SequenceInputLayer - Sequence input layer - MATLAB (original) (raw)
Main Content
Description
A sequence input layer inputs sequence data to a neural network and applies data normalization.
Creation
Syntax
Description
`layer` = sequenceInputLayer([inputSize](#mw%5F31edbc34-c21b-42da-8e3c-5ad4ed647b34)) creates a sequence input layer and sets the InputSize property.
`layer` = sequenceInputLayer([inputSize](#mw%5F31edbc34-c21b-42da-8e3c-5ad4ed647b34),[Name=Value](#namevaluepairarguments)) sets optional properties using one or more name-value arguments.
Input Arguments
inputSize — Size of input
positive integer | vector of positive integers
Size of the input, specified as a positive integer or a vector of positive integers.
- For vector sequence input,
inputSizeis a scalar corresponding to the number of features. - For 1-D image sequence input,
inputSizeis vector of two elements[h c], wherehis the image height andcis the number of channels of the image. - For 2-D image sequence input,
inputSizeis vector of three elements[h w c], wherehis the image height,wis the image width, andcis the number of channels of the image. - For 3-D image sequence input,
inputSizeis vector of four elements[h w d c], wherehis the image height,wis the image width,dis the image depth, andcis the number of channels of the image.
To specify the minimum sequence length of the input data, use theMinLength name-value argument.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose Name in quotes.
Example: sequenceInputLayer(12,Name="seq1") creates a sequence input layer with input size 12 and name'seq1'.
MinLength — Minimum sequence length of input data
1 (default) | positive integer
Minimum sequence length of input data, specified as a positive integer. When training or making predictions with the network, if the input data has fewer than MinLength time steps, then the software throws an error.
When you create a network that downsamples data in the time dimension, you must take care that the network supports your training data and any data for prediction. Some deep learning layers require that the input has a minimum sequence length. For example, a 1-D convolution layer requires that the input has at least as many time steps as the filter size.
As time series of sequence data propagates through a network, the sequence length can change. For example, downsampling operations such as 1-D convolutions can output data with fewer time steps than its input. This means that downsampling operations can cause later layers in the network to throw an error because the data has a shorter sequence length than the minimum length required by the layer.
When you train or assemble a network, the software automatically checks that sequences of length 1 can propagate through the network. Some networks might not support sequences of length 1, but can successfully propagate sequences of longer lengths. To check that a network supports propagating your training and expected prediction data, set the MinLength property to a value less than or equal to the minimum length of your data and the expected minimum length of your prediction data.
Tip
To prevent convolution and pooling layers from changing the size of the data, set the Padding option of the layer to "same" or"causal".
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Normalization — Data normalization
"none" (default) | "zerocenter" | "zscore" | "rescale-symmetric" | "rescale-zero-one" | function handle
Data normalization to apply every time data is forward propagated through the input layer, specified as one of the following:
"zerocenter"— Subtract the mean specified by Mean."zscore"— Subtract the mean specified by Mean and divide byStandardDeviation."rescale-symmetric"— Rescale the input to be in the range [-1, 1] using the minimum and maximum values specified by Min and Max, respectively."rescale-zero-one"— Rescale the input to be in the range [0, 1] using the minimum and maximum values specified by Min and Max, respectively."none"— Do not normalize the input data.- function handle — Normalize the data using the specified function. The function must be of the form
Y = f(X), whereXis the input data and the outputYis the normalized data.
If the input data is complex-valued and the SplitComplexInputs option is 0 (false), then the Normalization option must be"zerocenter","zscore", "none", or a function handle. (since R2024a)
Before R2024a: To input complex-valued data into the network, theSplitComplexInputs option must be1 (true).
Tip
The software, by default, automatically calculates the normalization statistics when you use the trainnet function. To save time when training, specify the required statistics for normalization and set the ResetInputNormalization option in trainingOptions to 0 (false).
The software applies normalization to all input elements, including padding values.
The SequenceInputLayer object stores theNormalization property as a character vector or a function handle.
Data Types: char | string | function_handle
NormalizationDimension — Normalization dimension
"auto" (default) | "channel" | "element" | "all"
Normalization dimension, specified as one of the following:
"auto"– If theResetInputNormalizationtraining option is0(false) and you specify any of the normalization statistics (Mean,StandardDeviation,Min, orMax), then normalize over the dimensions matching the statistics. Otherwise, recalculate the statistics at training time and apply channel-wise normalization."channel"– Channel-wise normalization."element"– Element-wise normalization."all"– Normalize all values using scalar statistics.
The SequenceInputLayer object stores theNormalizationDimension property as a character vector.
Mean — Mean for zero-center and z-score normalization
[] (default) | numeric array | numeric scalar
Mean for zero-center and z-score normalization, specified as a numeric array, or empty.
- For vector sequence input,
Meanmust be a InputSize-by-1 vector of means per channel, a numeric scalar, or[]. - For 2-D image sequence input,
Meanmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of means per channel, a numeric scalar, or[]. - For 3-D image sequence input,
Meanmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of means per channel, a numeric scalar, or[].
To specify the Mean property, the Normalization property must be "zerocenter" or "zscore". If Mean is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the mean using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to0.
Mean can be complex-valued. (since R2024a) If Mean is complex-valued, then the SplitComplexInputs option must be 0 (false).
Before R2024a: Split the mean into real and imaginary parts and set split the input data into real and imaginary parts by setting theSplitComplexInputs option to1 (true).
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Complex Number Support: Yes
StandardDeviation — Standard deviation
[] (default) | numeric array | numeric scalar
Standard deviation used for z-score normalization, specified as a numeric array, a numeric scalar, or empty.
- For vector sequence input,
StandardDeviationmust be a InputSize-by-1 vector of standard deviations per channel, a numeric scalar, or[]. - For 2-D image sequence input,
StandardDeviationmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of standard deviations per channel, a numeric scalar, or[]. - For 3-D image sequence input,
StandardDeviationmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of standard deviations per channel, or a numeric scalar.
To specify the StandardDeviation property, the Normalization must be"zscore". If StandardDeviation is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the standard deviation using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to1.
StandardDeviation can be complex-valued. (since R2024a) IfStandardDeviation is complex-valued, then the SplitComplexInputs option must be0 (false).
Before R2024a: Split the standard deviation into real and imaginary parts and set split the input data into real and imaginary parts by setting theSplitComplexInputs option to1 (true).
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Complex Number Support: Yes
Min — Minimum value for rescaling
[] (default) | numeric array | numeric scalar
Minimum value for rescaling, specified as a numeric array, or empty.
- For vector sequence input,
Minmust be a InputSize-by-1 vector of means per channel or a numeric scalar. - For 2-D image sequence input,
Minmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of minima per channel, or a numeric scalar. - For 3-D image sequence input,
Minmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of minima per channel, or a numeric scalar.
To specify the Min property, the Normalization must be"rescale-symmetric" or"rescale-zero-one". If Min is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the minimum value using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to-1and0whenNormalizationis"rescale-symmetric"and"rescale-zero-one", respectively.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Max — Maximum value for rescaling
[] (default) | numeric array | numeric scalar
Maximum value for rescaling, specified as a numeric array, or empty.
- For vector sequence input,
Maxmust be a InputSize-by-1 vector of means per channel or a numeric scalar. - For 2-D image sequence input,
Maxmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of maxima per channel, a numeric scalar, or[]. - For 3-D image sequence input,
Maxmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of maxima per channel, a numeric scalar, or[].
To specify the Max property, the Normalization must be"rescale-symmetric" or"rescale-zero-one". If Max is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the maximum value using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to1.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
SplitComplexInputs — Flag to split input data into real and imaginary components
0 (false) (default) | 1 (true)
Flag to split input data into real and imaginary components specified as one of these values:
0(false) – Do not split input data.1(true) – Split data into real and imaginary components.
When SplitComplexInputs is1, then the layer outputs twice as many channels as the input data. For example, if the input data is complex-valued with numChannels channels, then the layer outputs data with 2*numChannels channels, where channels 1 throughnumChannels contain the real components of the input data and numChannels+1 through2*numChannels contain the imaginary components of the input data. If the input data is real, then channels numChannels+1 through2*numChannels are all zero.
If the input data is complex-valued and SplitComplexInputs is0 (false), then the layer passes the complex-valued data to the next layers. (since R2024a)
Before R2024a: To input complex-valued data into a neural network, theSplitComplexInputs option of the input layer must be 1 (true).
For an example showing how to train a network with complex-valued data, see Train Network with Complex-Valued Data.
Name — Layer name
"" (default) | character vector | string scalar
Layer name, specified as a character vector or a string scalar. For Layer array input, the trainnet and dlnetwork functions automatically assign names to layers with the name "".
The SequenceInputLayer object stores the Name property as a character vector.
Data Types: char | string
Properties
Sequence Input
InputSize — Size of input
positive integer | vector of positive integers
Size of the input, specified as a positive integer or a vector of positive integers.
- For vector sequence input,
InputSizeis a scalar corresponding to the number of features. - For 1-D image sequence input,
InputSizeis vector of two elements[h c], wherehis the image height andcis the number of channels of the image. - For 2-D image sequence input,
InputSizeis vector of three elements[h w c], wherehis the image height,wis the image width, andcis the number of channels of the image. - For 3-D image sequence input,
InputSizeis vector of four elements[h w d c], wherehis the image height,wis the image width,dis the image depth, andcis the number of channels of the image.
To specify the minimum sequence length of the input data, use theMinLength property.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
MinLength — Minimum sequence length of input data
1 (default) | positive integer
Minimum sequence length of input data, specified as a positive integer. When training or making predictions with the network, if the input data has fewer than MinLength time steps, then the software throws an error.
When you create a network that downsamples data in the time dimension, you must take care that the network supports your training data and any data for prediction. Some deep learning layers require that the input has a minimum sequence length. For example, a 1-D convolution layer requires that the input has at least as many time steps as the filter size.
As time series of sequence data propagates through a network, the sequence length can change. For example, downsampling operations such as 1-D convolutions can output data with fewer time steps than its input. This means that downsampling operations can cause later layers in the network to throw an error because the data has a shorter sequence length than the minimum length required by the layer.
When you train or assemble a network, the software automatically checks that sequences of length 1 can propagate through the network. Some networks might not support sequences of length 1, but can successfully propagate sequences of longer lengths. To check that a network supports propagating your training and expected prediction data, set the MinLength property to a value less than or equal to the minimum length of your data and the expected minimum length of your prediction data.
Tip
To prevent convolution and pooling layers from changing the size of the data, set the Padding option of the layer to "same" or "causal".
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Normalization — Data normalization
"none" (default) | "zerocenter" | "zscore" | "rescale-symmetric" | "rescale-zero-one" | function handle
Data normalization to apply every time data is forward propagated through the input layer, specified as one of the following:
"zerocenter"— Subtract the mean specified by Mean."zscore"— Subtract the mean specified by Mean and divide by StandardDeviation."rescale-symmetric"— Rescale the input to be in the range [-1, 1] using the minimum and maximum values specified by Min and Max, respectively."rescale-zero-one"— Rescale the input to be in the range [0, 1] using the minimum and maximum values specified by Min and Max, respectively."none"— Do not normalize the input data.- function handle — Normalize the data using the specified function. The function must be of the form
Y = f(X), whereXis the input data and the outputYis the normalized data.
If the input data is complex-valued and theSplitComplexInputs option is 0 (false), then the Normalization option must be"zerocenter", "zscore","none", or a function handle. (since R2024a)
Before R2024a: To input complex-valued data into the network, the SplitComplexInputs option must be 1 (true).
Tip
The software, by default, automatically calculates the normalization statistics when you use the trainnet function. To save time when training, specify the required statistics for normalization and set the ResetInputNormalization option in trainingOptions to 0 (false).
The software applies normalization to all input elements, including padding values.
The SequenceInputLayer object stores this property as a character vector or a function handle.
Data Types: char | string | function_handle
NormalizationDimension — Normalization dimension
"auto" (default) | "channel" | "element" | "all"
Normalization dimension, specified as one of the following:
"auto"– If theResetInputNormalizationtraining option is0(false) and you specify any of the normalization statistics (Mean,StandardDeviation,Min, orMax), then normalize over the dimensions matching the statistics. Otherwise, recalculate the statistics at training time and apply channel-wise normalization."channel"– Channel-wise normalization."element"– Element-wise normalization."all"– Normalize all values using scalar statistics.
The SequenceInputLayer object stores this property as a character vector.
Mean — Mean for zero-center and z-score normalization
[] (default) | numeric array | numeric scalar
Mean for zero-center and z-score normalization, specified as a numeric array, or empty.
- For vector sequence input,
Meanmust be a InputSize-by-1 vector of means per channel, a numeric scalar, or[]. - For 2-D image sequence input,
Meanmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of means per channel, a numeric scalar, or[]. - For 3-D image sequence input,
Meanmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of means per channel, a numeric scalar, or[].
To specify the Mean property, theNormalization property must be"zerocenter" or "zscore". IfMean is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the mean using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to0.
Mean can be complex-valued. (since R2024a) IfMean is complex-valued, then theSplitComplexInputs option must be 0 (false).
Before R2024a: Split the mean into real and imaginary parts and split the input data into real and imaginary parts by setting theSplitComplexInputs option to1 (true).
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Complex Number Support: Yes
StandardDeviation — Standard deviation
[] (default) | numeric array | numeric scalar
Standard deviation used for z-score normalization, specified as a numeric array, a numeric scalar, or empty.
- For vector sequence input,
StandardDeviationmust be a InputSize-by-1 vector of standard deviations per channel, a numeric scalar, or[]. - For 2-D image sequence input,
StandardDeviationmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of standard deviations per channel, a numeric scalar, or[]. - For 3-D image sequence input,
StandardDeviationmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of standard deviations per channel, or a numeric scalar.
To specify the StandardDeviation property, the Normalization must be"zscore". If StandardDeviation is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the standard deviation using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to1.
StandardDeviation can be complex-valued. (since R2024a) If StandardDeviation is complex-valued, then the SplitComplexInputs option must be 0 (false).
Before R2024a: Split the standard deviation into real and imaginary parts and split the input data into real and imaginary parts by setting theSplitComplexInputs option to 1 (true).
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Complex Number Support: Yes
Min — Minimum value for rescaling
[] (default) | numeric array | numeric scalar
Minimum value for rescaling, specified as a numeric array, or empty.
- For vector sequence input,
Minmust be a InputSize-by-1 vector of means per channel or a numeric scalar. - For 2-D image sequence input,
Minmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of minima per channel, or a numeric scalar. - For 3-D image sequence input,
Minmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of minima per channel, or a numeric scalar.
To specify the Min property, theNormalization must be"rescale-symmetric" or"rescale-zero-one". If Min is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the minimum value using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to-1and0whenNormalizationis"rescale-symmetric"and"rescale-zero-one", respectively.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Max — Maximum value for rescaling
[] (default) | numeric array | numeric scalar
Maximum value for rescaling, specified as a numeric array, or empty.
- For vector sequence input,
Maxmust be a InputSize-by-1 vector of means per channel or a numeric scalar. - For 2-D image sequence input,
Maxmust be a numeric array of the same size as InputSize, a 1-by-1-by-InputSize(3)array of maxima per channel, a numeric scalar, or[]. - For 3-D image sequence input,
Maxmust be a numeric array of the same size as InputSize, a 1-by-1-by-1-by-InputSize(4)array of maxima per channel, a numeric scalar, or[].
To specify the Max property, theNormalization must be"rescale-symmetric" or"rescale-zero-one". If Max is [], then the software automatically sets the property at training or initialization time:
- The
trainnetfunction calculates the maximum value using the training data, ignoring any padding values, and uses the resulting value. - The
initializefunction and thedlnetworkfunction when theInitializeoption is1(true) sets the property to1.
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
SplitComplexInputs — Flag to split input data into real and imaginary components
0 (false) (default) | 1 (true)
This property is read-only.
Flag to split input data into real and imaginary components specified as one of these values:
0(false) – Do not split input data.1(true) – Split data into real and imaginary components.
When SplitComplexInputs is 1, then the layer outputs twice as many channels as the input data. For example, if the input data is complex-valued with numChannels channels, then the layer outputs data with 2*numChannels channels, where channels 1 through numChannels contain the real components of the input data andnumChannels+1 through 2*numChannels contain the imaginary components of the input data. If the input data is real, then channelsnumChannels+1 through 2*numChannels are all zero.
If the input data is complex-valued andSplitComplexInputs is 0 (false), then the layer passes the complex-valued data to the next layers. (since R2024a)
Before R2024a: To input complex-valued data into a neural network, the SplitComplexInputs option of the input layer must be1 (true).
For an example showing how to train a network with complex-valued data, see Train Network with Complex-Valued Data.
Layer
Layer name, specified as a character vector or string scalar. For Layer array input, the trainnet anddlnetwork functions automatically assign names to layers with the name "".
The SequenceInputLayer object stores this property as a character vector.
Data Types: char | string
NumInputs — Number of inputs
0 (default)
This property is read-only.
Number of inputs of the layer. The layer has no inputs.
Data Types: double
InputNames — Input names
{} (default)
This property is read-only.
Input names of the layer. The layer has no inputs.
Data Types: cell
NumOutputs — Number of outputs
1 (default)
This property is read-only.
Number of outputs from the layer, returned as 1. This layer has a single output only.
Data Types: double
OutputNames — Output names
{'out'} (default)
This property is read-only.
Output names, returned as {'out'}. This layer has a single output only.
Data Types: cell
Examples
Create Sequence Input Layer
Create a sequence input layer with an input size of 12.
layer = sequenceInputLayer(12)
layer = SequenceInputLayer with properties:
Name: ''
InputSize: 12
MinLength: 1
SplitComplexInputs: 0Hyperparameters Normalization: 'none' NormalizationDimension: 'auto'
Include a sequence input layer in a Layer array.
inputSize = 12; numHiddenUnits = 100; numClasses = 9;
layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]
layers = 4x1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 dimensions
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected 9 fully connected layer
4 '' Softmax softmaxCreate Sequence Input Layer for Image Sequences
Create a sequence input layer for sequences of 224-224 RGB images with the name 'seq1'.
layer = sequenceInputLayer([224 224 3], 'Name', 'seq1')
layer = SequenceInputLayer with properties:
Name: 'seq1'
InputSize: [224 224 3]
MinLength: 1
SplitComplexInputs: 0Hyperparameters Normalization: 'none' NormalizationDimension: 'auto'
Train Network for Sequence Classification
Train a deep learning LSTM network for sequence-to-label classification.
Load the example data from WaveformData.mat. The data is a numObservations-by-1 cell array of sequences, where numObservations is the number of sequences. Each sequence is a numTimeSteps-by-numChannels numeric array, where numTimeSteps is the number of time steps of the sequence and numChannels is the number of channels of the sequence.
Visualize some of the sequences in a plot.
numChannels = size(data{1},2);
idx = [3 4 5 12]; figure tiledlayout(2,2) for i = 1:4 nexttile stackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))end
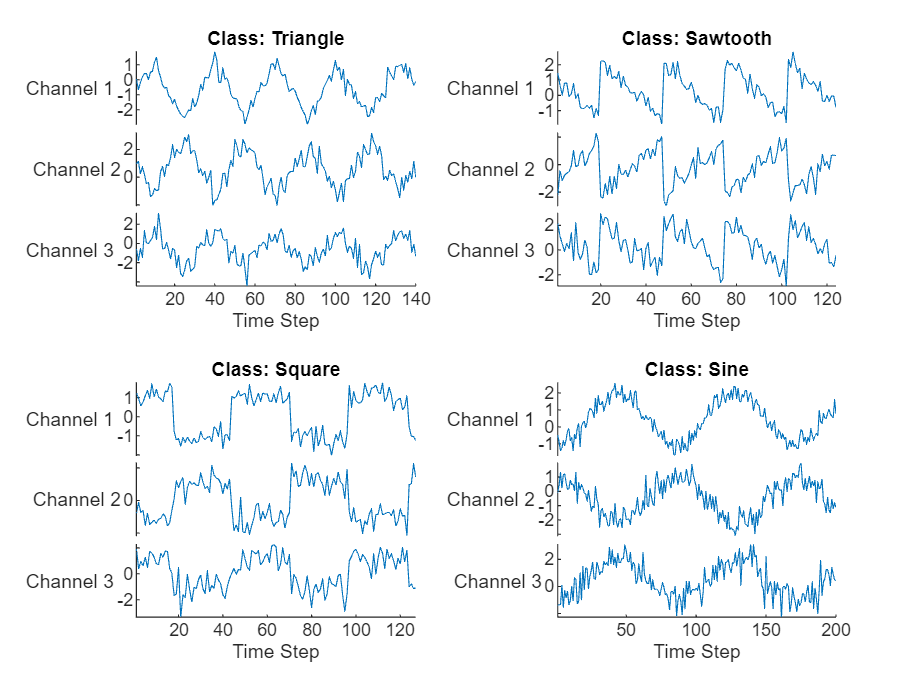
View the class names.
classNames = categories(labels)
classNames = 4×1 cell {'Sawtooth'} {'Sine' } {'Square' } {'Triangle'}
Set aside data for testing. Partition the data into a training set containing 90% of the data and a test set containing the remaining 10% of the data. To partition the data, use the trainingPartitions function, attached to this example as a supporting file. To access this file, open the example as a live script.
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain);
XTest = data(idxTest); TTest = labels(idxTest);
Define the LSTM network architecture. Specify the input size as the number of channels of the input data. Specify an LSTM layer to have 120 hidden units and to output the last element of the sequence. Finally, include a fully connected with an output size that matches the number of classes, followed by a softmax layer.
numHiddenUnits = 120; numClasses = numel(categories(TTrain));
layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]
layers = 4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmaxSpecify the training options. Train using the Adam solver with a learn rate of 0.01 and a gradient threshold of 1. Set the maximum number of epochs to 200 and shuffle every epoch. The software, by default, trains on a GPU if one is available. Using a GPU requires Parallel Computing Toolbox and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
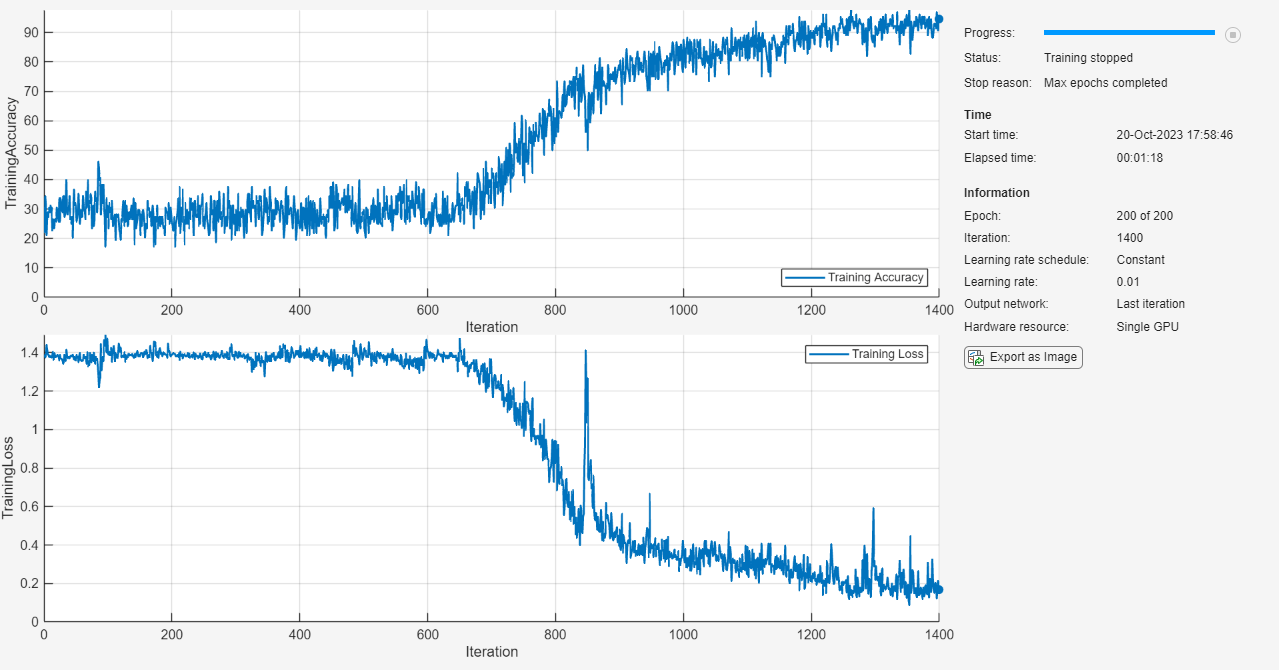
options = trainingOptions("adam", ... MaxEpochs=200, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Metrics="accuracy", ... Plots="training-progress");
Train the LSTM network using the trainnet function. For classification, use cross-entropy loss.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);
Classify the test data. Specify the same mini-batch size used for training.
scores = minibatchpredict(net,XTest); YTest = scores2label(scores,classNames);
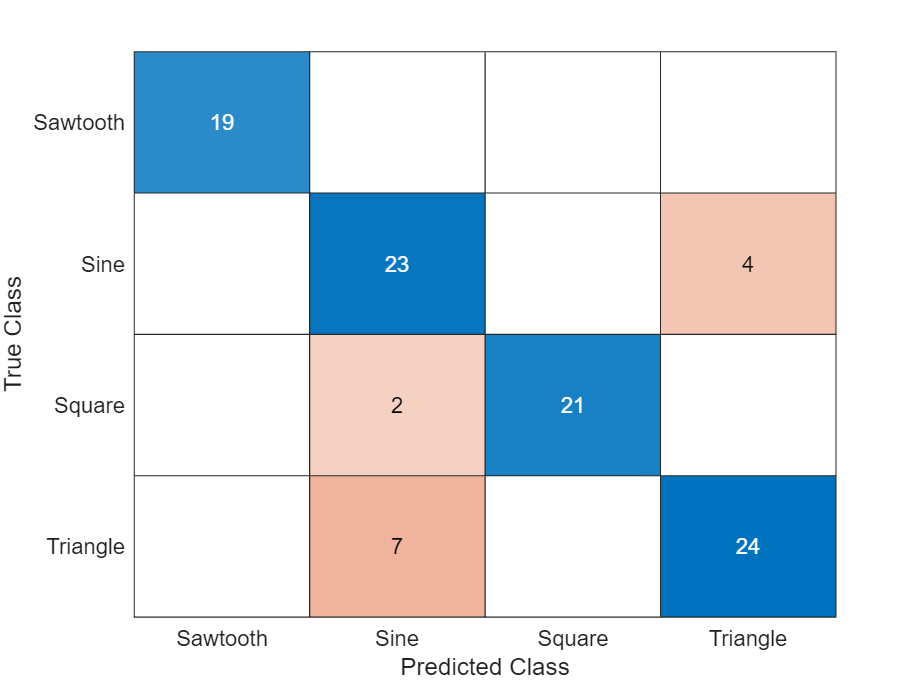
Calculate the classification accuracy of the predictions.
acc = mean(YTest == TTest)
Display the classification results in a confusion chart.
figure confusionchart(TTest,YTest)
Classification LSTM Networks
To create an LSTM network for sequence-to-label classification, create a layer array containing a sequence input layer, an LSTM layer, a fully connected layer, and a softmax layer.
Set the size of the sequence input layer to the number of features of the input data. Set the size of the fully connected layer to the number of classes. You do not need to specify the sequence length.
For the LSTM layer, specify the number of hidden units and the output mode "last".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
For an example showing how to train an LSTM network for sequence-to-label classification and classify new data, see Sequence Classification Using Deep Learning.
To create an LSTM network for sequence-to-sequence classification, use the same architecture as for sequence-to-label classification, but set the output mode of the LSTM layer to "sequence".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
Regression LSTM Networks
To create an LSTM network for sequence-to-one regression, create a layer array containing a sequence input layer, an LSTM layer, and a fully connected layer.
Set the size of the sequence input layer to the number of features of the input data. Set the size of the fully connected layer to the number of responses. You do not need to specify the sequence length.
For the LSTM layer, specify the number of hidden units and the output mode "last".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1;
layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses)];
To create an LSTM network for sequence-to-sequence regression, use the same architecture as for sequence-to-one regression, but set the output mode of the LSTM layer to "sequence".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1;
layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses)];
For an example showing how to train an LSTM network for sequence-to-sequence regression and predict on new data, see Sequence-to-Sequence Regression Using Deep Learning.
Deeper LSTM Networks
You can make LSTM networks deeper by inserting extra LSTM layers with the output mode "sequence" before the LSTM layer. To prevent overfitting, you can insert dropout layers after the LSTM layers.
For sequence-to-label classification networks, the output mode of the last LSTM layer must be "last".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
For sequence-to-sequence classification networks, the output mode of the last LSTM layer must be "sequence".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Algorithms
Layer Output Formats
Layers in a layer array or layer graph pass data to subsequent layers as formatted dlarray objects. The format of a dlarray object is a string of characters in which each character describes the corresponding dimension of the data. The formats consist of one or more of these characters:
"S"— Spatial"C"— Channel"B"— Batch"T"— Time"U"— Unspecified
For example, you can represent vector sequence data as a 3-D array, in which the first dimension corresponds to the channel dimension, the second dimension corresponds to the batch dimension, and the third dimension corresponds to the time dimension. This representation is in the format "CBT" (channel, batch, time).
The input layer of a network specifies the layout of the data that the network expects. If you have data in a different layout, then specify the layout using the InputDataFormats training option.
This table describes the expected layout of data for a neural network with a sequence input layer.
| Data | Layout |
|---|---|
| Vector sequences | dlnetwork object functions —t_-by-c matrices, where t is the sequence length and_c is the number of features of the sequences. |
| 1-D image sequences | _h_-by-_c_-by-t arrays, where h and c correspond to the height and number of channels of the images, respectively, and t is the sequence length. |
| 2-D image sequences | _h_-by-w_-by-c_-by-t arrays, where h, w, and_c correspond to the height, width, and number of channels of the images, respectively, and_t is the sequence length. |
| 3-D image sequences | _h_-by-_w_-by-_d_-by-_c_-by-t, where h, w,d, and c correspond to the height, width, depth, and number of channels of the 3-D images, respectively, and t is the sequence length. |
Complex Numbers
For complex-valued input to the neural network, when the SplitComplexIputs is 0 (false), the layer passes complex-valued data to subsequent layers. (since R2024a)
Before R2024a: To input complex-valued data into a neural network, the SplitComplexInputs option of the input layer must be 1 (true).
If the input data is complex-valued and the SplitComplexInputs option is 0 (false), then the Normalization option must be "zerocenter", "zscore", "none", or a function handle. The Mean and StandardDeviation properties of the layer also support complex-valued data for the "zerocenter" and "zscore" normalization options.
For an example showing how to train a network with complex-valued data, see Train Network with Complex-Valued Data.
Extended Capabilities
C/C++ Code Generation
Generate C and C++ code using MATLAB® Coder™.
- Code generation does not support passing
dlarrayobjects with unspecified (U) dimensions to this layer. - For vector sequence inputs, the number of features must be a constant during code generation.
- You can generate C or C++ code that does not depend on any deep learning third-party libraries for input data with zero, one, two, or three spatial dimensions.
- For ARM® Compute and Intel® MKL-DNN, the input data must contain either zero or two spatial dimensions.
- Code generation does not support
'Normalization'specified using a function handle. - Code generation does not support complex input and does not support
'SplitComplexInputs'option.
GPU Code Generation
Generate CUDA® code for NVIDIA® GPUs using GPU Coder™.
Usage notes and limitations:
- Code generation does not support passing
dlarrayobjects with unspecified (U) dimensions to this layer. - To generate CUDA® or C++ code by using GPU Coder™, you must first construct and train a deep neural network. Once the network is trained and evaluated, you can configure the code generator to generate code and deploy the convolutional neural network on platforms that use NVIDIA® or ARM GPU processors. For more information, see Deep Learning with GPU Coder (GPU Coder).
- You can generate CUDA code that is independent of deep learning libraries for input data with zero, one, two, or three spatial dimensions.
- You can generate code that takes advantage of the NVIDIA CUDA deep neural network library (cuDNN), or the NVIDIA TensorRT™ high performance inference library.
- The cuDNN library supports vector and 2-D image sequences. The TensorRT library support only vector input sequences.
- All spatial and channel dimensions of the input must be constant during code generation. For example,
- For vector sequence inputs, the number of features must be a constant during code generation.
- For image sequence inputs, the height, width, and the number of channels must be a constant during code generation.
- Code generation does not support
'Normalization'specified using a function handle. - Code generation does not support complex input and does not support
'SplitComplexInputs'option.
Version History
Introduced in R2017b
R2024a: Complex-valued outputs
For complex-valued input to the neural network, when the SplitComplexIputs is 0 (false), the layer passes complex-valued data to subsequent layers.
If the input data is complex-valued and the SplitComplexInputs option is0 (false), then theNormalization option must be "zerocenter","zscore", "none", or a function handle. TheMean and StandardDeviation properties of the layer also support complex-valued data for the "zerocenter" and"zscore" normalization options.
R2024a: DAGNetwork and SeriesNetwork objects are not recommend
Starting in R2024a, DAGNetwork and SeriesNetwork objects are not recommended, use dlnetwork objects instead.
There are no plans to remove support for DAGNetwork andSeriesNetwork objects. However, dlnetwork objects have these advantages and are recommended instead:
dlnetworkobjects are a unified data type that supports network building, prediction, built-in training, visualization, compression, verification, and custom training loops.dlnetworkobjects support a wider range of network architectures that you can create or import from external platforms.- The trainnet function supports
dlnetworkobjects, which enables you to easily specify loss functions. You can select from built-in loss functions or specify a custom loss function. - Training and prediction with
dlnetworkobjects is typically faster thanLayerGraphandtrainNetworkworkflows.
To convert a trained DAGNetwork or SeriesNetwork object to a dlnetwork object, use the dag2dlnetwork function.
Sequence input layers in a dlnetwork object expect data in a different layout when compared to sequence input layers inDAGNetwork or SeriesNetwork objects. For vector sequence input, DAGNetwork andSeriesNetwork object functions expect_c_-by-t matrices, where_c_ is the number of features of the sequences and_t_ is the sequence length. For vector sequence input,dlnetwork object functions expect_t_-by-c matrices, where_t_ is the sequence length and c is the number of features of the sequences.
R2020a: trainNetwork ignores padding values when calculating normalization statistics
Starting in R2020a, trainNetwork ignores padding values when calculating normalization statistics. This means that the Normalization option in thesequenceInputLayer now makes training invariant to data operations, for example, 'zerocenter' normalization now implies that the training results are invariant to the mean of the data.
If you train on padded sequences, then the calculated normalization factors may be different in earlier versions and can produce different results.
R2019b: sequenceInputLayer, by default, uses channel-wise normalization for zero-center normalization
Starting in R2019b, sequenceInputLayer, by default, uses channel-wise normalization for zero-center normalization. In previous versions, this layer uses element-wise normalization. To reproduce this behavior, set the NormalizationDimension option of this layer to'element'.