Songyou Peng - Homepage (original) (raw)
| News 06/2026 Real-3DQA received the |
|---|
| Research (Selected |Full List) |
Your browser does not support the video tag.  |
Vision Banana: Image Generators are Generalist Vision Learners Project Co-Lead Google DeepMind tech report |website | ||
|---|---|---|---|
| Gemini 3 & Gemini 2.5 Core Contributor Google DeepMind tech report | website | |||
Your browser does not support the video tag.  |
Selfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment Youming Deng,Songyou Peng,Junyi Zhang,Kathryn Heal,Tiancheng Sun,John Flynn,Steve Marschner,Lucy Chai Conference on Computer Vision and Pattern Recognition (CVPR), 2026 (Oral) paper |project page Teach a 3D foundation model to improve itself. No ground truth needed. | ||
Your browser does not support the video tag.  |
Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving Jiahao Wang,Bo Sun,Yijing Bai,Vincent Casser,Songyou Peng,Zehao Zhu,Meng-Li Shih,Xander Masotto,Shih-Yang Su,Kanaad V Parvate,Tiancheng Ge,Linn Bieske,Dragomir Anguelov,Mingxing Tan,Chiyu "Max" Jiang Conference on Computer Vision and Pattern Recognition (CVPR), 2026 paper A prototype for the Waymo World Model, translating in-the-wild monocular videos into high-fidelity multi-modal sensor logs. | ||
| Do 3D Large Language Models Really Understand 3D Spatial Relationships? Xianzheng Ma*,Tao Sun*,Shuai Chen,Yash Bhalgat,Jindong Gu,Angel X Chang,Iro Armeni,Iro Laina,Songyou Peng†,Victor Adrian Prisacariu† International Conference on Learning Representations (ICLR), 2026 Best Paper Runner-up Award at the 3D-LLM/VLA Workshop at CVPR 2026 (* equal contribution, † equal supervision) paper |project page | code | data Your 3D-LLM isn't understanding 3D. It might be just guessing without seeing. | |
  |
UFO-4D: Unposed Feedforward 4D Reconstruction from Two Images Junhwa Hur,Charles Herrmann,Songyou Peng,Philipp Henzler,Zeyu Ma,Todd Zickler,Deqing Sun International Conference on Learning Representations (ICLR), 2026 paper |project page | code Feedforward 4D reconstruction from just two unposed images. | |
Your browser does not support the video tag.  |
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering Jonas Kulhanek,Marie-Julie Rakotosaona,Fabian Manhardt,Christina Tsalicoglou,Michael Niemeyer,Torsten Sattler,Songyou Peng,Federico Tombari Conference on Neural Information Processing Systems (NeurIPS), 2025 (Spotlight, top 3%) paper |project page City-scale 3DGS in real-time with an iPhone. | ||
 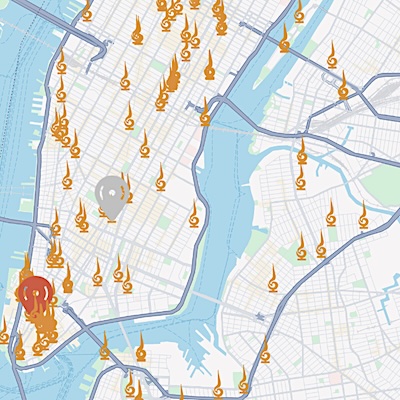 |
Visual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images Boyang Deng,Songyou Peng*,Kyle Genova*,Gordon Wetzstein,Noah Snavely,Leonidas Guibas,Thomas Funkhouser International Conference on Computer Vision (ICCV), 2025 (Highlight, top 2.3%) paper |project page We help you find "unusual" things and trends in NYC and SF, like 200+ abstract sculptures, see left for an example. | ||
Your browser does not support the video tag.  |
CL-Splats: Continual Learning of Gaussian Splatting with Local Optimization Jan Ackermann, Jonas Kulhanek, Shengqu Cai,Haofei Xu,Marc Pollefeys,Gordon Wetzstein,Leonidas Guibas,Songyou Peng International Conference on Computer Vision (ICCV), 2025 paper |project page | code We give you great 3DGS even after you add, delete, change stuff in your room. | |
 |
SplatTalk: 3D VQA with Gaussian Splatting Anh Thai,Songyou Peng,Kyle Genova,Leonidas Guibas,Thomas Funkhouser International Conference on Computer Vision (ICCV), 2025 paper |project page 3D language Gaussian field benefits 3D VQA tasks. | ||
Your browser does not support the video tag.  |
DepthSplat: Connecting Gaussian Splatting and Depth Haofei Xu,Songyou Peng,Fangjinhua Wang,Hermann Blum,Daniel Barath,Andreas Geiger,Marc Pollefeys Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper |project page | code Depths helps 3DGS, 3DGS helps depth prediction. | |
Your browser does not support the video tag.  |
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation Haotong Lin,Sida Peng,Jingxiao Chen,Songyou Peng Jiaming Sun,Minghuan Liu,Hujun Bao,Jiashi Feng,Xiaowei Zhou,Bingyi Kang Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper |project page | code 4K accurate metric depth estimation from low-res LiDAR. | |
Your browser does not support the video tag.  |
Free360: Layered Gaussian Splatting for Unbounded 360-Degree View Synthesis from Extremely Sparse and Unposed Views Chong Bao,Zehao Yu,Jiale Shi,Guofeng Zhang,Songyou Peng,Zhaopeng Cui Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper |project page | video | code Video models enable unbounded 360° scene reconstruction from 3-4 unposed views. |
Your browser does not support the video tag.  |
WildGS-SLAM: Monocular Gaussian Splatting SLAM in Dynamic Environments Jianhao Zheng*,Zihan Zhu,Valentin Bieri,Marc Pollefeys,Songyou Peng,Iro Armeni Conference on Computer Vision and Pattern Recognition (CVPR), 2025 paper |project page | code Robust SLAM for dynamic scenes in the wild. | |
Your browser does not support the video tag.  |
|
code Unposed 3DGS made easy, also enables SoTA relative pose estimation performance! | |
Your browser does not support the video tag.  |
WildGaussians: 3D Gaussian Splatting in the Wild Jonas Kulhanek,Songyou Peng,Zuzana Kukelova,Marc Pollefeys,Torsten Sattler Conference on Neural Information Processing Systems (NeurIPS), 2024 paper |project page | code Boost 3DGS for in-the-wild scenes with appearance and dynamic changes. | |
  |
Renovating Names in Open-Vocabulary Segmentation Benchmarks Haiwen Huang,Songyou Peng,Dan Zhang,Andreas Geiger Conference on Neural Information Processing Systems (NeurIPS), 2024 paper |project page | code Wanna enhance your segmentation model or benchmark? Renovate names now! | |
  |
Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels Rui Huang,Songyou Peng,Ayça Takmaz, Federico Tombari,Marc Pollefeys,Shiji Song,Gao Huang,Francis Engelmann European Conference on Computer Vision (ECCV), 2024 paper |project page | code | demo A self-supervised segmentation approach that outperforms fully-supervised methods. |
Your browser does not support the video tag.  |
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization Weiyang Liu*, Zeju Qiu*, Yao Feng**, Yuliang Xiu**, Yuxuan Xue**, Longhui Yu**,Haiwen Feng, Zhen Liu, Juyeon Heo,Songyou Peng, Yandong Wen, Michael J. Black, Adrian Weller, Bernhard Schölkopf (*/** equal contribution) International Conference on Learning Representations (ICLR), 2024 paper |project page | code | |
|---|
Your browser does not support the video tag.  |
FastHuman: Reconstructing High-Quality Clothed Human in Minutes Lixiang Lin, Songyou Peng, Qijun Gan, Jianke Zhu International Conference on 3D Vision (3DV), 2024 (Spotlight, top 8.2%) paper |project page | code Shape As Points (SAP) for fast human body reconstruction. |
|---|---|---|
 |
Neural Scene Representations for 3D Reconstruction and Scene Understanding Songyou Peng PhD Thesis, 2023 ECVA PhD Award, 2024 3DV Outstanding Dissertation Award Honorable Mention, 2026 thesis |slides PhD supervisors: Prof. Marc Pollefeys (ETH Zurich), Prof. Andreas Geiger (MPI-IS) External committee: Prof. Leonidas J. Guibas (Stanford), Prof. Vincent Sitzmann (MIT) |
Your browser does not support the video tag.  |
|
video | code Zero-shot approach for novel 3D scene understanding tasks with open-vocabulary queries. |
|---|---|---|---|
Your browser does not support the video tag.  |
|
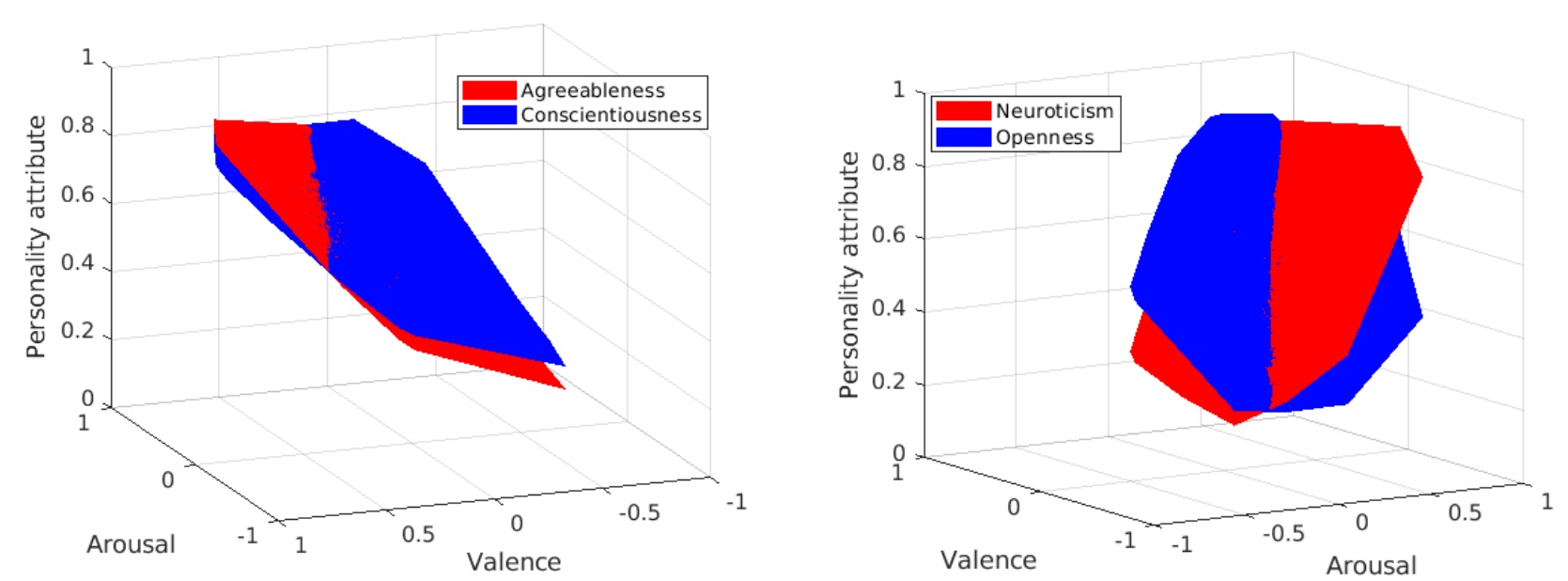 |
PersEmoN: A Deep Network for Joint Analysis of Apparent Personality, Emotion and Their Relationship Le Zhang, Songyou Peng, Stefan Winkler IEEE Transactions on Affective Computing (TAFFC), 2019. In press. paper |code A journal extension of our ACM MM 2018 paper. | |
|---|---|---|
 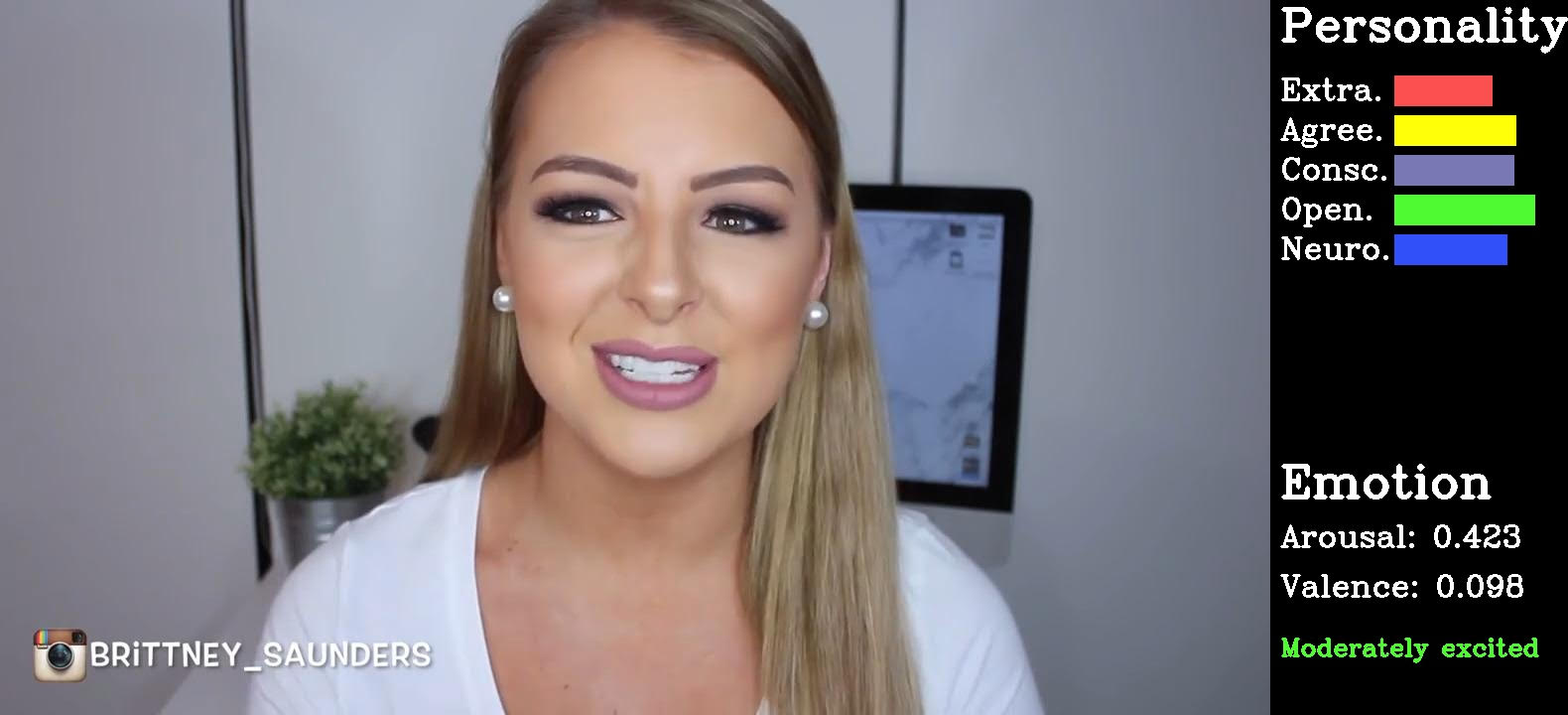 |
Give Me One Portrait Image, I Will Tell You Your Emotion and Personality Songyou Peng, Le Zhang, Stefan Winkler, Marianne Winslett ACM International Conference on Multimedia (ACM MM), 2018 paper |slides | code Technical Demo. A deep Siamese-like network is introduced to predict one's Big-Five personality and arousal-valence emotion from one portrait photo. |
  |
Depth Super-Resolution Meets Uncalibrated Photometric Stereo Songyou Peng, Bjoern Haefner, Yvain Queau, Daniel Cremers International Conference on Computer Vision (ICCV) Workshops, 2017 paper |slides | code & data A novel depth super-resolution approach for RGB-D sensors is presented. This paper a part of my master thesis, and subsumed by our TPAMI paper. |
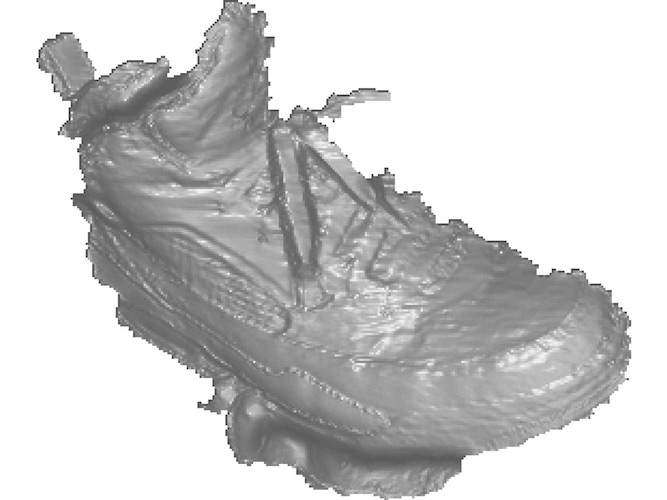  |
High Quality Shape from a RGB-D Camera using Photometric Stereo Songyou Peng M.Sc. Thesis, Techinical University of Munich Supervisor: Yvain Queau and Daniel Cremers thesis |bibtex | poster |
Mentored Students and Interns
I am fortunate to (co-)mentor some talented and highly motivated students and interns. I have learnt from and gotten inspired by them:
- Gene Chou (2025-2026): PhD student at Cornell University
- Internship project at Google: City-RAG (ECCV'26 submission)
- Youming Deng (2025): PhD student at Cornell University
- Internship project at Google: Selfi (CVPR'26 Oral)
- Jiahao Wang (2025): PhD student at John Hopkins University
- Internship project at Waymo: Sensor2Sensor (CVPR'26)
- Zehao Yu (2025): PhD student at University of Tübingen
- Internship project at Google DeepMind: 3D Reconstruction with Multimodal LLM
- Jonas Kulhanek (2024-2025): PhD student at Czech Technical University
- Internship project at Google: LODGE (NeurIPS'25 spotlight paper)
- PhD project at ETH Zurich: WildGaussians (NeurIPS'24)
- Boyang Deng (2024): PhD student at Stanford University
- Internship project at Google DeepMind: Visual Chronicles (ICCV'25 highlight paper)
- Anh Thai (2024): PhD student at Georgia Tech
- Internship project at Google DeepMind: SplatTalk (ICCV'25)
- → Senior AI Multimodal Researcher at Dolby Laboratories
- Jan Ackermann (2024): MSc student at ETH Zurich
- Semester thesis: Continual Learning of Gaussian Splatting with Local Optimization (ICCV'25)
- → Master thesis and PhD student at Stanford University, advised by Gordon Wetzstein
- Gonca Yilmaz (2024): MSc student at University of Zurich
- Semester thesis: Open Vocabulary Segmentation from Multi-Modal Inputs (ICCVW'23)
- Master thesis: OpenDAS: Open-Vocabulary Domain Adaption for Segmentation (ICLR'25 submission)
- → Software engineer at Google
- Weining Ren (2023): MSc student at ETH Zurich
- Master thesis: NeRF On-the-go (CVPR'24)
- → PhD student at The University of Hong Kong (HKU), advised by Kai Han
- Lei Li (2023): MSc student at ETH Zurich
- Master thesis: 3D Neural Edge Reconstruction (CVPR'24)
- → Computer vision engineer at ByteDance
- Mirlan Karimov (2023): MSc student at ETH Zurich
- Master thesis: Interactive Preprocessing via Multi-Modal Prompting for NeRFs
- → PhD student at Mercedes-Benz AG
- Junru Lin (2023): BSc student at Univeristy of Toronto
- Summer project: Ternary-type Opacity and Hybrid Odometry for RGB-only NeRF-SLAM (IROS'24)
- Shengqu Cai (2022): MSc student at ETH Zurich
- Master thesis: DiffDreamer (ICCV'23)
- → PhD student at Stanford University, advised by Gordon Wetzstein
- Zihan Zhu (2021): BSc student at Zhejiang University
- Bachelor internship project: NICE-SLAM (CVPR'22)
- Semester project: NICER-SLAM (3DV'24, Best Paper Honorable Mention)
- Semester project: WildGS-SLAM (CVPR'25)
- Master thesis: Leverage geometric constraints for better depth estimation
- → Direct doctorate student at ETH Zurich, advised by Marc Pollefeys
- Pfister Severin (2021): MSc student at ETH Zurich
- Master thesis: Online Implicit Reconstruction
- → Consultant at McKinsey & Company
- Weirong Chen (2020): MSc student at ETH Zurich
- Semester thesis: Real-time 3D Reconstruction through Neural Implicit Representation
- → PhD student at TU Munich, advised by Daniel Cremers and Andrea Vedaldi
Invited Talks















Teaching
| Teaching Assistant (Lead), 3D Vision, Spring 2023 Teaching Assistant, Computer Vision, Fall 2022 Teaching Assistant (Lead), 3D Vision, Spring 2022 Teaching Assistant, Deep Learning for Computer Vision: Seminal Work, Spring 2022 Teaching Assistant, 3D Vision, Spring 2020 Teaching Assistant, Deep Learning for Computer Vision: Seminal Work, Spring 2020 |
|---|
Academic Services
- Publicity Chair: 3DV'25
- Area Chair: NeurIPS'26, ECCV'26, CVPR'26, ICLR'26, ICCV'25, ICML'25, 3DV'24
- Workshop Organizer:
- Conference Reviewer: CVPR, ICCV, ECCV, ICLR, NeurIPS, SIGGRAPH, SIGGRAPH Asia
- Journal Reviewer: TPAMI, IJCV, CVIU