What is Chaos Engineering? (original) (raw)
Last Updated : 24 Oct, 2025
Chaos Engineering is the practice of intentionally introducing controlled failures like server shutdowns, latency injections, or network issues-to test a system’s resilience and uncover hidden weaknesses. By safely simulating disruptions, teams can observe system behavior, strengthen recovery mechanisms, and improve reliability before real incidents occur and also ensure stability under stress. It's importance are:
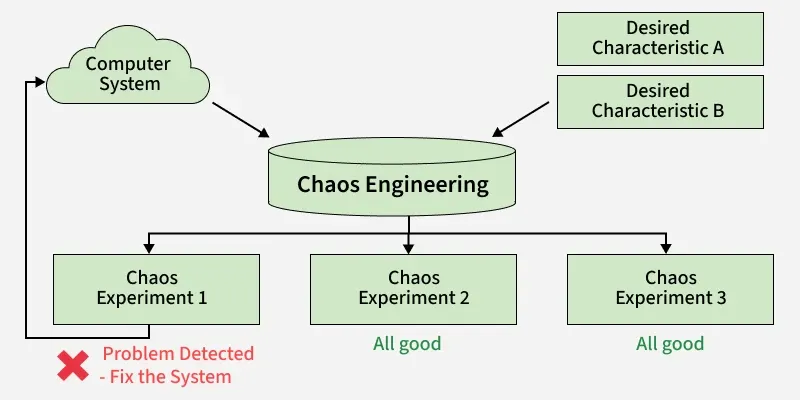
- **Identify Weaknesses: Exposes hidden failures and dependencies before they affect users.
- **Improve Resilience: Tests system behavior under stress to strengthen recovery and robustness.
- **Mitigate Downtime: Detects failure points early, enabling redundancy and failover strategies.
- **Enable Continuous Improvement: Fosters a learning culture through regular chaos experiments and iterative refinements.
Key Concepts and Principles of Chaos Engineering
Key concepts and principles of Chaos Engineering include:
- **Hypothesis Testing: Define how the system should behave under specific failure conditions.
- **Experimentation: Simulate controlled failures (e.g., server crash, latency, database outage) to test the hypothesis.
- **Automation: Automate chaos experiments for consistency, repeatability, and scalability.
- **Observability: Monitor metrics, logs, and behavior to analyze system response during failures.
- **Failure Injection: Intentionally introduce faults at different system layers to assess resilience.
The Chaos Engineering Process
The Chaos Engineering process typically involves several stages:
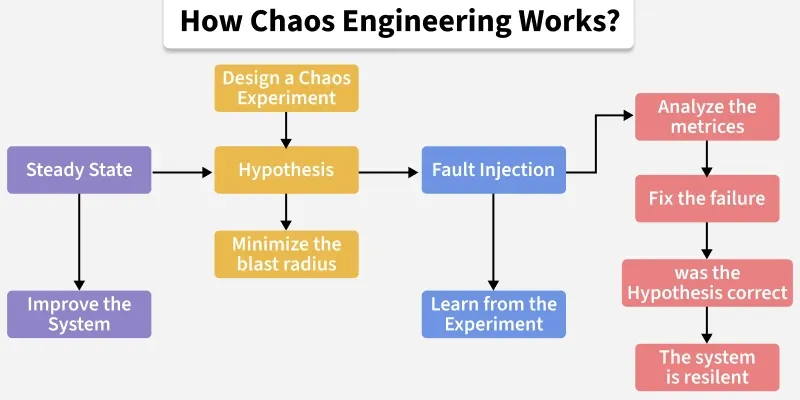
**Step 1: Define Objectives:
- Begin by clearly defining the objectives of the Chaos Engineering initiative. Determine what aspects of the system you want to test and improve, such as resilience, scalability, or fault tolerance.
**Step 2: Formulate Hypotheses:
- Develop hypotheses about how the system should behave under various failure conditions. These hypotheses serve as the basis for designing chaos experiments. For example, you might hypothesize that the system should remain responsive even when a specific service fails.
**Step 3: Design Experiments:
- Based on the hypotheses, design controlled experiments to simulate different failure scenarios. Decide which failure modes to test, how to inject failures into the system, and which metrics to monitor during the experiment. Consider the potential impact on users and business operations when designing experiments.
**Step 4: Prepare Infrastructure:
- Prepare the necessary infrastructure and tools for conducting chaos experiments. This may involve setting up testing environments, deploying monitoring systems, and configuring automation scripts for injecting failures.
**Step 5: Execute Experiments:
- Execute the planned chaos experiments in a controlled manner. Introduce failures into the system according to the experimental design and closely monitor its behavior. Collect relevant metrics, logs, and observations during the experiment.
**Step 6: Analyze Results:
- Analyze the results of the chaos experiments to validate or invalidate the hypotheses. Evaluate how the system responded to the injected failures, identify any weaknesses or vulnerabilities exposed, and assess the impact on system performance and user experience.
**Step 7: Iterate and Improve:
- Based on the insights gained from the analysis, iterate and improve the system's resilience. Implement changes to address any identified weaknesses, such as optimizing error handling, enhancing fault tolerance mechanisms, or improving scalability. Consider conducting additional chaos experiments to validate the effectiveness of these improvements.
**Step 8: Document and Share Findings:
- Document the findings, lessons learned, and best practices from the Chaos Engineering process. Share this knowledge with relevant teams and stakeholders to foster a culture of resilience and continuous improvement within the organization.
**Step 9: Integrate into Continuous Improvement:
- Integrate Chaos Engineering into the organization's continuous improvement processes. Incorporate regular chaos experiments into the development, testing, and deployment pipelines to continuously validate and enhance the system's resilience over time.
Several tools and technologies are available to support Chaos Engineering practices. These tools help engineers conduct controlled experiments, simulate failure scenarios, and analyze system behavior. Here are some commonly used Chaos Engineering tools and technologies:
- **Chaos Monkey: Developed by Netflix, Chaos Monkey is a popular open-source tool for randomly terminating instances in production environments. It helps teams test their system's resilience to instance failures in cloud-based architectures.
- **Chaos Toolkit: The Chaos Toolkit is an open-source framework for designing, running, and analyzing chaos experiments. It provides a command-line interface and Python-based DSL (Domain-Specific Language) for defining experiments and orchestrating chaos actions across different infrastructure and services.
- **Gremlin: Gremlin is a commercial Chaos Engineering platform that offers a range of tools and features for performing controlled chaos experiments. It supports the injection of various failure modes, such as CPU spikes, network partitioning, and blackhole attacks, across different cloud providers and infrastructure components.
- **Chaos Mesh: Chaos Mesh is an open-source Chaos Engineering platform developed by the CNCF (Cloud Native Computing Foundation). It enables engineers to orchestrate chaos experiments in Kubernetes environments by injecting faults into pods, containers, networks, and other Kubernetes resources.
- **Pumba: Pumba is an open-source Chaos Engineering tool specifically designed for Docker containers. It allows users to introduce chaos actions, such as network delays, packet loss, and container restarts, to simulate real-world failures and test containerized applications' resilience.
Use Cases and Applications of Chaos Engineering
Chaos Engineering can be applied across various industries and use cases to improve system resilience, reliability, and availability. Some common applications and use cases of Chaos Engineering include:
- **Cloud-Native Applications: Chaos Engineering is particularly valuable for cloud-native applications deployed in dynamic and distributed environments. By simulating failures in cloud infrastructure components, such as instances, containers, and services, teams can identify weaknesses and optimize resilience strategies.
- **Microservices Architectures: Microservices architectures are highly distributed and interconnected, making them susceptible to cascading failures. Chaos Engineering helps teams validate the resilience of microservices-based systems by testing service dependencies, failure propagation, and fault tolerance mechanisms.
- **Kubernetes Environments: Chaos Engineering is essential for Kubernetes environments to assess the resilience of containerized applications and Kubernetes clusters. Teams can use Chaos Engineering tools specifically designed for Kubernetes, such as Chaos Mesh and LitmusChaos, to orchestrate chaos experiments and validate Kubernetes resilience.
- **Highly Available Systems: For systems requiring high availability and uptime, such as e-commerce platforms, financial services, and telecommunications networks, Chaos Engineering is critical for identifying and mitigating single points of failure, improving redundancy, and optimizing failover mechanisms.
- **Disaster Recovery Testing: Chaos Engineering can be used to validate disaster recovery plans and procedures by simulating catastrophic failures, such as data center outages or regional infrastructure disruptions. Teams can assess the effectiveness of backup and recovery strategies and identify areas for improvement.incidents, such as DDoS attacks, injection vulnerabilities, or privilege escalation, teams can assess the system's ability to detect, respond to, and recover from security threats.
- **Incident Response Preparedness: Chaos Engineering exercises can enhance incident response preparedness by simulating real-world incidents and testing incident detection, communication, and mitigation processes. Teams can validate their incident response playbooks, train personnel, and improve coordination across teams and departments.
Benefits of Chaos Engineering
Chaos Engineering offers several benefits for organizations looking to improve the resilience, reliability, and performance of their systems:
- **Proactive Identification of Weaknesses: By intentionally introducing controlled chaos or failures into systems, Chaos Engineering helps identify weaknesses and vulnerabilities before they manifest in real-world scenarios. This proactive approach enables teams to address issues preemptively, reducing the likelihood of unplanned downtime or service disruptions.
- **Improved System Resilience: Chaos Engineering exercises validate the system's ability to withstand unexpected failures and disruptions, thereby improving its overall resilience. By systematically testing failure scenarios, teams can identify single points of failure, optimize fault tolerance mechanisms, and enhance the system's ability to recover gracefully from failures.
- **Enhanced **Reliability and **Availability: Chaos Engineering helps improve system reliability and availability by uncovering potential failure modes and bottlenecks. By identifying and mitigating risks associated with infrastructure, dependencies, and software components, teams can minimize downtime, improve service uptime, and enhance the user experience.
- **Cost Reduction: By identifying and addressing weaknesses early in the development lifecycle, Chaos Engineering helps reduce the cost associated with unplanned downtime, service outages, and emergency maintenance. Investing in resilience upfront can lead to significant cost savings over time by minimizing the impact of failures on business operations and revenue generation.
- **Alignment with DevOps Practices: Chaos Engineering aligns well with DevOps principles of collaboration, automation, and continuous delivery. By integrating Chaos Engineering into DevOps workflows, teams can automate chaos experiments, validate changes before deployment, and improve overall system quality and reliability.
Challenges of Chaos Engineering
While Chaos Engineering offers numerous benefits, it also presents several challenges that organizations may encounter:
- **Complexity: Difficult to implement in distributed systems due to intricate architectures and dependencies.
- **Resource Intensive: Requires significant time, infrastructure, and skilled personnel for setup, monitoring, and analysis.
- **Safety Concerns: Risk of service disruption or data loss when testing in production; needs strong safeguards.
- **Measurement Challenges: Hard to collect and interpret meaningful metrics in complex environments.
- **Cultural Resistance: Teams may resist intentional disruptions; needs education and organizational support.
Real-world Examples of Chaos Engineering
Several companies have successfully implemented Chaos Engineering practices to improve the resilience and reliability of their systems. Here are some real-world examples:
**1. Netflix
Netflix is one of the pioneers of Chaos Engineering and has been practicing it for many years. They developed tools like Chaos Monkey, which randomly terminates instances in their production environment to ensure their systems can withstand failures without impacting user experience. Netflix's Chaos Engineering practices have helped them build a highly resilient and scalable streaming platform that serves millions of users worldwide.
**2. Amazon
Amazon uses Chaos Engineering to test the resilience of its cloud infrastructure and services. They have developed tools like Chaos Gorilla and Latency Monkey to simulate large-scale failures and network latency in their AWS (Amazon Web Services) environment. By proactively testing their systems' resilience, Amazon can identify weaknesses and improve the reliability of their cloud services.
**3. Microsoft
Microsoft employs Chaos Engineering to validate the resilience of its Azure cloud platform. They conduct controlled chaos experiments, such as simulating server failures and network partitions, to assess the impact on Azure services and infrastructure. By continuously testing and improving the resilience of Azure, Microsoft can ensure high availability and performance for its customers.
**4. LinkedIn
LinkedIn utilizes Chaos Engineering to enhance the reliability of its social networking platform. They conduct chaos experiments to simulate various failure scenarios, such as database outages and service disruptions, to identify weaknesses and optimize their systems' fault tolerance mechanisms. By proactively testing their systems' resilience, LinkedIn can maintain a seamless user experience for millions of professionals