebase cannot fit within context.
Replying to @_carlosejimenez
SWE-bench sources 2,294 task instances from popular Python repos. Each challenge includes an issue and the repo's codebase. In order to succeed, the LM must generate a patch diff that applies correctly, and successfully passes all the unit tests associated with that issue.
Replying to @_carlosejimenez
The SWE-agent open-source repository provides a framework for turning general LMs into software engineering agents. SWE-agent lets LMs like GPT-4 interact with their own Docker container using an Agent Computer Interface (ACI) - allowing it to browse, search, edit, and run code.
Replying to @_carlosejimenez
To help open model development on SWE-bench, we also introduce SWE-Llama! SWE-Llama finetunes CodeLlama on SWE-bench-train (with up to 30k tokens per sequence) SWE-Llama can generate PRs given an issue + codebase Performs similarly to Claude Available at huggingface.co/princeton-nlp/…
Awesome to see people using SWE-bench to benchmark their coding agents! Try out swebench.com on your models!
Today we're excited to introduce Devin, the first AI software engineer. Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork. Devin is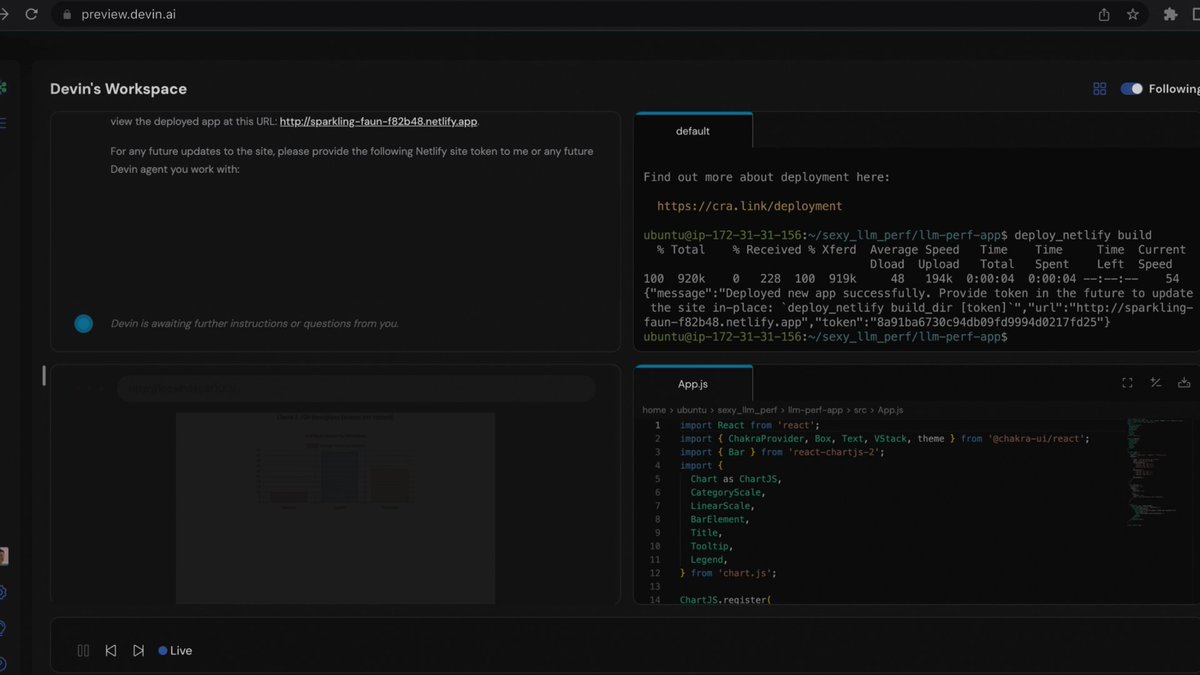
Replying to @_carlosejimenez
SOTA LMs are weak across the board. When using BM-25 to retrieve the relevant code files for each issue, only 23% of the patches written by Claude are valid (can be applied to the repo), and only ~1% actually fix the issue. Using an oracle retriever helps but not substantially

SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source! We designed a new agent-computer interface to make it easy for GPT-4 to edit+run codegithub.com/princeton-nlp/…
We just updated the SWE-bench Lite leaderboard with SWE-agent GPT4o! It gets slightly worse accuracy (17%) than GPT4 (18%). Super interested in whether people can build out new tools for SWE-agent with GPT4o to make it better!