Database Replication in System Design (original) (raw)
Last Updated : 17 Apr, 2026
Making and keeping duplicate copies of a database on other servers is known as database replication. It is essential for improving modern systems' scalability, reliability, and data availability.
- By distributing their data across multiple servers, organizations can guarantee that it will remain accessible even in the case of a server failure.
- This redundancy also improves data reliability because many copies are available to recover data in the case of corruption or loss.
- Database replication can help in workload distribution among servers, boosting scalability and performance.
**Example: An e-commerce website may use a primary database for write operations and multiple replica databases to handle read requests from users.
Working
These steps explaining how database replication works:
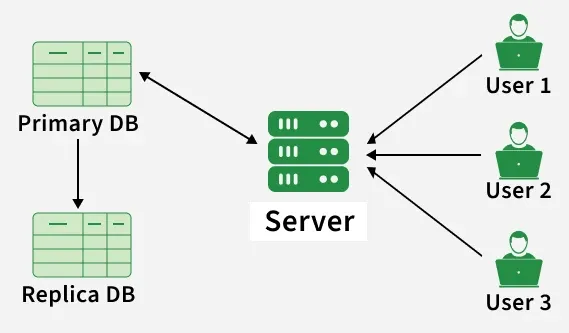
Working of Database Replication
- **Identify the Primary Database (Source): A primary (master) database is selected as the main source where all data changes originate.
- **Set Up Replica Databases (Targets): One or more replica databases are configured to receive data from the primary database.
- **Capture Data Changes: All inserts, updates, and deletes are recorded using logs or change data capture mechanisms.
- **Transmit Changes to Replicas: Captured changes are sent to replica databases either in real-time or at scheduled intervals.
- **Apply Changes on Replicas: Replica databases apply the received updates to stay synchronized with the primary database.
- **Monitor Synchronization: The system continuously checks replication status and resolves delays or synchronization issues.
- **Handle Read/Write Operations: Read operations are distributed across replicas, while write operations typically go to the primary database (depending on the model).
Types of Database Replication
Understand the different types of database replication:
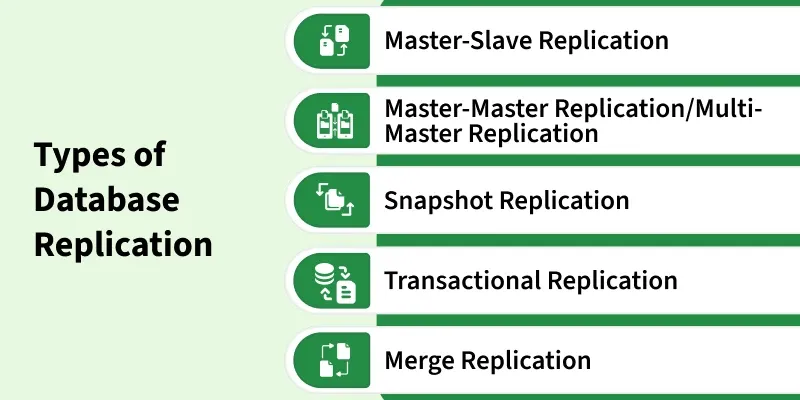
1. Master-Slave Replication
In this replication model, one database acts as the primary server while others maintain copies of its data.
- The master database handles all write operations such as insert, update, and delete.
- Slave databases replicate data from the master and usually handle read operations.
2. Master-Master Replication / Multi-Master Replication
In this setup, multiple databases act as masters and can accept both read and write operations.
- Changes made in one master database are replicated to the other master databases.
- Improves availability and allows distributed write operations across multiple servers.
3. Snapshot Replication
This method replicates the entire database by taking a snapshot at a specific point in time.
- A complete copy of the database is created and transferred to other servers.
- Suitable for systems where data changes are not very frequent.
4. Transactional Replication
Transactional replication synchronizes databases by replicating changes as they occur.
- Changes made in the publisher database are quickly sent to subscriber databases.
- Ensures near real-time data consistency between multiple databases.
5. Merge Replication
Merge replication allows multiple databases to update data independently and later synchronize the changes.
- Both publisher and subscriber databases can make modifications to the data.
- Conflicts are detected and resolved during the synchronization process.
Strategies
Database replication strategies determine how to select data, copy and distribute it between databases to gain specific goals such as scalability, availability, and efficiency.
Some common database replication strategies include the following:
- **Full Replication: Also referred to as full database replication, this is a technique in which the whole database is replicated to one or more destination servers. All the tables, rows, and columns in the database are copied to the destination servers. The replicas thus obtain an exact copy of the original database.
- **Partial Replication: This method involves not replicating the entire database, but merely a subset of it, such as particular tables, rows, or columns. This method can be useful when only specific data has to be reproduced for reporting, analysis, or other reasons, and it enables a more effective use of resources.
- **Selective Replication: It is a database replication strategy that involves replicating data based on predefined criteria or conditions. Unlike full replication, which replicates the entire database, or partial replication, which replicates a subset of the database, selective replication allows for more granular control over which data is replicated.
- **Sharding: It is a database scaling technique that involves partitioning data across multiple database instances (shards) based on a key. This approach allows for distributing the workload and data storage across multiple servers, improving scalability and performance.
- **Hybrid Replication: It is a database replication strategy that combines multiple replication techniques to achieve specific goals. This approach allows for the customization of replication methods based on the requirements of different parts of the database or application.
Configurations
To accomplish particular objectives related to data consistency, availability, and performance, database replication can be set up and run in a variety of ways:
1. Synchronous Replication Configuration
In synchronous replication, data changes are replicated to replicas immediately before the transaction is completed.
- The transaction is committed only after at least one replica confirms that it has received the update.
- Ensures strong data consistency because the primary and replicas remain fully synchronized.
2. Asynchronous Replication Configuration
In asynchronous replication, the primary database sends updates to replicas without waiting for confirmation.
- The primary database completes the transaction immediately, improving performance and speed.
- Replicas may receive updates with a slight delay, which can lead to temporary data inconsistency.
3. Semi-synchronous Replication Configuration
Semi-synchronous replication is a hybrid approach that combines features of synchronous and asynchronous replication.
- The primary database waits for confirmation from at least one replica before committing the transaction.
- Other replicas receive updates asynchronously, improving performance while maintaining reasonable consistency.
Importance
Database replication is important for several reasons:
- **High Availability: Database replication ensures High Availability by keeping data available even if one server fails, so the application runs without downtime.
- **Disaster Recovery: Replication supports Disaster Recovery by storing backup copies on multiple servers, helping restore data quickly after failure.
- **Load Balancer / Load Balancing: Replication improves Load Balancing by allowing a Load Balancer to send read requests to replica servers, reducing load on the primary DB.
- **Fault Tolerance: Replication provides Fault Tolerance by shifting traffic to another replica server when one server goes down.
- **Scalability: Replication helps Scalability by distributing database traffic across servers and handling more users smoothly.
- **Data Locality: Replication improves Data Locality by placing replicas near users, reducing latency and improving performance.
Challenges
Some of the challenges with Database Replication are:
- **Data Consistency: It can be difficult to maintain consistency among replicas, particularly in asynchronous replication situations where data replication may be delayed.
- **Complexity: System complexity is increased by database replication, which requires thorough setup and administration to guarantee accurate and effective data replication.
- **Cost: Setting up and maintaining a replicated database environment can be costly, especially for large-scale deployments with multiple replicas.
- **Conflict Resolution: When the same data is changed on multiple replicas at once in multi-master replication environments, conflicts might arise that require conflict resolution techniques.
- **Latency: Synchronous replication, which requires acknowledgment from replicas before committing transactions, can introduce latency and impact the performance of the primary database.