Optimize Datastores for Deep Learning Performance - MATLAB & Simulink (original) (raw)
Datastores enable you to conveniently access and modify your deep learning data sets. When using datastores for training or prediction, you can use the processes in this topic to maximize performance. For an introduction to using datastores for deep learning, see Datastores for Deep Learning.
Specify Read Size and Mini-Batch Size
A datastore can return any number of rows (observations) for each call to read. Functions, such as trainnet,minibatchpredict, and minibatchqueue, that accept datastores and support specifying aMiniBatchSize argument call read as many times as is necessary to form complete mini-batches of data. As these functions form mini-batches, they use internal queues in memory to store read data. For example, if a datastore consistently returns 64 rows per call to read andMiniBatchSize is 128, then the function requires two calls to read to form each mini-batch of data.
For best runtime performance, configure datastores so that the number of observations returned by read is equal to the MiniBatchSize. For datastores that have a ReadSize property, setReadSize to change the number of observations returned by the datastore for each call to read.
Use transform to Preprocess Images
If your data needs preprocessing, use the transform function and specify the underlying datastore and the preprocessing transformation as inputs. Using the ReadFcn property of imageDatastore to preprocess images is not recommended, and can slow down reading images. For more information about applying data transformations when reading from a datastore, see Transform Datastores.
Preprocess Data in the Background or in Parallel
To speed up training, you can fetch and preprocess training data from a datastore in the background or in parallel during training.
As shown in this diagram, fetching, preprocessing, and performing training computations in serial can result in downtime where your GPU (or other hardware) utilization is low. Using the background pool or parallel workers to fetch and preprocess the next batch of training data while your GPU is processing the current batch can increase hardware utilization, resulting in faster training. Use background or parallel preprocessing if your training data requires significant preprocessing, such as if you are manipulating large images.
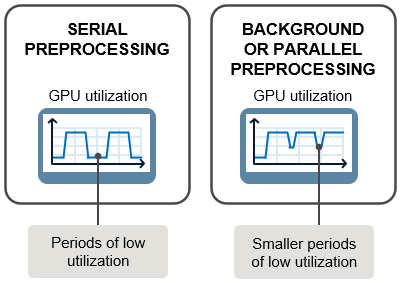
Background and parallel preprocessing use parallel pools to fetch and preprocess data during training. Background preprocessing uses the backgroundPool, which is a thread-based environment, and parallel preprocessing uses the current parallel pool or, if no pool is open, starts a pool using the default cluster profile which is a process-based environment by default. Thread-based pools have several advantages over process-based pools, and you should therefore use background preprocessing when possible. However, if your preprocessing is not supported on threads, or if you need to control the number of workers in the pool, then use parallel preprocessing. For more information about thread-based and process-based environments, see Choose Between Thread-Based and Process-Based Environments (Parallel Computing Toolbox).
To preprocess data in the background or in parallel, use one of these options:
- For built-in training, specify the
PreprocessingEnvironmentoption as"background"or"parallel"using the trainingOptions function. - For custom training loops, set the
PreprocessingEnvironmentproperty of your minibatchqueue to"background"or"parallel".
Setting the PreprocessingEnvironment option to"parallel" is supported for local parallel pools only and requires Parallel Computing Toolbox™.
To use the "background" or "parallel" options, the input datastore must be subsettable or partitionable. Custom datastores must implement the matlab.io.datastore.Subsettable class.
Parallel Training
Specify parallel or multi-GPU training using the ExecutionEnvironment name-value argument of trainingOptions. Training in parallel or using single or multiple GPUs requires Parallel Computing Toolbox.
Many built-in datastores already support parallel and multi-GPU training. Using thetransform and combine functions with built-in datastores frequently maintains support for parallel and multi-GPU training.
To use a datastore for parallel training or multi-GPU training, it must be subsettable or partitionable. To determine if a datastore is subsettable or partitionable, use the functions isSubsettable and isPartitionable, respectively.
If you need to create a custom datastore that supports parallel or multi-GPU training, your datastore object should implement the matlab.io.datastore.Subsettable class.
When training in parallel, datastores do not support specifying the Shuffle name-value argument of trainingOptions as "never".
You can further speed up parallel training by preprocessing training data in the background. For more information, see Preprocess Data in the Background or in Parallel.
Note
Use parallel training and background preprocessing when your training data set is large. These methods add overheads that might slow down training when your data set is small.
Use randomPatchExtractionDatastore
If you have Image Processing Toolbox™, then the randomPatchExtractionDatastore (Image Processing Toolbox) provides an alternate solution to associating image-based data between ImageDatastore,PixelLabelDatastore, and TransformedDatastore objects. A randomPatchExtractionDatastore has these advantages over associating data using the combine function.
- Improves performance by caching images
- Supports parallel training
- Can extract patches from both 2-D and 3-D data without requiring you to implement a custom cropping operation using
transformandcombine - Can generate multiple patches per image per mini-batch without requiring you to define a custom concatenation operation using
transform. - Supports efficient conversion between categorical and numeric data when applying image transforms to categorical data
See Also
transform | combine | read | trainnet | trainingOptions | dlnetwork
Related Examples
- Prepare Datastore for Image-to-Image Regression
- Classify Text Data Using Convolutional Neural Network