Types of Database Replication (original) (raw)
Last Updated : 17 Apr, 2026
Database replication is the process of copying and maintaining data across multiple database servers to ensure reliability and consistent data access even in case of failures. It helps improve system resilience and supports efficient data management in distributed environments.
- Enhances system performance and scalability by distributing read operations across multiple replicas in high-traffic systems.
- Ensures disaster recovery and continuous service availability by maintaining synchronized copies of data across servers.
**Example: an e-commerce website uses a primary database to handle order processing, while replica databases store copies of the same data. This ensures that users can still view products and place orders even if one server fails, improving availability and reliability.
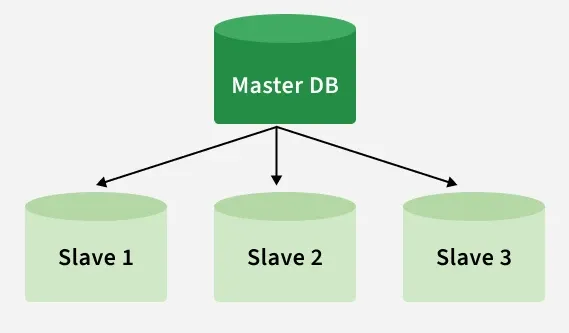
Replication
Types of Database Replication
Types of Database Replication include Single-leader (Master-Slave), Multi-leader (Master-Master), and Peer-to-Peer replication.
1. Master-Slave Replication
In master–slave replication, all write operations are handled by the master database, and the updated data is synchronized to slave databases.
- Master handles all inserts, updates, and deletes, while slaves maintain replicated copies of the master data.
- Improves read performance by using slaves for queries.
- Provides basic fault tolerance and is commonly used in read-heavy applications.
**Example: Imagine a library with two branches
- **Master branch: The master branch is the main library that maintains the original and updated collection of books.
- **Slave branch: This is a smaller branch that receives copies of new books from the master branch at regular intervals. Students can only borrow books that are physically present in the slave branch.
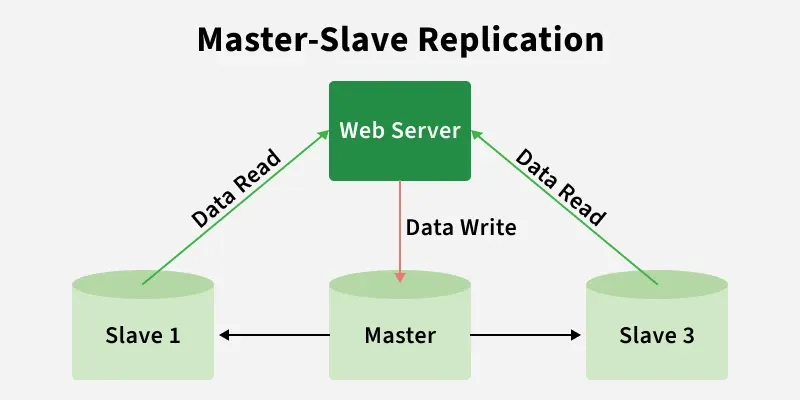
Master-Slave Replication
Working
Master-slave replication works by copying data changes from a primary database (master) to one or more secondary databases (slaves) in a sequential manner.
- **Write Operation: Master records changes in its transaction log.
- **Log Reading: Replication thread reads the transaction log.
- **Data Transfer: Changes are sent from master to slave over the network.
- **Sync Update: Slave applies the received changes to its data.
- **Confirmation: Slave sends acknowledgment back to the master.
Applications
This architecture is widely used in systems that require high performance and read scalability.
- **E-commerce Websites: Slave servers handle read-heavy tasks like product listings, while the master manages write operations such as orders.
- **Content Management Systems: Read requests for content are served by slave servers, and all content updates are handled by the master server.
Benefits
Master–slave replication provides several advantages in distributed database systems.
- **High Availability: A slave database can be promoted to become the new master in the event of a master database failure, ensuring high availability so that the system continues to function and remain accessible.
- **Scalability: The system can manage additional users and data without compromising speed by shifting read operations to slave databases, improving scalability and reducing the load on the master database.
- **Data Consistency: Master-slave replication keeps all copies of the data up to date by replicating changes from the master database to slave databases, ensuring strong data consistency across multiple databases.
Challenges
Despite its advantages, this approach also has some limitations.
- **Replication Lag: Data inconsistencies may result from a latency (replication lag) between the time a change is performed on the master database and when it is replicated to the slave databases.
- **Single Point of Failure: The master database acts as a single point of failure; if it goes down, the system may stop functioning until another database is promoted as the new master
- **Limited Write Scalability: Since write operations are limited to the master database, it can become a bottleneck for write-heavy applications.
2. Master-Master Replication
Bidirectional replication allows two or more master databases to accept write operations, where changes made on one master are automatically synchronized with the others.
- All master databases can handle read and write operations, and updates on one master are replicated to other masters.
- Improves availability and fault tolerance while requiring conflict resolution to maintain data consistency.
- More complex to manage compared to master–slave replication.
**Example: Like two air traffic controllers, both have equal authority, share updates continuously, and can take over for each other to ensure smooth, uninterrupted operations.
- Both controllers have full control over their sectors.
- Continuous communication prevents conflicts.
- Shared responsibility ensures reliability.
- One can fully take over if the other is unavailable.
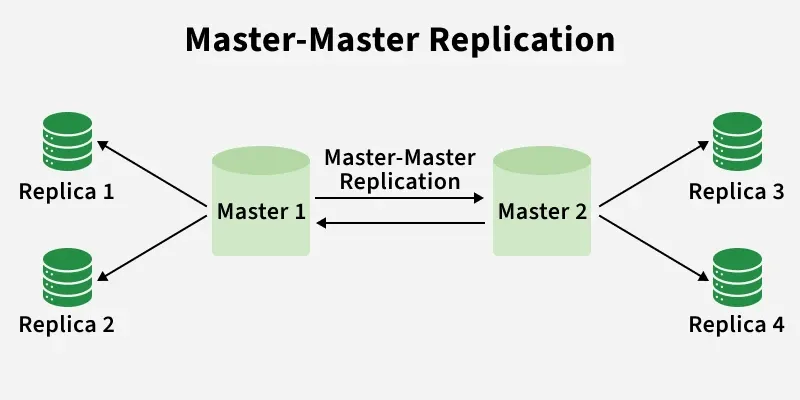
Master-Master Replication
Working
Multi-master replication allows multiple databases to act as masters and accept write operations simultaneously.
- **Write Operation: A master records inserts, updates, or deletes in its transaction log.
- **Replication Process: Changes are read from the log and prepared for replication.
- **Network Transfer: Updates are sent to other master nodes (sync or async).
- **Apply Changes: Receiving masters apply updates to their own data.
- **Conflict Resolution: Conflicting simultaneous writes are handled to ensure consistency.
- **Acknowledgment: Masters confirm successful application of changes.
Applications
This replication approach is suitable for systems that require high availability and distributed writes.
- **Multi-Datacenter Applications: Active-active setup across data centers for low-latency data access
- **Collaborative Editing Platforms: Multiple users edit content simultaneously with real-time synchronization
Benefits
Multi-master replication offers strong performance and reliability advantages.
- **Improved Write Scalability: Write load is distributed across multiple masters, boosting performance in write-heavy systems
- **High Availability: If one master fails, others continue handling writes without downtime
Challenges
Despite its advantages, multi-master replication introduces additional complexity.
- **Complexity: Difficult to configure and manage because of conflict resolution, consistency, and network setup.
- **Conflict Resolution: Simultaneous updates on different masters can cause conflicts that may need advanced logic or manual intervention.
3. Snapshot Replication
Snapshot replication creates a full copy of the database at a specific point in time and replicates it to other servers, mainly for reporting, backup, or distribution.
**Example:
- Like taking a photo of a room at one moment
- The snapshot captures the exact state at that time
- It can be used later to restore the room to that state
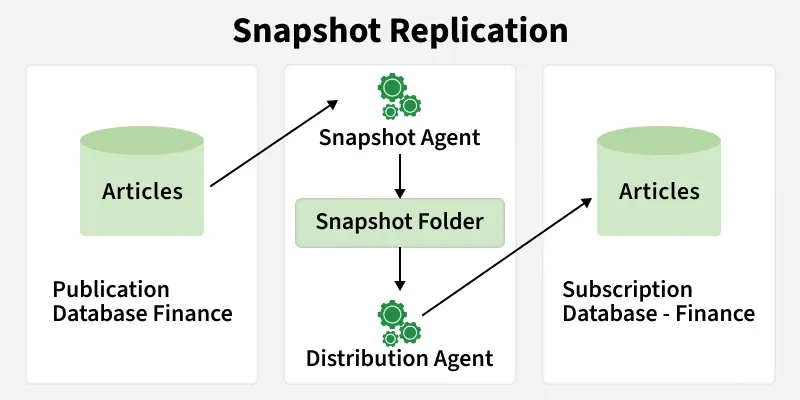
Snapshot Replication
Working
Snapshot replication works by periodically copying the entire database and distributing it to subscribers.
- **Initial Snapshot: Full database copy (schema + data) is taken at the publisher.
- **Distribution: Snapshot is stored in a distribution database.
- **Replication Process: Publisher changes are tracked and saved in the distributor.
- **Subscriber Updates: Subscribers apply received changes to stay in sync.
Applications
This replication method is commonly used where real-time updates are not critical.
- **Data Warehousing: Periodic snapshots for analytics and reporting without load on production
- **Auditing & Compliance: Preserves historical data states to meet regulatory requirements
Benefits
Snapshot replication offers simplicity and reliability for specific use cases.
- **Easy Implementation: Simpler to configure and maintain than other replication types.
- **Offline Access: Enables reporting or analysis without connecting to live systems.
- **Data Protection: Acts as a point-in-time backup for recovery purposes.
Challenges
Despite its simplicity, snapshot replication has certain limitations.
- **Data Consistency: Keeping multiple copies of a database synchronized is challenging, especially in environments with frequent updates, making data consistency difficult to maintain across all replicas.
- **Storage Requirements: Storing multiple copies of the database, including snapshots and changes, can require significant storage capacity.
4. Transactional Replication
Transactional replication copies every change made at the publisher to subscribers in near real time, ensuring all databases remain synchronized and maintain data consistency.
- Changes are replicated immediately after they occur, and the publisher sends updates to one or more subscribers.
- Ensures high data consistency across locations while supporting real-time or near real-time systems.
- Commonly used in high-availability environments.
**Example: Picture a live stock market with constantly changing prices
- Every price change (transaction) is immediately broadcasted to all connected screens (replicas).
- Everyone sees the same price updates in real-time.
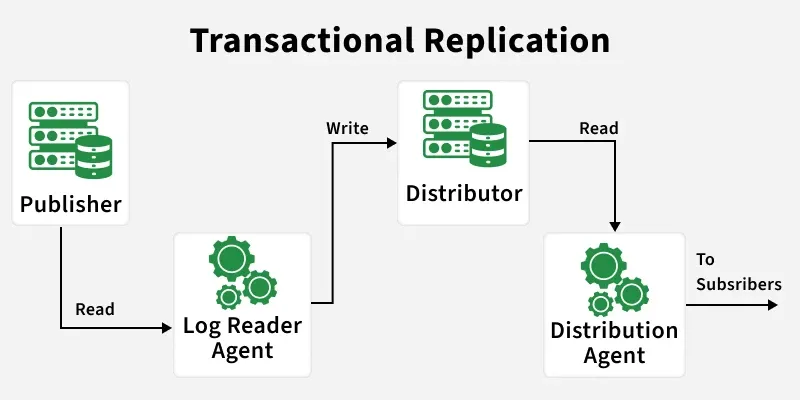
Transactional Replication
Working
Transactional replication works by tracking changes at the publisher, sending them through a distributor, and applying them to subscribers to keep data consistent.
- **Publisher & Subscriber: Selected tables at the publisher are marked for replication
- **Change Tracking: Inserts, updates, and deletes are continuously monitored
- **Transaction Capture: Changes are grouped into transactions for consistency
- **Distributor: Transactions are collected and forwarded to subscribers
- **Subscriber Update: Subscribers apply changes to stay synchronized
Applications
These applications rely on near real-time replication to maintain accuracy, consistency, and a seamless user experience across distributed systems.
- **Financial Services: Replicates transactions in near real time for auditing and compliance.
- **Online Gaming: Keeps player actions and game state synchronized across servers.
Benefits
These benefits ensure real-time data synchronization, high availability, reliable disaster recovery, and efficient data access across distributed locations.
- **Real-time Updates: Changes are immediately reflected across replicas, ensuring high availability and data consistency.
- **Disaster Recovery: Replicated copies act as backups during primary database failures.
- **Data Distribution: Provides up-to-date data to geographically distributed systems without performance impact.
Challenges
Despite its advantages, Transactional replication introduces additional complexity
- **Configuration: Requires careful setup and expertise with agents, distributors, and subscribers.
- **Overhead: Additional processing for replication can impact publisher database performance.
5. Merge Replication
Merge replication allows both the publisher and subscribers to update data independently and later synchronize changes, resolving conflicts when they occur.
- Supports two-way (bidirectional) data synchronization, where both publisher and subscribers can modify data.
- Works well with offline or occasionally connected systems and uses predefined rules or manual input for conflict resolution.
**Example: Imagine a team working on a shared document (database) in Google Docs
- Team members can edit the document offline (locally) and their changes are saved temporarily.
- When they connect online, their changes are merged with the main document, resolving any conflicts.
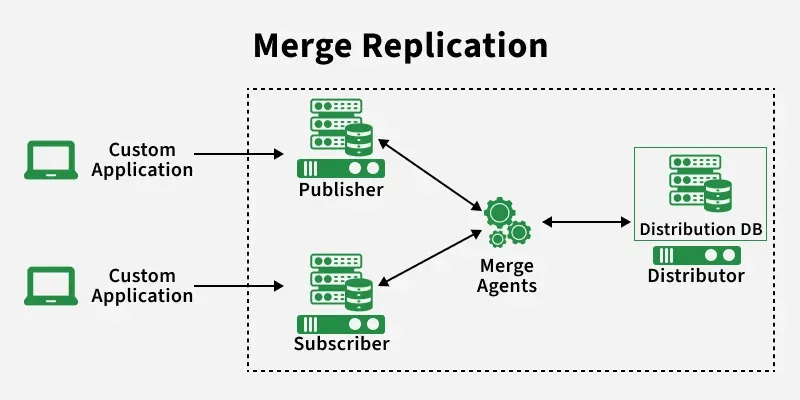
Merge Replication
Working
Merge replication tracks changes on both publisher and subscribers, merges them during synchronization, and resolves conflicts to keep data consistent.
- **Publisher & Subscribers: Selected tables allow read/write access on all nodes.
- **Change Tracking: Both sides record their data changes.
- **Conflicts: Conflicting updates may occur on the same data.
- **Sync & Resolution: Changes are merged and conflicts resolved using rules.
- **Update Distribution: Final updates are shared with all subscribers.
Applications
Merge replication is well suited for systems that require offline work with later data synchronization.
- **Field Service Applications: Field workers update data offline and sync with the central server when reconnected.
- **Healthcare Systems: Medical staff access and update patient records offline, then synchronize changes when online.
Benefits
Merge replication supports offline work with flexible, two-way data synchronization across distributed systems.
- **Offline Updates: Devices can modify data while disconnected and sync later.
- **Two-way Synchronization: Enables bidirectional data flow between publisher and subscribers.
- **Flexibility: Provides multiple conflict resolution strategies for different needs.
Challenges
Merge replication introduces higher complexity and performance overhead due to conflict handling and synchronization.
- **Complexity: Conflict resolution, synchronization, and troubleshooting require strong expertise.
- **Performance: Merging and resolving conflicts increases processing and network overhead.
- **Data Consistency: Errors during sync or conflict resolution can cause inconsistencies, demanding strict data integrity controls.
Master-Slave Replication Vs Master-Master Replication
This section highlights the key differences between single-master and multi-master replication models used in distributed database systems.
| **Master–Slave Replication | **Master–Master Replication |
|---|---|
| One-way data flow from master to slaves | Bi-directional data flow between masters |
| Only master handles write operations | All masters can handle writes |
| Slaves handle read operations | All masters handle read operations |
| Usually asynchronous; slight consistency delay | Can be synchronous; near real-time consistency |
| Conflicts are rare and easy to manage | Conflicts are common and complex to resolve |
| Lower availability if master fails | High availability if one master fails |
| Good for read-heavy workloads | Better for write-heavy workloads |
| Master can become a bottleneck | Load is distributed across masters |
| Easier to configure and manage | More complex to configure and manage |
| Lower network and processing overhead | Higher network and processing overhead |
Snapshot Replication Vs Transactional Replication
This section compares point-in-time data copying with continuous change-based replication to highlight their differences in consistency and use cases.
| **Snapshot Replication | **Transactional Replication |
|---|---|
| Takes a point-in-time snapshot of the entire database | Captures and replicates individual transactions |
| Used for infrequent updates | Used for frequent, near real-time updates |
| Transfers the entire dataset each time | Transfers only changes since last replication |
| Consistency at a specific moment in time | Maintains near real-time data consistency |
| Higher data transfer overhead | Lower data transfer, more efficient |
| Simple to configure and manage | More complex to configure |
| Suitable for reporting and backups | Suitable for real-time systems |
| Read-only copies are common | Subscribers stay continuously synchronized |