Design Distributed Cache | System Design (original) (raw)
Last Updated : 4 May, 2026
Designing a Distributed Cache system involves building a fast, scalable, and reliable layer to store frequently accessed data. It helps reduce latency and improves overall system performance.
- Focus on scalability and fault tolerance for handling large traffic.
- Optimize data access speed using efficient caching strategies.
Caching
In computing, a cache is a high-speed storage layer that temporarily stores frequently accessed data to improve performance. It helps serve future requests faster compared to fetching data from the primary storage.
- Stores frequently used or recently accessed data.
- Reduces latency by avoiding repeated data retrieval from the main source.
Distributed Caching
Distributed caching is a technique where cached data is stored across multiple servers to improve scalability and performance. It reduces load on the main database and speeds up data access.
- Distributes cache across multiple nodes for better scalability.
- Reduces latency by serving frequently accessed data faster.
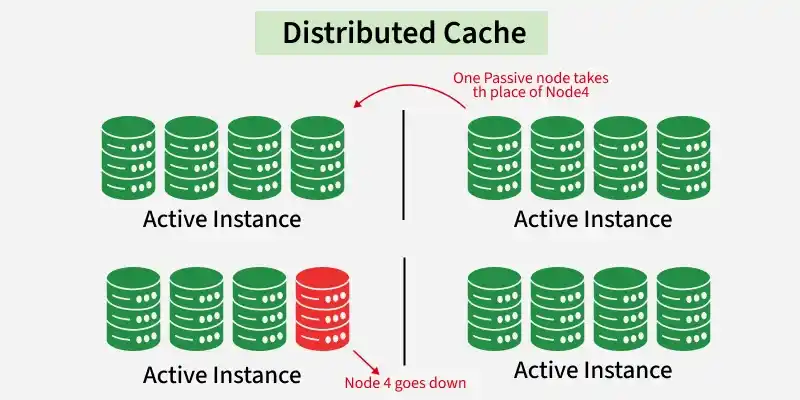
Distributed Cache
1. System Requirements
This section defines what the distributed cache system should do and how well it should perform under different conditions.
1. Functional Requirements for Distributed Cache Design
Functional Requirements define what the cache system must do to meet application needs.
- **Read Data: Quickly retrieve data from the cache.
- **Write Data: Store data into the cache.
- **Eviction Policy: Automatically evict least recently/frequently used items.
- **Replication: Replicate data across multiple nodes for fault tolerance.
- **Node Management: Add and remove cache nodes dynamically.
2. Non-Functional Requirements for Distributed Cache Design
Non-Functional Requirements define how well the cache system performs under various conditions.
- **Performance: Low latency for read and write operations.
- **Scalability: System should scale horizontally by adding more nodes.
- **Reliability: Ensure high availability and fault tolerance.
- **Durability: Persist data if required.
- **Security: Secure access to the cache system.
2. Use Case Diagram
A use case diagram helps visualize the interactions between users and the system.
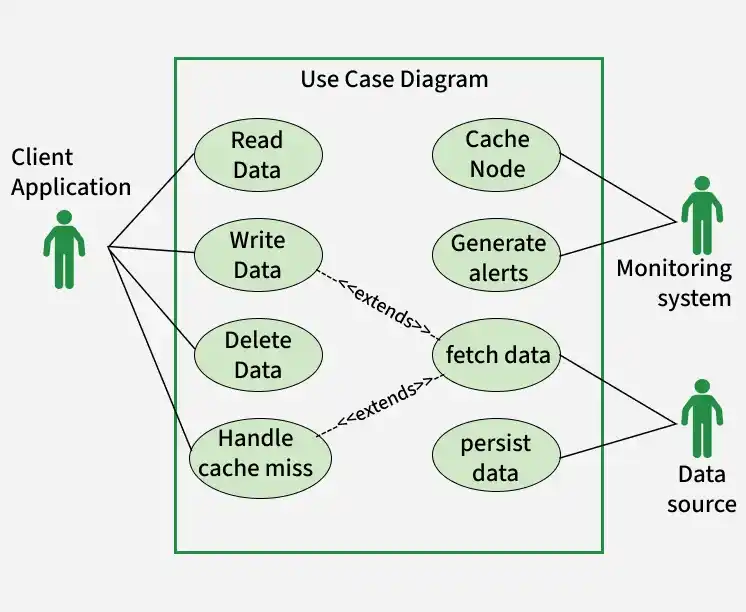
Use Case diagram
3. Capacity Estimation
Capacity estimation involves calculating the expected load on the system.
1. Traffic Estimate
Estimate read and write requests per second to ensure cache handles the expected load.
- **Read Traffic: Estimate the number of read requests per second.
- **Write Traffic: Estimate the number of write requests per second.
For example, if we expect 10,000 reads per second and 1,000 writes per second, our cache should handle this load.
2. Storage Estimate
Determine the total data size to be stored in the cache.
- **Data Size: Estimate the average size of each cache entry.
- **Total Data: Calculate the total amount of data to be stored in the cache.
If each entry is 1KB and we have 1 million entries, the total storage required is 1GB.
3. Bandwidth Estimate
Calculate the required bandwidth for read and write operations.
- **Read Bandwidth: Calculate the bandwidth needed for read operations.
- **Write Bandwidth: Calculate the bandwidth needed for write operations.
For example, if each read operation is 1KB and we have 10,000 reads per second, the read bandwidth is 10MB/s.
4. Memory Estimate
Determine memory requirements per node and across the cluster.
- **Node Memory: Estimate the amount of memory required per node.
- **Total Memory: Calculate the total memory required across all nodes.
If each node handles 10GB of data and we have 10 nodes, the total memory required is 100GB.
4. High-Level Design
The high-level design of a distributed cache system outlines the overall architecture, key components, and their interactions. It focuses on the big picture, ensuring that the system is scalable, fault-tolerant, and efficient. A high-level design outlines the overall architecture of the system.
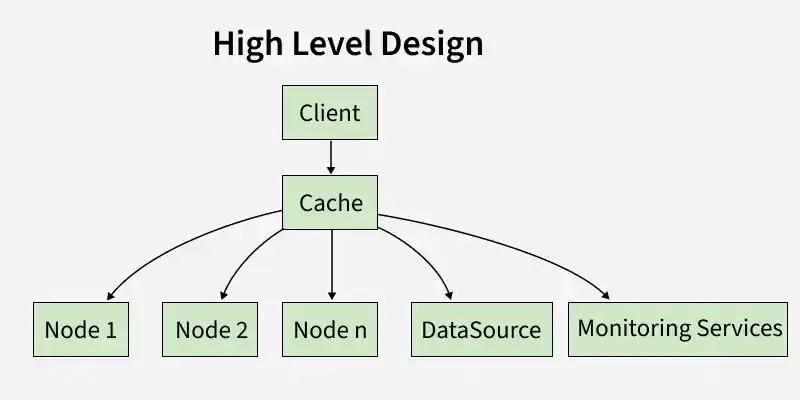
HLD
The high-level design of a distributed cache system, as illustrated in the above diagram, outlines the major components and their interactions to achieve a scalable, fault-tolerant, and efficient caching mechanism. Key components include:
- **Client: The client is any application or service that interacts with the cache system to perform read and write operations and sends requests to retrieve or update data.
- **Cache: This is the central component that manages the distributed caching logic, handles read/write operations, forwards requests to appropriate nodes, and ensures data consistency across the system.
- **Nodes (Node 1, Node 2, …, Node n): These are individual servers or instances that store cached data in-memory like Redis or Memcached and handle read/write requests for their portion of the cache.
- **Data Source: Represents the persistent backend database; if a cache miss occurs, data is fetched from the source and cached for future requests to improve performance.
- **Monitoring Service: Responsible for tracking cache system performance and health, collecting metrics like cache hits, misses, and node status to ensure efficient operation.
5. Low-Level Design
The low-level design (LLD) of the distributed cache system, as depicted in the diagram provided below, outlines the detailed interactions and responsibilities of each component in the system. This design delves into specific classes or modules, their functions, and how they collaborate to achieve the desired functionality. A low-level design provides detailed descriptions of system components and interactions.
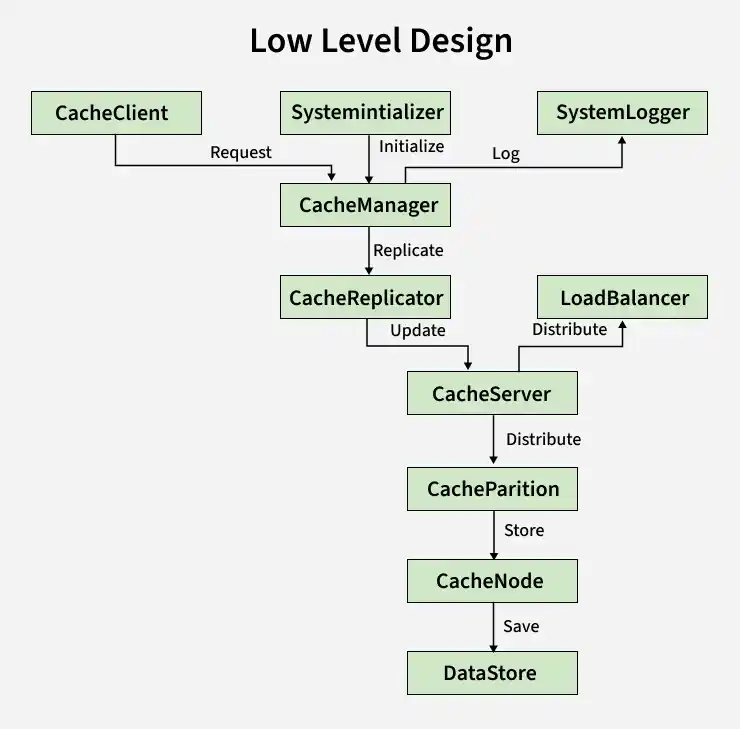
LLD
Components of the Low-Level Design include:
- **CacheClient: Initiates requests for data retrieval or updates and interacts with the CacheManager to perform operations.
- **SystemInitializer: Sets up and initializes the cache system, ensuring all components are configured and ready to handle requests.
- **SystemLogger: Logs system activities and events, useful for debugging and monitoring purposes.
- **CacheManager: Central coordinator for cache operations, receives requests from CacheClient, forwards them to appropriate components, and manages overall cache logic.
- **CacheReplicator: Handles data replication to ensure fault tolerance and consistent replication across multiple CacheNodes.
- **Load Balancer: Distributes incoming requests evenly across multiple CacheServers to ensure efficient resource utilization and prevent overloading.
- **CacheServer: Manages one or more CachePartitions and acts as an intermediary between the CacheManager and CachePartitions.
- **CachePartition: Subdivision of a CacheServer that stores a subset of cache data and ensures proper storage and retrieval.
- **CacheNode: Actual storage entity within a CachePartition, stores data in-memory, and handles CRUD operations.
- **DataStore: Persistent backend database providing durable storage and serving as a fallback for cache misses.
6. Database Design
A distributed cache system combines in-memory storage with backend databases to provide fast data access and durability. Its design ensures data consistency, fault tolerance, and efficient cache management, often integrating with databases for persistence.
CacheEntry Table
- **Purpose: Stores cache data persistently.
- **key: Unique identifier for each cache entry, ensuring uniqueness in the cache.
- **value: The actual cached data, often stored as text or binary.
- **expiration_time: Timestamp when the cache entry becomes invalid, aiding eviction.
- **created_at: Timestamp when the cache entry was created, useful for auditing and management.
- **updated_at: Timestamp when the cache entry was last updated, automatically refreshed on modification.
**SQL of above database table:
SQL `
CREATE TABLE CacheEntry ( key VARCHAR(255) PRIMARY KEY, value TEXT, expiration_time TIMESTAMP, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
`
7. Microservices and APIs
In a distributed cache system, microservices play a crucial role in ensuring modularity, scalability, and maintainability. Each microservice handles a specific set of functionalities and interacts with other microservices through well-defined APIs.
1. Cache Service
The Cache Service is responsible for handling read and write operations on the cache.
**1. Set Cache Data API:
**Endpoint: POST /cache
**Request:
Request `
{ "key": "string", "value": "string", "ttl": "integer" // Time-to-live in seconds }
`
**Response:
Response `
{ "status": "success", "message": "Data cached successfully." }
`
**2. Get Cache Data API:
Endpoint: GET /cache/{key}
**Request: None (key is part of the URL)
**Response:
Response `
{ "key": "string", "value": "string", "ttl": "integer" // Remaining time-to-live in seconds }
`
**3. Delete Cache Data API:
Endpoint: DELETE /cache/{key}
**Request: None (key is part of the URL)
**Response:
Response `
{ "status": "success", "message": "Data deleted successfully." }
`
2. Replication Service
The Replication Service manages the replication of data across multiple cache nodes to ensure data availability and fault tolerance.
**1. Replicate Data API:
Endpoint: POST /replicate
**Request:
Request `
{ "key": "string", "value": "string" }
`
**Response:
Response `
{ "status": "success", "message": "Data replicated successfully." }
`
**2. Get Replication Status API
Endpoint: GET /replication/status/{key}
**Request: None (key is part of the URL)
**Response:
Response `
{ "key": "string", "replication_status": "string" // e.g., "completed", "in_progress", "failed" }
`
3. Node Management Service
The Node Management Service handles the addition and removal of cache nodes, ensuring the system can scale dynamically.
**1. Add Node API
Endpoint: POST /node/add
**Request:
Request `
{ "node_id": "string", "node_address": "string" }
`
**Response:
Response `
{ "status": "success", "message": "Node added successfully." }
`
**2. Remove Node API
Endpoint: DELETE /node/remove/{node_id}
**Request: None (node_id is part of the URL)
**Response:
Response `
{ "status": "success", "message": "Node removed successfully." }
`
4. Coordinator Service
The Coordinator Service manages consistent hashing, rebalancing, and overall coordination of the cache nodes.
**1. Rebalance Data API
Endpoint: POST /rebalance
**Request:
Request `
{ "action": "start" // or "stop" to halt rebalancing }
`
**Response:
Response `
{ "status": "success", "message": "Rebalancing initiated." }
`
**2. Get Rebalance Status
Endpoint: GET /rebalance/status
**Request: None
**Response:
Response `
{ "rebalance_status": "string" // e.g., "in_progress", "completed", "not_started" }
`
5. Monitoring and Management Service
This service tracks performance metrics and health status of the cache system, providing insights for administrators.
**1. Get Cache Metrics API
Endpoint: GET /metrics
**Request: None
**Response:
Response `
{ "cache_hits": "integer", "cache_misses": "integer", "node_health": [ { "node_id": "string", "status": "string" // e.g., "healthy", "unhealthy" } ] }
`
**2. Get Node Health
Endpoint: GET /node/health/{node_id}
**Request: None (node_id is part of the URL)
**Response:
Response `
{ "node_id": "string", "status": "string" // e.g., "healthy", "unhealthy" }
`
8. Scalability for Distributed Cache Design
To ensure scalability, the system should support horizontal scaling, load balancing, and efficient data distribution.
- **Horizontal Scaling: Add nodes dynamically to the cache cluster and rebalance data using consistent hashing to minimize movement.
- **Load Balancing: Distribute client requests evenly across cache nodes with a load balancer.
- **Efficient Data Distribution: Use consistent hashing to evenly distribute data across nodes and reduce rebalancing efforts.