Код Рида — Соломона | это... Что такое Код Рида — Соломона? (original) (raw)
Код Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида — Соломона, работающие с байтами (октетами).
Код Рида — Соломона является частным случаем БЧХ-кода.
В настоящее время широко используется в системах восстановления данных с компакт-дисков, при создании архивов с информацией для восстановления в случае повреждений, в помехоустойчивом кодировании.
Содержание
- 1 История
- 2 Формальное описание
- 3 Свойства
- 4 Практическая реализация
- 5 Применение
- 6 Примеры кодов
- 7 Примечания
- 8 Литература
- 9 Ссылки
- 10 См. также
История
Код Рида — Соломона был изобретён в 1960 году сотрудниками лаборатории Линкольна Массачуссетского технологического института Ирвином Ридом (англ.) и Густавом Соломоном (англ.). Идея использования этого кода была представлена в статье «Polynomial Codes over Certain Finite Fields». Первое применение код Рида — Соломона получил в 1982 году в серийном выпуске компакт-дисков. Эффективный алгоритм декодирования был предложен в 1969 году Элвином Берлекэмпом (англ.) и Джэймсом Месси (алгоритм Берлекэмпа — Мэсси).
Формальное описание
Коды Рида — Соломона являются важным частным случаем БЧХ-кода, корни порождающего полинома которого лежат в том же поле, над каким и строится код (m = 1). Пусть α — элемент поля 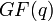 порядка
порядка 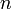 . Если α — примитивный элемент, то его порядок равен q − 1, то есть
. Если α — примитивный элемент, то его порядок равен q − 1, то есть 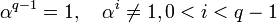 . Тогда нормированный полином g(x) минимальной степени над полем , корнями которого являются d − 1 подряд идущих степеней
. Тогда нормированный полином g(x) минимальной степени над полем , корнями которого являются d − 1 подряд идущих степеней 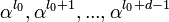 элемента α, является порождающим полиномом кода Рида — Соломона над полем :
элемента α, является порождающим полиномом кода Рида — Соломона над полем :
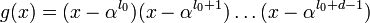
где _l_0 — некоторое целое число (в том числе 0 и 1), с помощью которого иногда удается упростить кодер. Обычно полагается _l_0 = 1. Степень многочлена 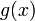 равна d − 1.
равна d − 1.
Длина полученного кода n, минимальное расстояние d (минимальное расстояние d линейного кода является минимальным из всех расстояний Хемминга всех пар кодовых слов, см. Линейный код). Код содержит r = d − 1 = deg(g(x)) проверочных символов, где deg() обозначает степень полинома; число информационных символов k = n − r = n − d + 1. Таким образом 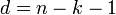 и код Рида — Соломона является разделимым кодом с максимальным расстоянием (является оптимальным в смысле границы Синглтона).
и код Рида — Соломона является разделимым кодом с максимальным расстоянием (является оптимальным в смысле границы Синглтона).
Кодовый полином c(x) может быть получен из информационного полинома m(x), 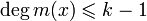 , путем перемножения m(x) и g(x):
, путем перемножения m(x) и g(x):
c(x) = m(x)g(x)
Свойства
Код Рида — Соломона над 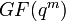 , исправляющий t ошибок, требует 2_t_ проверочных символов и с его помощью исправляются произвольные пакеты ошибок длиной t и меньше. Согласно теореме о границе Рейгера, коды Рида — Соломона являются оптимальными с точки зрения соотношения длины пакета и возможности исправления ошибок — используя 2_t_ дополнительных проверочных символов исправляются t ошибок (и менее).
, исправляющий t ошибок, требует 2_t_ проверочных символов и с его помощью исправляются произвольные пакеты ошибок длиной t и меньше. Согласно теореме о границе Рейгера, коды Рида — Соломона являются оптимальными с точки зрения соотношения длины пакета и возможности исправления ошибок — используя 2_t_ дополнительных проверочных символов исправляются t ошибок (и менее).
Теорема (граница Рейгера). Каждый линейный блоковый код, исправляющий все пакеты длиной t и менее, должен содержать, по меньшей мере, 2_t_ проверочных символов.
Исправление многократных ошибок
Код Рида — Соломона является одним из наиболее мощных кодов, исправляющих многократные пакеты ошибок. Применяется в каналах, где пакеты ошибок могут образовываться столь часто, что их уже нельзя исправлять с помощью кодов, исправляющих одиночные ошибки.
(q m − 1,q m − 1 − 2_t_)-код Рида — Соломона над полем с кодовым расстоянием d = 2_t_ + 1 можно рассматривать как ((q m − 1)m,(q m − 1 − 2_t_)m)-код над полем , который может исправлять любую комбинацию ошибок, сосредоточенную в t или меньшем числе блоков из m символов. Наибольшее число блоков длины m, которые может затронуть пакет длины l i, где 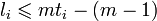 , не превосходит t i, поэтому код, который может исправить t блоков ошибок, всегда может исправить и любую комбинацию из p пакетов общей длины l, если
, не превосходит t i, поэтому код, который может исправить t блоков ошибок, всегда может исправить и любую комбинацию из p пакетов общей длины l, если 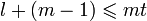 .
.
Практическая реализация
Кодирование с помощью кода Рида — Соломона может быть реализовано двумя способами: систематическим и несистематическим (см. [1], описание кодировщика).
При несистематическом кодировании информационное слово умножается на некий неприводимый полином в поле Галуа. Полученное закодированное слово полностью отличается от исходного и для извлечения информационного слова нужно выполнить операцию декодирования и уже потом можно проверить данные на содержание ошибок. Такое кодирование требует большие затраты ресурсов только на извлечение информационных данных, при этом они могут быть без ошибок.

Структура систематического кодового слова Рида — Соломона
При систематическом кодировании к информационному блоку из k символов приписываются 2_t_ проверочных символов, при вычислении каждого проверочного символа используются все k символов исходного блока. В этом случае нет затрат ресурсов при извлечении исходного блока, если информационное слово не содержит ошибок, но кодировщик/декодировщик должен выполнить k(n − k) операций сложения и умножения для генерации проверочных символов. Кроме того, так как все операции проводятся в поле Галуа, то сами операции кодирования/декодирования требуют много ресурсов и времени. Быстрый алгоритм декодирования, основанный на быстром преобразовании Фурье, выполняется за время порядка O(l n(_n_2)).

Кодирование
При операции кодирования информационный полином умножается на порождающий многочлен. Умножение исходного слова S длины k на неприводимый полином при систематическом кодировании можно выполнить следующим образом:
Кодировщик строится из сдвиговых регистров, сумматоров и умножителей. Сдвиговый регистр состоит из ячеек памяти, в каждой из которых находится один элемент поля Галуа.
Декодирование
Декодировщик, работающий по авторегрессивному спектральному методу декодирования, последовательно выполняет следующие действия:
- Вычисляет синдром ошибки
- Строит полином ошибки
- Находит корни данного полинома
- Определяет характер ошибки
- Исправляет ошибки
Вычисление синдрома ошибки
Вычисление синдрома ошибки выполняется синдромным декодером, который делит кодовое слово на порождающий многочлен. Если при делении возникает остаток, то в слове есть ошибка. Остаток от деления является синдромом ошибки.
Построение полинома ошибки
Вычисленный синдром ошибки не указывает на положение ошибок. Степень полинома синдрома равна 2_t_, что много меньше степени кодового слова n. Для получения соответствия между ошибкой и ее положением в сообщении строится полином ошибок. Полином ошибок реализуется с помощью алгоритма Берлекэмпа — Месси, либо с помощью алгоритма Евклида. Алгоритм Евклида имеет простую реализацию, но требует больших затрат ресурсов. Поэтому чаще применяется более сложный, но менее затратоемкий алгоритм Берлекэмпа — Месси. Коэффициенты найденного полинома непосредственно соответствуют коэффициентам ошибочных символов в кодовом слове.
Нахождение корней
На этом этапе ищутся корни полинома ошибки, определяющие положение искаженных символов в кодовом слове. Реализуется с помощью процедуры Ченя, равносильной полному перебору. В полином ошибок последовательно подставляются все возможные значения, когда полином обращается в ноль — корни найдены.
Определение характера ошибки и ее исправление
По синдрому ошибки и найденным корням полинома с помощью алгоритма Форни определяется характер ошибки и строится маска искаженных символов. Эта маска накладывается на кодовое слово с помощью операции XOR и искаженные символы восстанавливаются. После этого отбрасываются проверочные символы и получается восстановленное информационное слово.
Применение
В настоящий момент коды Рида — Соломона имеют очень широкую область применения благодаря их способности находить и исправлять многократные пакеты ошибок.
Запись и хранение информации
Код Рида — Соломона используется при записи и чтении в контроллерах оперативной памяти, при архивировании данных, записи информации на жесткие диски (ECC), записи на CD/DVD диски. Даже если поврежден значительный объем информации, испорчено несколько секторов дискового носителя, то коды Рида — Соломона позволяют восстановить большую часть потерянной информации. Также используется при записи на такие носители, как магнитные ленты и штрихкоды.
Запись на CD-ROM
Возможные ошибки при чтении с диска появляются уже на этапе производства диска, так как сделать идеальный диск при современных технологиях невозможно. Так же ошибки могут быть вызваны царапинами на поверхности диска, пылью и т. д. Поэтому при изготовлении читаемого компакт-диска используется система коррекции CIRC (Cross Interleaved Reed Solomon Code). Эта коррекция реализована во всех устройствах, позволяющих считывать данные с CD дисков, в виде чипа с прошивкой firmware. Нахождение и коррекция ошибок основана на избыточности и перемежении (redundancy & interleaving). Избыточность примерно 25 % от исходной информации.
При записи на цифровые аудиокомпакт-диски (Compact Disc Digital Audio — CD-DA) используется стандарт Red Book. Коррекция ошибок происходит на двух уровнях C1 и C2. При кодировании на первом этапе происходит добавление проверочных символов к исходным данным, на втором этапе информация снова кодируется. Кроме кодирования осуществляется также перемешивание (перемежение) байтов, чтобы при коррекции блоки ошибок распались на отдельные биты, которые легче исправляются. На первом уровне обнаруживаются и исправляются ошибочные блоки длиной один и два байта (один и два ошибочных символа соответственно). Ошибочные блоки длиной три байта обнаруживаются и передаются на следующий уровень. На втором уровне обнаруживаются и исправляются ошибочные блоки, возникшие в C2, длиной 1 и 2 байта. Обнаружение трех ошибочных символов является фатальной ошибкой и не может быть исправлено.
Беспроводная и мобильная связь
Этот алгоритм кодирования используется при передаче данных по сетям WiMAX, в оптических линиях связи, в спутниковой и радиорелейной связи. Метод прямой коррекции ошибок в проходящем трафике (Forward Error Correction, FEC) основывается на кодах Рида — Соломона.
Примеры кодов
16-ричный (15,11) код Рида — Соломона
Пусть t = 2,_l_0 = 1. Тогда
g(x) = (x − α)(x − α2)(x − α3)(x − α4) = x_4 + α13_x_3 + α6_x_2 + α3_x + α10
.
Степень g(x) равна 4, n − k = 4 и k = 11. Каждому элементу поля GF(16) можно сопоставить 4 бита. Информационный многочлен является последовательностью 11 символов из GF(16), что эквивалентно 44 битам, а все кодовое слово является набором из 60 бит.
8-ричный (7,3) код Рида — Соломона
Пусть t = 2,_l_0 = 4. Тогда
g(x) = (x − α4)(x − α5)(x − α6)(x − α0) = x_4 + α6_x_3 + α6_x_2 + α3_x + α
.
Пусть информационный многочлен имеет вид
m(x) = α4_x_2 + x + α3
.
Кодовое слово несистематического кода запишется в виде
c(x) = m(x)g(x) = (α4_x_2 + x + α3)(x_4 + α6_x_3 + α6_x_2 + α3_x + α) = α4_x_6 + α_x_5 + α6_x_4 + 0_x_3 + 0_x_2 + α5_x_ + α4
что представляет собой последовательность семи восьмеричных символов.
Примечания
Литература
- Питерсон У., Уэлдон Э. Коды, исправляющие ошибки. — М.: Мир, 1976. — С. 596.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Берлекэмп Э. Алгебраическая теория кодирования = Algebraic Coding Theory. — М.: Мир, 1971. — С. 478.
- Егоров С.И. Коррекция ошибок в информационных каналах периферийных устройств ЭВМ. — Курск: КурскГТУ, 2008. — С. 252.
Ссылки
- Могущество кодов Рида — Соломона или информация, воскресшая из пепла (статья Криса Касперски)
- Помехоустойчивое кодирование в пакетных сетях (статья В. Варгаузина)
- Error Correcting Code (ECC)
- CD-R диски, технология изнутри
- Формат CD
См. также
- Конечное поле
- Обнаружение и исправление ошибок
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Турбо-код
Wikimedia Foundation.2010.