Database Per Service Pattern for Microservices (original) (raw)
Last Updated : 23 Jul, 2025
The "Database Per Service" pattern is a critical concept in microservices architecture, promoting decentralized data management by assigning a unique database to each service. This approach enhances data encapsulation, autonomy, and scalability, allowing services to evolve independently without impacting others. By isolating databases, the pattern supports diverse data storage technologies tailored to specific service needs, improving performance and resilience. Understanding this pattern is essential for designing robust and flexible microservices systems, ensuring efficient data handling and service independence.
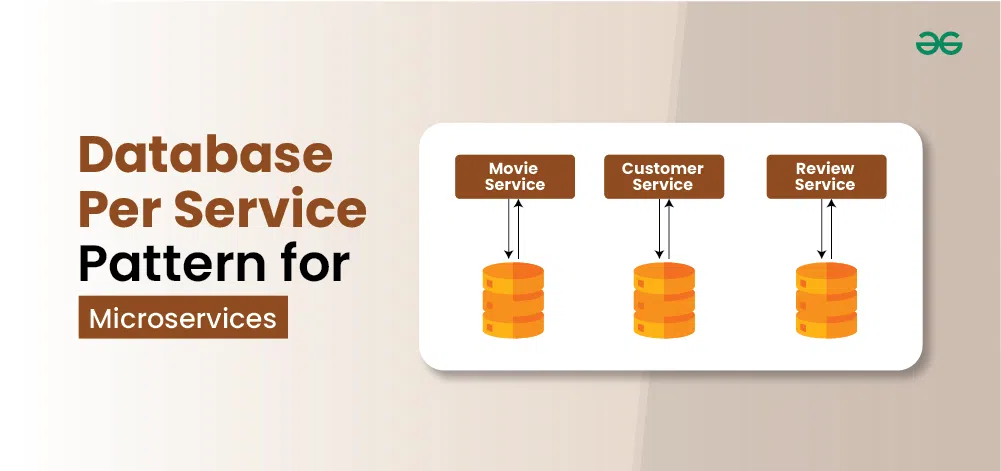
Database Per Service Pattern for Microservices
Important Topics for Database Per Service Pattern for Microservices
- What is Database Per Service Pattern?
- Importance of Database Per Service Pattern in Microservices Architecture
- Steps for Implementing the Database Per Service Pattern
- Data Management Techniques
- Real-World Examples of the Database Per Service Pattern
- Conclusion
- FAQs for Database Per Service Pattern for Microservices
What is Database Per Service Pattern?
The Database Per Service Pattern is a design principle in microservices architecture where each microservice is assigned its own exclusive database. This ensures that each service operates independently without relying on a central, shared database. The database can be any type (SQL, NoSQL, etc.) that best suits the needs of the specific microservice.
Key Objectives of Database Per Service Pattern:
- **Independence: Each microservice has a dedicated database, preventing schema changes in one service from impacting others.
- **Encapsulation: Data is fully encapsulated within the microservice, with access provided only through well-defined APIs.
- **Technology Choice: Each service can select the database technology that best fits its needs.
- **Scalability and Performance: Databases can be scaled independently based on each service’s requirements.
- **Resilience and Fault Isolation: Database failures in one service do not affect others, enhancing system resilience.
Database Per Service Pattern vs. other Database Patterns in Microservices
| Aspect | Database Per Service Pattern | Shared Database Pattern | SAGA Pattern (for Distributed Transactions) |
|---|---|---|---|
| Definition | Each microservice has its own private database | Multiple microservices share a single database | Manages transactions across multiple microservices with independent databases |
| Coupling | Loose coupling between services | Tight coupling between services | Loose coupling between services |
| Schema Management | Independent schema evolution for each service | Shared schema, changes affect all services | Independent schema evolution for each service |
| Scalability | Easier to scale services independently | Difficult to scale services independently | Easier to scale services independently |
| Performance | Optimized performance, no contention | Risk of data contention and performance bottlenecks | Optimized performance, no contention |
| Fault Isolation | Improved fault isolation | Failure in the database affects all services | Improved fault isolation |
| Technological Choice | Each service can choose its own database technology | Limited, as all services must use the same database technology | Each service can choose its own database technology |
| Data Consistency | Challenges in maintaining data consistency across services | Easier to enforce data consistency across services | Requires complex handling of distributed transactions |
| Complexity | More complex to manage multiple databases | Simpler to manage a single database | Most complex, requires careful handling of transactions |
| Use Case | Suitable for complex, modular systems with diverse needs | Suitable for simpler systems with tightly related services | Suitable for systems requiring complex distributed transactions |
Importance of Database Per Service Pattern in Microservices Architecture
The Database Per Service Pattern plays a critical role in microservices architecture by addressing key concerns related to data management and service independence. In a microservices environment, where services are designed to be small, autonomous units, data management becomes a vital aspect. The Database Per Service Pattern ensures that each microservice manages its own data, fostering an environment where services can operate independently without interfering with one another.
1. Loose Coupling and Independent Scaling
The Database Per Service Pattern promotes loose coupling and independent scaling, which are essential in microservices architecture.
- **Loose Coupling:
- **Minimized Dependencies: Services do not share a common database schema, reducing dependencies and simplifying updates.
- **Independent Deployment: Services can be deployed independently, allowing for separate deployment cycles.
- **Independent Scaling:
- **Tailored Scaling: Databases can be scaled based on the specific needs of each service.
- **Resource Optimization: Efficient allocation of resources based on service-specific requirements.
2. Impact on Service Autonomy and Data Encapsulation
The Database Per Service Pattern has a profound impact on service autonomy and data encapsulation, which are essential for maintaining a robust and flexible microservices architecture.
- **Service Autonomy:
- **Self-sufficiency: Services are self-contained units that include both business logic and data management. This self-sufficiency allows teams to develop, test, and deploy services independently.
- **Failure Isolation: If one service fails, its failure is isolated to its own database, reducing the risk of cascading failures across the system. This isolation enhances the overall resilience of the system.
- **Data Encapsulation:
- **Encapsulated Data Management: Each service handles its data internally, exposing only necessary data through APIs. This encapsulation ensures data integrity and security, as external access to the database is restricted.
- **Clear Interfaces: The use of APIs for data interaction promotes clear and well-defined interfaces between services, simplifying integration and reducing the risk of errors.
Benefits of Database Per Service Pattern for Microservices
- **Improved Scalability and Performance: Independent scaling and optimized performance based on service needs.
- **Enhanced Fault Isolation and Resilience: Better fault tolerance and service independence.
- **Simplified Service Evolution and Deployment: Independent evolution and deployment of services.
- **Alignment with Domain-Driven Design: Supports bounded contexts and domain-specific data management.
Challenges of Database Per Service Pattern for Microservices
- **Increased Complexity in Data Management and Consistency: Managing multiple databases and ensuring consistency is complex.
- **Potential for Data Duplication: Risk of redundant data and synchronization challenges.
- **Complex Transactions and Queries: Difficulties in handling distributed transactions and cross-service queries.
- **Need for Robust Synchronization Mechanisms: Requires mechanisms for ensuring data consistency and synchronization.
Steps for Implementing the Database Per Service Pattern
Implementing the Database Per Service Pattern involves several key steps to ensure that each microservice operates with its own database while maintaining data consistency and system coherence. Here is a step-by-step guide to effectively implement this pattern:
Step 1: Designing the Service Boundaries
- **Identify Business Domains: Begin by analyzing the business requirements and identifying distinct business domains or functionalities. Each microservice should correspond to a specific domain or bounded context.
- **Define Service Boundaries: Clearly define the boundaries for each service based on the identified domains. Ensure that each service has a well-defined responsibility and does not overlap with other services.
- **Establish APIs: Design APIs for each service to facilitate interaction and data exchange between services. Define the API contracts and ensure that services interact through these well-defined interfaces.
Step 2: Selecting Appropriate Database Technologies for Each Service
- **Evaluate Requirements: Assess the specific data requirements and workload characteristics of each service. Consider factors such as data volume, transaction needs, and query complexity.
- **Choose Database Type: Select the database technology that best fits the needs of each service. Options include SQL databases (e.g., PostgreSQL, MySQL) for transactional requirements and NoSQL databases (e.g., MongoDB, Cassandra) for high-volume or unstructured data.
- **Ensure Compatibility: Ensure that the chosen database technology is compatible with the service’s technology stack and can handle the expected load and performance requirements.
Step 3: Defining Data Ownership and Schema Design
- **Design Schemas: Design the database schema for each service based on its data needs and responsibilities. Ensure that the schema supports the service's specific functionality and data requirements.
- **Define Data Ownership: Clearly define which service owns which data. Each service should manage its own data and have exclusive access to its database.
- **Avoid Shared Data: Minimize or eliminate the need for shared data between services. If shared data is unavoidable, consider mechanisms such as API calls or event-driven updates to synchronize data.
Step 4: Implementing Communication Between Services
- **Choose Communication Methods: Decide on the communication methods for inter-service interactions. Options include synchronous methods (e.g., RESTful APIs, gRPC) and asynchronous methods (e.g., messaging queues, event streams).
- **API Gateways****:** Implement an API gateway to handle requests to various services, manage authentication, and route requests to the appropriate microservices.
- **Message Brokers****:** Use message brokers (e.g., RabbitMQ, Apache Kafka) for asynchronous communication and to decouple services. This approach helps in handling event-driven interactions and processing background tasks.
Step 5: Handling Data Consistency and Synchronization
- **Consistency Models****:** Choose the appropriate consistency model based on the needs of the system. Options include strong consistency (e.g., distributed transactions) or eventual consistency (e.g., using event sourcing).
- **Event Sourcing: Implement event sourcing to capture and store all changes to the data as a sequence of events. This helps in maintaining consistency and recovering from failures.
- **Data Synchronization: Use techniques such as data replication, synchronization services, or periodic batch processes to keep data consistent across services if necessary.
Step 6: Monitoring and Managing Databases for Each Service
- **Set Up Monitoring: Implement monitoring tools to track the health and performance of each service's database. Use metrics such as query performance, resource utilization, and error rates.
- **Implement Backup and Recovery: Ensure that each database has proper backup and recovery procedures in place to protect against data loss and enable quick recovery in case of failures.
- **Manage Resources: Continuously monitor and manage database resources to handle changing loads and ensure optimal performance. This may include scaling resources, optimizing queries, and performing regular maintenance.
Data Management Techniques
Effective data management is crucial for maintaining the integrity and performance of a microservices architecture. Here’s an overview of techniques and strategies for managing data consistency, replication, synchronization, and handling cross-service queries:
1. Techniques for Managing Data Consistency
- **Eventual Consistency****:**
- Eventual Consistency is a model for distributed systems where updates are spread across all replicas over time, ensuring that all nodes eventually reach the same state.
- Unlike strong consistency, which requires immediate synchronization, eventual consistency allows temporary discrepancies.
- This model is typically implemented using messaging systems like Apache Kafka or RabbitMQ, or through event sourcing, with each service updating its database asynchronously.
- **Distributed Transactions:
- Distributed transactions involve coordinating transactions across multiple services and databases to ensure the ACID properties—atomicity, consistency, isolation, and durability.
- Implementation often relies on two-phase commit (2PC) protocols or distributed transaction managers to manage and commit transactions across different services.
- **SAGA Pattern****:**
- The SAGA pattern addresses distributed transactions by breaking them into a series of smaller, isolated transactions known as sagas, with compensating transactions to handle any failures that occur.
- In this approach, each service performs its local transaction and publishes events to initiate subsequent transactions or compensations in other services.
- The sequence and coordination of these sagas can be managed through either orchestration or choreography.
2. Strategies for Data Replication and Synchronization
- **Data Replication:
- Data replication involves copying and maintaining data across multiple databases or nodes to ensure redundancy and availability.
- This process is implemented using strategies such as master-slave (primary-replica) or peer-to-peer replication, depending on the database technology in use.
- Effective replication ensures that data remains consistent and efficiently synchronized across all nodes.
- **Data Synchronization:
- Data synchronization involves ensuring that multiple databases or data stores remain consistent with each other, even in distributed environments.
- This is achieved through techniques such as periodic batch processes, real-time data streaming, or change data capture (CDC) to propagate updates between services.
- Data synchronization is crucial in systems where data is frequently updated and must be kept consistent across different services.
3. Approaches to Handle Cross-Service Queries and Reporting
- **CQRS (Command Query Responsibility Segregation):
- CQRS (Command Query Responsibility Segregation) separates read (query) and write (command) operations into distinct models to optimize data handling and scalability.
- In this pattern, separate databases or data models are used for reading and writing operations.
- Write operations update the write model, while read operations query the read model, with synchronization managed between the two models as needed.
- **Data Lakes:
- A data lake is a centralized repository that stores raw data from various sources in its native format, facilitating advanced analytics and reporting.
- Implementation involves aggregating data from multiple microservices into the data lake through ETL (Extract, Transform, Load) processes.
- Tools like Hadoop, AWS S3, or Azure Data Lake are commonly used for storage and processing.
- **Materialized Views:
- Materialized views are precomputed and stored query results that can be periodically refreshed to provide fast access to aggregated or computed data.
- Implementation involves creating materialized views in the database to hold the results of complex queries or aggregations, with periodic or trigger-based refreshes to ensure up-to-date information. They are particularly useful in scenarios that require quick access to precomputed data, such as dashboards or reporting systems.
Real-World Examples of the Database Per Service Pattern
1. Netflix
- **Scalability: By using the Database Per Service Pattern, Netflix can scale individual services independently based on their load and performance requirements. This approach allows Netflix to handle massive amounts of user data and high traffic volumes efficiently.
- **Fault Tolerance: The separation of databases ensures that issues in one service do not impact others, enhancing the overall resilience of the platform.
- **Flexibility: Netflix can use different database technologies suited to each service’s specific needs, optimizing performance and resource utilization.
2. Amazon
- **Performance Optimization: Amazon’s approach allows them to optimize database performance for different services, handling large-scale transactions and search operations efficiently.
- **Scalability: The ability to scale individual services independently helps Amazon manage peak traffic periods and maintain high availability.
- **Resilience: Isolating databases reduces the risk of system-wide failures and enhances the overall fault tolerance of the platform.
Conclusion
The Database Per Service Pattern is crucial in microservices architecture, offering benefits like improved scalability, resilience, and service independence. By giving each microservice its own database, it enables optimized performance, fault isolation, and flexible service evolution. Key points discussed include the pattern's advantages, such as independent scaling and enhanced fault tolerance, alongside challenges like data management complexity. Examples from Netflix and Amazon highlight its effective application in handling large-scale systems. Adopting this pattern helps create scalable, resilient, and modular systems, crucial for managing modern digital demands.