John Yang (@jyangballin) on X (original) (raw)


CS PhD
. Created
(multi-lingual/modal); SWE-agent; SWE-smith; InterCode; CodeClash; ProgramBench 🆕
- Pinned

How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access. Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵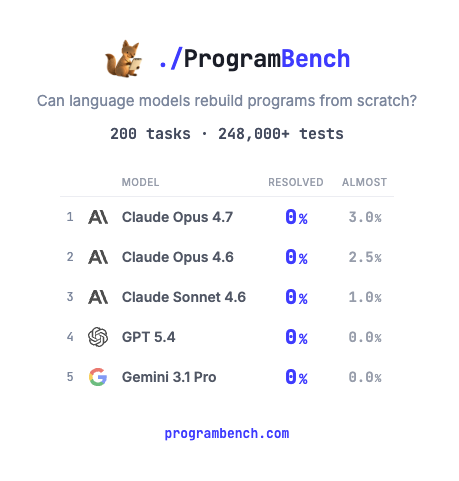
SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source! We designed a new agent-computer interface to make it easy for GPT-4 to edit+run codegithub.com/princeton-nlp/…
40% with just 1 try per task: SWE-agent-LM-32B is the new #1 open source model on SWE-bench Verified. We built it by synthesizing a ton of agentic training data from 100+ Python repos. Today we’re open-sourcing the toolkit that made it happen: SWE-smith.
New eval! Code duels for LMs ⚔️ Current evals test LMs on *tasks*: "fix this bug," "write a test" But we code to achieve *goals*: maximize revenue, cut costs, win users Meet CodeClash: LMs compete via their codebases across multi-round tournaments to achieve high-level goals

"Your fancy AI scaffolds will be washed away by scale" - Noam Brown If you're still doing SWE-agent research with heavy frameworks + manually defined tools, don't. All those artifacts (exec. traces, tools, prompts) don't transfer. Use mini-SWE-agent. Bash-only is the future.
We evaluated Anthropic's Sonnet 4.5 with our minimal agent. New record on SWE-bench verified: 70.6%! Same price/token as Sonnet 4, but takes more steps, ending up being more expensive. Cost analysis details & link to full trajectories in 🧵
Replying to @jyangballin
Simply connecting an LM to a vanilla bash terminal does not work well. Our key insight is that LMs require carefully designed agent-computer interfaces (similar to how humans like good UI design) E.g. When the LM messes up indentation, our editor prevents it and gives feedback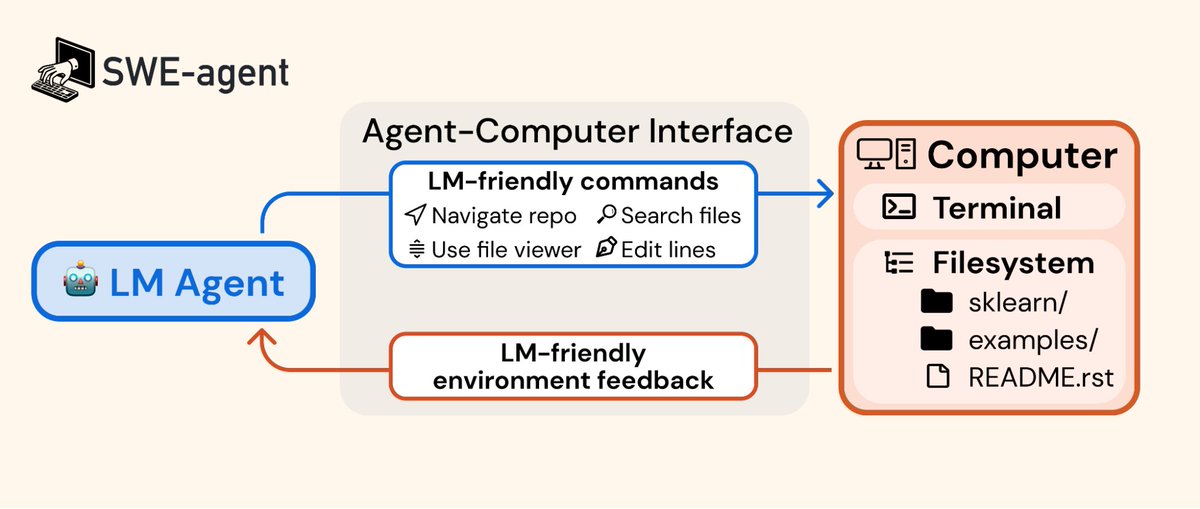
We're launching SWE-bench Multimodal to eval agents' ability to solve visual GitHub issues. - 617 *brand new* tasks from 17 JavaScript repos - Each task has an image! Existing agents struggle here! We present SWE-agent Multimodal to remedy some issues Led w/
@_carlosejimenez
🧵
We just updated the SWE-agent preprint: - New results: 87.7% Pass@1 on HumanEvalFix (SoTA!) - Full SWE-agent walkthrough + ACI definition - More analysis (Failure modes, pass@k, agent behaviors, + ton more) ACI is 🔑 to LMs as SWEs, here:arxiv.org/abs/2405.157931/3
SWE-bench Multimodal evaluation code is out now! SWE-bench MM is a new set of JavaScript issues that have a visual component (‘map isn’t rendering correctly’, ‘button text isn’t appearing’).
Replying to @jyangballin
Another example is that we discovered that for viewing files, letting SWE-agent only view 100 lines at a time was better than letting it view 200 or 300 lines and much better than letting it view the entire file. Good agent-computer design is important even when using GPT-4. 4/N
📊 SWE-bench Leaderboard UpdateSWE-bench Lite 🥇 Bytedance MarsCode Agent 🥈 Honeycomb 🥉 Gru (2024-08-11) SWE-bench Verified 🥇 [Anthropic] Tools + Claude 3.5 Sonnet (2024-10-22) 🥈 Solver (2024-09-12) 🥉 Gru(2024-08-24) Keep reading for summaries!

@ weekend warriors - DM me a GitHub repo that you like / maintain, and I'll train you a 7B coding agent that's an expert for that repo. Main constraints - it's predominantly Python, and has a testing suite w/ good coverage. (example of good repo = sympy, pandas, sqlfluff)