Failover Mechanisms in System Design (original) (raw)
Last Updated : 30 Mar, 2026
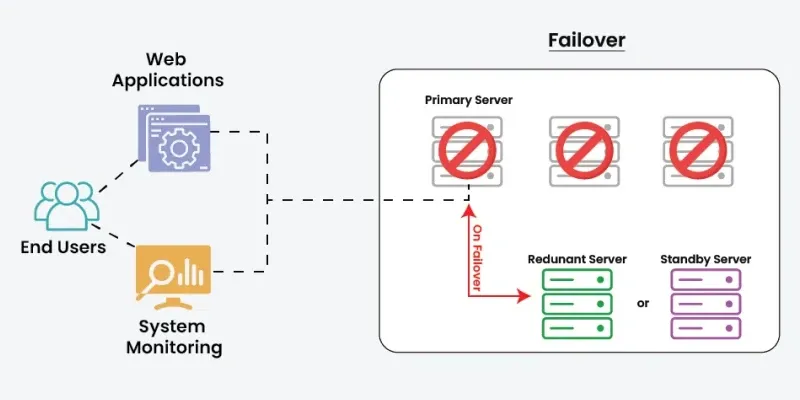
A failover mechanism is a system design approach that ensures continuous availability when a component fails. It automatically shifts operations from a failed or degraded component to a standby or redundant one, minimizing downtime and service disruption.
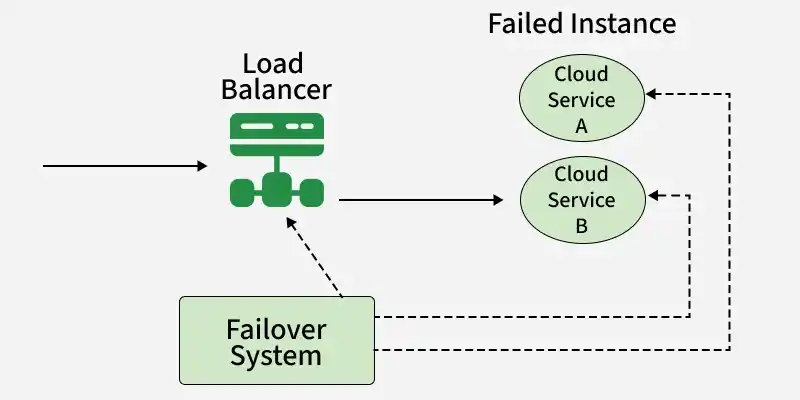
Failover mechanism
- Maintains uninterrupted service by switching to backup components during failures.
- Reduces system downtime and improves overall reliability.
- Commonly used with redundant servers, databases, or network components.
Triggers Failover
This section highlights the common conditions that can trigger a failover in a system.
Various events or circumstances may cause a failover, depending on the system's particular architecture and design. The following are a few typical failover triggers:
- **Hardware Failure: When a server, storage drive, network switch, or other piece of hardware malfunctions or stops working, failover can be set off. These malfunctions can be identified by monitoring systems, which can then start failover processes to transition to redundant hardware.
- **Software Failure: Errors, crashes, or other problems with software that make a part or service unavailable can cause failover. These malfunctions can be identified by monitoring tools or health checks, which can then start the failover to redundant software instances or components.
- **Network Outages: When a component or service cannot communicate with another due to network outages or connectivity problems, failover may be activated. To ensure connectivity and initiate failover, one can make use of redundant network paths or alternative communication channels.
- **Performance Degradation: When performance parameters, including throughput or response times, drop below acceptable limits, failover methods could be activated. In times of peak usage or resource restrictions, this proactive approach aids in maintaining service levels and preventing service degradation.
- **Load balancer health checks: The outcomes of health checks carried out by load balancers or other traffic management devices may trigger a failover. The load balancer can reroute traffic to healthy instances in the event that a backend server or service fails health checks.
- **Manual Intervention: System administrators or operators may occasionally manually initiate failover in response to scheduled maintenance tasks, security issues, or other operational requirements.
- **Configuration Changes: Modifications to the system configuration, such as the addition or removal of servers, alteration of routing rules, or altering failover policies, may cause the failover mechanisms to activate.
Types
Various types of failover exist, depending on the degree of redundancy offered and the manner in which it is implemented. Here are a few typical failover types:
**1. Failover to Cold Standby
A standby system or component is available but not actively operating in this kind of failover. Compared to other forms of failover, standby systems usually need more downtime because they must be initiated and brought online in the event of a failure.
**2. Cozy Standby Failure Mode
In the event of a failure, a warm standby system is prepared to take over, operating partially. Even though the standby system might not be handling live traffic, it is typically partially configured and has a short downtime when brought online.
**3. Warm Standby Failure-Over
Keeping a fully functional, synchronized backup system up to date so it can take over right away in the event that the primary system fails is known as hot standby failover. The quickest recovery time with the least amount of service disruption is offered by this kind of failover.
**4. Active-Passive Switching
Just one system or component is active at a time in an active-passive failover configuration, with the others operating in standby mode. The passive system kicks in when the active system malfunctions. High availability clustering and database mirroring frequently use this configuration.
**5. Dynamic-Active Switchover
Both the primary and standby systems are concurrently processing traffic and fulfilling requests in an active-active failover arrangement. The burden is automatically reassigned to the surviving operational systems in the event that one system fails. This configuration is frequently used to increase load balancing and scalability.
Importance of Failover Mechanisms in System Design
A crucial component of system design is failover, particularly in settings where dependability and uptime are crucial. Failure over is crucial for the following reasons:
- **High Availability: In the event that a system or component fails, failover makes sure that services continue to be offered. This is essential for systems like banking systems, emergency services, and e-commerce platforms that must be available around-the-clock.
- **Redundancy: In the event of a breakdown, failover systems offer redundancy by having backup parts or resources prepared to take over. The possibility that a single point of failure will bring down the entire system is reduced by this redundancy.
- **Fault Tolerance: By automatically identifying faults and rerouting workload or traffic to healthy components, failover techniques enhance fault tolerance. This lessens the effect that malfunctions have on the system as a whole.
- **Disaster Recovery: A crucial part of any strategy for disaster recovery is failover. Failure over techniques aid in the prompt restoration of services and reduction of downtime in the event of a disaster, such as a hardware malfunction, network outage, or natural disaster.
- **Business Continuity: By reducing downtime and guaranteeing the continued availability of vital services, failover assures business continuity. This is especially crucial for companies whose operations significantly depend on their IT infrastructure.
- **Customer Satisfaction: Higher customer satisfaction is a result of dependable services. By preserving service dependability and availability, failover techniques make sure that users may continue to access the services they require.
Failover Architecture
The deliberate construction of a system to guarantee continuous service availability in the event of failures is known as failover architecture. To quickly identify and address problems, it entails putting in place redundancy, automated failover methods, and proactive monitoring. Redundant hardware, including networking gear and servers, as well as failover techniques like load balancing and clustering, are essential elements.
- To avoid data loss, data replication makes sure that important data is synchronized across several sites. By placing redundant systems in different areas, geographic redundancy improves resilience even more.
- The process is streamlined by automated failover orchestration, and scalability guarantees that the system can adjust to fluctuating demands.
- Frequent testing and validation guarantee that the design is ready for real-world failures and help confirm its efficacy.
- In general, the goals of failover architecture are to reduce downtime, reduce risks,preserve end consumers' access to dependable services.
**Failover Mechanisms in Different Systems
Failover mechanisms are essential components of various systems across different domains, ensuring resilience and continuity of operations in the face of component failures or disruptions.
**1. Network Infrastructure:
- In network infrastructure, failover mechanisms are employed to maintain connectivity and routing functionality in the event of link failures or router outages.
- Routing protocols like OSPF (Open Shortest Path First) and BGP (Border Gateway Protocol) utilize failover mechanisms to dynamically reroute traffic around failed links or routers.
- Failover mechanisms automatically switch traffic to standby devices when primary devices fail.
**2. Database Systems:
- In database systems, failover mechanisms ensure continuous availability of data and uninterrupted access to critical services.
- Database clustering technologies like MySQL Cluster and Oracle RAC (Real Application Clusters) provide failover capabilities by synchronizing data across multiple nodes and automatically failing over to standby nodes in case of primary node failure.
- Replication mechanisms, such as master-slave replication and synchronous replication, replicate data changes to standby nodes in real-time, enabling fast failover with minimal data loss.
**3. Cloud Computing Platforms:
- Cloud computing platforms implement failover mechanisms to maintain uptime and availability of virtualized resources and services.
- Hypervisor-based failover mechanisms, such as VMware HA (High Availability) and Microsoft Hyper-V Replica, automatically restart virtual machines on healthy hosts in case of host failures.
- Load balancers and DNS-based failover solutions distribute incoming traffic across multiple servers or data centers and redirect traffic to healthy instances during failures or performance degradation.
**4. Web Applications:
- Web applications leverage failover mechanisms to ensure uninterrupted access and responsiveness for users.
- Content Delivery Networks (CDNs) use global server load balancing (GSLB) and DNS failover to direct user requests to the nearest and healthiest servers, minimizing latency and downtime.
- Application-level failover mechanisms, such as session replication and stateless application design, enable seamless failover between redundant application servers without interrupting user sessions or transactions.
**5. Telecommunication Systems:
- Telecommunication systems rely on failover mechanisms to maintain call routing, messaging services, and network availability.
- Redundant switches, routers, and signaling gateways are configured with protocols like VRRP (Virtual Router Redundancy Protocol) and SIP (Session Initiation Protocol) to automatically reroute traffic and handle signaling traffic in case of equipment failures.
Load balancers and session border controllers (SBCs) distribute voice and data traffic across redundant paths and failover to alternate paths during failures or congestion.
Best Practices for Failover Mechanisms Design
It is necessary to carefully evaluate a number of elements while designing an efficient failover solution. Observe the following recommended practices:
- **Determine Which Systems Are Critical: List the systems that are most important to the functioning of your company and rank them in order of importance for failover deployment.
- **Define Recovery Objectives: For every important system, clearly define the recovery time objectives (RTO) and recovery point objectives (RPO). Your failover architecture will be guided by these KPIs, which also assist set expectations for data loss and downtime.
- **Put **Redundancy Into Practice: Add redundancy to your hardware, networking, storage, and power supply systems, among other areas. Redundant parts contribute to fault tolerance and high availability.
- Employ **Load Balancers: To disperse incoming traffic among several servers or instances in an equitable manner, utilize load balancers. By automatically identifying problems and rerouting traffic to reliable resources, load balancers can increase system reliability as a whole.
- **Automate Failover Procedures: To cut down on manual involvement and speed up recovery, automate as many failover procedures as you can. To find errors, start failover processes, and carry out post-failover validation, use tools and scripts.
- **Maintain System Health: To keep an eye on the functionality and general health of important components, put in place reliable alerting and monitoring mechanisms. proactively identify problems and malfunctions before they affect the provision of services.
Challenges in Implementing Failover Mechanisms
- **Complexity: Because failover systems can be complex, coordination between multiple teams and technologies is necessary.
- **Cost: Adding failover and redundancy methods frequently results in higher infrastructure, software, and hardware costs.
- **Compatibility: It can be difficult to integrate failover solutions with current applications and infrastructure.
- **Testing and Validation: It can be difficult and resource-intensive to carry out thorough testing and validation of failover systems.
- **Staff Training: It might be difficult to make sure employees are properly prepared to handle failover processes, particularly in companies with little funding.
- **Maintenance and Updates: In order to keep failover systems functioning properly, regular maintenance and updates must be carried out without interfering with service.
- **Security: Data protection and secure communication are two new security issues brought about by failover methods that need to be taken into account.
Examples Failover Mechanisms
A wide range of sectors and technologies have real-world instances of failover systems. Here are a few instances:
**1. Google Cloud Platform (GCP) Regional Failover:
Google Cloud Platform enables users to distribute resources over various geographical areas by providing regional failover for its services. GCP automatically reroutes traffic to reliable resources in other regions in the case of a regional failure or outage, guaranteeing high availability.
**2. Netflix Chaos Monkey:
One tool that Netflix uses in their Chaos Engineering process is called Chaos Monkey. In production scenarios, Chaos Monkey randomly ends virtual machine instances to mimic failures and assess how resilient their systems are. In order to maintain continuous service for its streaming platform, this aids Netflix in identifying flaws and strengthening its failover methods.
**3. Elastic Load Balancer (ELB) on Amazon Web Services (AWS):
Incoming traffic is automatically split up among several Availability Zones or EC2 instances by Amazon Elastic Load Balancer. Apps hosted on AWS are guaranteed to be continuously available and reliable even in the event of an instance or zone failure, thanks to ELB's ability to reroute traffic to healthy instances or zones.
**4. Global Load Balancer (GSLB) on Facebook:
Global Load Balancers (GSLBs) are used by Facebook to disperse user traffic among its global data centers. To guarantee the best possible user experience and uptime, the GSLB constantly checks the health and performance of data centers and reroutes traffic away from underperforming or unavailable data centers.