Large-scale exploration of growth inhibition caused by overexpression of genomic fragments in Saccharomyces cerevisiae (original) (raw)
- Method
- Open access
- Published: 31 August 2004
- Gwenaël Badis1,2,
- Cécile Fairhead1,
- Emmanuel Talla1,3,
- Florence Hantraye2,
- Emmanuelle Fabre1,
- Gilles Fischer1,
- Christophe Hennequin1,4,
- Romain Koszul1,
- Ingrid Lafontaine1,
- Odile Ozier-Kalogeropoulos1,
- Miria Ricchetti1,5,
- Guy-Franck Richard1,
- Agnès Thierry1 &
- …
- Bernard Dujon1
Genome Biology volume 5, Article number: R72 (2004)Cite this article
- 9028 Accesses
- 32 Citations
- 1 Altmetric
- Metrics details
Abstract
We have screened the genome of Saccharomyces cerevisiae for fragments that confer a growth-retardation phenotype when overexpressed in a multicopy plasmid with a tetracycline-regulatable (Tet-off) promoter. We selected 714 such fragments with a mean size of 700 base-pairs out of around 84,000 clones tested. These include 493 in-frame open reading frame fragments corresponding to 454 distinct genes (of which 91 are of unknown function), and 162 out-of-frame, antisense and intergenic genomic fragments, representing the largest collection of toxic inserts published so far in yeast.
Background
The complete genome sequences of various eukaryotic model organisms such as Saccharomyces cerevisiae, Caenorhabditis elegans, Drosophila melanogaster, Arabidopsis thaliana and Schizosaccharomyces pombe, have revealed a large number of novel genes of unknown functions. In S. cerevisiae, for example, around 1,800 genes (of the total of around 5,800) encode proteins that so far remain functionally uncharacterized (compilation from Saccharomyces Genome Database (SGD) [[1](/articles/10.1186/gb-2004-5-9-r72#ref-CR1 " Saccharomyces Genome Database. [ http://www.yeastgenome.org
]")\] April 2004). Since the completion of its DNA sequence \[[2](/articles/10.1186/gb-2004-5-9-r72#ref-CR2 "Goffeau A, Barrell BG, Bussey H, Davis RW, Dujon B, Feldmann H, Galibert F, Hoheisel JD, Jacq C, Johnston M, et al: Life with 6000 genes. Science. 1996, 274: 546-567. 10.1126/science.274.5287.546.")\], the genome of _S. cerevisiae_ has been extensively studied, serving as a test case for novel and important developments in functional genomics. Such developments include transposon-mediated gene inactivation and tagging \[[3](/articles/10.1186/gb-2004-5-9-r72#ref-CR3 "Ross-Macdonald P, Coelho PS, Roemer T, Agarwal S, Kumar A, Jansen R, Cheung KH, Sheehan A, Symoniatis D, Umansky L, et al: Large-scale analysis of the yeast genome by transposon tagging and gene disruption. Nature. 1999, 402: 413-418. 10.1038/46558.")\], the analysis of gene-expression networks through partial or complete transcriptome studies \[[4](/articles/10.1186/gb-2004-5-9-r72#ref-CR4 "Velculescu VE, Zhang L, Zhou W, Vogelstein J, Basrai MA, Bassett DE, Hieter P, Vogelstein B, Kinzler KW: Characterization of the yeast transcriptome. Cell. 1997, 88: 243-251. 10.1016/S0092-8674(00)81845-0.")–[6](/articles/10.1186/gb-2004-5-9-r72#ref-CR6 "Le Crom S, Devaux F, Marc P, Zhang X, Moye-Rowley WS, Jacq C: New insights into the pleiotropic drug resistance network from genome-wide characterization of the YRR1 transcription factor regulation system. Mol Cell Biol. 2002, 22: 2642-2649. 10.1128/MCB.22.8.2642-2649.2002.")\], two-hybrid screening \[[7](/articles/10.1186/gb-2004-5-9-r72#ref-CR7 "Fromont-Racine M, Rain JC, Legrain P: Toward a functional analysis of the yeast genome through exhaustive two-hybrid screens. Nat Genet. 1997, 16: 277-282. 10.1038/ng0797-277.")–[9](/articles/10.1186/gb-2004-5-9-r72#ref-CR9 "Ito T, Chiba T, Ozawa R, Yoshida M, Hattori M, Sakaki Y: A comprehensive two-hybrid analysis to explore the yeast protein interactome. Proc Natl Acad Sci USA. 2001, 98: 4569-4574. 10.1073/pnas.061034498.")\], protein-complex purification \[[10](/articles/10.1186/gb-2004-5-9-r72#ref-CR10 "Gavin AC, Bosche M, Krause R, Grandi P, Marzioch M, Bauer A, Schultz J, Rick JM, Michon AM, Cruciat CM, et al: Functional organization of the yeast proteome by systematic analysis of protein complexes. Nature. 2002, 415: 141-147. 10.1038/415141a."), [11](/articles/10.1186/gb-2004-5-9-r72#ref-CR11 "Ho Y, Gruhler A, Heilbut A, Bader GD, Moore L, Adams SL, Millar A, Taylor P, Bennett K, Boutilier K, et al: Systematic identification of protein complexes in Saccharomyces cerevisiae by mass spectrometry. Nature. 2002, 415: 180-183. 10.1038/415180a.")\], two-dimensional gel protein identification \[[12](/articles/10.1186/gb-2004-5-9-r72#ref-CR12 "Perrot M, Sagliocco F, Mini T, Monribot C, Schneider U, Shevchenko A, Mann M, Jeno P, Boucherie H: Two-dimensional gel protein database of Saccharomyces cerevisiae (update 1999). Electrophoresis. 1999, 20: 2280-2298. 10.1002/(SICI)1522-2683(19990801)20:11<2280::AID-ELPS2280>3.0.CO;2-Q.")\], proteome qualitative analysis by protein microarrays (see review in \[[13](/articles/10.1186/gb-2004-5-9-r72#ref-CR13 "Zhu H, Bilgin M, Snyder M: Proteomics. Annu Rev Biochem. 2003, 72: 783-812. 10.1146/annurev.biochem.72.121801.161511.")\]) and protein abundance measurements after _in situ_ gene tagging \[[14](/articles/10.1186/gb-2004-5-9-r72#ref-CR14 "Ghaemmaghami S, Huh WK, Bower K, Howson RW, Belle A, Dephoure N, O'Shea EK, Weissman JS: Global analysis of protein expression in yeast. Nature. 2003, 425: 737-741. 10.1038/nature02046.")\]. Even intergenic regions have been studied using microarray technology to characterize transcription-factor-binding sites and to map replication origins or recombination hotspots \[[15](/articles/10.1186/gb-2004-5-9-r72#ref-CR15 "Wyrick JJ, Aparicio JG, Chen T, Barnett JD, Jennings EG, Young RA, Bell SP, Aparicio OM: Genome-wide distribution of ORC and MCM proteins in S. cerevisiae: high-resolution mapping of replication origins. Science. 2001, 294: 2357-2360. 10.1126/science.1066101."), [16](/articles/10.1186/gb-2004-5-9-r72#ref-CR16 "Raghuraman MK, Winzeler EA, Collingwood D, Hunt S, Wodicka L, Conway A, Lockhart DJ, Davis RW, Brewer BJ, Fangman WL: Replication dynamics of the yeast genome. Science. 2001, 294: 115-121. 10.1126/science.294.5540.115.")\] (see also \[[17](/articles/10.1186/gb-2004-5-9-r72#ref-CR17 "Kumar A, Snyder M: Emerging technologies in yeast genomics. Nat Rev Genet. 2001, 2: 302-312. 10.1038/35066084.")\] for a review). Following a large cooperative effort between European and American labs, a nearly complete collection of deletion mutants of all yeast protein-coding genes is now available \[[18](/articles/10.1186/gb-2004-5-9-r72#ref-CR18 "Lucau-Danila A, Wysocki R, Roganti T, Foury F: Systematic disruption of 456 ORFs in the yeast Saccharomyces cerevisiae. Yeast. 2000, 16: 547-552. 10.1002/(SICI)1097-0061(200004)16:6<547::AID-YEA552>3.0.CO;2-2.")–[20](/articles/10.1186/gb-2004-5-9-r72#ref-CR20 "EUROSCARF index. [
http://www.uni-frankfurt.de/fb15/mikro/euroscarf
]")\], which offers the possibility of systematically screening numerous phenotypes, including synthetic lethals \[[21](/articles/10.1186/gb-2004-5-9-r72#ref-CR21 "Giaever G, Chu AM, Ni L, Connelly C, Riles L, Veronneau S, Dow S, Lucau-Danila A, Anderson K, Andre B, et al: Functional profiling of the Saccharomyces cerevisiae genome. Nature. 2002, 418: 387-391. 10.1038/nature00935.")–[23](/articles/10.1186/gb-2004-5-9-r72#ref-CR23 "Tong AH, Lesage G, Bader GD, Ding H, Xu H, Xin X, Young J, Berriz GF, Brost RL, Chang M, et al: Global mapping of the yeast genetic interaction network. Science. 2004, 303: 808-813. 10.1126/science.1091317.")\], in search of novel gene functions.As a complement to gene inactivation, phenotypic changes resulting from gene overexpression may also be informative of gene functions. Indeed, in a number of cases, such as genes encoding cytoskeletal proteins or protein kinases and phosphatases, overexpression may lead to a lethal phenotype (see [24] for a review). The overexpression approach is complementary to the loss-of-function approach, as it leads to dominant phenotypes even in the presence of the wild-type gene, thus allowing the study of genes for which no loss-of-function mutants can be obtained. Overexpression of gene fragments can be equivalent to 'dominant negative mutation' in which the fragment disrupts the activity of the wild-type gene [25]. Overexpression can also activate specific pathways, leading to deleterious phenotypes: examples include genes involved in the yeast pheromone response pathway, such as STE4, STE11 and STE12 (see [24, 26] and references therein). In other cases, specific effects are not known, but the region responsible for toxicity has been identified. For example, lethality upon overexpression of Rap1p depends on the presence of the DNA-binding domain and an adjacent region [27]. In general, however, unless the domain structure of the protein is well understood, one cannot predict which segment(s) of it would act as a dominant mutant when overexpressed.
Several yeast cDNA libraries have been screened for lethal or impaired growth phenotypes upon overexpression under the control of the GAL1 or GAL10 promoters on centromeric or multicopy plasmids [28–30]. Other libraries of random genomic DNA have also been screened for toxicity upon overexpression from the same promoters [24, 26]. Whereas the four earlier studies each identified only a few genes (from 1 to 24 each, making a grand total of 43), Stevenson et al. [30] identified 185 genes (20 of which were shared with earlier work) that cause impaired growth when overexpressed.
In the work reported here, we have screened the yeast genome with the aim of characterizing a list of fragments whose overexpression confers growth impairment. To do this, we constructed a yeast genomic library in a multicopy plasmid vector in which transcription is driven by a chimeric tetO-CYC1 promoter [31]. Random genomic inserts of a mean size of 700 base-pairs (bp) were overexpressed in yeast as translational fusions using the plasmid-borne initiation codon. Out of around 84,000 clones tested, we have identified the largest collection yet of toxic overexpressed fragments in yeast: 714 showed overexpression-dependent lethality or various degrees of growth impairments, identifying 454 protein-coding genes (91 of which are of unknown functions), and a variety of intergenic or other regions.
Results
Screening the library of yeast random genomic fragments for toxic phenotypes
We have analyzed a total of 84,086 independent yeast transformants, each of which contains a random fragment of the yeast genome placed under the control of a doxycyclin-repressible promoter (Figure 1a,1b). Effects on growth or survival were monitored by spotting serial dilutions of the transformants in the presence and absence of doxycyclin (uninduced and overexpression conditions respectively, Figure 1c). Phenotypes were recorded using numerical values from 0 to 3 (Figure 2): value 3 was assigned to normal growth (similar to non-toxic control), 2 and 1 were assigned to intermediate growth levels (less abundant and/or smaller-sized colonies), and 0 was assigned to complete or almost complete absence of colonies (comparable to the toxic control on the same plate). We have retained 714 clones (0.85% of total) that show impaired growth in overexpression conditions (Table 1). Among these, 112 also show a slight or severe growth reduction (level 2 for 77 cases, or level 1 for 35 cases, respectively) in unexpressed conditions. Proof that the observed growth defects were caused by the presence of the plasmid rather than an accidental mutation in the clone was directly demonstrated by the recovery of the wild-type phenotype after plasmid loss using selection for resistance to 5-fluoroorotic acid (5-FOA) (Figure 2).
Figure 1
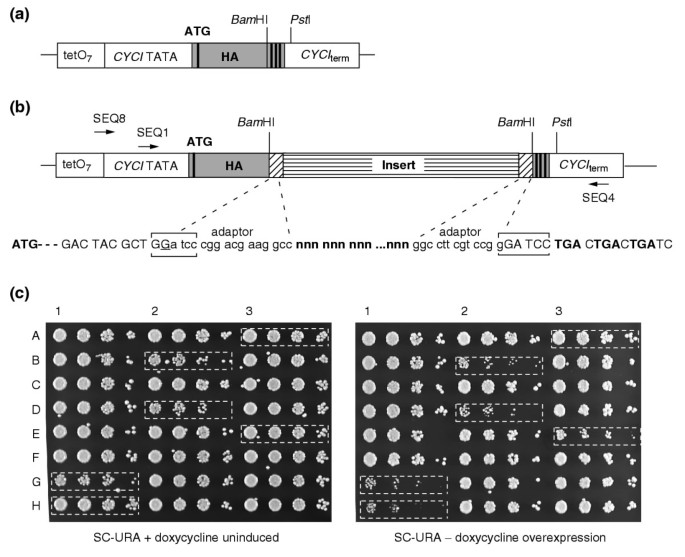
Overexpression library construction and screening. (a) Construction of an HA-tagged vector. The pCMha190 vector used here was constructed by insertion of a linker (gray box) in place of the multiple cloning site in vector pCM190 [31]. Features shown include the promoter and TATA box as well as the terminator from the original plasmid (open boxes), and the start codon, HA-tag, _Bam_HI site and stop codons (thick vertical bars) from the introduced linker sequence. The linker was composed from the following annealed oligonucleotides: EXP3: 5'-GATCGTTTAAACCATATGTACCCATACGACGTCCCAGACTACGCTGG ATCCTGACTGACTGATC-3', EXP4: 5'-GGCCGATCAGTCAGTCAGGATCCAGCGT AGTCTGGGACGTCGTATGGGTACATATGGTTTAAAC-3'. (b) Library construction in pCMha190 (see Materials and methods for experimental details). The resulting ligation product is schematized, with the insert as a striped box and adaptors as hatched boxes. Sequences shown below are from junctions, with uppercase letters corresponding to vector (the extra nucleotide from filling-in is underlined), lowercase letters to adaptors and bold nnn's to insert. Arrows indicate the different primers used: SEQ8 and SEQ4 are used for PCR amplification of the insert, and SEQ1 for sequencing (see sequences in Additional data file 8). (c) First-round screening of toxic phenotypes. The growth of random and control clones on selective medium in uninduced and overexpression conditions is shown. Drops of serial dilutions (1/100 to 1/100,000) of cultures were grown for 45 h at 30°C. A3, non-toxic control clone transformed by pCMha190; H1, toxic control clone transformed by MCM1 gene cloned in pCMha190; G1, B2, D2, E3, library transformed clones, exhibiting different levels of toxicity in overexpression conditions (see Figure 2).
Figure 2
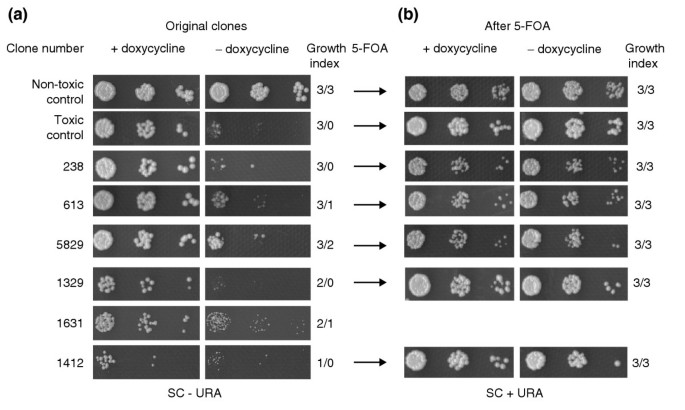
Second-round scoring of toxic phenotypes and control. (a) Selected clones from the first round were diluted and three drops (1/100, 1/1,000 and 1/10,000) were spotted and grown for 42 h at 30°C, with controls on same plates, for confirmation of toxicity. Growth levels in the presence and absence of doxycycline were scored as described in the text. Each clone was assigned a growth index where the first number represents the growth in uninduced conditions and second number the growth in induced conditions; for example, 3/3 indicates a non-toxic insert; 3/0 indicates a highly toxic insert. Clone numbers are the same as in the tables describing the toxic inserts (see Additional file 1,2,3,4). (b) After 5-FOA-induced plasmid loss, growth of surviving clones is scored in the same way as in (a). Wild-type phenotypes in overexpression conditions are indicative of plasmid-borne toxicity.
Table 1 Distribution of the toxic inserts between the different genetic objects
Identification of the genomic inserts conferring toxic phenotypes
Inserts of the selected clones were identified by DNA sequencing (Materials and methods). The complete list of inserts is described in Additional file 1 and 2, and results are summarized in Table 1. A majority of inserts (493, or 69% of total) carry in-frame portions of annotated open reading frames (ORFs), excluding Ty and Y' ORFs. In addition, a significant number of inserts (162 (23%)) correspond to fragments of ORFs cloned either in antiparallel orientation or out-of-frame with respect to the initiator ATG codon or to intergenic regions. The 59 remaining cases (8% of total) correspond to fragments of transposable elements (17 clones) and subtelomeric Y' elements (9 clones), to RNA-coding genes (4 clones), and to non-chromosomal replicons such as the 2 μm plasmid and mitochondrial DNA (mtDNA) (29 clones). If any random fragment of the yeast genome were capable of generating a toxic phenotype, in-frame ORF fusions would represent only around 10-12% of the selected inserts (around 70% of the genome correspond to coding regions, and only one frame out of six corresponds to the natural frame). The fact that the toxic inserts correspond principally to in-frame portions of natural ORFs suggests that the coding part of the genome is the most prone to confer toxicity when overexpressed.
Analysis of domains within in-frame ORF fragments
The 493 inserts corresponding to in-frame ORF fragments represent 454 distinct annotated ORFs (see Materials and methods), which are randomly distributed throughout the 16 chromosomes of S. cerevisiae (see Additional file 1). In our screening, 32 ORFs were found twice, two ORFs were found three times and one ORF (_YHR056_c in the CUP1 region) was found four times, the cloned fragments being either overlapping (22 ORFs) or non-overlapping (13 ORFs). Mean size of the coding region of inserts is 659 bp. The chosen cloning strategy favors recovery of central-or carboxy-terminal coding parts of the natural yeast genes, whereas the amino-terminal coding regions are rare [7]. In our work, the cloned insert encompasses the entire gene in only six cases (additional file 3, column 20 to 23). In 154 additional cases, the insert corresponds to the carboxy-terminal portion of the natural protein (the stop codon is present). In 10 cases, the inserts start upstream of the natural ATG initiator codons, lengthening the natural peptides by reading in-frame through the untranslated region. Other cases correspond to the central coding region of natural genes.
To find possible common characteristics, we have compared between themselves all the peptides encoded by in-frame ORF fragments. BLASTP analysis was combined with detection of characterized conserved domains, of COG patterns (clusters of predicted orthologous groups of proteins [32]), and of transmembrane spans (TMS) to identify toxic inserts similar to each other (see Materials and methods). Out of the 493 in-frame ORF fragments, a total of 170 were divided up into 57 distinct groups of similarity, containing from two to 12 inserts, including overlapping fragments of the same ORF (see Additional file 4). It is expected that several ORFs from a same paralogous gene family are found in a same group. Note that in 16 out of 57 groups, the inserts contain transport-specific domains and/or transmembrane spans.
As well as comparing inserts to each other, we also analyzed the totality of the conserved domains present in all peptides encoded by the 493 toxic inserts (see Materials and methods). Characterized domains are found, at least partially, in a total of 281 inserts (see additional file 1 and 3). Of a total of 183 distinct domains, 46 are represented more than once. We have compared the frequency of these 46 domains among the toxic inserts versus their frequency among the 5,803 ORF-encoded proteins of the entire genome (Table 2). We find that 37 domains are significantly over-represented compared to a random expectation, suggesting that we have screened specific domains.
Table 2 Conserved domains found more than once among the toxic in-frame ORF fragments
These 37 domains correspond predominantly to various transporter domains (11 cases), such as amino-acid permeases and mitochondrial carrier protein domains. The toxicity of these domains is probably due to the presence of transmembrane spans. Indeed, 132 out of the 493 toxic peptides contain at least two transmembrane spans, including cases where one span is putative (see Materials and methods). Among these, 63 contain three or more predicted spans and 26 have five spans or more. Putative spans were also recognized in 84 other ORF fragments (seven with at least three spans, 15 with two spans, and 62 with one span) (see Additional file 1 and 3).
RNA-and DNA-binding domains (nine cases) involved in replication, transcription or translation functions, such as PUF, KH and rrm, are also much more represented than expected (Table 2). The PUF domain is also involved in recruitment of proteins into a complex that controls mRNA translation (see [33] for review).
Other important domains for interactions with polypeptides, phospholipids or small molecules (nine cases) are also over-represented. The WD40 motif, a propeller-like platform for stable or reversible binding of proteins in eukaryotes, has been found in inserts of 12 distinct ORFs (see additional data file 3). The 12 ORFs code for proteins having interactions with other proteins in complexes related to RNA processing or transcription [10], and nine have at least one partner also selected during our screening (see Discussion). Other interacting domains were found, such as dynamin, MRS6, and adaptin_N domains, which have roles in the dynamics of proteins, membranes and cytoskeleton, and PBD, a small domain which binds small GTPases and inhibits transcription activation. The PH domain, which binds phosphoinositides or other ligands and is involved in signal transduction, was found in inserts of three distinct ORFs involved in different functions: metabolism, cell fate, transcription (see Additional data file 3). Finally, other over-represented domains are related to metabolism and other functions (eight cases), of which several may be involved in interactions with other domains.
The serine/threonine protein kinase domain (S_TKc) is significantly under-represented in our screen. Among the 10 toxic inserts whose cognate genes code for protein kinases (PK), only four contain this domain (Additional data file 3). In these four cases, the S_TKc domain is either truncated (Additional data file 4), or flanked by a coiled-coil region and/or a low-complexity segment. Two other inserts contain the PBD (and PH) domains, and the four remaining inserts contain no characterized domain to date. As it is known that overexpression of some protein kinases is deleterious for cells (see [24] and references therein), our results suggest that a domain different from the catalytic domain is responsible for the toxicity of these proteins, and that the fragments selected in our screen have a role in binding ligands such as substrates or regulators of protein kinase activity, or of proteins involved in the signaling cascades. Three other genes coding for protein kinases of the phosphatidylinositol 3-kinase (PI kinase) family are also represented in our screen by four toxic inserts, none of which contained the kinase domain (see Discussion).
The remaining 137 domains (out of 183) were found only once each. Many correspond to functional categories described above, such as transport, metabolism, and interactions with nucleotides, other proteins or other ligands. Seven domains associated with ubiquitination functions were also found (see Additional data file 3 and 5). Several of the domains encountered have also been isolated as mammalian genetic suppressor elements (GSEs), which are cDNA fragments that inhibit cell growth (see [34] and references therein).
In addition to the domains described above, we found toxic inserts coding for natural peptides without recognizable domains but containing regions of low complexity (56 cases). A number of these peptides are highly charged, either negatively or positively (see Additional data file 3). Such charged peptides might interact in an artifactual way with other charged domains of proteins or nucleic acids or with small molecules. Interestingly, the prion-like (Q+N)-rich domain was found in eight of the natural peptides having low-complexity regions.
Nature of the selected genes
We have seen above that 493/714 toxic inserts are in-frame fragments of protein-coding genes. The complete list of the 454 genes corresponding to these toxic inserts is given in Additional data files 1 and 2. Their sizes range between 282 bp and 14,733 bp. The mean size of this distribution is 2,401 bp (standard deviation (SD) 1,671 bp), to be compared with a mean size of 1,444 bp (SD 1,094 bp) for the entire set of 5,803 ORFs of the yeast genome. The bias towards longer ORFs is expected from our cloning strategy (see above). Note that the 35 ORFs that we found more than once are nearly randomly distributed in various size classes.
We examined the distribution of these genes according to different criteria, such as function, subcellular localization, viability and phylogeny (Table 3) and compared it to the distribution of the genes of S. cerevisiae.
Table 3 Distribution of selected genes versus all S. cerevisiae genes
Among the 454 ORFs identified, 91 are unclassified, and function is not yet clear for six others (see Additional data file 3). The remaining ORFs represent a variety of functional classes (Table 3). Distribution of the 454 ORFs shows statistically significant deviations for eight out of the 15 functional classes, taking into account biases due to mean size of genes in each class. Globally, there is a deficit of genes involved in protein synthesis and of unclassified genes, and an excess of genes involved in transport facilitation and cellular transport (echoing the fact that we found many inserts containing transporter domains and transmembrane spans), in cell fate, in transcription and, to a lesser extent, in cell cycle/DNA processing and in homeostasis (regulation of/interaction with the environment).
As seen above, many toxic inserts contain multiple predicted TMS. Such inserts correspond most often to genes coding for transporters or for non-transporter membrane proteins [35]. We have selected a total of 96 transporters (see Additional data file 3) of which 18 belong to the class of putative uncharacterized transporters, whose toxic inserts contain several TMS. Fourteen others belong to the class of transporters of unknown classification, including 13 genes of the nuclear-pore complex family, whereas there is a total of 58 genes in this family in the whole genome. On the other hand, 24 genes coding for non-transporter membrane proteins were also selected. Taken together, 120 transporters and non-transporter membrane proteins are represented in our screen, twice as many as expected (61 expected), as 782/5,803 ORFs are known or predicted as coding for such proteins [35].
The distribution of the proteins encoded by these genes in the cell is strongly biased in favour of the plasma membrane and against the cytoplasm, and, to a lesser extent, in favour of nucleus and cytoskeleton (Table 3).
Although the majority of inserts originate from non-essential genes, we have found 96 essential genes (21%) among the selected ORFs. This is a significantly higher percentage than in the whole genome, where 939/5,803 genes (16.2%) are essential (Table 3).
Using the classification from Malpertuy et al. [36] and additional updating (Génolevures [[37](/articles/10.1186/gb-2004-5-9-r72#ref-CR37 "Génolevures. [ http://cbi.labri.fr/Genolevures/Genolevures.php
]")\]), we find that the majority of genes yielding toxic fragments in this work are conserved (336/454 (74%)) between _S. cerevisiae_ and other sequenced organisms, whereas 106 (23%) are ascomycete-specific and 10 (2.2%) are orphan genes. This distribution is significantly different from the distribution among the 5,803 genes of _S. cerevisiae_, where 64% of protein-coding genes are conserved (see Table [3](/articles/10.1186/gb-2004-5-9-r72#Tab3)). The under-representation of orphan genes in our screen is already apparent in the under-representation of functionally unclassified genes, as a high rate of orphans of the whole genome (79%) are also unclassified (data from Génolevures \[[37](/articles/10.1186/gb-2004-5-9-r72#ref-CR37 "Génolevures. [
http://cbi.labri.fr/Genolevures/Genolevures.php
]")\] and Munich Information Center for Protein Sequences (MIPS) \[[38](/articles/10.1186/gb-2004-5-9-r72#ref-CR38 "Comprehensive Yeast Genome Database. [
http://mips.gsf.de/genre/proj/yeast
]")\]).Toxicity of entire genes versus ORF fragments
To compare the phenotypes conferred by overexpression of the entire gene and of the gene fragment, we have cloned the cognate entire genes of 13 in-frame toxic inserts into the vector pCMha191 (see Materials and methods). One criterion for the choice of the genes was the absence of a mutant phenotype of the corresponding gene disruption at the time this work was started, except for the NOP4 gene whose disruption is lethal. Six of these genes are singletons; three others have a paralog already known as toxic upon overexpression. Six out of the 13 still have no known function to date (Table 4). Expression at the protein level of both entire gene and gene fragment was verified by western-blot analysis, using an anti-hemagglutinin (HA) antibody (data not shown). As seen in Table 4 and Figure 3, we found that overexpression of 10 genes was as toxic or more toxic than overexpression of the gene fragments. One gene, YGR149w, was less toxic in its entire version than in the truncated form, which was weakly toxic. Finally, we found that two genes, YML128c/MSC1 and YDL112w/TRM3, showed no toxicity when overexpressed, whereas the cloned inserts were strongly toxic. In these two cases, the immunolocalization of overexpressed products was examined, and the cytoplasmic localization of the fragment agreed with the location of the natural gene product (data not shown), indicating that the toxic effect is not the result of mislocalization of the overexpressed fragment. The gene MSC1 had already been screened [24] as a toxic fragment in overexpression conditions, the region concerned being the same as in our screening. This gene has low similarity to a stress protein of Schizosaccharomyces pombe and has a role in meiotic recombination. The TRM3 gene contains a carboxy-terminal domain responsible for tRNA methyltransferase activity [39], which is absent from our insert. The protein is a member of a complex probably involved in signaling [10].
Table 4 Toxicity of fragments versus whole ORF products
Figure 3
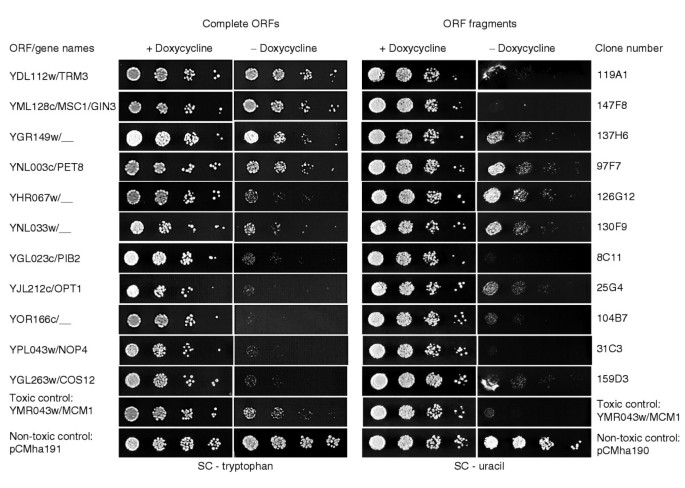
Toxic phenotypes of overexpressed fragments versus whole ORF products. Complete ORFs are cloned in pCMha191 (tryptophan marker); inserts are cloned in pCMha190 (uracil marker). Eleven out of the 13 cases are represented in this figure. + doxycycline, uninduced conditions; - doxycycline, overexpressed conditions.
Analysis of other fragments
Additional data file 2 analyzes the 221 other toxic inserts which do not correspond to in-frame fragments of annotated ORFs. Sixty-eight inserts correspond to natural ORF fragments cloned in an antiparallel orientation, most of them being entirely included within the ORF sequence (47 cases), the others overlapping the intergenic upstream region of the natural ORF (17 cases) and sometimes the next gene as well (four cases). Their toxicity can result either from the overexpression of an antisense RNA or from the overexpression of a toxic artificial peptide encoded by a fortuitous ORF. Several arguments favor the second hypothesis. First, short ORFs longer than 24 codons (maximum observed 250 codons), and in-frame with the start codon of the cloning vector, are observed in 53 cases (78% of the total). A number of those artificial ORFs are due to the 'mirror' effect produced by codon-biased natural ORFs [40, 41]. But the fact that they are observed more than one-third of the time suggests a positive selection for toxic artificial peptides. Second, antiparallel ORF fragments do not correspond to a majority of essential genes, as might be expected from antisense RNA inhibition. Third, we have directly verified, for two inserts recloned in the same vector, that addition of a stop codon that blocks translation of the artificial ORF also suppresses toxicity (see Additional data file 9). Even if this concerns only two cases, we have no direct results indicating the existence of antisense RNA molecules that could block expression of essential genes.
Fifty-three additional inserts correspond to natural ORF fragments cloned out-of-frame with respect to the plasmid-borne ATG codon, of which only 12 code for artificial ORFs longer than 24 codons (see Table 1 and Additional data file 2). Intergenic regions are represented by 41 inserts, of which 27 (65% of total) code for short artificial ORFs.
In total, short artificial peptides may be encoded by 92 out of the 162 inserts described above. Comparison of the 92 peptides between themselves reveals several low-complexity sequences (see Additional data file 2), mostly encoded by antiparallel ORF fragments whose direct amino-acid sequence is itself of low complexity. Comparison with the proteins of S. cerevisiae and of all available sequenced organisms compiled in our internal database (GPROTEOME3, see Materials and methods) reveals no significant similarity. None of these artificial ORFs corresponds to the 137 new annotated yeast genes of Kumar et al. [42], to the 62 new genes of Oshiro et al. [43] or to the 84 genes of Kessler et al. [44]. Even though we have no evidence for antisense RNA activity, we cannot exclude a toxic effect due to the overexpressed transcript itself.
Among the 59 remaining inserts, 17 belong to Ty elements, 10 of which are in-frame ORF fragments corresponding to TyB only (two of them containing the carboxy-terminal part of the rve domain (integrase core)), whereas all antisense fragments (three inserts) correspond to TyA. Y' elements, which are present in 20 copies in the genome, are represented by nine inserts, all coding for highly basic or acidic peptides (of which three are in-frame fragments of natural ORFs) which contain repeats of amino acids or motifs, and confer a strongly toxic effect (see Additional data file 2). Considering that these inserts are toxic, their observed number is not different from that expected from the size and number of Y' in the genome.
Four inserts from yeast chromosome XII are fragments of genes coding for 18S or 25S RNA, two inserts being cloned in the sense orientation. The 2 μm plasmid is represented by 17 fragments, 10 of which are in-frame fragments of ORFs coding for REP1, REP2 and FLP1. The seven other inserts are out-of-frame or antisense fragments of FLP1, or fragments of intergenic regions, all (except two) coding for artificial ORFs. Finally, mtDNA is represented by 12 fragments, mostly corresponding to intergenic regions on the minus strand of the chromosome. Artificial peptides highly enriched in the amino acids tyrosine (Y), isoleucine (I), and lysine (K) are encoded by 10 out of the 12 mitochondrial inserts.
Discussion
The general fitness of living organisms largely depends on a harmonious equilibrium between the various cellular components and on their capacity to maintain homeostasis. The intricate circuitries that regulate gene expression form the basis of these properties, and massive deregulation of single components may result in flagrant phenotypic defects leading to serious growth impairment or even cell death. Our large-scale screening of the yeast genome using random genomic fragments resulted in a collection of several hundreds of inserts showing toxic effects on cell survival or growth when overexpressed. These toxic effects are expected to result from several distinct molecular situations that have been encountered at various frequencies in our experiments. Of the total of 714 toxic inserts studied, a majority (69%) correspond to the overexpression of fragments originating from natural protein-coding genes (454 genes were identified in total). But, interestingly, a large minority (23%) correspond to noncoding DNA fragments. The remaining cases (less than 10% of the total) correspond to fragments of Ty or Y' elements, of the 2 μm plasmid or of mtDNA which, after analysis, can be attributed to one of the two previous categories. Toxic fragments of natural gene products are interesting to consider with respect to the functions of the corresponding genes. But the second category may be even more promising in that it offers us a description of DNA sequences that cannot be overexpressed in a cell without a deleterious effect.
The toxicity of coding fragments may result from the imbalance between products of tightly controlled genes, or from the titration of active complexes by the presence of truncated proteins and/or isolated domains. In addition, nonspecific effects might also exist, for example, as a result of an abnormal intracellular localization of an artificially overabundant peptide or protein. We did not attempt to distinguish experimentally between these possibilities for all the coding inserts isolated in this work. Taking into account only specific effects, in the limited number of cases in which the entire gene corresponding to a toxic insert was cloned in the overexpression vector (see Results), we verified that toxicity was due, in most cases, to the disruption of the precise dosage of an essential cellular component (the entire protein is also toxic when overexpressed) and, in some cases, to the titration effect exerted by the incomplete fragment of the natural protein (the entire protein is not toxic when overexpressed). A few examples where the domain responsible for toxicity upon overexpression is known can be found in the literature. In the case of TOR1 and TOR2 genes, toxicity is specific to a central domain of the proteins distinct from their carboxy-terminal protein kinase domain; overexpression of the entire gene has no effect, and can even cure the negative effect of the overexpressed domain [45]. Alarcon et al. [45] have proposed that Tor proteins could serve as a scaffold on which to assemble other proteins for appropriate interaction with the kinase domain. Our results agree with this hypothesis, as four out of the five yeast genes belonging to the conserved family of PI kinase-related protein kinases - TOR1, TOR2, TEL1 and TRA1 - were selected in this work, all represented by inserts of the central region of these proteins (Figure 4 and Additional data file 3). In mammalian cells, overexpression of such fragments of ATM, a homolog of TEL1, also has a negative effect [46]. In other cases in which overexpression of the entire gene is toxic, certain domains responsible for the toxicity have been mapped, for example the Myb DNA-binding domain of RAP1 (see Background), the ZnF C3H1 domain of CTH1 [47] and the bZIP domain of GCN4 [48]. All these DNA-binding domains were significantly over-represented in our screen (Table 2).
Figure 4
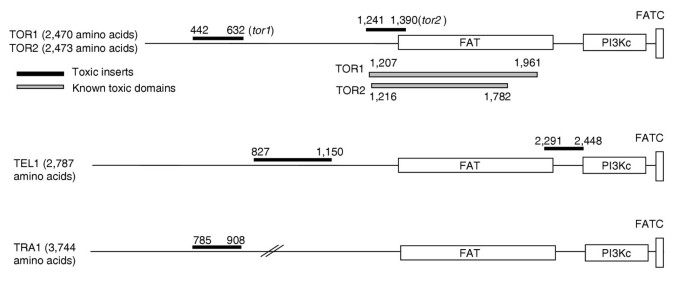
Positions of selected toxic fragments relative to the structure of genes of the PI kinase family. Names of the selected genes and protein lengths (in amino acids) are indicated. Coordinates of the toxic fragments selected in this work and of known toxic domains (see text) are also given. Conserved domains in the proteins have been positioned using the NCBI CD-Search program [64] (see Materials and methods). Domain abbreviations: FAT (pfam 00259) is named after FRAP, ATM and TRRAP, which are human homologs of yeast TOR, TEL1 and TRA1, respectively; PI3Kc (smart00146) is the PI kinase catalytic domain; FATC (pfam02260.11) is named after FRAP, ATM, TRRAP carboxy-terminal region. Complete COG5032 TEL1 (2,105 residues) spans the carboxy-terminal regions of the four proteins. The drawing is not to scale.
Even in the absence of precise mapping of the toxic domain present in our clones, we were able to explore the nature of the domains found in each insert. Our experiment has shown a bias towards domains corresponding to transport functions and to various interactions (Table 2). As mentioned in Results, the toxic effect of transport-specific domains may be due to the presence of corresponding TMS.
As our results also showed a bias towards a number of interaction domains, we have examined the known interactions of the proteins encoded by the 454 genes found in this screen (see Materials and methods). Genetic interactions were also considered, excluding the coexpression results obtained in microarray experiments. It appears that 88.3% of our genes (401/454, of which 70 are of unknown function) code for proteins which have known genetic or physical interactions, or are members of complexes (see Additional data file 3). Moreover, for 60% of these (242/401), at least one of their known partners is also found in our screen (see Additional data file 6 and 7). Among the 53 genes having no known interactions, 24 correspond to transporter or membrane proteins (see Additional data file 3).
The biases we have observed show little overlap with previous screenings of S. cerevisiae, which had previously identified a total of 231 genes or gene fragments that were toxic when overexpressed [24, 26, 28–30, 49]. Among the 185 genes of Stevenson et al. [30], those involved in protein synthesis are represented twice as frequently as in the whole genome, whereas they are twice less frequent in our own experiment. In contrast, genes involved in transport facilitation and interactions with the environment were not over-represented in the Stevenson et al. experiment. Common biases are, however, observed in favor of transcription, cell-cycle and cellular transport genes. Overall, only 33 of our 454 ORFs were previously identified by the previous authors (the total rises to 78 if one considers individual gene studies). Twenty-five other genes from the previous screenings not found here are members of paralogous gene families represented in our work (see Additional data file 3). The limited overlap may result from partial genome coverage. However, by screening 84,086 clones (a coverage of around 4.5 genome equivalents), we must have encountered a total of 4,677 ORFs, each being represented 1.6 times as an ORF fragment (see Materials and methods). We have thus screened for toxicity around 80% of the natural yeast ORFs. But the limited overlap of results may also be explained by the experimental bias introduced by each technique. The previous experiments were mostly based on cDNA cloning, which favors short and highly expressed genes, whereas our genomic library favors large ORFs (mean size 800 ± 557 codons per ORF) and has no expression bias. In addition, the largest previous experiment [30] was done using centromeric plasmids and a galactose promoter as opposed to our multicopy vectors. Furthermore, our serial dilution drop assay is probably more sensitive to growth alteration than the replica techniques previously used. Finally, previous overexpression experiments relied on changing the nutrient composition of the growth medium (galactose vs glucose) whereas our experimental set-up relied on the presence/absence of a drug in a medium of the same nutritional composition.
The finding of a large minority of toxic inserts corresponding to noncoding DNA is puzzling. Indeed, some of the toxic inserts originate from annotated but questionable ORFs, and some originate from antisense or intergenic fragments which can artificially be translated into small ORFs. None of these peptides has recognizable characterized domains, but many of them are charged, mostly positively (see Additional data file 2) and some have amino-acid sequences of low complexity. It could be proposed that all these small ORFs represent a reservoir of potentially new gene sequences in the genome. In addition, 100 of the in-frame toxic inserts had no characterized domains and sometimes no predicted secondary structure. These inserts do not contain conserved domains, COGs or TMS, and are not biased in amino-acid composition (see Additional data file 3). They may correspond to domains that have not yet been described, or to domains whose structure has diverged, but another possibility would be that some protein domains are perhaps not structured in a permanent way before evolving towards a structurally functional domain. Interestingly, a significant proportion of the expressed peptides we selected are specific to ascomycetes, or are even true orphan genes that have no known homolog in any other species than S. cerevisiae. A collection of toxic polypeptides, acting as genetic suppressor elements and interfering with major cellular functions, is of interest not only in antifungal research but also as a means of identifying new domains with major physiological roles.
Finally, given the large number of inserts encoding very short ORFs (around 70 amino acids in the groups of antiparallel, intergene and out-of-frame fragments, and 80 in total, see Additional data file 2), we cannot exclude the possibility that some transcripts are toxic through hypothetical mechanisms that may include, for example, nonspecific interactions with other cellular or nuclear complexes or through overloading of some component(s) involved in RNA metabolism.
Conclusions
In a large-scale phenotypic screening of overexpressed random DNA fragments, we selected around 470 genes (including Ty, Y' and the 2 μm plasmid) whose domains inhibit or impair growth when overexpressed. Many functional categories are represented, transporter proteins being especially over-represented, and genes of unknown function represent one-fifth of our selection. Our approach gave access to genes controlling intracellular and membrane structures, as well as to genes whose deficiency is compensated for by genetic redundancy. Comparable approaches, using efficient phenotyping technology [50] and appropriate screening procedures, could be used for identification of genes involved in specific functions, such as homeostasis and response to stress.
We have carried out an analysis of toxic protein domains, pointing out the importance of binding domains and of protein-protein interactions correlated to regulation of cell growth and cell division. This provides a large body of data for targeting more specific studies on the modular construction of proteins and the role of interaction domains in multicomponent assembly of physiological complexes. Finally, in some cases, the deleterious effects in our system of inserts that encode very short ORFs may suggest that overexpression of some transcripts is also toxic for cell growth.
Materials and methods
Strains and media
Total yeast DNA from strain FY1679 (Mata/α, ura3-52/ura3-52, trp1-Δ63/+, leu2-Δ1/+, his3-Δ200/+) [51] was a generous gift of A. Harington. Strains FYBL2-5D (Matα, ura3-Δ851, trp1-Δ63, leu2-Δ1) [52] and FYAT-01 (Matα, ura3-Δ851, trp1-Δ63, leu2-Δ1, his3-Δ200, ade2-661) (A. Thierry, unpublished work) were used for transformations and growth defect screening. All strains are isogenic derivatives of S288C.
The yeast genomic library was constructed using Escherichia coli DH10B cells (Electromax DH10B, Gibco-BRL).
Yeast cells transformed by pCMha190 recombinants were grown at 30°C on glucose synthetic complete medium lacking uracil (SC - URA) always supplemented with 10 μg/ml doxycycline (Sigma) (uninduced conditions). Phenotypic tests were done on solid medium (12 cm × 12 cm plates) containing 70 ml of SC - URA + 10 μg/ml doxycycline (uninduced conditions) or SC - URA without doxycycline (overexpression conditions). Yeast cells transformed by pCMha191 recombinants were grown at 30°C on SC - tryptophan medium, with or without addition of doxycycline. Plasmid loss was carried out on SC plates containing uracil (50 mg/l) and 0.1% of 5-fluoroorotic acid (5-FOA).
Vector construction and cloning
Plasmids pCMha184, pCMha189, and pCMha190 were derived from the centromeric (pCM184, pCM189) or episomal (pCM190) overexpression vectors, containing a tetracycline-regulatable promoter system and URA3 (pCM189, pCM190) or TRP1 (pCM184) as selection markers [31]. In the original vectors, a 33 bp _Bam_HI-_Not_I fragment was replaced by a synthetic linker with ends compatible with these sites and introducing an ATG codon followed by an in-frame HA-tag, a _Bam_HI cloning site, and stop codons in the three frames (Figure 1a). The episomal pCMha191 vector was derived from pCMha184 (TRP1 selection marker) by replacement of the centromere and replication origin with a 2 μm plasmid replication origin. This was PCR-amplified from pCMha190 using primers M1 and M2 (see Additional data file 8) using Pfu polymerase (Stratagene), and ligated to the 5,953 bp _Eco_RI-_Bgl_II fragment of pCMha184.
The overexpression system was checked by cloning two short genes, MCM1 and AUAI (861 and 285 bp respectively), which are toxic when overexpressed under the control of a GAL1 promoter [29]. Both genes were PCR-amplified from yeast genomic DNA (see primers in Additional data file 8), cloned into vectors pCMha189 and pCMha190, and transformed into yeast strain FYAT-01. Only gene MCM1, cloned in the high-copy pCMha190 vector, had a clear and constant toxic effect on yeast growth when overexpressed. We thus decided to build the library into pCMha190 and to choose the MCM1 gene as a control for toxic phenotype in overexpression conditions.
Thirteen complete genes corresponding to 13 selected toxic inserts (see Results) and the MCM1 control gene were cloned into the Bam_HI digested plasmid pCMha191 (TRP1 marker)._ Genes were PCR-amplified from genomic DNA (see primers in Additional data file 8). For each gene, two independent plasmids were transformed into yeast strain FYBL2-5D. In parallel, the same strain was transformed with the plasmids bearing the corresponding toxic inserts.
Two toxic inserts, 156C1 and 57B6, which are antiparallel fragments of YGL039w and YAL062w/GDH3 ORFs, were modified by PCR synthesis (see Additional data file 9), then recloned in vivo into pCMha190 using homologous recombination [53] in yeast strain FYBL2-5D. Constructions were verified by sequencing. In parallel, original plasmids extracted from transformed strain FYAT-01 were retransformed into strain FYBL2-5D. Phenotypes in uninduced and overexpression conditions were observed in seven independent transformants in each case.
Construction of a random yeast genomic library into pCMha190
The adaptor-based strategy [7, 54] was used to prevent self-ligation of the vector and ligation of multiple inserts.
Sonicated total yeast DNA fragments from FY1679 ranging in size from 200 to 1,200 bp were treated with mung-bean nuclease, T4 DNA polymerase and Klenow enzyme following the manufacturers' protocols. Blunt ends of DNA fragments were ligated to the following adaptor:
5'-pATCCCGGACGAAGGCC-3'
3'-GGCCTGCTTCCGG-5'.
Excess of unligated adaptors and small adaptor-DNA fragments were eliminated by two consecutive purifications using Chroma spin+TE-400 columns (Clontech). Vector predigested with _Bam_HI and filled in with dGTP by the Vent (exo-) polymerase (New England Biolabs) was ligated to the purified adaptor-DNA inserts (800 ng = ~0.16 pmol vector, 800 ng = ~1.7 pmol inserts, in a 40 μl final volume per ligation). The ligation result is drawn in Figure 1b.
Electroporations of 40 μl of E. coli DH10B cells were performed with 1.8 μl of ligation mix and plated onto 2YT medium (16.1 g/l Bacto tryptone, 10.1 g/l Bacto yeast extract, 5 g/l NaCl, 15 g/l Bacto agar) containing 100 μg/ml ampicillin (four 12 × 12 cm plates per transformation) giving 25,000 to 45,000 clones per transformation.
A total of 51 independent transformations were made. This corresponds to 1,888,000 clones. We tested 150 clones for the presence of an insert and observed that more than 85% contained one (average size 700 bp, minimum 220 bp, maximum 1,620 bp). Colonies from each transformation were pooled and distinct Qiagen Tip 500 DNA preparations were made and stored separately for yeast transformation. Final concentration of DNA was 300 to 1,300 ng/μl. The detailed protocol of library construction is available on request.
Another library had previously been constructed with the same vector ligated to a distinct DNA-adaptor preparation and was partially used, giving rise to 160,000 primary clones. Characteristics of the transformants were the same as described above. Eight pools of plasmid DNA were prepared from this first library.
Yeast transformations
We carried out a total of 28 independent transformations of yeast by the LiAc method [55]: five with the yeast strain FYAT-01 using five distinct plasmid DNA preparations from the first library and 23 with the strain FYBL2-5D using 23 distinct plasmid DNA preparations from the main library. Aliquots of each transformation were spread onto 24 × 24 cm plates (Q-Pix Trays, Genetix) containing SC - URA + doxycycline, to obtain 1,000 to 3,000 yeast transformants per plate.
Screening and storage of toxic clones
Transformed yeast clones were transferred into fresh liquid SC - URA + doxycycline medium in 96-well microplates by manual picking (30,015 clones) or with the Q-Pix robot (54,071 clones) for overnight growth. Non-toxic and toxic control clones (transformed by empty pCMha190 vector and by vector bearing MCM1, respectively) were also inoculated into each microplate. Cultures were grown overnight at 30°C and stored at 4°C before dilutions for phenotypic examination. Screening of the toxic phenotypes after overexpression was done in a two-round selection, using the 'drop test', which allowed us to see even slightly impaired growth effects. Ten-fold serial dilutions in water were made from each 96-well culture microplate with a Beckman Biomek 2000 robot, then manually replicated with the 96-pin Beckman replicator onto SC - URA + doxycycline and SC - URA plates in parallel (Figure 1c). Clones showing impaired growth in overexpression conditions were streaked onto SC - URA + doxycycline medium for colony isolation, then transferred (one subclone per streak) into a new 96-well microplate and grown for 22 h at 30°C. This plate served as a mother plate for four culture microplates which were grown overnight at 30°C (one plate for the second-round screening, another plate for PCR amplification on colonies for sizing and sequencing the inserts and two plates for storage at -80°C). For the second round of screening, cultures were diluted (1/100 to 1/10,000 dilution) and tested on SC - URA + doxycycline and SC - URA plates in parallel. Phenotypes in the presence and absence of doxycycline (uninduced and overexpression conditions respectively) were scored as described in Results and Figure 2. Between the two rounds of screening, most of the clones conserved a comparable phenotype. For those displaying an important difference, a new subclone was tested again, and the transformant was rejected if the phenotype revealed was inconsistent.
The dependence of the phenotype on the presence of the plasmid was demonstrated using two methods: for 150 tested clones, wild-type phenotypes were recovered after plasmid loss using 5-FOA resistance selection; for 35 other clones, plasmids were extracted from transformed strain FYAT-01 and retransformed into strain FYBL2-5D, in which the toxic phenotypes were confirmed.
Identification of the toxic inserts at the nucleotide and peptide levels
Inserts of the selected clones were PCR-amplified directly from cultures using primers SEQ4 and SEQ8 (Figure 1b). The length of each insert was determined by gel electrophoresis and the 5' junction was sequenced using primer SEQ1. Identification of each insert in our internal database (see below) was carried out using the DOGEL program [56], adapted by Nicolas Joly (Institut Pasteur) to our purpose. This program gives the start position of the insert on chromosomes, the corresponding genetic object and the start position in the ORF relative to the natural ATG (see Additional data files 1 and 2). We first verified the sequence at the junction with the adaptor-insert. Correct in-frame ligation between vector and adaptor-1 was observed for 632 clones (88.5% of total). For the remaining 82 clones, base substitutions, and short (one to three nucleotides) deletions within the adaptor-1 were observed (nine and 18 cases respectively). A total of 46 cases of a single G addition at the junction vector-adaptor-1, and 15 partial vector sequence duplicates were found (see Additional data files 1 and 2). As the incorrect ligations introduced no stop codon between the initiation codon of the vector and the first codon of the insert, these clones were conserved for further analysis. In these cases, the start position of the insert relative to the chromosome and to the ORF coordinates was corrected manually.
For analysis of in-frame ORF fragments, sequences of peptides encoded by toxic inserts were extracted from the complete sequences of S. cerevisiae proteins, taking the first amino acid corresponding to the junction with the adaptor as the starting point and the end of the insert or the last codon of the ORF as the end point.
Fragments of mtDNA, 2 μm plasmid, and DNA coding for Y'-ORFs, Tys, long terminal repeats (LTRs) and RNA were examined manually for their position relative to the coding sequences.
Sequences of inserts other than in-frame ORF fragments were systematically translated into amino-acid sequences from the junction with the adaptor up to the first stop codon encountered in the insert. Sequences coding for more than 24 amino acids were internally compared using BLASTP, then compared to the S. cerevisiae annotated ORFs and to the 308,738 sequences of our internal database (see below).
Databases
Genetic entities corresponding to the toxic inserts were identified by comparison with the DNA sequences of the 16 chromosomes (available in the Comprehensive Yeast Genome Database (CYGD) at MIPS [[38](/articles/10.1186/gb-2004-5-9-r72#ref-CR38 "Comprehensive Yeast Genome Database. [ http://mips.gsf.de/genre/proj/yeast
]")\]); with our own interpretation table containing the coordinates of 6,256 coding sequences (CDS or ORFs), which comprises the new genes found by Blandin _et al._ \[[57](/articles/10.1186/gb-2004-5-9-r72#ref-CR57 "Blandin G, Durrens P, Tekaia F, Aigle M, Bolotin-Fukuhara M, Bon E, Casaregola S, de Montigny J, Gaillardin C, Lepingle A, et al: Genomic exploration of the hemiascomycetous yeasts: 4. The genome of Saccharomyces cerevisiae revisited. FEBS Lett. 2000, 487: 31-36. 10.1016/S0014-5793(00)02275-4.")\]; with the 2 μm plasmid DNA sequence \[[58](/articles/10.1186/gb-2004-5-9-r72#ref-CR58 "Hartley JL, Donelson JE: Nucleotide sequence of the yeast plasmid. Nature. 1980, 286: 860-865. 10.1038/286860a0.")\]; and with the yeast mitochondrial sequence \[[59](/articles/10.1186/gb-2004-5-9-r72#ref-CR59 "Foury F, Roganti T, Lecrenier N, Purnelle B: The complete sequence of the mitochondrial genome of Saccharomyces cerevisiae. FEBS Lett. 1998, 440: 325-331. 10.1016/S0014-5793(98)01467-7.")\]. The set of 6,256 ORFs of _S. cerevisiae_ was filtered to eliminate all spurious ORFs or unlikely real genes, as well as Ty, Y' and mitochondrial ORFs, yielding a final list of 5,803 ORFs \[[60](/articles/10.1186/gb-2004-5-9-r72#ref-CR60 "Talla E, Tekaia F, Brino L, Dujon B: A novel design of whole-genome microarray probes for Saccharomyces cerevisiae which minimizes cross-hybridization. BMC Genomics. 2003, 4: 38-10.1186/1471-2164-4-38.")\]. For all comparisons of the set of 454 toxic ORFs with the set of ORFs of the entire genome, we used these 5,803 ORFs. GPROTEOME3 is an updated version of the GPROTEOME sequence library \[[61](/articles/10.1186/gb-2004-5-9-r72#ref-CR61 "Tekaia F, Blandin G, Malpertuy A, Llorente B, Durrens P, Toffano-Nioche C, Ozier-Kalogeropoulos O, Bon E, Gaillardin C, Aigle M, et al: Genomic exploration of the hemiascomycetous yeasts: 3. Methods and strategies used for sequence analysis and annotation. FEBS Lett. 2000, 487: 17-30. 10.1016/S0014-5793(00)02274-2.")\] containing 308,738 predicted protein sequences from 60 organisms (F. Tekaia, personal communication).Analysis of the toxic inserts and of their cognate genes
Comparisons among the peptides encoded by in-frame ORF fragments were done using BLASTP [62]. Alignments corresponding to E-values equal to or lower than 10-3 were examined individually before validation.
Conserved domains or patterns of COGs [32] were identified using the NCBI Conserved Domain Search service (CD-Search [63, [64](/articles/10.1186/gb-2004-5-9-r72#ref-CR64 "NCBI CD-Search. [ http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi
]")\]). The NCBI Conserved Domain Database (cdd.v1.62) \[[65](/articles/10.1186/gb-2004-5-9-r72#ref-CR65 "NCBI Conserved Domain Database. [
http://www.ncbi.nlm.nih.gov/Structure/cdd/cdd.shtml
]")\] contained domains derived from Smart \[[66](/articles/10.1186/gb-2004-5-9-r72#ref-CR66 "Letunic I, Goodstadt L, Dickens NJ, Doerks T, Schultz J, Mott R, Ciccarelli F, Copley RR, Ponting CP, Bork P: Recent improvements to the SMART domain-based sequence annotation resource. Nucleic Acids Res. 2002, 30: 242-244. 10.1093/nar/30.1.242.")\] and Pfam \[[67](/articles/10.1186/gb-2004-5-9-r72#ref-CR67 "Bateman A, Birney E, Cerruti L, Durbin R, Etwiller L, Eddy SR, Griffiths-Jones S, Howe KL, Marshall M, Sonnhammer EL: The Pfam protein families database. Nucleic Acids Res. 2002, 30: 276-280. 10.1093/nar/30.1.276.")\] collections, plus contributions from NCBI such as COGs, leading to 11,088 position-specific score matrices (PSSMs). A routine was written for extraction of the CD-Search results obtained for the toxic inserts and the 5,803 proteins of the entire genome. The cut-off E-value was chosen to be equal to or less than 10\-4 for most domains, and 10\-3 for short domains (60 amino acids or fewer). Domains were considered as present even when represented only partially. In describing genes (Table [4](/articles/10.1186/gb-2004-5-9-r72#Tab4)) or toxic in-frame inserts (see Additional data files 1, 3 and 4), only one domain (giving the best hit) was chosen for a given insert, among several possible hits. In contrast, to compare the frequency of a given domain among all toxic inserts versus its frequency among the 5,803 proteins of _S. cerevisiae_ (Table [2](/articles/10.1186/gb-2004-5-9-r72#Tab2)), all occurrences were taken into account, giving a total of 843 occurrences among the 493 toxic inserts, and a total of 15,925 occurrences among the 5,803 proteins.Searches for transmembrane spans (TMS) were done using TopPredII [68] implemented by Deveaud and Schuerer (Institut Pasteur), predicting both certain and putative TMS. The isoelectric points (IEPs) of proteins or peptides were calculated using iep algorithm from the European Molecular Biology Open Software Suite (EMBOSS) [[69](/articles/10.1186/gb-2004-5-9-r72#ref-CR69 "EMBOSS homepage. [ http://www.hgmp.mrc.ac.uk/Software/EMBOSS
]")\].Descriptions of selected genes and their products were retrieved from the Yeast Proteome Database [70] (release of March 2002; this database is no longer freely available), and from MIPS [[38](/articles/10.1186/gb-2004-5-9-r72#ref-CR38 "Comprehensive Yeast Genome Database. [ http://mips.gsf.de/genre/proj/yeast
]")\]. Functional classes, cellular localizations and a list of essential genes were retrieved from MIPS \[[38](/articles/10.1186/gb-2004-5-9-r72#ref-CR38 "Comprehensive Yeast Genome Database. [
http://mips.gsf.de/genre/proj/yeast
]")\]; gene classes (conserved/asco-specific/orphan) are from Génolevures \[[37](/articles/10.1186/gb-2004-5-9-r72#ref-CR37 "Génolevures. [
http://cbi.labri.fr/Genolevures/Genolevures.php
]")\]. Paralogous gene families of _S. cerevisiae_ \[[57](/articles/10.1186/gb-2004-5-9-r72#ref-CR57 "Blandin G, Durrens P, Tekaia F, Aigle M, Bolotin-Fukuhara M, Bon E, Casaregola S, de Montigny J, Gaillardin C, Lepingle A, et al: Genomic exploration of the hemiascomycetous yeasts: 4. The genome of Saccharomyces cerevisiae revisited. FEBS Lett. 2000, 487: 31-36. 10.1016/S0014-5793(00)02275-4.")\] are accessible at Génolevures \[[37](/articles/10.1186/gb-2004-5-9-r72#ref-CR37 "Génolevures. [
http://cbi.labri.fr/Genolevures/Genolevures.php
]")\] through gene or ORF name.We searched for the participation of the selected ORFs in protein-protein interactions (genetic and physical) and in protein complexes using three different sources: YPD [70] files for individual proteins; protein complexes defined by Gavin et al. [10]; data compilations concerning protein-protein interactions and complexes, extracted from SGD [[1](/articles/10.1186/gb-2004-5-9-r72#ref-CR1 " Saccharomyces Genome Database. [ http://www.yeastgenome.org
]")\], MIPS \[[38](/articles/10.1186/gb-2004-5-9-r72#ref-CR38 "Comprehensive Yeast Genome Database. [
http://mips.gsf.de/genre/proj/yeast
]")\] and unpublished two-hybrid experiments (M. Fromont-Racine and C. Saveanu, personal communication).How representative is our screening?
We consider that our library contains DNA fragments randomly distributed throughout the genome. Out of 84,086 clones tested, 11% (9,530) contain a DNA fragment cloned in-frame with the frame of the natural ORF (~68% of the genome corresponds to coding regions, and only one frame out of six corresponds to the natural frame), the others containing noncoding, out-of-frame or antisense DNA fragments. If we use the simplifying assumption that all genes are equally represented among the 9,530 clones (not taking into account the size diversity of genes), each of the 5,803 ORFs will be represented 1.64 times (9,530/5,803). The probability P x of encountering any gene x times is described by a Poisson distribution:
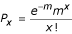
where m, the mean of the distribution, is 1.64. This is used to estimate the fraction of genes not encountered: for x = 0 and probability p = 0.19, the number of non-encountered genes = 1,126. Thus, by screening a total of 84,086 clones, we have encountered a maximum of 4,677 ORFs (5,803 - 1,126).
Additional data files
The following additional data are available with the online version of this article. Additional data file 1 contains lists and coordinates of the 493 in-frame fragments of annotated ORFs giving toxic phenotypes when overexpressed, and short description of their cognate genes. Additional data file 2 contains a list and description of the 221 DNA toxic inserts other than in-frame ORF fragments. Additional data file 3 gives a description of the peptides encoded by the 493 toxic ORF fragments, and of the cognate proteins. Additional data file 4 gives the content of the 57 groups of peptide inserts sharing similarities. Additional data file 5 gives a list and description of protein domains found only once among the toxic inserts. Additional data file 6 lists the genes selected in this work whose products are members of complexes [10]. Additional data file 7 lists genes selected in this work whose products are known as interacting with each other. Additional data file 8 contains the sequences of the oligonucleotides used in this work. Additional data file 9 contains a figure showing the phenotypes induced by overexpression of antiparallel ORF fragments before and after introduction of a stop codon upstream of the artificial ORFs.
References
- Saccharomyces Genome Database. [http://www.yeastgenome.org]
- Goffeau A, Barrell BG, Bussey H, Davis RW, Dujon B, Feldmann H, Galibert F, Hoheisel JD, Jacq C, Johnston M, et al: Life with 6000 genes. Science. 1996, 274: 546-567. 10.1126/science.274.5287.546.
Article PubMed CAS Google Scholar - Ross-Macdonald P, Coelho PS, Roemer T, Agarwal S, Kumar A, Jansen R, Cheung KH, Sheehan A, Symoniatis D, Umansky L, et al: Large-scale analysis of the yeast genome by transposon tagging and gene disruption. Nature. 1999, 402: 413-418. 10.1038/46558.
Article PubMed CAS Google Scholar - Velculescu VE, Zhang L, Zhou W, Vogelstein J, Basrai MA, Bassett DE, Hieter P, Vogelstein B, Kinzler KW: Characterization of the yeast transcriptome. Cell. 1997, 88: 243-251. 10.1016/S0092-8674(00)81845-0.
Article PubMed CAS Google Scholar - Lashkari DA, DeRisi JL, McCusker JH, Namath AF, Gentile C, Hwang SY, Brown PO, Davis RW: Yeast microarrays for genome wide parallel genetic and gene expression analysis. Proc Natl Acad Sci USA. 1997, 94: 13057-13062. 10.1073/pnas.94.24.13057.
Article PubMed CAS PubMed Central Google Scholar - Le Crom S, Devaux F, Marc P, Zhang X, Moye-Rowley WS, Jacq C: New insights into the pleiotropic drug resistance network from genome-wide characterization of the YRR1 transcription factor regulation system. Mol Cell Biol. 2002, 22: 2642-2649. 10.1128/MCB.22.8.2642-2649.2002.
Article PubMed CAS PubMed Central Google Scholar - Fromont-Racine M, Rain JC, Legrain P: Toward a functional analysis of the yeast genome through exhaustive two-hybrid screens. Nat Genet. 1997, 16: 277-282. 10.1038/ng0797-277.
Article PubMed CAS Google Scholar - Uetz P, Giot L, Cagney G, Mansfield TA, Judson RS, Knight JR, Lockshon D, Narayan V, Srinivasan M, Pochart P, et al: A comprehensive analysis of protein-protein interactions in Saccharomyces cerevisiae. Nature. 2000, 403: 623-627. 10.1038/35001009.
Article PubMed CAS Google Scholar - Ito T, Chiba T, Ozawa R, Yoshida M, Hattori M, Sakaki Y: A comprehensive two-hybrid analysis to explore the yeast protein interactome. Proc Natl Acad Sci USA. 2001, 98: 4569-4574. 10.1073/pnas.061034498.
Article PubMed CAS PubMed Central Google Scholar - Gavin AC, Bosche M, Krause R, Grandi P, Marzioch M, Bauer A, Schultz J, Rick JM, Michon AM, Cruciat CM, et al: Functional organization of the yeast proteome by systematic analysis of protein complexes. Nature. 2002, 415: 141-147. 10.1038/415141a.
Article PubMed CAS Google Scholar - Ho Y, Gruhler A, Heilbut A, Bader GD, Moore L, Adams SL, Millar A, Taylor P, Bennett K, Boutilier K, et al: Systematic identification of protein complexes in Saccharomyces cerevisiae by mass spectrometry. Nature. 2002, 415: 180-183. 10.1038/415180a.
Article PubMed CAS Google Scholar - Perrot M, Sagliocco F, Mini T, Monribot C, Schneider U, Shevchenko A, Mann M, Jeno P, Boucherie H: Two-dimensional gel protein database of Saccharomyces cerevisiae (update 1999). Electrophoresis. 1999, 20: 2280-2298. 10.1002/(SICI)1522-2683(19990801)20:11<2280::AID-ELPS2280>3.0.CO;2-Q.
Article PubMed CAS Google Scholar - Zhu H, Bilgin M, Snyder M: Proteomics. Annu Rev Biochem. 2003, 72: 783-812. 10.1146/annurev.biochem.72.121801.161511.
Article PubMed CAS Google Scholar - Ghaemmaghami S, Huh WK, Bower K, Howson RW, Belle A, Dephoure N, O'Shea EK, Weissman JS: Global analysis of protein expression in yeast. Nature. 2003, 425: 737-741. 10.1038/nature02046.
Article PubMed CAS Google Scholar - Wyrick JJ, Aparicio JG, Chen T, Barnett JD, Jennings EG, Young RA, Bell SP, Aparicio OM: Genome-wide distribution of ORC and MCM proteins in S. cerevisiae: high-resolution mapping of replication origins. Science. 2001, 294: 2357-2360. 10.1126/science.1066101.
Article PubMed CAS Google Scholar - Raghuraman MK, Winzeler EA, Collingwood D, Hunt S, Wodicka L, Conway A, Lockhart DJ, Davis RW, Brewer BJ, Fangman WL: Replication dynamics of the yeast genome. Science. 2001, 294: 115-121. 10.1126/science.294.5540.115.
Article PubMed CAS Google Scholar - Kumar A, Snyder M: Emerging technologies in yeast genomics. Nat Rev Genet. 2001, 2: 302-312. 10.1038/35066084.
Article PubMed CAS Google Scholar - Lucau-Danila A, Wysocki R, Roganti T, Foury F: Systematic disruption of 456 ORFs in the yeast Saccharomyces cerevisiae. Yeast. 2000, 16: 547-552. 10.1002/(SICI)1097-0061(200004)16:6<547::AID-YEA552>3.0.CO;2-2.
Article PubMed CAS Google Scholar - Winzeler EA, Shoemaker DD, Astromoff A, Liang H, Anderson K, Andre B, Bangham R, Benito R, Boeke JD, Bussey H, et al: Functional characterization of the S. cerevisiae genome by gene deletion and parallel analysis. Science. 1999, 285: 901-906. 10.1126/science.285.5429.901.
Article PubMed CAS Google Scholar - EUROSCARF index. [http://www.uni-frankfurt.de/fb15/mikro/euroscarf]
- Giaever G, Chu AM, Ni L, Connelly C, Riles L, Veronneau S, Dow S, Lucau-Danila A, Anderson K, Andre B, et al: Functional profiling of the Saccharomyces cerevisiae genome. Nature. 2002, 418: 387-391. 10.1038/nature00935.
Article PubMed CAS Google Scholar - Tong AH, Evangelista M, Parsons AB, Xu H, Bader GD, Page N, Robinson M, Raghibizadeh S, Hogue CW, Bussey H, et al: Systematic genetic analysis with ordered arrays of yeast deletion mutants. Science. 2001, 294: 2364-2368. 10.1126/science.1065810.
Article PubMed CAS Google Scholar - Tong AH, Lesage G, Bader GD, Ding H, Xu H, Xin X, Young J, Berriz GF, Brost RL, Chang M, et al: Global mapping of the yeast genetic interaction network. Science. 2004, 303: 808-813. 10.1126/science.1091317.
Article PubMed CAS Google Scholar - Akada R, Yamamoto J, Yamashita I: Screening and identification of yeast sequences that cause growth inhibition when overexpressed. Mol Gen Genet. 1997, 254: 267-274. 10.1007/s004380050415.
Article PubMed CAS Google Scholar - Herskowitz I: Functional inactivation of genes by dominant negative mutations. Nature. 1987, 329: 219-222. 10.1038/329219a0.
Article PubMed CAS Google Scholar - Ramer SW, Elledge SJ, Davis RW: Dominant genetics using a yeast genomic library under the control of a strong inducible promoter. Proc Natl Acad Sci USA. 1992, 89: 11589-11593.
Article PubMed CAS PubMed Central Google Scholar - Freeman K, Gwadz M, Shore D: Molecular and genetic analysis of the toxic effect of RAP1 overexpression in yeast. Genetics. 1995, 141: 1253-1262.
PubMed CAS PubMed Central Google Scholar - Liu H, Krizek J, Bretscher A: Construction of a GAL1-regulated yeast cDNA expression library and its application to the identification of genes whose overexpression causes lethality in yeast. Genetics. 1992, 132: 665-673.
PubMed CAS PubMed Central Google Scholar - Espinet C, de la Torre MA, Aldea M, Herrero E: An efficient method to isolate yeast genes causing overexpression-mediated growth arrest. Yeast. 1995, 11: 25-32. 10.1002/yea.320110104.
Article PubMed CAS Google Scholar - Stevenson LF, Kennedy BK, Harlow E: A large-scale overexpression screen in Saccharomyces cerevisiae identifies previously uncharacterized cell cycle genes. Proc Natl Acad Sci USA. 2001, 98: 3946-3951. 10.1073/pnas.051013498.
Article PubMed CAS PubMed Central Google Scholar - Gari E, Piedrafita L, Aldea M, Herrero E: A set of vectors with a tetracycline-regulatable promoter system for modulated gene expression in Saccharomyces cerevisiae. Yeast. 1997, 13: 837-848. 10.1002/(SICI)1097-0061(199707)13:9<837::AID-YEA145>3.0.CO;2-T.
Article PubMed CAS Google Scholar - Tatusov RL, Natale DA, Garkavtsev IV, Tatusova TA, Shankavaram UT, Rao BS, Kiryutin B, Galperin MY, Fedorova ND, Koonin EV: The COG database: new developments in phylogenetic classification of proteins from complete genomes. Nucleic Acids Res. 2001, 29: 22-28. 10.1093/nar/29.1.22.
Article PubMed CAS PubMed Central Google Scholar - Pawson T, Nash P: Assembly of cell regulatory systems through protein interaction domains. Science. 2003, 300: 445-452. 10.1126/science.1083653.
Article PubMed CAS Google Scholar - Primiano T, Baig M, Maliyekkel A, Chang BD, Fellars S, Sadhu J, Axenovich SA, Holzmayer TA, Roninson IB: Identification of potential anticancer drug targets through the selection of growth-inhibitory genetic suppressor elements. Cancer Cell. 2003, 4: 41-53. 10.1016/S1535-6108(03)00169-7.
Article PubMed CAS Google Scholar - De Hertogh B, Carvajal E, Talla E, Dujon B, Baret P, Goffeau A: Phylogenetic classification of transporters and other membrane proteins from Saccharomyces cerevisiae. Funct Integr Genomics. 2002, 2: 154-170. 10.1007/s10142-002-0060-8.
Article PubMed CAS Google Scholar - Malpertuy A, Tekaia F, Casaregola S, Aigle M, Artiguenave F, Blandin G, Bolotin-Fukuhara M, Bon E, Brottier P, de Montigny J, et al: Genomic exploration of the hemiascomycetous yeasts: 19. Ascomycete-specific genes. FEBS Lett. 2000, 487: 113-121. 10.1016/S0014-5793(00)02290-0.
Article PubMed CAS Google Scholar - Génolevures. [http://cbi.labri.fr/Genolevures/Genolevures.php]
- Comprehensive Yeast Genome Database. [http://mips.gsf.de/genre/proj/yeast]
- Cavaille J, Chetouani F, Bachellerie JP: The yeast Saccharomyces cerevisiae YDL112w ORF encodes the putative 2'-O-ribose methyltransferase catalyzing the formation of Gm18 in tRNAs. RNA. 1999, 5: 66-81. 10.1017/S1355838299981475.
Article PubMed CAS PubMed Central Google Scholar - Merino E, Balbas P, Puente JL, Bolivar F: Antisense overlapping open reading frames in genes from bacteria to humans. Nucleic Acids Res. 1994, 22: 1903-1908.
Article PubMed CAS PubMed Central Google Scholar - Cebrat S, Mackiewicz P, Dudek MR: The role of the genetic code in generating new coding sequences inside existing genes. Biosystems. 1998, 45: 165-176. 10.1016/S0303-2647(97)00072-5.
Article PubMed CAS Google Scholar - Kumar A, Harrison PM, Cheung KH, Lan N, Echols N, Bertone P, Miller P, Gerstein MB, Snyder M: An integrated approach for finding overlooked genes in yeast. Nat Biotechnol. 2002, 20: 58-63. 10.1038/nbt0102-58.
Article PubMed CAS Google Scholar - Oshiro G, Wodicka LM, Washburn MP, Yates JR, Lockhart DJ, Winzeler EA: Parallel identification of new genes in Saccharomyces cerevisiae. Genome Res. 2002, 12: 1210-1220. 10.1101/gr.226802.
Article PubMed CAS PubMed Central Google Scholar - Kessler MM, Zeng Q, Hogan S, Cook R, Morales AJ, Cottarel G: Systematic discovery of new genes in the Saccharomyces cerevisiae genome. Genome Res. 2003, 13: 264-271. 10.1101/gr.232903.
Article PubMed CAS PubMed Central Google Scholar - Alarcon CM, Heitman J, Cardenas ME: Protein kinase activity and identification of a toxic effector domain of the target of rapamycin TOR proteins in yeast. Mol Biol Cell. 1999, 10: 2531-2546.
Article PubMed CAS PubMed Central Google Scholar - Morgan SE, Lovly C, Pandita TK, Shiloh Y, Kastan MB: Fragments of ATM which have dominant-negative or complementing activity. Mol Cell Biol. 1997, 17: 2020-2029.
Article PubMed CAS PubMed Central Google Scholar - Thompson MJ, Lai WS, Taylor GA, Blackshear PJ: Cloning and characterization of two yeast genes encoding members of the CCCH class of zinc finger proteins: zinc finger-mediated impairment of cell growth. Gene. 1996, 174: 225-233. 10.1016/0378-1119(96)00084-4.
Article PubMed CAS Google Scholar - Drysdale CM, Duenas E, Jackson BM, Reusser U, Braus GH, Hinnebusch AG: The transcriptional activator GCN4 contains multiple activation domains that are critically dependent on hydrophobic amino acids. Mol Cell Biol. 1995, 15: 1220-1233.
Article PubMed CAS PubMed Central Google Scholar - Ouspenski II, Elledge SJ, Brinkley BR: New yeast genes important for chromosome integrity and segregation identified by dosage effects on genome stability. Nucleic Acids Res. 1999, 27: 3001-3008. 10.1093/nar/27.15.3001.
Article PubMed CAS PubMed Central Google Scholar - Bochner BR: New technologies to assess genotype-phenotype relationships. Nat Rev Genet. 2003, 4: 309-314. 10.1038/nrg1046.
Article PubMed CAS Google Scholar - Thierry A, Fairhead C, Dujon B: The complete sequence of the 8.2 kb segment left of MAT on chromosome III reveals five ORFs, including a gene for a yeast ribokinase. Yeast. 1990, 6: 521-534. 10.1002/yea.320060609.
Article PubMed CAS Google Scholar - Fairhead C, Llorente B, Denis F, Soler M, Dujon B: New vectors for combinatorial deletions in yeast chromosomes and for gap-repair cloning using 'split-marker' recombination. Yeast. 1996, 12: 1439-1457. 10.1002/(SICI)1097-0061(199611)12:14<1439::AID-YEA37>3.3.CO;2-F.
Article PubMed CAS Google Scholar - Raymond CK, Pownder TA, Sexson SL: General method for plasmid construction using homologous recombination. Biotechniques. 1999, 26: 134-138. 140-131
PubMed CAS Google Scholar - Povinelli CM, Gibbs RA: Large-scale sequencing library production: an adaptor-based strategy. Anal Biochem. 1993, 210: 16-26. 10.1006/abio.1993.1144.
Article PubMed CAS Google Scholar - Gietz RD, Schiestl RH, Willems AR, Woods RA: Studies on the transformation of intact yeast cells by the LiAc/SS-DNA/PEG procedure. Yeast. 1995, 11: 355-360. 10.1002/yea.320110408.
Article PubMed CAS Google Scholar - Fromont-Racine M, Mayes AE, Brunet-Simon A, Rain JC, Colley A, Dix I, Decourty L, Joly N, Ricard F, Beggs JD, Legrain P: Genome-wide protein interaction screens reveal functional networks involving Sm-like proteins. Yeast. 2000, 17: 95-110. 10.1002/1097-0061(20000630)17:2<95::AID-YEA16>3.0.CO;2-H.
Article PubMed CAS PubMed Central Google Scholar - Blandin G, Durrens P, Tekaia F, Aigle M, Bolotin-Fukuhara M, Bon E, Casaregola S, de Montigny J, Gaillardin C, Lepingle A, et al: Genomic exploration of the hemiascomycetous yeasts: 4. The genome of Saccharomyces cerevisiae revisited. FEBS Lett. 2000, 487: 31-36. 10.1016/S0014-5793(00)02275-4.
Article PubMed CAS Google Scholar - Hartley JL, Donelson JE: Nucleotide sequence of the yeast plasmid. Nature. 1980, 286: 860-865. 10.1038/286860a0.
Article PubMed CAS Google Scholar - Foury F, Roganti T, Lecrenier N, Purnelle B: The complete sequence of the mitochondrial genome of Saccharomyces cerevisiae. FEBS Lett. 1998, 440: 325-331. 10.1016/S0014-5793(98)01467-7.
Article PubMed CAS Google Scholar - Talla E, Tekaia F, Brino L, Dujon B: A novel design of whole-genome microarray probes for Saccharomyces cerevisiae which minimizes cross-hybridization. BMC Genomics. 2003, 4: 38-10.1186/1471-2164-4-38.
Article PubMed PubMed Central Google Scholar - Tekaia F, Blandin G, Malpertuy A, Llorente B, Durrens P, Toffano-Nioche C, Ozier-Kalogeropoulos O, Bon E, Gaillardin C, Aigle M, et al: Genomic exploration of the hemiascomycetous yeasts: 3. Methods and strategies used for sequence analysis and annotation. FEBS Lett. 2000, 487: 17-30. 10.1016/S0014-5793(00)02274-2.
Article PubMed CAS Google Scholar - Altschul SF, Madden TL, Schaffer AA, Zhang J, Zhang Z, Miller W, Lipman DJ: Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 1997, 25: 3389-3402. 10.1093/nar/25.17.3389.
Article PubMed CAS PubMed Central Google Scholar - Marchler-Bauer A, Anderson JB, DeWeese-Scott C, Fedorova ND, Geer LY, He S, Hurwitz DI, Jackson JD, Jacobs AR, Lanczycki CJ, et al: CDD: a curated Entrez database of conserved domain alignments. Nucleic Acids Res. 2003, 31: 383-387. 10.1093/nar/gkg087.
Article PubMed CAS PubMed Central Google Scholar - NCBI CD-Search. [http://www.ncbi.nlm.nih.gov/Structure/cdd/wrpsb.cgi]
- NCBI Conserved Domain Database. [http://www.ncbi.nlm.nih.gov/Structure/cdd/cdd.shtml]
- Letunic I, Goodstadt L, Dickens NJ, Doerks T, Schultz J, Mott R, Ciccarelli F, Copley RR, Ponting CP, Bork P: Recent improvements to the SMART domain-based sequence annotation resource. Nucleic Acids Res. 2002, 30: 242-244. 10.1093/nar/30.1.242.
Article PubMed CAS PubMed Central Google Scholar - Bateman A, Birney E, Cerruti L, Durbin R, Etwiller L, Eddy SR, Griffiths-Jones S, Howe KL, Marshall M, Sonnhammer EL: The Pfam protein families database. Nucleic Acids Res. 2002, 30: 276-280. 10.1093/nar/30.1.276.
Article PubMed CAS PubMed Central Google Scholar - Claros MG, von Heijne G: TopPred II: an improved software for membrane protein structure predictions. Comput Appl Biosci. 1994, 10: 685-686.
PubMed CAS Google Scholar - EMBOSS homepage. [http://www.hgmp.mrc.ac.uk/Software/EMBOSS]
- Hodges PE, McKee AH, Davis BP, Payne WE, Garrels JI: The Yeast Proteome Database (YPD): a model for the organization and presentation of genome-wide functional data. Nucleic Acids Res. 1999, 27: 69-73. 10.1093/nar/27.1.69.
Article PubMed CAS PubMed Central Google Scholar - Koonin EV, Fedorova ND, Jackson JD, Jacobs AR, Krylov DM, Makarova KS, Mazumder R, Mekhedov SL, Nikolskaya AN, Rao BS, et al: A comprehensive evolutionary classification of proteins encoded in complete eukaryotic genomes. Genome Biol. 2004, 5: R7-10.1186/gb-2004-5-2-r7.
Article PubMed PubMed Central Google Scholar
Acknowledgements
We thank F. Tekaia and N. Joly for suggestions and support during this work, E. Couvé for help with experiments, M. Fromont-Racine and C. Saveanu for helpful discussions and communications of unpublished data, and S. Marchiset, C. Lequatre and L. Oreus for media supply and technical help. This work was supported in part by the EUROFAN2 project (Bio4-CT97-2294) from the European Commission (DGXII). E.T. was supported by the European contract CYGD (QLRI-CT 1999-01333), R.K. is a recipient of a CNRS-BDI fellowship. B.D. is a member of the Institut Universitaire de France.
Author information
Authors and Affiliations
- Unité de Génétique Moléculaire des Levures (URA2171 CNRS and UFR 927 Université Pierre et Marie Curie), France
Jeanne Boyer, Gwenaël Badis, Cécile Fairhead, Emmanuel Talla, Emmanuelle Fabre, Gilles Fischer, Christophe Hennequin, Romain Koszul, Ingrid Lafontaine, Odile Ozier-Kalogeropoulos, Miria Ricchetti, Guy-Franck Richard, Agnès Thierry & Bernard Dujon - Department of Structure and Dynamics of Genomes, Unité de Génétique des Interactions Macromoléculaires (URA2171 CNRS), Institut Pasteur, 25 rue du Dr Roux, 75724, Paris-Cedex 15, France
Gwenaël Badis & Florence Hantraye - CNRS-Laboratoire de Chimie Bactérienne, 31 Chemin Joseph Aiguier, 13402, Marseille-Cedex 20, France
Emmanuel Talla - Laboratoire de Parasitologie, Faculté de Médecine St-Antoine, 27 rue de Chaligny, 75012, Paris, France
Christophe Hennequin - Unité de Génétique et Biochimie du Développement, Institut Pasteur, 25 rue du Dr Roux, 75724, Paris-Cedex 15, France
Miria Ricchetti
Authors
- Jeanne Boyer
You can also search for this author inPubMed Google Scholar - Gwenaël Badis
You can also search for this author inPubMed Google Scholar - Cécile Fairhead
You can also search for this author inPubMed Google Scholar - Emmanuel Talla
You can also search for this author inPubMed Google Scholar - Florence Hantraye
You can also search for this author inPubMed Google Scholar - Emmanuelle Fabre
You can also search for this author inPubMed Google Scholar - Gilles Fischer
You can also search for this author inPubMed Google Scholar - Christophe Hennequin
You can also search for this author inPubMed Google Scholar - Romain Koszul
You can also search for this author inPubMed Google Scholar - Ingrid Lafontaine
You can also search for this author inPubMed Google Scholar - Odile Ozier-Kalogeropoulos
You can also search for this author inPubMed Google Scholar - Miria Ricchetti
You can also search for this author inPubMed Google Scholar - Guy-Franck Richard
You can also search for this author inPubMed Google Scholar - Agnès Thierry
You can also search for this author inPubMed Google Scholar - Bernard Dujon
You can also search for this author inPubMed Google Scholar
Corresponding author
Correspondence toJeanne Boyer.
Electronic supplementary material
Authors’ original submitted files for images
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Boyer, J., Badis, G., Fairhead, C. et al. Large-scale exploration of growth inhibition caused by overexpression of genomic fragments in Saccharomyces cerevisiae .Genome Biol 5, R72 (2004). https://doi.org/10.1186/gb-2004-5-9-r72
- Received: 24 May 2004
- Revised: 13 July 2004
- Accepted: 26 July 2004
- Published: 31 August 2004
- DOI: https://doi.org/10.1186/gb-2004-5-9-r72