readtable - Create table from file - MATLAB (original) (raw)
Main Content
Syntax
Description
[T](#btx%5F238-1%5Fsep%5Fshared-T) = readtable([filename](#mw%5Fb0826a11-ea6e-45f6-92ce-54960958581f)) creates a table by reading column-oriented data from a text file, spreadsheet (includingMicrosoft® Excel®) file, XML file, HTML file, or a Microsoft Word document. readtable detects elements of your data, such as delimiter and data types, to determine how to import your data.
[T](#btx%5F238-1%5Fsep%5Fshared-T) = readtable([filename](#mw%5Fb0826a11-ea6e-45f6-92ce-54960958581f),[Name,Value](#namevaluepairarguments)) specifies options using one or more name-value arguments. For example, you can read the first row of the file as variable names or as data by using the ReadVariableNames name-value argument.
[T](#btx%5F238-1%5Fsep%5Fshared-T) = readtable([filename](#mw%5Fb0826a11-ea6e-45f6-92ce-54960958581f),[opts](#mw%5Fda8f54b7-5bd3-4640-9eb5-715f76a3a7f0)) creates a table using the options specified by the import options objectopts. Use an import options object to configure howreadtable interprets your file. Compared to name-value arguments, an import options object provides more control, better performance, and reusability of the file import configuration.
[T](#btx%5F238-1%5Fsep%5Fshared-T) = readtable([filename](#mw%5Fb0826a11-ea6e-45f6-92ce-54960958581f),[opts](#mw%5Fda8f54b7-5bd3-4640-9eb5-715f76a3a7f0),[Name,Value](#namevaluepairarguments)) creates a table using both an import options object and name-value arguments. If you specify name-value arguments in addition to an import options object, then readtable supports only the ReadVariableNames, ReadRowNames,DateLocale, and Encoding name-value arguments for text files, and the ReadVariableNames, ReadRowNames,Sheet, and UseExcel name-value arguments for spreadsheet files.
Examples
Read Text File as Table
Import the contents of a text file into a table. The resulting table contains one variable for each column in the file and uses the entries in the first line of the file as variable names.
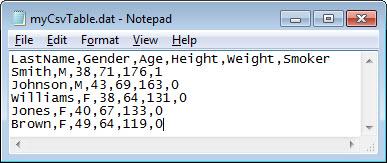
T = readtable("myCsvTable.dat")
T=5×6 table LastName Gender Age Height Weight Smoker ____________ ______ ___ ______ ______ ______
{'Smith' } {'M'} 38 71 176 1
{'Johnson' } {'M'} 43 69 163 0
{'Williams'} {'F'} 38 64 131 0
{'Jones' } {'F'} 40 67 133 0
{'Brown' } {'F'} 49 64 119 0 Read Text File with Missing Data
Create a table from a text file that contains data gaps. By default, readtable fills the gaps with the appropriate missing values.
T = readtable("headersAndMissing.txt")
T=5×6 table LastName Gender Age Height Weight Smoker ___________ __________ ___ ______ ______ ______
{'Wu' } {'M' } 38 71 176 1
{'Johnson'} {'M' } 43 69 163 0
{'Sanchez'} {'F' } 38 64 131 0
{'Brown' } {'F' } NaN 67 133 0
{'Picard' } {0x0 char} NaN 64 119 0 To omit the rows with the data gaps, specify the MissingRule name-value argument.
T = readtable("headersAndMissing.txt",MissingRule="omitrow")
T=3×6 table LastName Gender Age Height Weight Smoker ___________ ______ ___ ______ ______ ______
{'Wu' } {'M'} 38 71 176 1
{'Johnson'} {'M'} 43 69 163 0
{'Sanchez'} {'F'} 38 64 131 0 Read Subset of Text File Using Import Options
Configure how readtable interprets your file using an import options object. For example, use an import options object to read only a subset of a text file.
First, create an import options object by using detectImportOptions to detect aspects of your text file, including variable names and types, delimiters, and white-space characters. In this case, detectImportOptions creates a DelimitedTextImportOptions object.
opts = detectImportOptions("airlinesmall.csv")
opts = DelimitedTextImportOptions with properties:
Format Properties: Delimiter: {','} Whitespace: '\b\t ' LineEnding: {'\n' '\r' '\r\n'} CommentStyle: {} ConsecutiveDelimitersRule: 'split' LeadingDelimitersRule: 'keep' TrailingDelimitersRule: 'ignore' EmptyLineRule: 'skip' Encoding: 'ISO-8859-1'
Replacement Properties: MissingRule: 'fill' ImportErrorRule: 'fill' ExtraColumnsRule: 'addvars'
Variable Import Properties: Set types by name using setvartype VariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more} VariableTypes: {'double', 'double', 'double' ... and 26 more} SelectedVariableNames: {'Year', 'Month', 'DayofMonth' ... and 26 more} VariableOptions: [1-by-29 matlab.io.VariableImportOptions] Access VariableOptions sub-properties using setvaropts/getvaropts VariableNamingRule: 'modify'
Location Properties: DataLines: [2 Inf] VariableNamesLine: 1 RowNamesColumn: 0 VariableUnitsLine: 0 VariableDescriptionsLine: 0 To display a preview of the table, use preview
Specify the subset of variables to import by modifying the import options object. Then, import the subset of data using readtable with the import options object.
opts.SelectedVariableNames = ["TaxiIn","TaxiOut"]; T = readtable("airlinesmall.csv",opts);
Read Spreadsheet File as Table with Row Names
Create a table from a spreadsheet that contains variable names in the first row and row names in the first column. Display the first five rows and first four variables of the table.
T = readtable("patients.xls",ReadRowNames=true); T(1:5,1:4)
ans=5×4 table Gender Age Location Height __________ ___ _____________________________ ______
Smith {'Male' } 38 {'County General Hospital' } 71
Johnson {'Male' } 43 {'VA Hospital' } 69
Williams {'Female'} 38 {'St. Mary's Medical Center'} 64
Jones {'Female'} 40 {'VA Hospital' } 67
Brown {'Female'} 49 {'County General Hospital' } 64 Read Spreadsheet File Using Specific Range
Create a table using data from a specified region of a spreadsheet. Use the data from the 5-by-3 rectangular region between the corners C2 and E6. Do not use the first row of this region as variable names. The resulting table uses the default variable names instead.
T = readtable("patients.xls",Range="C2:E6",ReadVariableNames=false)
T=5×3 table Var1 Var2 Var3 ____ _____________________________ ____
38 {'County General Hospital' } 71
43 {'VA Hospital' } 69
38 {'St. Mary's Medical Center'} 64
40 {'VA Hospital' } 67
49 {'County General Hospital' } 64 Read Spreadsheet File Using Import Options
Configure how readtable interprets your file using an import options object. For example, use an import options object to read only specified variables from a spreadsheet file.
First, create an import options object from a file by using detectImportOptions to detect aspects of your spreadsheet file, including variable names and types. In this case, detectImportOptions creates a SpreadsheetImportOptions object.
opts = detectImportOptions("patients.xls")
opts = SpreadsheetImportOptions with properties:
Sheet Properties: Sheet: ''
Replacement Properties: MissingRule: 'fill' ImportErrorRule: 'fill' MergedCellColumnRule: 'placeleft' MergedCellRowRule: 'placetop'
Variable Import Properties: Set types by name using setvartype VariableNames: {'LastName', 'Gender', 'Age' ... and 7 more} VariableTypes: {'char', 'char', 'double' ... and 7 more} SelectedVariableNames: {'LastName', 'Gender', 'Age' ... and 7 more} VariableOptions: [1-by-10 matlab.io.VariableImportOptions] Access VariableOptions sub-properties using setvaropts/getvaropts VariableNamingRule: 'modify'
Range Properties: DataRange: 'A2' (Start Cell) VariableNamesRange: 'A1' RowNamesRange: '' VariableUnitsRange: '' VariableDescriptionsRange: '' To display a preview of the table, use preview
Specify which variables to import by modifying the import options object. Then, import the specified variables using readtable with the import options object. Display the first 5 rows of the table.
opts.SelectedVariableNames = ["Systolic","Diastolic"]; T = readtable("patients.xls",opts); T(1:5,:)
ans=5×2 table Systolic Diastolic ________ _________
124 93
109 77
125 83
117 75
122 80 Read XML File as Table
Import the contents of an XML file into a table.
The students.xml file has seven sibling nodes named Student, which each contain the same child nodes and attributes.
First, create an XMLImportOptions object by using detectImportOptions to detect aspects of your XML file. Read just the street names into a table by specifying the VariableSelectors name-value argument as the XPath expression of the Street element node. Register a custom namespace prefix to the existing namespace URL by setting the RegisteredNamespaces name-value argument.
opts = detectImportOptions("students.xml",RegisteredNamespaces=["myPrefix","https://www.mathworks.com"], ... VariableSelectors="//myPrefix:Street");
Then, import the specified variable using readtable with the import options object.
T = readtable("students.xml",opts)
T=7×1 table
Street
___________________
"591 Spring Lane"
"4641 Pearl Street"
"30 Highland Road"
"3388 Moore Avenue"
"3388 Moore Avenue"
"22 Angie Drive"
"65 Decatur Lane" Read Microsoft Word Document as Table
Import a table from a Microsoft Word document into a table in MATLAB. In this case, the document contains two tables, and the second table contains merged cells. Read the second table by setting the TableIndex name-value argument. Skip rows that have cells with merged columns by setting the MergedCellColumnRule name-value argument.
filename = "MaintenanceReport.docx"; T = readtable(filename,TableIndex=2,MergedCellColumnRule="omitrow")
T=3×5 table
Description Category Urgency Resolution Cost
_____________________________________________________________________ ____________________ ________ __________________ ________
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" "$45"
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" "$35"
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" "$16200"Alternatively, you can select a table with an XPath selector by using the TableSelector name-value argument. To select the Microsoft Word document table that contains the text "Description", use the XPath selector "//w:tbl[contains(.,'Description')]".
T = readtable(filename, ... TableSelector="//w:tbl[contains(.,'Description')]", ... MergedCellColumnRule="omitrow")
T=3×5 table
Description Category Urgency Resolution Cost
_____________________________________________________________________ ____________________ ________ __________________ ________
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" "$45"
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" "$35"
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" "$16200"Read HTML Webpage as Table
Import the first table from the URL https://www.mathworks.com/help/matlab/text-files.html that contains the text "readtable" using the XPath selector "//TABLE[contains(.,'readtable')]". The table does not have a header row, so set the ReadVariableNames name-value argument to false.
url = "https://www.mathworks.com/help/matlab/text-files.html"; T = readtable(url,TableSelector="//TABLE[contains(.,'readtable')]", ... ReadVariableNames=false)
T=4×2 table
Var1 Var2
________________ ____________________________
"readtable" "Create table from file"
"writetable" "Write table to file"
"readtimetable" "Create timetable from file"
"writetimetable" "Write timetable to file" Input Arguments
filename — Name of file to read
string scalar | character vector
Name of the file to read, specified as a string scalar or character vector.readtable supports reading data from text, spreadsheet, XML, and HTML files as well as Microsoft Word documents.
If filename does not include an extension, use theFileType name-value argument to indicate the file format. By default,readtable creates variables that have data types that are appropriate for the data values detected in each column of the input file.
Depending on the location of your file, filename can take on one of these forms.
| Location | Form |
|---|---|
| Current folder or folder on the MATLAB® path | Specify the name of the file infilename.Example: "myFile.txt" |
| File in a folder | If the file is not in the current folder or in a folder on the MATLAB path, then specify the full or relative pathname infilename.Example: "C:\myFolder\myFile.xlsx"Example: "dataDir\myFile.txt" |
| Internet URL | If the file is specified as an internet uniform resource locator (URL), thenfilename must contain the protocol type "http://" or "https://".Example: "http://hostname/path\_to\_file/my\_data.csv" |
| Remote Location | If the file is stored at a remote location, then filename must contain the full path of the file specified with the form:scheme_name://path_to_file/_my_file.ext_Based on the remote location,scheme_name can be one of the values in this table. Remote Locationscheme_nameAmazon S3™s3Windows Azure® Blob Storagewasb, wasbsHDFS™hdfsFor more information, see Work with Remote Data.Example: "s3://bucketname/path_to_file/my_file.csv"Example: "wasbs://path_to_file/my_file.csv"Example: "hdfs:///path_to_file/my_file.csv" |
Text Files
- Files with
.txt,.dat, or.csvextensions are read as delimited text files. - By default,
readtablecreates one table variable for each column in the file and reads variable names from the first row of the file. Empty fields are converted to eitherNaNfor a numeric variable or an empty character vector for a text variable. White space is ignored when reading the file. - All lines in the text file must have the same number of delimiters.
For more options, see the name value arguments for Text Files.
For commonly used text file workflows, see Import Data from Text File to Table.
Spreadsheet Files
- Files with
.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsextensions are read as spreadsheet files. - By default,
readtablecreates one table variable for each column in the file and reads variable names from the first row of the file. - On Windows® systems with Microsoft Excel software,
readtablereads any Excel spreadsheet file format recognized by your version of Excel. If your system does not have Microsoft Excel for Windows or if you are using MATLAB Online™, thenreadtableoperates with theUseExcelproperty set tofalseand reads only files with.xls,.xlsm,.xlsx,.xltm, and.xltxextensions. - Large files in XLSX format sometimes load slowly. For better import and export performance, Microsoft recommends that you use the XLSB format.
For more options, see the name value arguments for Spreadsheet Files.
For commonly used spreadsheet file workflows, see Read Spreadsheet Data into Table.
XML Files
- Files with the
.xmlextension are read as Extensible Markup Language (XML) files. - By default,
readtablecreates one table variable for each element or attribute node detected as a table variable. Variable names correspond to element and attribute names.
For more options, see the name value arguments for XML Files.
Microsoft Word Document Files
- Files with the
.docxextension are read as Microsoft Word document files. - By default,
readtableimports data from the first table in the document, creates one table variable for each column in the file, and reads variable names from the first row of the table.
For more options, see the name value arguments for Microsoft Word Document Files.
HTML Files
- Files with the
.html,.xhtml, or.htmextensions are read as Hypertext Markup Language (HTML) files. - By default,
readtableimports data from the first<TABLE>element, creates one table variable for each column in the file, and reads variable names from the first row of the table.
For more options, see the name value arguments for HTML Files.
opts — File import options
DelimitedTextImportOptions object | FixedWidthImportOptions object | SpreadsheetImportOptions object | …
File import options, specified as one of the import options objects in the table, created by either the detectImportOptions function or the associated import options function. The import options object contains properties that configure the data import process. readtable uses only the relevant properties of each import options object.
For more information on how to control your import, see Control How MATLAB Imports Your Data.
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Example: readtable(filename,ReadVariableNames=false) indicates that the first row of the file does not correspond to variable names.
Before R2021a, use commas to separate each name and value, and enclose Name in quotes.
Example: readtable(filename,"ReadVariableNames",false) indicates that the first row of the file does not correspond to variable names.
Text Files
FileType — Type of file
"spreadsheet" | "text" | "delimitedtext" | "fixedwidth" | "xml" | "worddocument" | "html"
Type of file, specified as one of these values.
| Value | File Type |
|---|---|
| "spreadsheet" | Spreadsheet files |
| "text" | Text files |
| "delimitedtext" | Delimited text files |
| "fixedwidth" | Fixed-width text files |
| "xml" | XML files |
| "worddocument" | Microsoft Word document |
| "html" | HTML files |
Use the "FileType" name-value pair argument whenfilename does not include the file extension, or when the extension is not one of these:
.txt,.dat, or.csvfor text files.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsfor spreadsheet files.xml, for XML files.docxfor Microsoft Word document files.html,.xhtml, or.htmfor HTML files
Example: "FileType","text"
ReadRowNames — Option to read first column as row names
false or 0 (default) | true or 1
Option to read the first column as row names, specified as a numeric or logical 1 (true) or 0 (false).
- Set
ReadRowNamestotruewhen the first column of the region to read contains the row names for the table. - Set
ReadRowNamestofalsewhen the first column of the region to read contains data, not the row names for the table.
If both the ReadVariableNames and ReadRowNames name-value arguments are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property T.Properties.DimensionNames.
If you specify the ReadRowNames argument in addition to an import options object, then the readtable behavior changes based on the specification:
- If
ReadRowNamesistrue, then read the row names from the specified file by using theRowNamesColumn(DelimitedTextImportOptions,FixedWidthImportOptions),RowNamesRange(SpreadsheetImportOptions), orRowNamesSelector(XMLImportOptions) property of the respective import options object. - If
ReadRowNamesisfalse, then do not import row names.
If you use the import options syntax without specifying ReadRowNames,readtable uses the value associated with the import options object and its ReadRowNames name-value argument.
Example: "ReadRowNames",true
Delimiter — Field delimiter character
character vector | cell array of character vectors | string
Field delimiter character, specified as Delimiter and a character vector, a cell array of character vectors, or a string. Specify Delimiter using any valid character such as a comma "," or a period".".
This table lists some commonly used field delimiter characters.
| Specifier | Field Delimiter |
|---|---|
| ",""comma" | Comma |
| " ""space" | Space |
| "\t""tab" | Tab |
| ";""semi" | Semicolon |
| "|""bar" | Vertical bar |
| unspecified | If unspecified, readtable automatically detects the delimiter. |
To treat consecutive delimiters as a single delimiter, specifyDelimiter as a cell array of character vectors. In addition, you must also specify the MultipleDelimsAsOne option.
Example: "Delimiter","," or"Delimiter","comma"
LeadingDelimitersRule — Procedure to manage leading delimiters
"keep" | "ignore" | "error"
Procedure to manage leading delimiters in a delimited text file, specified as one of the values in this table.
| Leading Delimiters Rule | Behavior |
|---|---|
| "keep" | Keep the delimiter. |
| "ignore" | Ignore the delimiter. |
| "error" | Return an error and abort the import operation. |
Example: "LeadingDelimitersRule","keep"
TrailingDelimitersRule — Procedure to manage trailing delimiters
"keep" | "ignore" | "error"
Procedure to manage trailing delimiters in a delimited text file, specified as one of the values in this table.
| Trailing Delimiters Rule | Behavior |
|---|---|
| "keep" | Keep the delimiter. |
| "ignore" | Ignore the delimiter. |
| "error" | Return an error and abort the import operation. |
Example: "TrailingDelimitersRule","keep"
ConsecutiveDelimitersRule — Procedure to handle consecutive delimiters
"split" | "join" | "error"
Procedure to handle consecutive delimiters in a delimited text file, specified as one of the values in this table.
| Consecutive Delimiters Rule | Behavior |
|---|---|
| "split" | Split the consecutive delimiters into multiple fields. |
| "join" | Join the delimiters into one delimiter. |
| "error" | Return an error and abort the import operation. |
Example: "ConsecutiveDelimitersRule","split"
MultipleDelimsAsOne — Multiple delimiter handling
0 (false) (default) | 1 (true)
Multiple delimiter handling, specified as MultipleDelimsAsOne and either true or false. If true, thenreadtable treats consecutive delimiters as a single delimiter. Repeated delimiters separated by white-space are also treated as a single delimiter. You must also specify the Delimiter option.
Example: "MultipleDelimsAsOne",1
NumHeaderLines — Number of header lines
0 | positive integer
Number of header lines to skip at the beginning of the file, specified asNumHeaderLines and either 0 or a positive integer. If unspecified, readtable automatically detects the number of lines to skip.
Example: "NumHeaderLines",2
Data Types: single | double
TreatAsMissing — Placeholder text to treat as empty value
character vector | cell array of character vectors | string scalar | string array
Placeholder text to treat as an empty value, specified as"TreatAsMissing" and a character vector, cell array of character vectors, string scalar, or string array. Table elements corresponding to these characters are set to the missing value associated with the data type. For more information, see fillmissing.
Example: "TreatAsMissing","N/A" or"TreatAsMissing","N/A" sets N/A within numeric columns to NaN.
Example: "TreatAsMissing",{'.','NA','N/A'} or"TreatAsMissing",[".","NA","N/A"] sets .,NA and N/A within numeric columns toNaN.
MissingRule — Procedure to manage missing data
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to manage missing data, specified as one of the values in this table. Data is considered missing if an expected field in a row does not exist. Because missing fields cause subsequent elements of a row to shift fields, the missing fields are interpreted at the end of the row.
| Missing Rule | Behavior |
|---|---|
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the missing record and field. |
| "omitrow" | Omit rows that contain missing data. |
| "omitvar" | Omit variables that contain missing data. |
Example: "MissingRule","omitrow"
TextType — Type for imported text data
"string" | "char"
Type for imported text data, specified as one of these values:
"string"— Import text data as string arrays."char"— Import text data as character vectors.
Example: "TextType","char"
DatetimeType — Type for imported date and time data
"datetime" (default) | "text" | "exceldatenum" (spreadsheet files only)
Type for imported date and time data, specified as DatetimeType and one of these values: "datetime", "text", or"exceldatenum". The value "exceldatenum" is applicable only for spreadsheet files, and is not valid for text files.
| Value | Type for Imported Date and Time Data |
|---|---|
| "datetime" | MATLABdatetime data type For more information, see datetime. |
| "text" | If "DatetimeType" is specified as"text", then the type for imported date and time data depends on the value specified in the "TextType" parameter: If "TextType" is set to "char", thenreadtable returns dates as a cell array of character vectors.If "TextType" is set to "string", thenreadtable returns dates as an array of strings. |
| "exceldatenum" | Excel serial date numbersA serial date number is a single number equal to the number of days from a given reference date. Excel serial date numbers use a different reference date than MATLAB serial date numbers. For more information on Excel dates, see Differences between the 1900 and the 1904 date system in Excel. |
Example: "DatetimeType","datetime"
VariableNamingRule — Flag to preserve variable names
"modify" (default) | "preserve"
Flag to preserve variable names, specified as either "modify" or"preserve".
"modify"— Convert invalid variable names (as determined by theisvarname function) to valid MATLAB identifiers."preserve"— Preserve variable names that are not valid MATLAB identifiers such as variable names that include spaces and non-ASCII characters.
Starting in R2019b, variable names and row names can include any characters, including spaces and non-ASCII characters. Also, they can start with any characters, not just letters. Variable and row names do not have to be valid MATLAB identifiers (as determined by the isvarname function). To preserve these variable names and row names, set the value of VariableNamingRule to "preserve". Variable names are not refreshed when the value of VariableNamingRule is changed from "modify" to "preserve".
Example: "VariableNamingRule","preserve"
ImportErrorRule — Procedure to handle import errors
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to handle import errors, specified as one of the values in this table. An import error occurs when readtable is unable to convert a text element to the expected data type.
| Import Error Rule | Behavior |
|---|---|
| "fill" | Replace the data where the error occurred with the contents of theFillValue property.The FillValue property is specified in the VariableImportOptions object of the variable being imported. For more information on accessing theFillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the error-causing record and field. |
| "omitrow" | Omit rows where errors occur. |
| "omitvar" | Omit variables where errors occur. |
Example: "ImportErrorRule","omitvar"
WebOptions — HTTP or HTTPS request options
weboptions object
HTTP or HTTPS request options, specified as aweboptions object. The weboptions object determines how to import data when the specified filename is an internet URL containing the protocol type "http://" or "https://".
ReadVariableNames — Read first row as variable names
true | false | 1 | 0
Indicator for reading the first row as variable names, specified asReadVariableNames and either true,false, 1, or 0. If unspecified,readtable automatically detects the presence of variable names.
| Indicator | Description |
|---|---|
| true | Use when the first row of the region to read contains the variable names for the table. readtable creates a variable, with the detected variable name, for each column in T. |
| false | Use when the first row of the region to read contains data in the table.readtable creates default variable names of the form"Var1",...,"VarN", where N is the number of variables. |
| unspecified | When left unspecified, readtable automatically detectstrue or false and proceeds accordingly. |
Note: If both the"ReadVariableNames" and "ReadRowNames" logical indicators are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property, T.Properties.DimensionNames.
If you specify the ReadVariableNames argument in addition toopts the import options, then the readtable behavior changes based on the specification:
- If
ReadVariableNamesistrue, then read the variable names from the specified file by using theVariableNamesRangeor theVariableNamesLineproperty of the import options object. - If
ReadVariableNamesisfalse, then read the variable names from theVariableNamesproperty of the import options object.
Example: "ReadVariableNames",true
ExpectedNumVariables — Expected number of variables
positive integer
Expected number of variables, specified as ExpectedNumVariables and a positive integer. If unspecified, readtable automatically detects the number of variables.
Example: "ExpectedNumVariables",5
Data Types: single | double
VariableWidths — Field widths of variables
vector of positive integer values
Field widths of variables in a fixed-width text file, specified as a vector of positive integer values. Each positive integer in the vector corresponds to the number of characters in a field that makes up the variable. The VariableWidths property contains an entry corresponding to each variable specified in theVariableNames property.
Example: "VariableWidths",[10,7,4,26,7]
Whitespace — Characters to treat as white space
string scalar | character vector
Characters to treat as white space, specified as a string scalar or character vector containing one or more characters.
This table shows how to represent special characters that you cannot enter using ordinary text.
| Special Character | Representation |
|---|---|
| Percent character | %% |
| Backslash | \\ |
| Alarm | \a |
| Backspace | \b |
| Form feed | \f |
| New line | \n |
| Carriage return | \r |
| Horizontal tab | \t |
| Vertical tab | \v |
| Character whose Unicode® numeric value can be represented by the hexadecimal number,N | \xN |
| Character whose Unicode numeric value can be represented by the octal number,N | \N |
Example: "Whitespace"," _"
Example: "Whitespace","?!.,"
EmptyLineRule — Procedure to handle empty lines
"skip" | "read" | "error"
Procedure to handle empty lines in the data, specified as one of the values in this table. readtable interprets white space as empty. A line is considered empty if it contains no fields. A line is defined by two end-of-line characters.
| Empty Line Rule | Behavior |
|---|---|
| "skip" | Skip the empty lines. |
| "read" | Import the empty lines. readtable parses an empty line using the values specified in VariableWidths,VariableOptions, MissingRule, and other relevant properties, such as Whitespace. |
| "error" | Display an error message and cancel the import operation. |
Example: "EmptyLineRule","skip"
VariableNamesLine — Variable names location
0 (default) | positive scalar integer
Variable names location, specified as a positive scalar integer. TheVariableNamesLine property specifies the line number where variable names are located.
If VariableNamesLine is specified as 0, then do not import the variable names. Otherwise, import the variable names from the specified line.
Example: "VariableNamesLine",6
Data Types: single | double | uint8 | uint16 | uint32 | uint64
PartialFieldRule — Procedure to handle partial fields
"keep" | "fill" | "omitrow" | "omitvar" | "wrap" | "error"
Procedure to handle partial fields in the data, specified as one of the values in this table. A field is considered partially filled if it terminates before the end of the expected width. This applies only to fields with fixed widths.
| Partial Field Rule | Behavior |
|---|---|
| "keep" | Keep the partial field data and convert the text to the appropriate data type.In some cases, when readtable is unable to interpret the partial data, a conversion error can occur. |
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "omitrow" | Omit rows that contain partial data. |
| "omitvar" | Omit variables that contain partial data. |
| "wrap" | Begin reading the next line of characters. |
| "error" | Display an error message and cancel the import operation. |
Example: "PartialFieldRule","keep"
VariableUnitsLine — Variable units location
0 (default) | positive scalar integer
Variable units location, specified as a positive scalar integer. TheVariableUnitsLine property specifies the line number where variable units are located.
If VariableUnitsLine is specified as 0, then do not import the variable units. Otherwise, import the variable units from the specified line.
Example: "VariableUnitsLine",8
Data Types: single | double | uint8 | uint16 | uint32 | uint64
VariableDescriptionsLine — Variable description location
0 (default) | positive scalar integer
Variable description location, specified as a positive scalar integer. TheVariableDescriptionsLine property specifies the line number where variable descriptions are located.
If VariableDescriptionsLine is specified as 0, then do not import the variable descriptions. Otherwise, import the variable descriptions from the specified line.
Example: "VariableDescriptionsLine",7
Data Types: single | double | uint8 | uint16 | uint32 | uint64
ExtraColumnsRule — Procedure to handle extra columns
"addvars" | "ignore" | "wrap" | "error"
Procedure to handle extra columns in the data, specified as one of the values in this table. Columns are considered extra if a row has more columns than expected.
| Extra Columns Rule | Behavior |
|---|---|
| "addvars" | To import extra columns, create new variables. If there areN extra columns, then import new variables as"ExtraVar1","ExtraVar2",...,"ExtraVarN".The extra columns are imported as text with data type char. |
| "ignore" | Ignore the extra columns of data. |
| "wrap" | Wrap the extra columns of data to new records. This action does not change the number of variables. |
| "error" | Display an error message and cancel the import operation. |
Example: "ExtraColumnsRule","addvars"
Format — Column format
character vector | string scalar | "auto"
Column format of the file, specified as Format and a character vector or a string scalar having one or more conversion specifiers, or "auto". The conversion specifiers are the same as the specifiers accepted by thetextscan function.
Specifying the format can significantly improve speed for some large files. If you do not specify a value for Format, then readtable uses%q to interpret nonnumeric columns. The %q specifier reads the text and omits double quotation marks (") if appropriate.
- If you do not specify the
"Format"name-value pair, then thereadtablefunction behaves as though you have used the results of thedetectImportOptionsfunction to import the data. For more information on the consequences of this behavior, see Compatibility Considerations. - If you specify
"Format","auto", then the variables created aredoublearrays, cell array of character vectors, ordatetimearrays, depending on the data. If the entire column is numeric, variables are imported asdouble. If any element in a column is not numeric, the variables are imported as cell arrays of character vectors, or asdatetimearrays if the values represent dates and times.
Example: "Format","auto"
EmptyValue — Returned value for empty numeric fields
NaN (default) | numeric scalar
Returned value for empty numeric fields in delimited text files, specified asEmptyValue and a numeric scalar.
Example: "EmptyValue",0
CollectOutput — Logical indicator determining data concatenation
false (default) | true
Logical indicator determining data concatenation, specified asCollectOutput and either true orfalse. If true, then readtable concatenates consecutive output cells of the same fundamental MATLAB class into a single array.
Example: "CollectOutput",true
CommentStyle — Symbols designating text to ignore
character vector | cell array of character vectors | string scalar | string array
Symbols designating text to ignore, specified as CommentStyle and a character vector, cell array of character vectors, string scalar, or string array.
For example, specify a character such as "%" to ignore text following the symbol on the same line. Specify a cell array of two character vectors, such as{'/*','*/'}, to ignore any text between those sequences.
MATLAB checks for comments only at the start of each field, not within a field.
Example: "CommentStyle",{'/*','*/'}
ExponentCharacter — Exponent characters
"eEdD" (default) | character vector | string scalar
Exponent characters, specified as ExponentCharacter and a character vector or string scalar. The default exponent characters are e,E, d, and D.
Example: "ExponentCharacter","eE"
LineEnding — End-of-line characters
character vector | string scalar
End-of-line characters, specified as LineEnding and a character vector or string scalar. The character vector must be "\r\n" or it must specify a single character. Common end-of-line characters are a newline character ("\n") or a carriage return ("\r"). If you specify"\r\n", then readtable treats any of\r, \n, and the combination of the two (\r\n) as end-of-line characters.
The default end-of-line sequence is \n, \r, or\r\n, depending on the contents of your file.
If there are missing values and an end-of-line sequence at the end of the last line in a file, then readtable returns empty values for those fields. This ensures that individual cells in output cell array, C, are the same size.
Example: "LineEnding",":"
DateLocale — Locale for reading dates
character vector | string scalar
Locale for reading dates, specified as DateLocale and a character vector or a string scalar of the form_`xx`__ _`YY`_, where:
YYis an uppercase ISO 3166-1 alpha-2 code indicating a country.xxis a lowercase ISO 639-1 two-letter code indicating a language.
This table lists some common values for the locale.
| Locale | Language | Country |
|---|---|---|
| "de_DE" | German | Germany |
| "en_GB" | English | United Kingdom |
| "en_US" | English | United States |
| "es_ES" | Spanish | Spain |
| "fr_FR" | French | France |
| "it_IT" | Italian | Italy |
| "ja_JP" | Japanese | Japan |
| "ko_KR" | Korean | Korea |
| "nl_NL" | Dutch | Netherlands |
| "zh_CN" | Chinese (simplified) | China |
When using the %D format specifier to read text asdatetime values, use DateLocale to specify the locale in which readtable should interpret month and day-of-week names and abbreviations.
If you specify the DateLocale argument in addition toopts the import options, then readtable uses the specified value for the DateLocale argument, overriding the locale defined in the import options.
Example: "DateLocale","ja_JP"
DecimalSeparator — Characters indicating decimal separator
character vector | string scalar
Characters indicating the decimal separator in numeric variables, specified as a character vector or string scalar. The readtable uses the characters specified in the DecimalSeparator name-value argument to distinguish the integer part of a number from the decimal part.
When converting to integer data types, numbers with a decimal part are rounded to the nearest integer.
Example: If name-value pair is specified as "DecimalSeparator",",", then readtable imports the text "3,14159" as the number3.14159.
ThousandsSeparator — Characters that indicate thousands grouping
character vector | string scalar
Characters that indicate the thousands grouping in numeric variables, specified as a character vector or string scalar. The thousands grouping characters act as visual separators, grouping the number at every three place values. The readtable uses the characters specified in the ThousandsSeparator name-value argument to interpret the numbers being imported.
Example: If name-value pair is specified as "ThousandsSeparator",",", then readtable imports the text "1,234,000" as1234000.
TrimNonNumeric — Remove nonnumeric characters
false (default) | true
Remove nonnumeric characters from a numeric variable, specified as a logicaltrue or false.
Example: If name-value pair is specified as "TrimNonNumeric",true, then readtable reads "$500/-" as500.
Data Types: logical
Encoding — Character encoding scheme
"UTF-8" | "ISO-8859-1" | "windows-1251" | "windows-1252" | ...
Character encoding scheme associated with the file, specified asEncoding and "system" or a standard character encoding scheme name. When you do not specify any encoding, the readtable function uses automatic character set detection to determine the encoding when reading the file.
If you specify the "Encoding" argument in addition to the import options, then the readtable function uses the specified value for"Encoding", overriding the encoding defined in the import options.
Example: "Encoding","UTF-8" uses UTF-8 as the encoding.
Example: "Encoding","system" uses the system default encoding.
DurationType — Output data type of duration data
"duration" (default) | "text"
Output data type of duration data from text files, specified asDurationType and either "duration" or"text".
| Value | Type for Imported Duration Data |
|---|---|
| "duration" | MATLABduration data type For more information, see duration. |
| "text" | If "DurationType" is specified as"text", then the type for imported duration data depends on the value specified in the "TextType" parameter: If "TextType" is "char", thenreadtable returns duration data as a cell array of character vectors. If "TextType" is "string", thenreadtable returns duration data as an array of strings. |
Example: "DurationType","text"
HexType — Output data type of hexadecimal data
"auto" (default) | "text" | "int8" | "int16" | ...
Output data type of hexadecimal data, specified as HexType and one of the values listed in the table.
The input file represents hexadecimal values as text, using either 0x or 0X as a prefix and the characters0-9, a-f, andA-F as digits. (Uppercase and lowercase letters represent the same digits—for example, "0xf" and "0xF" both represent 15.)
readtable converts the hexadecimal values to the data type specified by the value of "HexType".
| Value of "HexType" | Data Type of Output Table Variables |
|---|---|
| "auto" | data type detected automatically |
| "text" | unaltered input text |
| "int8" | 8-bit integer, signed |
| "int16" | 16-bit integer, signed |
| "int32" | 32-bit integer, signed |
| "int64" | 64-bit integer, signed |
| "uint8" | 8-bit integer, unsigned |
| "uint16" | 16-bit integer, unsigned |
| "uint32" | 32-bit integer, unsigned |
| "uint64" | 64-bit integer, unsigned |
Example: "HexType","uint16" converts text representing hexadecimal values (such as "0xFF") to unsigned 16-bit integers (such as255) in the output table.
BinaryType — Output data type of binary data
"auto" (default) | "text" | "int8" | "int16" | ...
Output data type of binary data, specified as BinaryType and one of the values listed in the table.
The input file represents binary values as text, using either 0b or0B as a prefix and the characters 0 and1 as digits.
readtable converts the binary values to the data type specified by the value of "BinaryType".
| Value of "BinaryType" | Data Type of Output Table Variables |
|---|---|
| "auto" | data type detected automatically |
| "text" | unaltered input text |
| "int8" | 8-bit integer, signed |
| "int16" | 16-bit integer, signed |
| "int32" | 32-bit integer, signed |
| "int64" | 64-bit integer, signed |
| "uint8" | 8-bit integer, unsigned |
| "uint16" | 16-bit integer, unsigned |
| "uint32" | 32-bit integer, unsigned |
| "uint64" | 64-bit integer, unsigned |
Example: "BinaryType","uint16" converts text representing binary values (such as "0b11111111") to unsigned 16-bit integers (such as255) in the output table.
Spreadsheet Files
FileType — Type of file
"spreadsheet" | "text" | "delimitedtext" | "fixedwidth" | "xml" | "worddocument" | "html"
Type of file, specified as one of these values.
| Value | File Type |
|---|---|
| "spreadsheet" | Spreadsheet files |
| "text" | Text files |
| "delimitedtext" | Delimited text files |
| "fixedwidth" | Fixed-width text files |
| "xml" | XML files |
| "worddocument" | Microsoft Word document |
| "html" | HTML files |
Use the "FileType" name-value pair argument whenfilename does not include the file extension, or when the extension is not one of these:
.txt,.dat, or.csvfor text files.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsfor spreadsheet files.xml, for XML files.docxfor Microsoft Word document files.html,.xhtml, or.htmfor HTML files
Example: "FileType","text"
ReadRowNames — Option to read first column as row names
false or 0 (default) | true or 1
Option to read the first column as row names, specified as a numeric or logical1 (true) or 0 (false).
- Set
ReadRowNamestotruewhen the first column of the region to read contains the row names for the table. - Set
ReadRowNamestofalsewhen the first column of the region to read contains data, not the row names for the table.
If both the ReadVariableNames and ReadRowNames name-value arguments are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property, T.Properties.DimensionNames.
If you specify the ReadRowNames argument in addition to an import options object, then the readtable behavior changes based on the specification:
- If
ReadRowNamesistrue, then read the row names from the specified file by using theRowNamesColumn(DelimitedTextImportOptions,FixedWidthImportOptions),RowNamesRange(SpreadsheetImportOptions), orRowNamesSelector(XMLImportOptions) property of the respective import options object. - If
ReadRowNamesisfalse, then do not import row names.
If you use the import options syntax without specifying ReadRowNames,readtable uses the value associated with the import options object and its ReadRowNames name-value argument.
Example: "ReadRowNames",true
TreatAsMissing — Placeholder text to treat as empty value
character vector | cell array of character vectors | string scalar | string array
Placeholder text to treat as an empty value, specified asTreatAsMissing and a character vector, cell array of character vectors, string scalar, or string array. Table elements corresponding to these characters are set to the missing value associated with the data type. For more information, see fillmissing.
Example: "TreatAsMissing","N/A" or"TreatAsMissing","N/A" sets N/A within numeric columns to NaN.
Example: "TreatAsMissing",{'.','NA','N/A'} or"TreatAsMissing",[".","NA","N/A"] sets .,NA and N/A within numeric columns toNaN.
MissingRule — Procedure to manage missing data
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to manage missing data, specified as one of the values in this table. Data is considered missing if the expected field in the row has no data and the field type is blank or empty.
| Missing Rule | Behavior |
|---|---|
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the missing record and field. |
| "omitrow" | Omit rows that contain missing data. |
| "omitvar" | Omit variables that contain missing data. |
Example: "MissingRule","omitrow"
Range — Portion of worksheet to read
character vector | string scalar
Portion of the worksheet to read, indicated as a rectangular area specified as a character vector or string scalar in one of the following forms.
| Ways to specify Range | Description |
|---|---|
| "Cell" or _[row col]_Starting Cell | Specify the starting cell for the data as a character vector or string scalar or a two element numeric vector. Character vector or string scalar containing a column letter and row number using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5. Two element numeric vector of the form [row col] indicating the starting row and column.Using the starting cell, readtable automatically detects the extent of the data by beginning the import at the start cell and ending at the last empty row or footer range.Example: "A5" or [5 1] |
| "Corner1:Corner2"Rectangular Range | Specify the range using the syntax"Corner1:Corner2", where_Corner1_ and Corner2 are two opposing corners that define the region. For example, "D2:H4" represents the 3-by-5 rectangular region between the two corners D2 and H4 on the worksheet. The "Range" name-value pair argument is not case-sensitive, and uses Excel A1 reference style (see Excel help).Example: "Range","D2:H4" |
| ""Unspecified or Empty | If unspecified, readtable automatically detects the used range.Example: "Range",""Note: Used Range refers to the rectangular portion of the spreadsheet that actually contains data. readtable automatically detects the used range by trimming any leading and trailing rows and columns that do not contain data. Text that is only white space is considered data and is captured within the used range. |
| "Row1:Row2"Row Range | You can identify range by specifying the beginning and ending rows using Excel row designators. Then readtable automatically detects the used column range within the designated rows. For instance,readtable interprets the range specification"1:7" as an instruction to read all columns in the used range in rows 1 through 7 (inclusive).Example: "Range","1:7" |
| "Column1:Column2"Column Range | You can identify range by specifying the beginning and ending columns using Excel column designators. Then readtable automatically detects the used row range within the designated columns. For instance,readtable interprets the range specification"A:F" as an instruction to read all rows in the used range in columns A through F (inclusive).Example: "Range","A:F" |
| "NamedRange"Named Range in Excel | In Excel, you can create names to identify ranges in the spreadsheet. For instance, you can select a rectangular portion of the spreadsheet and call it"myTable". If such named ranges exist in a spreadsheet, thenreadtable can read that range using its name.Example: "Range","myTable" |
Example: "Range", "A1:F10"
Example: "Range", "A1:F10"—
DataRange — Location of data
character vector | string scalar | positive scalar integer | array of positive scalar integers | cell array of character vector | string array
Location of data to be imported, specified as a character vector, string scalar, cell array of character vectors, string array, positive scalar integer or anN-by-2 array of positive scalar integers. SpecifyDataRange using one of these forms.
| Specified by | Behavior |
|---|---|
| "Cell" or_n_Starting Cell or Starting Row | Specify the starting cell for the data, using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5.Using the starting cell,readtable automatically detects the extent of the data, by beginning the import at the start cell and ending at the last empty row or footer range.Alternatively, specify the first row containing the data using the positive scalar row index. Using the specified row index,readtable automatically detects the extent of the data by reading from the specified first row to the end of the data or the footer range.Example: "A5" or 5 |
| "Corner1:Corner2"Rectangular Range | Specify the exact range to read using the rectangular range form, where_Corner1_ and Corner2 are two opposing corners that define the region to read.readtable only reads the data contained in the specified range. Any empty fields within the specified range are imported as missing cells.The number of columns must match the number specified in theNumVariables property.Example: "A5:K50" |
| "Row1:Row2" or"Column1:Column2"Row Range or Column Range | Specify the range by identifying the beginning and ending rows using Excel row numbers. Using the specified row range,readtable automatically detects the column extent by reading from the first nonempty column to the end of the data, and creates one variable per column.Example: "5:500"Alternatively, specify the range by identifying the beginning and ending columns using Excel column letters or numbers.Using the specified column range, the import function automatically detects the row extent by reading from the first nonempty row to the end of the data or the footer range.The number of columns in the specified range must match the number specified in theNumVariables property.Example: "A:K" |
| [n1 n2; n3 n4;...] Multiple Row Ranges | Specify multiple row ranges to read with anN-by-2 array containing N different row ranges.A valid array of multiple row ranges must: Specify line ranges in an increasing order, that is the first row range specified in the array appears in the file before the other row ranges.Contain only non-overlapping row ranges.Use of Inf is only supported to indicate the last range in the numeric array specifying multiple row ranges. For example,[1 3; 5 6; 8 Inf].Example: [1 3; 5 6; 8 Inf] |
| ""Unspecified or Empty | Do not fetch any data.Example: "" |
Example: "DataRange", "B2:H15"
Data Types: char | string | cell | single | double
RowNamesRange — Location of row names
character vector | string scalar | positive scalar integer | "" empty character array
Location of row names, specified as a character vector, string scalar, positive scalar integer, or an empty character array. Specify RowNamesRange as one of the values in this table.
| Specified by | Behavior |
|---|---|
| "Cell" | Specify the starting cell for the data, using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5.readtable identifies a name for each variable in the data.Example: "A5" |
| "Corner1:Corner2"Rectangular Range | Specify the exact range to read using the rectangular range form, where_Corner1_ and Corner2 are two opposing corners that define the region to read.The number of rows contained in RowNamesRange must match the number of data rows, and the range indicated by RowNamesRange must span only one column.Example: "A5:A50" |
| "Row1:Row2"Row Range | Specify range by identifying the beginning and ending rows using Excel row numbers.Row names must be in a single column.Example: "5:50" |
| _n_Number Index | Specify the column containing the row names using a positive scalar column index. Example: 5 |
| ""Unspecified or Empty | Indicate that there are no row names.Example: "" |
Example: "RowNamesRange", "A1:H1"
Data Types: char | single | double
VariableNamesRange — Location of variable names
character vector | string scalar | positive scalar integer | "" empty character array
Location of variable names, specified as a character vector, string scalar, positive scalar integer, or an empty character array. Specify VariableNamesRange as one of the values in this table.
| Specified by | Behavior |
|---|---|
| "Cell" | Specify the starting cell for the data, using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5.readtable reads a name for each variable in the data.Example: "A5" |
| "Corner1:Corner2"Rectangular Range | Specify the exact range to read using the rectangular range form, where_Corner1_ and Corner2 are two opposing corners that define the region to read.The number of columns must match the number specified in the NumVariables property, and the range must span only one row.Example: "A5:K5" |
| "Row1:Row2"Row Range | Specify range by identifying the beginning and ending rows using Excel row numbers. Must be a single row.Example: "5:5" |
| _n_Number Index | Specify the row containing the variable names using a positive scalar row index. Example: 5 |
| ""Unspecified or Empty | Indicate that there are no variable names.Example: "" |
Example: "VariableNamesRange","A1:A15"
Data Types: char | single | double
VariableUnitsRange — Location of variable units
character vector | string scalar | positive scalar integer | "" empty character array
Location of variable units, specified as a character vector, string scalar, positive scalar integer, or an empty character array. Specify VariableUnitsRange as one of the values in this table.
| Specified by | Behavior |
|---|---|
| "Cell" | Specify the starting cell for the data, using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5.readtable reads a unit for each variable in the data.Example: "A5" |
| "Corner1:Corner2"Rectangular Range | Specify the exact range to read using the rectangular range form, where_Corner1_ and Corner2 are two opposing corners that define the region to read.The number of columns must match the number specified in the NumVariables property, and the range must span only one row.Example: "A5:K5" |
| "Row1:Row2"Row Range | Specify range by identifying the beginning and ending rows using Excel row numbers. Must be a single row.Example: "5:5" |
| _n_Number Index | Specify the row containing the data units using a positive scalar row index.Example: 5 |
| ""Unspecified or Empty | Indicate that there are no variable units.Example: "" |
Example: "VariableUnitsRange","A1:A5"
Data Types: char | string | single | double
VariableDescriptionsRange — Location of variable descriptions
character vector | string scalar | "" empty character array
Location of variable descriptions, specified as a character vector, string scalar, positive scalar integer, or an empty character array. SpecifyVariableDescriptionRange as one of the values in this table.
| Specified by | Behavior |
|---|---|
| "Cell" | Specify the starting cell for the data, using ExcelA1 notation. For example, A5 is the identifier for the cell at the intersection of column A and row5.readtable reads a description for each variable in the data.Example: "A5" |
| "Corner1:Corner2"Rectangular Range | Specify the exact range to read using the rectangular range form, where_Corner1_ and Corner2 are two opposing corners that define the region to read.The number of columns must match the number specified in the NumVariables property, and the range must span only one row.Example: "A5:K5" |
| "Row1:Row2"Row Range | Specify range by identifying the beginning and ending rows using Excel row numbers. Must be a single row.Example: "5:5" |
| _n_Number Index | Specify the row containing the descriptions using a positive scalar row index. Example: 5 |
| ""Unspecified or Empty | Indicate that there are no variable descriptions.Example: "" |
Example: "VariableDescriptionsRange","B1:B15"
Data Types: char | string | single | double
TextType — Type for imported text data
"string" | "char"
Type for imported text data, specified as one of these values:
"string"— Import text data as string arrays."char"— Import text data as character vectors.
Example: "TextType","char"
DatetimeType — Type for imported date and time data
"datetime" (default) | "text" | "exceldatenum" (spreadsheet files only)
Type for imported date and time data, specified as DatetimeType and one of these values: "datetime", "text", or"exceldatenum". The value "exceldatenum" is applicable only for spreadsheet files, and is not valid for text files.
| Value | Type for Imported Date and Time Data |
|---|---|
| "datetime" | MATLABdatetime data type For more information, see datetime. |
| "text" | If "DatetimeType" is specified as"text", then the type for imported date and time data depends on the value specified in the "TextType" parameter: If "TextType" is set to "char", thenreadtable returns dates as a cell array of character vectors.If "TextType" is set to "string", thenreadtable returns dates as an array of strings. |
| "exceldatenum" | Excel serial date numbersA serial date number is a single number equal to the number of days from a given reference date. Excel serial date numbers use a different reference date than MATLAB serial date numbers. For more information on Excel dates, see Differences between the 1900 and the 1904 date system in Excel. |
Example: "DatetimeType","datetime"
VariableNamingRule — Flag to preserve variable names
"modify" (default) | "preserve"
Flag to preserve variable names, specified as either "modify" or"preserve".
"modify"— Convert invalid variable names (as determined by theisvarname function) to valid MATLAB identifiers."preserve"— Preserve variable names that are not valid MATLAB identifiers such as variable names that include spaces and non-ASCII characters.
Starting in R2019b, variable names and row names can include any characters, including spaces and non-ASCII characters. Also, they can start with any characters, not just letters. Variable and row names do not have to be valid MATLAB identifiers (as determined by the isvarname function). To preserve these variable names and row names, set the value of VariableNamingRule to "preserve". Variable names are not refreshed when the value of VariableNamingRule is changed from "modify" to "preserve".
Example: "VariableNamingRule","preserve"
ImportErrorRule — Procedure to handle import errors
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to handle import errors, specified as one of the values in this table. An import error occurs when readtable is unable to convert data to the expected data type or the cell has the Microsoft error data type.
| Import Error Rule | Behavior |
|---|---|
| "fill" | Replace the data where the error occurred with the contents of theFillValue property.The FillValue property is specified in the VariableImportOptions object of the variable being imported. For more information on accessing theFillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the error-causing record and field. |
| "omitrow" | Omit rows where errors occur. |
| "omitvar" | Omit variables where errors occur. |
Example: "ImportErrorRule","omitvar"
WebOptions — HTTP or HTTPS request options
weboptions object
HTTP or HTTPS request options, specified as aweboptions object. The weboptions object determines how to import data when the specified filename is an internet URL containing the protocol type "http://" or "https://".
ReadVariableNames — Read first row as variable names
true | false | 1 | 0
Indicator for reading the first row as variable names, specified asReadVariableNames and either true,false, 1, or 0. If unspecified,readtable automatically detects the presence of variable names.
| Indicator | Description |
|---|---|
| true | Use when the first row of the region to read contains the variable names for the table. readtable creates a variable, with the detected variable name, for each column in T. |
| false | Use when the first row of the region to read contains data in the table.readtable creates default variable names of the form"Var1",...,"VarN", where N is the number of variables. |
| unspecified | When left unspecified, readtable automatically detectstrue or false and proceeds accordingly. |
Note: If both the"ReadVariableNames" and "ReadRowNames" logical indicators are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property, T.Properties.DimensionNames.
If you specify the ReadVariableNames argument in addition toopts the import options, then the readtable behavior changes based on the specification:
- If
ReadVariableNamesistrue, then read the variable names from the specified file by using theVariableNamesRangeor theVariableNamesLineproperty of the import options object. - If
ReadVariableNamesisfalse, then read the variable names from theVariableNamesproperty of the import options object.
Example: "ReadVariableNames",true
ExpectedNumVariables — Expected number of variables
positive integer
Expected number of variables, specified as ExpectedNumVariables and a positive integer. If unspecified, readtable automatically detects the number of variables.
Example: "ExpectedNumVariables",5
Data Types: single | double
Sheet — Worksheet to read
1 (default) | positive integer | character vector | string scalar
Worksheet to read, specified as Sheet and a positive integer indicating the worksheet index or a character vector or string scalar containing the worksheet name. The worksheet name cannot contain a colon (:). To determine the names of sheets in a spreadsheet file, use sheets = sheetnames(filename). For more information, see sheetnames.
If you specify the Sheet argument in addition toopts the import options, then the readtable function uses the specified value for Sheet argument, overriding the sheet name defined in the import options.
Example: "Sheet", 2
Example: 'Sheet', 'MySheetName'
Example: "Sheet", "MySheetName"
Data Types: char | string | single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
UseExcel — Flag to start instance of Microsoft Excel for Windows
false (default) | true
Flag to start an instance of Microsoft Excel for Windows when reading spreadsheet data, specified as UseExcel and either true, or false.
You can set the "UseExcel" parameter to one of these values:
true—readtablestarts an instance ofMicrosoft Excel when reading the file.false—readtabledoes not start an instance ofMicrosoft Excel when reading the file. When operating in this mode,readtablefunctionality differs in the support of file formats and interactive features, such as formulas and macros.
| UseExcel | true | false |
|---|---|---|
| Supported file formats | .xls, .xlsx, .xlsm, .xltx, .xltm, .xlsb, .ods | .xls, .xlsx, .xlsm, .xltx, .xltm |
| Support for interactive features, such as formulas and macros | Yes | No |
When reading from spreadsheet files on Windows platforms, if you want to start an instance of Microsoft Excel, then set the "UseExcel" parameter totrue.
UseExcel is not supported in noninteractive, automated environments.
Example: "UseExcel",true
MergedCellColumnRule — Rule for cells merged across columns
"placeleft" (default) | "placeright" | "duplicate" | "omitrow" | "error"
Since R2024b
Rule for cells merged across columns, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placeleft" | Place the data in the leftmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placeright" | Place the data in the rightmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitrow" | Omit rows where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
MergedCellRowRule — Rule for cells merged across rows
"placetop" (default) | "placebottom" | "duplicate" | "omitvar" | "error"
Since R2024b
Rule for cells merged across rows, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placetop" | Place the data in the top cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placebottom" | Place the data in the bottom cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitvar" | Omit variables where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
XML Files
FileType — Type of file
"spreadsheet" | "text" | "delimitedtext" | "fixedwidth" | "xml" | "worddocument" | "html"
Type of file, specified as one of these values.
| Value | File Type |
|---|---|
| "spreadsheet" | Spreadsheet files |
| "text" | Text files |
| "delimitedtext" | Delimited text files |
| "fixedwidth" | Fixed-width text files |
| "xml" | XML files |
| "worddocument" | Microsoft Word document |
| "html" | HTML files |
Use the "FileType" name-value pair argument whenfilename does not include the file extension, or when the extension is not one of these:
.txt,.dat, or.csvfor text files.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsfor spreadsheet files.xml, for XML files.docxfor Microsoft Word document files.html,.xhtml, or.htmfor HTML files
Example: "FileType","text"
ReadRowNames — Option to read the first column as row names
false or 0 (default) | true or 1
Option to read the first column as row names, specified as a numeric or logical1 (true) or 0 (false).
- Set
ReadRowNamestotruewhen the first column of the region to read contains the row names for the table. - Set
ReadRowNamestofalsewhen the first column of the region to read contains data, not the row names for the table.
If both the ReadVariableNames and ReadRowNames name-value arguments are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property, T.Properties.DimensionNames.
If you specify the ReadRowNames argument in addition to an import options object, then the readtable behavior changes based on the specification:
- If
ReadRowNamesistrue, then read the row names from the specified file by using theRowNamesColumn(DelimitedTextImportOptions,FixedWidthImportOptions),RowNamesRange(SpreadsheetImportOptions), orRowNamesSelector(XMLImportOptions) property of the respective import options object. - If
ReadRowNamesisfalse, then do not import row names.
If you use the import options syntax without specifying ReadRowNames,readtable uses the value associated with the import options object and its ReadRowNames name-value argument.
Example: "ReadRowNames",true
TreatAsMissing — Placeholder text to treat as empty value
character vector | cell array of character vectors | string scalar | string array
Placeholder text to treat as an empty value, specified asTreatAsMissing and a character vector, cell array of character vectors, string scalar, or string array. Table elements corresponding to these characters are set to the missing value associated with the data type. For more information, see fillmissing.
Example: 'TreatAsMissing','N/A' or"TreatAsMissing","N/A" sets N/A within numeric columns to NaN.
Example: 'TreatAsMissing',{'.','NA','N/A'} or"TreatAsMissing",[".","NA","N/A"] sets .,NA and N/A within numeric columns toNaN.
MissingRule — Procedure to manage missing data
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to manage missing data, specified as one of the values in this table. Data is considered missing if an expected node does not exist.
| Missing Rule | Behavior |
|---|---|
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the missing record and field. |
| "omitrow" | Omit rows that contain missing data. |
| "omitvar" | Omit variables that contain missing data. |
Example: "MissingRule","omitrow"
TextType — Type for imported text data
"string" | "char"
Type for imported text data, specified as one of these values:
"string"— Import text data as string arrays."char"— Import text data as character vectors.
Example: "TextType","char"
DatetimeType — Type for imported date and time data
"datetime" (default) | "text" | "exceldatenum" (spreadsheet files only)
Type for imported date and time data, specified as DatetimeType and one of these values: "datetime", "text", or"exceldatenum". The value "exceldatenum" is applicable only for spreadsheet files, and is not valid for text files.
| Value | Type for Imported Date and Time Data |
|---|---|
| "datetime" | MATLABdatetime data type For more information, see datetime. |
| "text" | If "DatetimeType" is specified as"text", then the type for imported date and time data depends on the value specified in the "TextType" parameter: If "TextType" is set to "char", thenreadtable returns dates as a cell array of character vectors.If "TextType" is set to "string", thenreadtable returns dates as an array of strings. |
| "exceldatenum" | Excel serial date numbersA serial date number is a single number equal to the number of days from a given reference date. Excel serial date numbers use a different reference date than MATLAB serial date numbers. For more information on Excel dates, see Differences between the 1900 and the 1904 date system in Excel. |
Example: "DatetimeType","datetime"
VariableNamingRule — Flag to preserve variable names
"modify" (default) | "preserve"
Flag to preserve variable names, specified as either "modify" or"preserve".
"modify"— Convert invalid variable names (as determined by theisvarname function) to valid MATLAB identifiers."preserve"— Preserve variable names that are not valid MATLAB identifiers such as variable names that include spaces and non-ASCII characters.
Starting in R2019b, variable names and row names can include any characters, including spaces and non-ASCII characters. Also, they can start with any characters, not just letters. Variable and row names do not have to be valid MATLAB identifiers (as determined by the isvarname function). To preserve these variable names and row names, set the value of VariableNamingRule to "preserve". Variable names are not refreshed when the value of VariableNamingRule is changed from "modify" to "preserve".
Example: "VariableNamingRule","preserve"
ImportErrorRule — Procedure to handle import errors
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to handle import errors, specified as one of the values in this table. An import error occurs when readtable is unable to convert text to the expected data type.
| Import Error Rule | Behavior |
|---|---|
| "fill" | Replace the data where the error occurred with the contents of theFillValue property.The FillValue property is specified in the VariableImportOptions object of the variable being imported. For more information on accessing theFillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the error-causing record and field. |
| "omitrow" | Omit rows where errors occur. |
| "omitvar" | Omit variables where errors occur. |
Example: "ImportErrorRule","omitvar"
WebOptions — HTTP or HTTPS request options
weboptions object
HTTP or HTTPS request options, specified as aweboptions object. The weboptions object determines how to import data when the specified filename is an internet URL containing the protocol type "http://" or "https://".
AttributeSuffix — Attribute suffix
"Attribute" (default) | character vector | string scalar
Attribute suffix, specified as AttributeSuffix and either a character vector or string scalar. This argument specifies the suffix the reading function appends to all table variables that correspond to attributes in the input XML file. If you do not specify AttributeSuffix, then the reading function defaults to appending the suffix "Attribute" to all variable names corresponding to attributes in the input XML file.
Example: "AttributeSuffix","_att"
ImportAttributes — Import attributes
logical 1 or true (default) | logical 0 or false
Import attributes, specified as ImportAttributes and either1 (true) or 0 (false). If you specify false, then the reading function will not import the XML attributes in the input file as variables in the output table.
Example: "ImportAttributes",false
RowNodeName — Table row XML node name
character vector | string scalar
Table row XML node name, specified as RowNodeName and either a character vector or string scalar. This argument specifies the XML node name that delineates rows of the output table.
Example: "RowNodeName","XMLNodeName"
RowSelector — Table row XPath expression
character vector | string scalar
Table row XPath expression, specified as a character vector or string scalar that the reading function uses to select individual rows of the output table. You must specifyRowSelector as a valid XPath version 1.0 expression.
Example: "RowSelector","/RootNode/ChildNode"
VariableNodeNames — Table variable XML node names
cell array of character vectors | string array
Table variable XML node names, specified as VariableNodeNames and either a cell array of character vectors or string array. This argument specifies the XML node name that the reading function uses to identify the XML nodes to read as variables in the output table.
Example: "VariableNodeNames",{'XMLNodeName1','XMLNodeName2'}
Example: 'VariableNodeNames',"XMLNodeName"
Example: 'VariableNodeNames',["XMLNodeName1","XMLNodeName2"]
VariableSelectors — Table variable XPath expressions
cell array of character vectors | string array
Table variable XPath expressions, specified as a cell array of character vectors or string array that the reading function uses to select table variables. You must specifyVariableSelectors as valid XPath version 1.0 expressions.
Use XPath selectors to specify which elements of the XML input document to import. For example, suppose you want to import the XML filemyFile.xml, which has the following structure:
| Selection Operation | Syntax | Example |
|---|---|---|
| Select every node whose name matches the node you want to select, regardless of its location in the document. | Prefix the name with two forward slashes (//). | To select every node named "var", use:data = readtable("myFile.xml", "VariableSelectors", "//var") |
| Read the value of an attribute belonging to an element node. | Prefix the attribute with an at sign (@). | To select the value of the category attribute of the table node, use:data = readtable("myFile.xml", "VariableSelectors", "//table/@category") |
| Select a specific node in a set of nodes. | Provide the index of the node you want to select in square brackets ([]). | To select the first var node of each table node, use:data = readtable("myFile.xml", "VariableSelectors", "//var[1]") |
| Specify precedence of operations. | Add parentheses around the expression you want to evaluate first. | To select the first value of each var node, use:data = readtable("myFile.xml", "VariableSelectors", "//table/var[1]") |
| To select the first value of the first var node, use:data = readtable("myFile.xml", "VariableSelectors", "(//table/var)[1]") |
TableNodeName — Table XML node name
character vector | string scalar
Table XML node name, specified as TableNodeName and either a character vector or string scalar. This argument specifies the node in the input structure that the reading function should read to a table.
Example: "TableNodeName","NodeName"
VariableUnitsSelector — Variable units XPath expression
character vector | string scalar
Variable units XPath, specified as a character vector or string scalar that the reading function uses to select the table variable units. You must specifyVariableUnitsSelector as a valid XPath version 1.0 expression.
Example: "VariableUnitsSelector","/RootNode/ChildNode"
VariableDescriptionsSelector — Variable descriptions XPath expression
character vector | string scalar
Variable descriptions XPath expression, specified as a character vector or string scalar that the reading function reads uses to select the table variable descriptions. You must specify VariableDescriptionsSelector as a valid XPath version 1.0 expression.
Example: "VariableDescriptionsSelector","/RootNode/ChildNode"
RowNamesSelector — Table row names XPath expression
character vector | string scalar
Table row names XPath expression, specified as a character vector or string scalar that the reading function uses to select the names of the table rows. You must specifyRowNamesSelector as a valid XPath version 1.0 expression.
Example: "RowNamesSelector","/RootNode/ChildNode"
RepeatedNodeRule — Procedure to handle repeated XML nodes
"addcol" (default) | "ignore" | "error"
Procedure to handle repeated XML nodes in a given row of a table, specified as"addcol", "ignore", or"error".
| Repeated Node Rule | Behavior |
|---|---|
| "addcol" | Add columns for the repeated nodes under the variable header in the table. Specifying the value of "RepeatedNodeRule" as"addcol" does not create a separate variable in the table for the repeated node. |
| "ignore" | Skip importing the repeated nodes. |
| "error" | Display an error message and abort the import operation. |
Example: "RepeatedNodeRule","ignore"
RegisteredNamespaces — Set of registered XML namespace prefixes
string array
Set of registered XML namespace prefixes, specified asRegisteredNamespaces and an array of prefixes. The reading function uses these prefixes when evaluating XPath expressions on an XML file. Specify the namespace prefixes and their associated URLs as an Nx2 string array.RegisteredNamespaces can be used when you also evaluate an XPath expression specified by a selector name-value argument, such asStructSelector for readstruct, orVariableSelectors for readtable andreadtimetable.
By default, the reading function automatically detects namespace prefixes to register for use in XPath evaluation, but you can also register new namespace prefixes using theRegisteredNamespaces name-value argument. You might register a new namespace prefix when an XML node has a namespace URL, but no declared namespace prefix in the XML file.
For example, evaluate an XPath expression on an XML file calledexample.xml that does not contain a namespace prefix. Specify"RegisteredNamespaces" as ["myprefix", "https://www.mathworks.com"] to assign the prefix myprefix to the URL https://www.mathworks.com.
T = readtable("example.xml", "VariableSelector", "/myprefix:Data",... "RegisteredNamespaces", ["myprefix", "https://www.mathworks.com"])
Example: "RegisteredNamespaces",["myprefix", "https://www.mathworks.com"]
TableSelector — Table data XPath expression
character vector | string scalar
Table data XPath expression, specified as a character vector or string scalar that the reading function uses to select the output table data. You must specifyTableSelector as a valid XPath version 1.0 expression. Use XPath selectors to specify which elements of the XML input document to import.
| Selection Operation | Syntax |
|---|---|
| Select every node whose name matches the node you want to select, regardless of its location in the document. | Prefix the name with two forward slashes (//). |
| Select the value of an attribute belonging to an element node. | Prefix the attribute with an at sign (@). |
| Select a specific node in a set of nodes. | Provide the index of the node you want to select in square brackets ([]). |
| Specify precedence of operations. | Add parentheses around the expression you want to evaluate first. |
Example: "myFile.xml", "TableSelector", "//table[1]"
Microsoft Word Document Files
FileType — Type of file
"spreadsheet" | "text" | "delimitedtext" | "fixedwidth" | "xml" | "worddocument" | "html"
Type of file, specified as one of these values.
| Value | File Type |
|---|---|
| "spreadsheet" | Spreadsheet files |
| "text" | Text files |
| "delimitedtext" | Delimited text files |
| "fixedwidth" | Fixed-width text files |
| "xml" | XML files |
| "worddocument" | Microsoft Word document |
| "html" | HTML files |
Use the "FileType" name-value pair argument whenfilename does not include the file extension, or when the extension is not one of these:
.txt,.dat, or.csvfor text files.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsfor spreadsheet files.xml, for XML files.docxfor Microsoft Word document files.html,.xhtml, or.htmfor HTML files
Example: "FileType","text"
ReadRowNames — Option to read first column as row names
false or 0 (default) | true or 1
Option to read the first column as row names,specified as a numeric or logical1 (true) or 0 (false).
- Set
ReadRowNamestotruewhen the first column of the region to read contains the row names for the table. - Set
ReadRowNamestofalsewhen the first column of the region to read contains data, not the row names for the table.
If both the ReadVariableNames and ReadRowNames name-value arguments are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property, T.Properties.DimensionNames.
If you specify the ReadRowNames argument in addition to an import options object, then the readtable behavior changes based on the specification:
- If
ReadRowNamesistrue, then read the row names from the specified file by using theRowNamesColumn(DelimitedTextImportOptions,FixedWidthImportOptions),RowNamesRange(SpreadsheetImportOptions), orRowNamesSelector(XMLImportOptions) property of the respective import options object. - If
ReadRowNamesisfalse, then do not import row names.
If you use the import options syntax without specifying ReadRowNames,readtable uses the value associated with the import options object and its ReadRowNames name-value argument.
Example: "ReadRowNames",true
TreatAsMissing — Placeholder text to treat as empty value
character vector | cell array of character vectors | string scalar | string array
Placeholder text to treat as an empty value, specified asTreatAsMissing and a character vector, cell array of character vectors, string scalar, or string array. Table elements corresponding to these characters are set to the missing value associated with the data type. For more information, see fillmissing.
Example: 'TreatAsMissing','N/A' or"TreatAsMissing","N/A" sets N/A within numeric columns to NaN.
Example: 'TreatAsMissing',{'.','NA','N/A'} or"TreatAsMissing",[".","NA","N/A"] sets .,NA and N/A within numeric columns toNaN.
MissingRule — Procedure to manage missing data
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to manage missing data, specified as one of the values in this table. Data is considered missing if an expected field in a row does not exist.
| Missing Rule | Behavior |
|---|---|
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the missing record and field. |
| "omitrow" | Omit rows that contain missing data. |
| "omitvar" | Omit variables that contain missing data. |
Example: "MissingRule","omitrow"
EmptyRowRule — Rule to apply to empty rows in the table
"skip" (default) | "read" | "error"
Rule to apply to empty rows in the table, specified as one of the following:
"skip"– Skip empty rows."read"– Read empty rows."error"– Ignore empty rows during table detection and error when reading.
Example: "EmptyRowRule","read"
EmptyColumnRule — Rule to apply to empty columns in the table
"skip" (default) | "read" | "error"
Rule to apply to empty columns in the table, specified as one of the following:
"skip"– Skip empty columns."read"– Read empty columns."error"– Ignore empty columns during table detection and error when reading.
Example: "EmptyColumnRule","error"
TextType — Type for imported text data
"string" | "char"
Type for imported text data, specified as one of these values:
"string"— Import text data as string arrays."char"— Import text data as character vectors.
Example: "TextType","char"
DatetimeType — Type for imported date and time data
"datetime" (default) | "text" | "exceldatenum" (spreadsheet files only)
Type for imported date and time data, specified as DatetimeType and one of these values: "datetime", "text", or"exceldatenum". The value "exceldatenum" is applicable only for spreadsheet files, and is not valid for text files.
| Value | Type for Imported Date and Time Data |
|---|---|
| "datetime" | MATLABdatetime data type For more information, see datetime. |
| "text" | If "DatetimeType" is specified as"text", then the type for imported date and time data depends on the value specified in the "TextType" parameter: If "TextType" is set to "char", thenreadtable returns dates as a cell array of character vectors.If "TextType" is set to "string", thenreadtable returns dates as an array of strings. |
| "exceldatenum" | Excel serial date numbersA serial date number is a single number equal to the number of days from a given reference date. Excel serial date numbers use a different reference date than MATLAB serial date numbers. For more information on Excel dates, see Differences between the 1900 and the 1904 date system in Excel. |
Example: "DatetimeType","datetime"
VariableNamingRule — Flag to preserve variable names
"modify" (default) | "preserve"
Flag to preserve variable names, specified as either "modify" or"preserve".
"modify"— Convert invalid variable names (as determined by theisvarname function) to valid MATLAB identifiers."preserve"— Preserve variable names that are not valid MATLAB identifiers such as variable names that include spaces and non-ASCII characters.
Starting in R2019b, variable names and row names can include any characters, including spaces and non-ASCII characters. Also, they can start with any characters, not just letters. Variable and row names do not have to be valid MATLAB identifiers (as determined by the isvarname function). To preserve these variable names and row names, set the value of VariableNamingRule to "preserve". Variable names are not refreshed when the value of VariableNamingRule is changed from "modify" to "preserve".
Example: "VariableNamingRule","preserve"
ImportErrorRule — Procedure to handle import errors
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to handle import errors, specified as one of the values in this table. An import error occurs when readtable is unable to convert text to the expected data type.
| Import Error Rule | Behavior |
|---|---|
| "fill" | Replace the data where the error occurred with the contents of theFillValue property.The FillValue property is specified in the VariableImportOptions object of the variable being imported. For more information on accessing theFillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the error-causing record and field. |
| "omitrow" | Omit rows where errors occur. |
| "omitvar" | Omit variables where errors occur. |
Example: "ImportErrorRule","omitvar"
WebOptions — HTTP or HTTPS request options
weboptions object
HTTP or HTTPS request options, specified as aweboptions object. The weboptions object determines how to import data when the specified filename is an internet URL containing the protocol type "http://" or "https://".
TableIndex — Index of table to read
1 (default) | positive integer
Index of table to read from Microsoft Word document or HTML file containing multiple tables, specified as a positive integer.
When you specify TableIndex, the software automatically setsTableSelector to the equivalent XPath expression.
Example: "TableIndex",2
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
MergedCellColumnRule — Rule for cells merged across columns
"placeleft" (default) | "placeright" | "duplicate" | "omitrow" | "error"
Rule for cells merged across columns, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placeleft" | Place the data in the leftmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placeright" | Place the data in the rightmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitrow" | Omit rows where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
MergedCellRowRule — Rule for cells merged across rows
"placetop" (default) | "placebottom" | "duplicate" | "omitvar" | "error"
Rule for cells merged across rows, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placetop" | Place the data in the top cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placebottom" | Place the data in the bottom cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitvar" | Omit variables where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
VariableNamesRow — Row containing variable names
nonnegative integer
Row containing variable names, specified as a nonnegative integer.
- If you do not specify
VariableNamesRow, then the software reads variable names according to theReadVariableNamesargument. - If
VariableNamesRowis0, then the software does not import the variable names. - Otherwise, the software imports the variable names from the specified row.
Example: "VariableNamesRow",2
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
VariableUnitsRow — Row containing variable units
0 (default) | nonnegative integer
Row containing variable units, specified as a nonnegative integer.
If VariableUnitsRow is 0, then the software does not import the variable units. Otherwise, the software imports the variable units from the specified row.
Example: "VariableUnitsRow",3
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
VariableDescriptionsRow — Row containing variable descriptions
0 (default) | nonnegative integer
Row containing variable descriptions, specified as a nonnegative integer.
If VariableDescriptionsRow is 0, then the software does not import the variable descriptions. Otherwise, the software imports the variable descriptions from the specified row.
Example: "VariableDescriptionsRow",4
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
TableSelector — Table data XPath expression
character vector | string scalar
Table data XPath expression, specified as a character vector or string scalar that the reading function uses to select the output table data. You must specifyTableSelector as a valid XPath version 1.0 expression. Use XPath selectors to specify which elements of the XML input document to import.
| Selection Operation | Syntax |
|---|---|
| Select every node whose name matches the node you want to select, regardless of its location in the document. | Prefix the name with two forward slashes (//). |
| Select the value of an attribute belonging to an element node. | Prefix the attribute with an at sign (@). |
| Select a specific node in a set of nodes. | Provide the index of the node you want to select in square brackets ([]). |
| Specify precedence of operations. | Add parentheses around the expression you want to evaluate first. |
Example: "TableSelector","/RootNode/ChildNode"
Example: "myFile.xml", "TableSelector", "//table[1]"
HTML Files
FileType — Type of file
"spreadsheet" | "text" | "delimitedtext" | "fixedwidth" | "xml" | "worddocument" | "html"
Type of file, specified as one of these values.
| Value | File Type |
|---|---|
| "spreadsheet" | Spreadsheet files |
| "text" | Text files |
| "delimitedtext" | Delimited text files |
| "fixedwidth" | Fixed-width text files |
| "xml" | XML files |
| "worddocument" | Microsoft Word document |
| "html" | HTML files |
Use the "FileType" name-value pair argument whenfilename does not include the file extension, or when the extension is not one of these:
.txt,.dat, or.csvfor text files.xls,.xlsb,.xlsm,.xlsx,.xltm,.xltx, or.odsfor spreadsheet files.xml, for XML files.docxfor Microsoft Word document files.html,.xhtml, or.htmfor HTML files
Example: "FileType","text"
ReadRowNames — Option to read first column as row names
false or 0 (default) | true or 1
Option to read the first column as row names, specified as a numeric or logical1 (true) or 0 (false).
- Set
ReadRowNamestotruewhen the first column of the region to read contains the row names for the table. - Set
ReadRowNamestofalsewhen the first column of the region to read contains data, not the row names for the table.
If both the ReadVariableNames and ReadRowNames name-value arguments are true, then readtable saves the name in the first column of the first row of the region to read as the first dimension name in the property T.Properties.DimensionNames.
If you specify the ReadRowNames argument in addition to an import options object, then the readtable behavior changes based on the specification:
- If
ReadRowNamesistrue, then read the row names from the specified file by using theRowNamesColumn(DelimitedTextImportOptions,FixedWidthImportOptions),RowNamesRange(SpreadsheetImportOptions), orRowNamesSelector(XMLImportOptions) property of the respective import options object. - If
ReadRowNamesisfalse, then do not import row names.
If you use the import options syntax without specifying ReadRowNames,readtable uses the value associated with the import options object and its ReadRowNames name-value argument.
Example: "ReadRowNames",true
TreatAsMissing — Placeholder text to treat as empty value
character vector | cell array of character vectors | string scalar | string array
Placeholder text to treat as an empty value, specified asTreatAsMissing and a character vector, cell array of character vectors, string scalar, or string array. Table elements corresponding to these characters are set to the missing value associated with the data type. For more information, see fillmissing.
Example: "TreatAsMissing","N/A" or"TreatAsMissing","N/A" sets N/A within numeric columns to NaN.
Example: 'TreatAsMissing',{'.','NA','N/A'} or"TreatAsMissing",[".","NA","N/A"] sets .,NA and N/A within numeric columns toNaN.
MissingRule — Procedure to manage missing data
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to manage missing data, specified as one of the values in this table. Data is considered missing if an expected field in a row does not exist.
| Missing Rule | Behavior |
|---|---|
| "fill" | Replace missing data with the contents of the FillValue property.The FillValue property is specified in theVariableImportOptions object of the variable being imported. For more information on accessing the FillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the missing record and field. |
| "omitrow" | Omit rows that contain missing data. |
| "omitvar" | Omit variables that contain missing data. |
Example: "MissingRule","omitrow"
EmptyRowRule — Rule to apply to empty rows in the table
"skip" (default) | "read" | "error"
Rule to apply to empty rows in the table, specified as one of the following:
"skip"– Skip empty rows."read"– Read empty rows."error"– Ignore empty rows during table detection and error when reading.
Example: "EmptyRowRule","read"
EmptyColumnRule — Rule to apply to empty columns in the table
"skip" (default) | "read" | "error"
Rule to apply to empty columns in the table, specified as one of the following:
"skip"– Skip empty columns."read"– Read empty columns."error"– Ignore empty columns during table detection and error when reading.
Example: "EmptyColumnRule","error"
TextType — Type for imported text data
"string" | "char"
Type for imported text data, specified as one of these values:
"string"— Import text data as string arrays."char"— Import text data as character vectors.
Example: "TextType","char"
DatetimeType — Type for imported date and time data
"datetime" (default) | "text" | "exceldatenum" (spreadsheet files only)
Type for imported date and time data, specified as DatetimeType and one of these values: "datetime", "text", or"exceldatenum". The value "exceldatenum" is applicable only for spreadsheet files, and is not valid for text files.
| Value | Type for Imported Date and Time Data |
|---|---|
| "datetime" | MATLABdatetime data type For more information, see datetime. |
| "text" | If "DatetimeType" is specified as"text", then the type for imported date and time data depends on the value specified in the "TextType" parameter: If "TextType" is set to "char", thenreadtable returns dates as a cell array of character vectors.If "TextType" is set to "string", thenreadtable returns dates as an array of strings. |
| "exceldatenum" | Excel serial date numbersA serial date number is a single number equal to the number of days from a given reference date. Excel serial date numbers use a different reference date than MATLAB serial date numbers. For more information on Excel dates, see Differences between the 1900 and the 1904 date system in Excel. |
Example: "DatetimeType","datetime"
VariableNamingRule — Flag to preserve variable names
"modify" (default) | "preserve"
Flag to preserve variable names, specified as either "modify" or"preserve".
"modify"— Convert invalid variable names (as determined by theisvarname function) to valid MATLAB identifiers."preserve"— Preserve variable names that are not valid MATLAB identifiers such as variable names that include spaces and non-ASCII characters.
Starting in R2019b, variable names and row names can include any characters, including spaces and non-ASCII characters. Also, they can start with any characters, not just letters. Variable and row names do not have to be valid MATLAB identifiers (as determined by the isvarname function). To preserve these variable names and row names, set the value of VariableNamingRule to "preserve". Variable names are not refreshed when the value of VariableNamingRule is changed from "modify" to "preserve".
Example: "VariableNamingRule","preserve"
ImportErrorRule — Procedure to handle import errors
"fill" (default) | "error" | "omitrow" | "omitvar"
Procedure to handle import errors, specified as one of the values in this table. An import error occurs when readtable is unable to convert text to the expected data type.
| Import Error Rule | Behavior |
|---|---|
| "fill" | Replace the data where the error occurred with the contents of theFillValue property.The FillValue property is specified in the VariableImportOptions object of the variable being imported. For more information on accessing theFillValue property, see setvaropts. |
| "error" | Stop importing and display an error message showing the error-causing record and field. |
| "omitrow" | Omit rows where errors occur. |
| "omitvar" | Omit variables where errors occur. |
Example: "ImportErrorRule","omitvar"
WebOptions — HTTP or HTTPS request options
weboptions object
HTTP or HTTPS request options, specified as aweboptions object. The weboptions object determines how to import data when the specified filename is an internet URL containing the protocol type "http://" or "https://".
TableIndex — Index of table to read
1 (default) | positive integer
Index of table to read from Microsoft Word document or HTML file containing multiple tables, specified as a positive integer.
When you specify TableIndex, the software automatically setsTableSelector to the equivalent XPath expression.
Example: "TableIndex",2
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
MergedCellColumnRule — Rule for cells merged across columns
"placeleft" (default) | "placeright" | "duplicate" | "omitrow" | "error"
Rule for cells merged across columns, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placeleft" | Place the data in the leftmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placeright" | Place the data in the rightmost cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitrow" | Omit rows where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
MergedCellRowRule — Rule for cells merged across rows
"placetop" (default) | "placebottom" | "duplicate" | "omitvar" | "error"
Rule for cells merged across rows, specified as one of the values in this table.
| Import Rule | Behavior |
|---|---|
| "placetop" | Place the data in the top cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "placebottom" | Place the data in the bottom cell and fill the remaining cells with the contents of the FillValue property.You can specify theFillValue property in the VariableImportOptions object of the variable being imported. For more information on setting theFillValue property, see setvaropts. |
| "duplicate" | Duplicate the data in all cells. |
| "omitvar" | Omit variables where merged cells occur. |
| "error" | Display an error message and cancel the import operation. |
VariableNamesRow — Row containing variable names
nonnegative integer
Row containing variable names, specified as a nonnegative integer.
- If you do not specify
VariableNamesRow, then the software reads variable names according to theReadVariableNamesargument. - If
VariableNamesRowis0, then the software does not import the variable names. - Otherwise, the software imports the variable names from the specified row.
Example: "VariableNamesRow",2
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
VariableUnitsRow — Row containing variable units
0 (default) | nonnegative integer
Row containing variable units, specified as a nonnegative integer.
If VariableUnitsRow is 0, then the software does not import the variable units. Otherwise, the software imports the variable units from the specified row.
Example: "VariableUnitsRow",3
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
VariableDescriptionsRow — Row containing variable descriptions
0 (default) | nonnegative integer
Row containing variable descriptions, specified as a nonnegative integer.
If VariableDescriptionsRow is 0, then the software does not import the variable descriptions. Otherwise, the software imports the variable descriptions from the specified row.
Example: "VariableDescriptionsRow",4
Data Types: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
TableSelector — Table data XPath expression
character vector | string scalar
Table data XPath expression, specified as a character vector or string scalar that the reading function uses to select the output table data. You must specifyTableSelector as a valid XPath version 1.0 expression. Use XPath selectors to specify which elements of the XML input document to import.
| Selection Operation | Syntax |
|---|---|
| Select every node whose name matches the node you want to select, regardless of its location in the document. | Prefix the name with two forward slashes (//). |
| Select the value of an attribute belonging to an element node. | Prefix the attribute with an at sign (@). |
| Select a specific node in a set of nodes. | Provide the index of the node you want to select in square brackets ([]). |
| Specify precedence of operations. | Add parentheses around the expression you want to evaluate first. |
Example: "TableSelector","/RootNode/ChildNode"
Example: "myFile.xml", "TableSelector", "//table[1]"
Output Arguments
Output table, returned as a table. The table can store metadata such as descriptions, variable units, variable names, and row names. For more information, see the Properties section of table.
Extended Capabilities
Thread-Based Environment
Run code in the background using MATLAB® backgroundPool or accelerate code with Parallel Computing Toolbox™ ThreadPool.
Usage notes and limitations:
- Text and spreadsheet file workflows are supported in thread-based environments.
Version History
Introduced in R2013b
R2024b: Specify how to import merged cells in spreadsheets
When importing data from spreadsheets, you can specify how readtable imports cells that are merged across rows and columns by using theMergedCellRowRule and MergedCellColumnRule name-value arguments.
R2023a: Create tables from text and spreadsheet files in thread-based environments
This function supports thread-based environments for text and spreadsheet file workflows.
R2020a: Results of detectImportOptions function used by default to import tabular data
By default, the readtable function uses the results of thedetectImportOptions function to import tabular data. In essence, these two function calls behave identically.
T = readtable(filename) T = readtable(filename,detectImportOptions(filename))
In R2020a, there are several differences between the default behavior ofreadtable and its default behavior in previous releases.
| Description of Input Fields or Rows | Default R2020a readtable Behavior | Default Behavior in Previous Releases |
|---|---|---|
| First row does not have text to assign as names of output table variables | Assigns the names Var1,...,Var_N_ as the names of output table variables | Converts the values in the first row of data values to the names of output table variables |
| Multiple rows of text as header lines | Ignore additional header linesImport values in remaining rows as detected data types | Import additional header lines as text in the first rows of output tableImport values in remaining rows as text |
| Empty fields | Treat as missing values for detected data type | Treat as empty character vectors or strings |
| Values in quotes | Treat as detected data type | Treat as text |
| Text that cannot be converted | Treat as missing values for detected data type | Treat as text |
| Nonnumeric character trails numeric character without delimiter between them | Treat characters as nonnumeric | Treat numeric and nonnumeric characters as though delimiter separated them |
| Input text file has lines with different number of delimiters | Returns output table with extra variables | Raises error message |
To call readtable with the default behavior it had up to R2019b, use the 'Format','auto' name-value pair argument.
T = readtable(filename,'Format','auto')