predictAndUpdateState - (Not recommended) Predict responses using a trained recurrent neural network and
update the network state - MATLAB ([original](https://in.mathworks.com/help/deeplearning/ref/seriesnetwork.predictandupdatestate.html)) ([raw](?raw))(Not recommended) Predict responses using a trained recurrent neural network and update the network state
predictAndUpdateState is not recommended. Instead, use thepredict function and use the state output to update the State property of the neural network. For more information, see Version History.
Syntax
Description
You can make predictions using a trained deep learning network on either a CPU or GPU. Using a GPU requires a Parallel Computing Toolbox™ license and a supported GPU device. For information about supported devices, seeGPU Computing Requirements (Parallel Computing Toolbox). Specify the hardware requirements using the ExecutionEnvironment name-value argument.
[[updatedNet](#d126e215727),[Y](#d126e215746)] = predictAndUpdateState([recNet](#d126e214943),[sequences](#mw%5Fe64205e2-5297-4ff5-ad37-0d5375e19ef2%5Fsep%5Fmw%5F5a3519e4-ff13-4b34-baf4-c9f3a716e62d)) predicts responses for data in sequences using the trained recurrent neural network recNet and updates the network state.
This function supports recurrent neural networks only. The inputrecNet must have at least one recurrent layer such as an LSTM layer or a custom layer with state parameters.
[[updatedNet](#d126e215727),[Y](#d126e215746)] = predictAndUpdateState([recNet](#d126e214943),[X1,...,XN](#mw%5Fe64205e2-5297-4ff5-ad37-0d5375e19ef2%5Fsep%5Fmw%5Fbd719580-c2ff-492b-a0ab-8291fdbdc004)) predicts the responses for the data in the numeric or cell arraysX1, …, XN for the multi-input networkrecNet. The input Xi corresponds to the network input recNet.InputNames(i).
[[updatedNet](#d126e215727),[Y](#d126e215746)] = predictAndUpdateState([recNet](#d126e214943),[mixed](#mw%5Fe64205e2-5297-4ff5-ad37-0d5375e19ef2%5Fsep%5Fmw%5F24c37e26-6497-4d74-ab01-7a7b3250bf9a)) makes predictions using the multi-input network recNet with data of mixed data types.
[updatedNet,[Y1,...,YM](#mw%5F43dbc3bc-3fb7-4703-ba56-666f53d1f06a)] = predictAndUpdateState(___) predicts responses for the M outputs of a multi-output network using any of the previous input arguments. The output Yj corresponds to the network output recNet.OutputNames(j). To return categorical outputs for the classification output layers, set the ReturnCategorical option to 1 (true).
[___] = predictAndUpdateState(___,[Name=Value](#namevaluepairarguments)) makes predictions with additional options specified by one or more name-value arguments using any of the previous syntaxes. For example,MiniBatchSize=27 makes predictions using mini-batches of size 27.
Tip
When you make predictions with sequences of different lengths, the mini-batch size can impact the amount of padding added to the input data, which can result in different predicted values. Try using different values to see which works best with your network. To specify mini-batch size and padding options, use the MiniBatchSize and SequenceLength options, respectively.
Examples
Predict responses using a trained recurrent neural network and update the network state.
Suppose you have a long short-term memory (LSTM) networknet that was trained on the Japanese Vowels data set as described in [1] and [2]. Suppose the network was trained on the sequences sorted by sequence length with a mini-batch size of 27.
View the network architecture.
ans = 5x1 Layer array with layers:
1 'sequenceinput' Sequence Input Sequence input with 12 dimensions
2 'lstm' LSTM LSTM with 100 hidden units
3 'fc' Fully Connected 9 fully connected layer
4 'softmax' Softmax softmax
5 'classoutput' Classification Output crossentropyex with '1' and 8 other classesLoad the test data.
load JapaneseVowelsTestData
Loop over the time steps in a sequence. Predict the scores of each time step and update the network state.
X = XTest{94}; numTimeSteps = size(X,2); for i = 1:numTimeSteps v = X(:,i); [net,score] = predictAndUpdateState(net,v); scores(:,i) = score; end
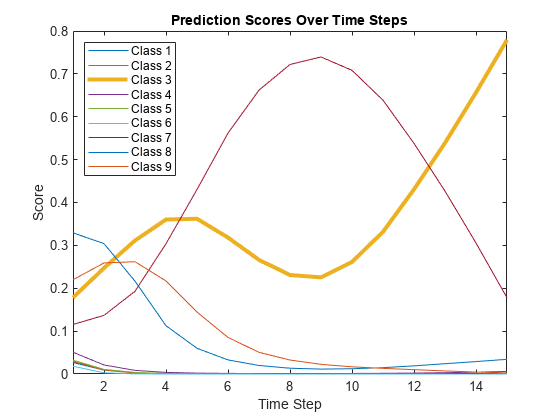
Plot the prediction scores. The plot shows how the prediction scores change between time steps.
classNames = string(net.Layers(end).Classes); figure lines = plot(scores'); xlim([1 numTimeSteps]) legend("Class " + classNames,Location="northwest") xlabel("Time Step") ylabel("Score") title("Prediction Scores Over Time Steps")
Highlight the prediction scores over time steps for the correct class.
trueLabel = TTest(94); lines(trueLabel).LineWidth = 3;
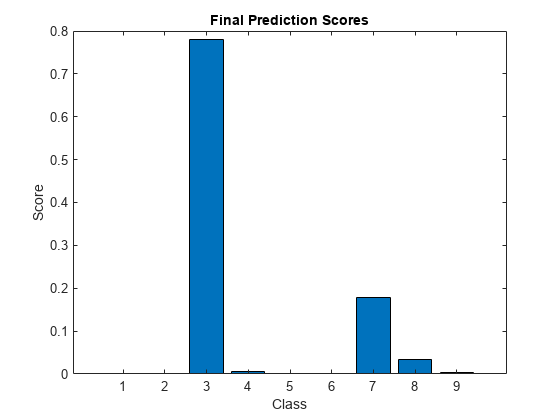
Display the final time step prediction in a bar chart.
figure bar(score) title("Final Prediction Scores") xlabel("Class") ylabel("Score")
Input Arguments
Trained recurrent neural network, specified as a SeriesNetwork or a DAGNetwork object. You can get a trained network by importing a pretrained network or by training your own network using the trainNetwork function.
recNet is a recurrent neural network. It must have at least one recurrent layer (for example, an LSTM network).
Sequence or time series data, specified as an _N_-by-1 cell array of numeric arrays, where N is the number of observations, a numeric array representing a single sequence, or a datastore.
For cell array or numeric array input, the dimensions of the numeric arrays containing the sequences depend on the type of data.
| Input | Description |
|---|---|
| Vector sequences | c_-by-s matrices, where_c is the number of features of the sequences and s is the sequence length. |
| 1-D image sequences | _h_-by-_c_-by-s arrays, where h and c correspond to the height and number of channels of the images, respectively, and s is the sequence length. |
| 2-D image sequences | _h_-by-_w_-by-c_-by-s arrays, where h, w, and_c correspond to the height, width, and number of channels of the images, respectively, and s is the sequence length. |
| 3-D image sequences | _h_-by-_w_-by-_d_-by-_c_-by-s, where h, w,d, and c correspond to the height, width, depth, and number of channels of the 3-D images, respectively, and s is the sequence length. |
For datastore input, the datastore must return data as a cell array of sequences or a table whose first column contains sequences. The dimensions of the sequence data must correspond to the table above.
Tip
This argument supports complex-valued predictors. To input complex-valued data into a SeriesNetwork or DAGNetwork object, theSplitComplexInputs option of the input layer must be1 (true).
Numeric or cell arrays for networks with multiple inputs.
For sequence predictor input, the input must be a numeric array representing a single sequence or a cell array of sequences, where the format of the predictors match the formats described in the sequences argument description. For image and feature predictor input, the input must be a numeric array and the format of the predictors must match the one of the following:
| Data | Format |
|---|---|
| 2-D images | _h_-by-_w_-by-c numeric array, where h, w, and c are the height, width, and number of channels of the images, respectively. |
| 3-D images | _h_-by-_w_-by-_d_-by-c numeric array, where h, w, d, and c are the height, width, depth, and number of channels of the images, respectively. |
| Feature data | _c_-by-1 column vectors, where c is the number of features. |
For an example showing how to train a network with multiple inputs, see Train Network on Image and Feature Data.
Tip
To input complex-valued data into a DAGNetwork orSeriesNetwork object, theSplitComplexInputs option of the input layer must be1.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | cell
Complex Number Support: Yes
Mixed data, specified as one of the following.
| Data Type | Description | Example Usage |
|---|---|---|
| TransformedDatastore | Datastore that transforms batches of data read from an underlying datastore using a custom transformation function | Make predictions using networks with multiple inputs.Transform outputs of datastores not supported bypredictAndUpdateState so they have the required format.Apply custom transformations to datastore output. |
| CombinedDatastore | Datastore that reads from two or more underlying datastores | Make predictions using networks with multiple inputs.Combine predictors from different data sources. |
| Custom mini-batch datastore | Custom datastore that returns mini-batches of data | Make predictions using data in a format that other datastores do not support.For details, see Develop Custom Mini-Batch Datastore. |
You can use other built-in datastores for making predictions by using the transform and combine functions. These functions can convert the data read from datastores to the table or cell array format required by predictAndUpdateState. For more information, see Datastores for Deep Learning.
The datastore must return data in a table or a cell array. Custom mini-batch datastores must output tables. The format of the datastore output depends on the network architecture.
| Datastore Output | Example Output |
|---|---|
| Cell array with numInputs columns, wherenumInputs is the number of network inputs.The order of inputs is given by the InputNames property of the network. | data = read(ds) data = 4×3 cell array {12×50 double} {28×1 double} {12×50 double} {28×1 double} {12×50 double} {28×1 double} {12×50 double} {28×1 double} |
For sequence predictor input, the input must be a numeric array representing a single sequence or a cell array of sequences, where the format of the predictors match the formats described in the sequences argument description. For image and feature predictor input, the input must be a numeric array and the format of the predictors must match the one of the following:
| Data | Format |
|---|---|
| 2-D images | _h_-by-_w_-by-c numeric array, where h, w, and c are the height, width, and number of channels of the images, respectively. |
| 3-D images | _h_-by-_w_-by-_d_-by-c numeric array, where h, w, d, and c are the height, width, depth, and number of channels of the images, respectively. |
| Feature data | _c_-by-1 column vectors, where c is the number of features. |
For an example showing how to train a network with multiple inputs, see Train Network on Image and Feature Data.
Tip
To convert a numeric array to a datastore, use ArrayDatastore.
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose Name in quotes.
Example: [updatedNet,Y] = predictAndUpdateState(recNet,C,MiniBatchSize=27) makes predictions using mini-batches of size 27.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Performance optimization, specified as one of the following:
"auto"— Automatically apply a number of optimizations suitable for the input network and hardware resources."none"— Disable all acceleration.
Using the Acceleration option "auto" can offer performance benefits, but at the expense of an increased initial run time. Subsequent calls with compatible parameters are faster. Use performance optimization when you plan to call the function multiple times using new input data.
Hardware resource, specified as one of these values:
"auto"— Use a GPU if one is available. Otherwise, use the CPU."gpu"— Use the GPU. Using a GPU requires a Parallel Computing Toolbox license and a supported GPU device. For information about supported devices, seeGPU Computing Requirements (Parallel Computing Toolbox). If Parallel Computing Toolbox or a suitable GPU is not available, then the software returns an error."cpu"— Use the CPU.
Option to return categorical labels, specified as 0 (false) or 1 (true).
If ReturnCategorical is 1 (true), then the function returns categorical labels for classification output layers. Otherwise, the function returns the prediction scores for classification output layers.
Option to pad, truncate, or split sequences, specified as one of these values:
"longest"— Pad sequences in each mini-batch to have the same length as the longest sequence. This option does not discard any data, though padding can introduce noise to the neural network."shortest"— Truncate sequences in each mini-batch to have the same length as the shortest sequence. This option ensures that no padding is added, at the cost of discarding data.- Positive integer — For each mini-batch, pad the sequences to the length of the longest sequence in the mini-batch, and then split the sequences into smaller sequences of the specified length. If splitting occurs, then the software creates extra mini-batches. If the specified sequence length does not evenly divide the sequence lengths of the data, then the mini-batches containing the ends those sequences have length shorter than the specified sequence length. Use this option if the full sequences do not fit in memory. Alternatively, try reducing the number of sequences per mini-batch by setting the
MiniBatchSizeoption to a lower value.
To learn more about the effect of padding and truncating sequences, see Sequence Padding and Truncation.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64 | char | string
Direction of padding or truncation, specified as one of the following:
"right"— Pad or truncate sequences on the right. The sequences start at the same time step and the software truncates or adds padding to the end of the sequences."left"— Pad or truncate sequences on the left. The software truncates or adds padding to the start of the sequences so that the sequences end at the same time step.
Because recurrent layers process sequence data one time step at a time, when the recurrent layer OutputMode property is "last", any padding in the final time steps can negatively influence the layer output. To pad or truncate sequence data on the left, set the SequencePaddingDirection option to "left".
For sequence-to-sequence neural networks (when the OutputMode property is "sequence" for each recurrent layer), any padding in the first time steps can negatively influence the predictions for the earlier time steps. To pad or truncate sequence data on the right, set the SequencePaddingDirection option to "right".
To learn more about the effect of padding and truncating sequences, see Sequence Padding and Truncation.
Value by which to pad input sequences, specified as a scalar.
Do not pad sequences with NaN, because doing so can propagate errors throughout the neural network.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Output Arguments
Updated network. updatedNet is the same type of network as the input network.
Predicted scores or responses, returned as a numeric array, categorical array, or a cell array. The format of Y depends on the type of problem.
The following table describes the format for classification tasks.
| Task | ReturnCategorical | Format |
|---|---|---|
| Sequence-to-label classification | 0 (false) | _N_-by-K matrix, where N is the number of observations, and K is the number of classes |
| 1 (true) | N_-by-1 categorical vector, where_N is the number of observations | |
| Sequence-to-sequence classification | 0 (false) | N_-by-1 cell array of matrices, where N is the number of observations. The sequences are matrices with_K rows, where_K_ is the number of classes. Each sequence has the same number of time steps as the corresponding input sequence after theSequenceLength option is applied to each mini-batch independently. |
| 1 (true) | _N_-by-1 cell array of categorical sequences, where N is the number of observations. The categorical sequences are categorical vectors with the same number of time steps as the corresponding input sequence after theSequenceLength option is applied to each mini-batch independently. |
For sequence-to-sequence classification tasks with one observation,sequences can be a matrix. In this case, the format of Y depends on theReturnCategorical option:
- If
ReturnCategoicalis0(false), thenYis a K_-by-S matrix scores, where K is the number of classes, and_S is the total number of time steps in the corresponding input sequence. - If
ReturnCategoicalis1(true), thenYis a _1_-by-S categorical vector, where S is the total number of time steps in the corresponding input sequence.
The following table describes the format for regression tasks.
| Task | Format |
|---|---|
| Sequence-to-one regression | _N_-by-R matrix, where N is the number of observations and R is the number of responses. |
| Sequence-to-sequence regression | N_-by-1 cell array of numeric sequences, where N is the number of observations. The sequences are matrices with_R rows, where_R_ is the number of responses. Each sequence has the same number of time steps as the corresponding input sequence after applying theSequenceLength option to each mini-batch independently.For sequence-to-sequence problems with one observation,sequences can be a matrix. In this case, Y is a matrix of responses. |
Predicted scores or responses of networks with multiple outputs, returned as numeric arrays, categorical arrays, or cell arrays.
Each output Yj corresponds to the network outputrecNet.OutputNames(j) and has format as described in the Y output argument.
Algorithms
When you train a neural network using the trainnet or trainNetwork functions, or when you use prediction or validation functions with DAGNetwork and SeriesNetwork objects, the software performs these computations using single-precision, floating-point arithmetic. Functions for prediction and validation include predict, classify, and activations. The software uses single-precision arithmetic when you train neural networks using both CPUs and GPUs.
To provide the best performance, deep learning using a GPU in MATLAB® is not guaranteed to be deterministic. Depending on your network architecture, under some conditions you might get different results when using a GPU to train two identical networks or make two predictions using the same network and data.
Alternatives
For recurrent neural networks with a single classification layer only, you can compute the predicted classes and scores and update the network state using the classifyAndUpdateState function.
To compute the activations of a network layer, use the activations function. The activations function does not update the network state.
To make predictions without updating the network state, use the classify function or the predict function.
References
[1] M. Kudo, J. Toyama, and M. Shimbo. "Multidimensional Curve Classification Using Passing-Through Regions." Pattern Recognition Letters. Vol. 20, No. 11–13, pages 1103–1111.
[2] UCI Machine Learning Repository: Japanese Vowels Dataset. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
Extended Capabilities
Usage notes and limitations:
- C++ code generation supports the following syntaxes:
[updatedNet,Y] = predictAndUpdateState(recNet,sequences), wheresequencesis cell array.[updatedNet,Y] = predictAndUpdateState(recNet,sequences,Name=Value)
- For vector sequence inputs, the number of features must be a constant during code generation. The sequence length can be variable sized.
- For image sequence inputs, the height, width, and the number of channels must be a constant during code generation.
- Only the
MiniBatchSize,SequenceLength,SequencePaddingDirection, andSequencePaddingValuename-value arguments are supported for code generation. All name-value arguments must be compile-time constants. - Only the
"longest"and"shortest"options of theSequenceLengthname-value argument is supported for code generation. - Code generation for Intel® MKL-DNN target does not support the combination of
SequenceLength="longest",SequencePaddingDirection="left", andSequencePaddingValue=0name-value arguments.
Usage notes and limitations:
GPU code generation supports the following syntaxes:
[updatedNet,Y] = predictAndUpdateState(recNet,sequences), wheresequencesis cell array or numeric array.[updatedNet,Y] = predictAndUpdateState(recNet,sequences,Name=Value)
GPU code generation for the
predictAndUpdateStatefunction is only supported for recurrent neural networks targeting cuDNN and TensorRT libraries.GPU code generation does not support
gpuArrayinputs to thepredictAndUpdateStatefunction.For vector sequence inputs, the number of features must be a constant during code generation. The sequence length can be variable sized.
For image sequence inputs, the height, width, and the number of channels must be a constant during code generation.
Only the
MiniBatchSize,SequenceLength,SequencePaddingDirection, andSequencePaddingValuename-value arguments are supported for code generation. All name-value pairs must be compile-time constants.Only the
"longest"and"shortest"options of theSequenceLengthname-value argument is supported for code generation.The
ExecutionEnvironmentoption must be"auto"or"gpu"when the input data is:- A
gpuArray - A cell array containing
gpuArrayobjects - A table containing
gpuArrayobjects - A datastore that outputs cell arrays containing
gpuArrayobjects - A datastore that outputs tables containing
gpuArrayobjects
- A
For more information, see Run MATLAB Functions on a GPU (Parallel Computing Toolbox).
Version History
Introduced in R2017b
Starting in R2024a, DAGNetwork and SeriesNetwork objects are not recommended, use dlnetwork objects instead. This recommendation means that the predictAndUpdateState function is also not recommended. Instead, use the predict function and use the state output to update the State property of the neural network.
There are no plans to remove support for DAGNetwork andSeriesNetwork objects. However, dlnetwork objects have these advantages and are recommended instead:
dlnetworkobjects are a unified data type that supports network building, prediction, built-in training, visualization, compression, verification, and custom training loops.dlnetworkobjects support a wider range of network architectures that you can create or import from external platforms.- The trainnet function supports
dlnetworkobjects, which enables you to easily specify loss functions. You can select from built-in loss functions or specify a custom loss function. - Training and prediction with
dlnetworkobjects is typically faster thanLayerGraphandtrainNetworkworkflows.
To convert a trained DAGNetwork or SeriesNetwork object to a dlnetwork object, use the dag2dlnetwork function.
This table shows a typical usage of the predictAndUpdateState function and how to update your code to use dlnetwork objects instead.
| Not Recommended | Recommended |
|---|---|
| [net,Y] = predictAndUpdateState(net,X); | [scores,state] = predict(net,X); net.State = state; |
Starting in R2022b, when you make predictions with sequence data using thepredict, classify,predictAndUpdateState, classifyAndUpdateState, and activations functions and the SequenceLength option is an integer, the software pads sequences to the length of the longest sequence in each mini-batch and then splits the sequences into mini-batches with the specified sequence length. If SequenceLength does not evenly divide the sequence length of the mini-batch, then the last split mini-batch has a length shorter thanSequenceLength. This behavior prevents time steps that contain only padding values from influencing predictions.
In previous releases, the software pads mini-batches of sequences to have a length matching the nearest multiple of SequenceLength that is greater than or equal to the mini-batch length and then splits the data. To reproduce this behavior, manually pad the input data such that the mini-batches have the length of the appropriate multiple of SequenceLength. For sequence-to-sequence workflows, you may also need to manually remove time steps of the output that correspond to padding values.