TF-NumPy Type Promotion (original) (raw)
Overview
There are 4 options for type promotion in TensorFlow.
- By default, TensorFlow raises errors instead of promoting types for mixed type operations.
- Running
tf.numpy.experimental_enable_numpy_behavior()switches TensorFlow to use NumPy type promotion rules. - This doc describes two new options that will be available in TensorFlow 2.15 (or currently in
tf-nightly):
pip install -q tf_nightlySetup
import numpy as np
import tensorflow as tf
import tensorflow.experimental.numpy as tnp
print("Using TensorFlow version %s" % tf.__version__)
Using TensorFlow version 2.20.0-dev20250306
Enabling the new type promotion
In order to use the JAX-like type promotion in TF-Numpy, specify either 'all' or 'safe' as the dtype conversion mode when enabling NumPy behavior for TensorFlow.
This new system (with dtype_conversion_mode="all") is associative, commutative, and makes it easy to control what width of float you end up with (it doesn't automatically convert to wider floats). It does introduce some risks of overflows and precision loss, but dtype_conversion_mode="safe" forces you to handle those cases explicitly. The two modes are explained more in detail in the next section.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet.
Two Modes : ALL mode vs SAFE mode
In the new type promotion system, we introduce two modes: ALL mode and SAFE mode. SAFE mode is used to mitigate the concerns of "risky" promotions that can result in precision loss or bit-widening.
Dtypes
We will be using the following abbreviations for brevity.
bmeans tf.boolu8means tf.uint8i16means tf.int16i32means tf.int32bf16means tf.bfloat16f32means tf.float32f64means tf.float64i32*means Pythonintor weakly-typedi32f32*means Pythonfloator weakly-typedf32c128*means Pythoncomplexor weakly-typedc128
The asterisk (*) denotes that the corresponding type is “weak” - such a dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is explained more in detail here.
Example of precision losing operations
In the following example, i32 + f32 is allowed in ALL mode but not in SAFE mode due to the risk of precision loss.
# i32 + f32 returns a f32 result in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, dtype = tf.int32)
b = tf.constant(5.0, dtype = tf.float32)
a + b # <tf.Tensor: shape=(), dtype=float32, numpy=15.0>
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. WARNING: All log messages before absl::InitializeLog() is called are written to STDERR I0000 00:00:1741314679.354086 16587 gpu_device.cc:2018] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 13638 MB memory: -> device: 0, name: Tesla T4, pci bus id: 0000:00:05.0, compute capability: 7.5 I0000 00:00:1741314679.356319 16587 gpu_device.cc:2018] Created device /job:localhost/replica:0/task:0/device:GPU:1 with 13756 MB memory: -> device: 1, name: Tesla T4, pci bus id: 0000:00:06.0, compute capability: 7.5 I0000 00:00:1741314679.358627 16587 gpu_device.cc:2018] Created device /job:localhost/replica:0/task:0/device:GPU:2 with 13756 MB memory: -> device: 2, name: Tesla T4, pci bus id: 0000:00:07.0, compute capability: 7.5 I0000 00:00:1741314679.360752 16587 gpu_device.cc:2018] Created device /job:localhost/replica:0/task:0/device:GPU:3 with 13756 MB memory: -> device: 3, name: Tesla T4, pci bus id: 0000:00:08.0, compute capability: 7.5 <tf.Tensor: shape=(), dtype=float32, numpy=15.0>
# This promotion is not allowed in SAFE mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="safe")
a = tf.constant(10, dtype = tf.int32)
b = tf.constant(5.0, dtype = tf.float32)
try:
a + b
except TypeError as e:
print(f'{type(e)}: {e}') # TypeError: explicitly specify the dtype or switch to ALL mode.
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <class 'TypeError'>: In promotion mode PromoMode.SAFE, implicit dtype promotion between (<dtype: 'int32'>, weak=False) and (<dtype: 'float32'>, weak=False) is disallowed. You need to explicitly specify the dtype in your op, or relax your dtype promotion rules (such as from SAFE mode to ALL mode).
Example of bit-widening operations
In the following example, i8 + u32 is allowed in ALL mode but not in SAFE mode due to bit-widening, which means using more bits than the number of bits in the inputs. Note that the new type promotion semantics only allows necessary bit-widening.
# i8 + u32 returns an i64 result in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, dtype = tf.int8)
b = tf.constant(5, dtype = tf.uint32)
a + b
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <tf.Tensor: shape=(), dtype=int64, numpy=15>
# This promotion is not allowed in SAFE mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="safe")
a = tf.constant(10, dtype = tf.int8)
b = tf.constant(5, dtype = tf.uint32)
try:
a + b
except TypeError as e:
print(f'{type(e)}: {e}') # TypeError: explicitly specify the dtype or switch to ALL mode.
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <class 'TypeError'>: In promotion mode PromoMode.SAFE, implicit dtype promotion between (<dtype: 'int8'>, weak=False) and (<dtype: 'uint32'>, weak=False) is disallowed. You need to explicitly specify the dtype in your op, or relax your dtype promotion rules (such as from SAFE mode to ALL mode).
A System Based on a Lattice
Type Promotion Lattice
The new type promotion behavior is determined via the following type promotion lattice:
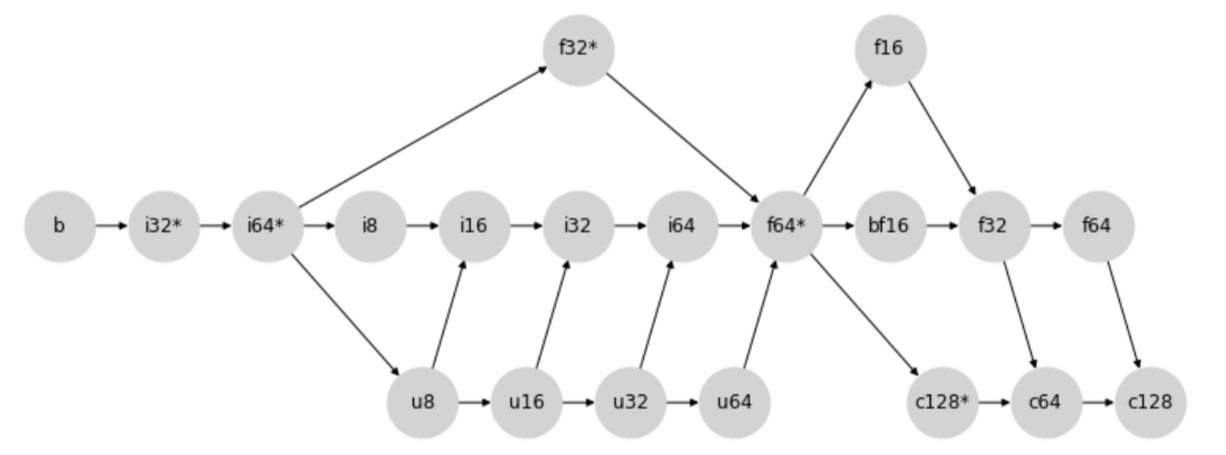
More specifically, promotion between any two types is determined by finding the first common child of the two nodes (including the nodes themselves).
For example, in the diagram above, the first common child of i8 and i32 is i32 because the two nodes intersect for the first time at i32 when following the direction of the arrows.
Similarly as another example, the result promotion type between u64 and f16 would be f16.
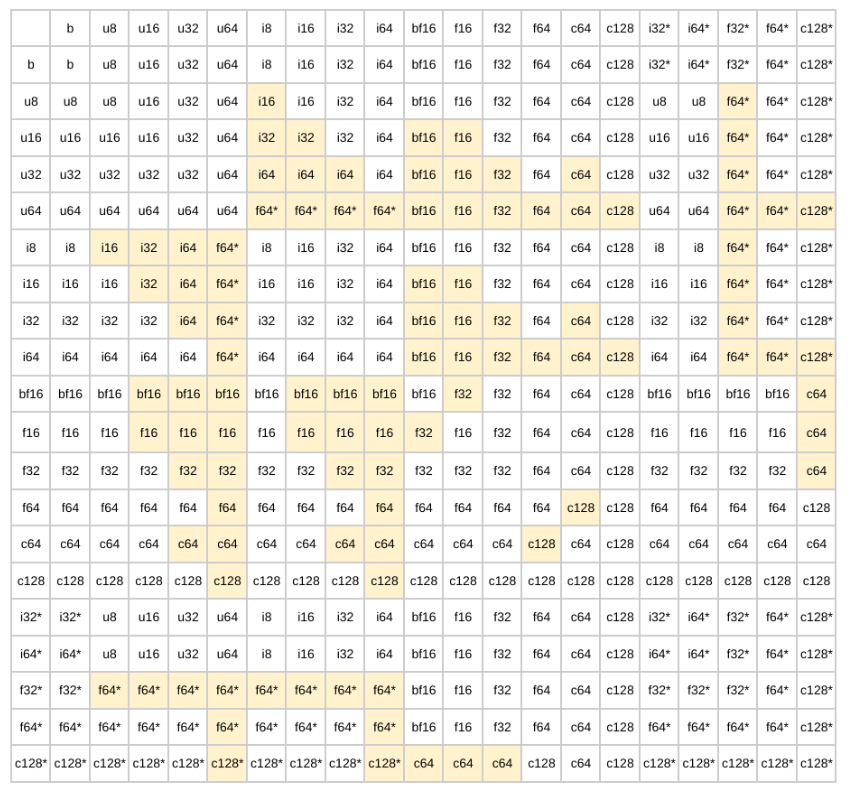
Type Promotion Table
Following the lattice generates the binary promotion table below:
We adopt a JAX-like lattice-based system for our new type promotion, which offers the following advantages:
Advantages of Lattice-Based System
First, using a lattice-based system ensures three very important properties:
- Existence: There is a unique result promotion type for any combinations of types.
- Commutativity:
a + b = b + a - Associativity:
a + (b + c) = (a + b) = c
These three properties are critical for constructing a type promotion semantics that is consistent and predictable.
Advantages of JAX-like Lattice System
Another crucial advantage of the JAX-like lattice system is that outside unsigned ints, it avoids all wider-than-necessary promotions. This means you cannot get 64-bit results without 64-bit inputs. This is especially beneficial for working on accelerators as it avoids unnecessary 64-bit values, which was frequent in the old type promotion.
However, this comes with a trade-off: mixed float/integer promotion is very prone to precision loss. For instance, in the example below, i64 + f16 results in promoting i64 to f16.
# The first input is promoted to f16 in ALL mode.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
tf.constant(1, tf.int64) + tf.constant(3.2, tf.float16) # <tf.Tensor: shape=(), dtype=float16, numpy=4.2>
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <tf.Tensor: shape=(), dtype=float16, numpy=4.19921875>
To migitage this concern, we introduced a SAFE mode that will disallow these "risky" promotions.
WeakTensor
Overview
Weak tensors are Tensors that are "weakly typed", similar to a concept in JAX.
WeakTensor's dtype is temporarily inferred by the system, and could defer to other dtypes. This concept is introduced in the new type promotion to prevent unwanted type promotion within binary operations between TF values and values with no explicitly user-specified type, such as Python scalar literals.
For instance, in the example below, tf.constant(1.2) is considered "weak" because it doesn't have a specific dtype. Therefore, tf.constant(1.2) defers to the type of tf.constant(3.1, tf.float16), resulting in a f16 output.
tf.constant(1.2) + tf.constant(3.1, tf.float16) # <tf.Tensor: shape=(), dtype=float16, numpy=4.3>
<tf.Tensor: shape=(), dtype=float16, numpy=4.30078125>
WeakTensor Construction
WeakTensors are created if you create a tensor without specifying a dtype the result is a WeakTensor. You can check whether a Tensor is "weak" or not by checking the weak attribute at the end of the Tensor's string representation.
First Case: When tf.constant is called with an input with no user-specified dtype.
tf.constant(5) # <tf.Tensor: shape=(), dtype=int32, numpy=5, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=5, weak=True>
tf.constant([5.0, 10.0, 3]) # <tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 5., 10., 3.], dtype=float32), weak=True>
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([ 5., 10., 3.], dtype=float32), weak=True>
# A normal Tensor is created when dtype arg is specified.
tf.constant(5, tf.int32) # <tf.Tensor: shape=(), dtype=int32, numpy=5>
<tf.Tensor: shape=(), dtype=int32, numpy=5>
Second Case: When an input with no user-specified dtype is passed into a WeakTensor-supporting API.
tf.math.abs([100.0, 4.0]) # <tf.Tensor: shape=(2,), dtype=float32, numpy=array([100., 4.], dtype=float32), weak=True>
<tf.Tensor: shape=(2,), dtype=float32, numpy=array([100., 4.], dtype=float32), weak=True>
Below is a non-exhaustive list of changes that result from turning on the new type promotion.
- More consistent and predictable promotion results.
- Reduced risk of bit-widening.
- tf.Tensor mathematical dunder methods use new type promotion.
- tf.constant can return
WeakTensor. - tf.constant allows implicit conversions when a Tensor input with a dtype different from the
dtypearg is passed in. - tf.Variable in-place ops (
assign,assign-add,assign-sub) allow implicit conversions. tnp.array(1)andtnp.array(1.0)returns 32-bit WeakTensor.WeakTensors will be created and used for WeakTensor-supporting unary and binary API's.
More consistent and predictable promotion results
Using a lattice-based system allows the new type promotion to produce consistent and predictable type promotion results.
Old Type Promotion
Changing the order of operations produces inconsistent results using old type promotion.
# Setup
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="legacy")
a = np.array(1, dtype=np.int8)
b = tf.constant(1)
c = np.array(1, dtype=np.float16)
# (a + b) + c throws an InvalidArgumentError.
try:
tf.add(tf.add(a, b), c)
except tf.errors.InvalidArgumentError as e:
print(f'{type(e)}: {e}') # InvalidArgumentError
<class 'tensorflow.python.framework.errors_impl.InvalidArgumentError'>: cannot compute AddV2 as input #1(zero-based) was expected to be a int8 tensor but is a int32 tensor [Op:AddV2] name:
# (b + a) + c returns an i32 result.
tf.add(tf.add(b, a), c) # <tf.Tensor: shape=(), dtype=int32, numpy=3>
<tf.Tensor: shape=(), dtype=int32, numpy=3>
New Type Promotion
New type promotion produces consistent results regardless of the order.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = np.array(1, dtype=np.int8)
b = tf.constant(1)
c = np.array(1, dtype=np.float16)
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet.
# (a + b) + c returns a f16 result.
tf.add(tf.add(a, b), c) # <tf.Tensor: shape=(), dtype=float16, numpy=3.0>
<tf.Tensor: shape=(), dtype=float16, numpy=3.0>
# (b + a) + c also returns a f16 result.
tf.add(tf.add(b, a), c) # <tf.Tensor: shape=(), dtype=float16, numpy=3.0>
<tf.Tensor: shape=(), dtype=float16, numpy=3.0>
Reduced risk of bit-widening
Old Type Promotion
Old type promotion often resulted in 64-bit results.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="legacy")
np.array(3.2, np.float16) + tf.constant(1, tf.int8) + tf.constant(50) # <tf.Tensor: shape=(), dtype=float64, numpy=54.19921875>
<tf.Tensor: shape=(), dtype=float64, numpy=54.19921875>
New Type Promotion
New type promotion returns results with minimal number of bits necessary.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet.
np.array(3.2, np.float16) + tf.constant(1, tf.int8) + tf.constant(50) # <tf.Tensor: shape=(), dtype=float16, numpy=54.2>
<tf.Tensor: shape=(), dtype=float16, numpy=54.1875>
tf.Tensor mathematical dunder methods
All tf.Tensor mathematical dunder methods will follow the new type promotion.
-tf.constant(5) # <tf.Tensor: shape=(), dtype=int32, numpy=-5, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=-5, weak=True>
tf.constant(5, tf.int16) - tf.constant(1, tf.float32) # <tf.Tensor: shape=(), dtype=float32, numpy=4.0>
<tf.Tensor: shape=(), dtype=float32, numpy=4.0>
tf.Variable in-place ops
Implicit conversions will be allowed in tf.Variable in-place ops.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.Variable(10, tf.int32)
a.assign_add(tf.constant(5, tf.int16)) # <tf.Variable shape=() dtype=int32, numpy=15>
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <tf.Variable 'UnreadVariable' shape=() dtype=int32, numpy=15>
tf.constant implicit conversions
In the old type promotion, tf.constant required an input Tensor to have the same dtype as the dtype argument. However, in the new type promotion, we implicitly convert Tensor to the specified dtype.
tnp.experimental_enable_numpy_behavior(dtype_conversion_mode="all")
a = tf.constant(10, tf.int16)
tf.constant(a, tf.float32) # <tf.Tensor: shape=(), dtype=float32, numpy=10.0>
WARNING:tensorflow:UserWarning: enabling the new type promotion must happen at the beginning of the program. Please ensure no TF APIs have been used yet. <tf.Tensor: shape=(), dtype=float32, numpy=10.0>
TF-NumPy Array
tnp.array defaults to i32* and f32* for python inputs using the new type promotion.
tnp.array(1) # <tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
<tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
tnp.array(1.0) # <tf.Tensor: shape=(), dtype=int32, numpy=1, weak=True>
<tf.Tensor: shape=(), dtype=float32, numpy=1.0, weak=True>
Input Type Inference
This is how different inputs' types are inferred in the new type promotion.
- tf.Tensor: Since tf.Tensor has a dtype property, we don't do further inference.
- NumPy types: This includes types like
np.array(1),np.int16(1), andnp.float. Since NumPy inputs also have a dtype property, we take the dtype property as the result inference type. Note that NumPy defaults toi64andf64. - Python scalars/Nested types: This includes types like
1,[1, 2, 3], and(1.0, 2.0).- Python
intis inferred asi32*. - Python
floatis inferred asf32*. - Python
complexis inferred asc128*.
- Python
- If the input doesn't fall into any of the above categories but has a dtype property, we take the dtype property as the result inference type.
Further Reading
The new type promotion closely resembles JAX-NumPy's type promotion. If you want to know more details about the new type promotion and the design choices, check out the resources below.
- JAX Type Promotion Semantics
- Design of Type Promotion Semantics for JAX
- Old TF-NumPy Promotion Semantics
References
WeakTensor-supporting APIs
Below is a list of APIs that supports WeakTensor.
For an unary op, this means that if an input with no user-specified type is passed in, it will return a WeakTensor.
For a binary op, it will follow the promotion table here. It may or may not return a WeakTensor depending on the promotion result of the two inputs.
- tf.bitwise.invert
- tf.clip_by_value
- tf.debugging.check_numerics
- tf.expand_dims
- tf.identity
- tf.image.adjust_brightness
- tf.image.adjust_gamma
- tf.image.extract_patches
- tf.image.random_brightness
- tf.image.stateless_random_brightness
- tf.linalg.diag
- tf.linalg.diag_part
- tf.linalg.matmul
- tf.linalg.matrix_transpose
- tf.linalg.tensor_diag_part
- tf.linalg.trace
- tf.math.abs
- tf.math.acos
- tf.math.acosh
- tf.math.add
- tf.math.angle
- tf.math.asin
- tf.math.asinh
- tf.math.atan
- tf.math.atanh
- tf.math.ceil
- tf.math.conj
- tf.math.cos
- tf.math.cosh
- tf.math.digamma
- tf.math.divide_no_nan
- tf.math.divide
- tf.math.erf
- tf.math.erfc
- tf.math.erfcinv
- tf.math.erfinv
- tf.math.exp
- tf.math.expm1
- tf.math.floor
- tf.math.floordiv
- tf.math.floormod
- tf.math.imag
- tf.math.lgamma
- tf.math.log1p
- tf.math.log_sigmoid
- tf.math.log
- tf.math.multiply_no_nan
- tf.math.multiply
- tf.math.ndtri
- tf.math.negative
- tf.math.pow
- tf.math.real
- tf.math.real
- tf.math.reciprocal_no_nan
- tf.math.reciprocal
- tf.math.reduce_euclidean_norm
- tf.math.reduce_logsumexp
- tf.math.reduce_max
- tf.math.reduce_mean
- tf.math.reduce_min
- tf.math.reduce_prod
- tf.math.reduce_std
- tf.math.reduce_sum
- tf.math.reduce_variance
- tf.math.rint
- tf.math.round
- tf.math.rsqrt
- tf.math.scalar_mul
- tf.math.sigmoid
- tf.math.sign
- tf.math.sin
- tf.math.sinh
- tf.math.softplus
- tf.math.special.bessel_i0
- tf.math.special.bessel_i0e
- tf.math.special.bessel_i1
- tf.math.special.bessel_i1e
- tf.math.special.bessel_j0
- tf.math.special.bessel_j1
- tf.math.special.bessel_k0
- tf.math.special.bessel_k0e
- tf.math.special.bessel_k1
- tf.math.special.bessel_k1e
- tf.math.special.bessel_y0
- tf.math.special.bessel_y1
- tf.math.special.dawsn
- tf.math.special.expint
- tf.math.special.fresnel_cos
- tf.math.special.fresnel_sin
- tf.math.special.spence
- tf.math.sqrt
- tf.math.square
- tf.math.subtract
- tf.math.tan
- tf.math.tanh
- tf.nn.depth_to_space
- tf.nn.elu
- tf.nn.gelu
- tf.nn.leaky_relu
- tf.nn.log_softmax
- tf.nn.relu6
- tf.nn.relu
- tf.nn.selu
- tf.nn.softsign
- tf.nn.space_to_depth
- tf.nn.swish
- tf.ones_like
- tf.realdiv
- tf.reshape
- tf.squeeze
- tf.stop_gradient
- tf.transpose
- tf.truncatediv
- tf.truncatemod
- tf.zeros_like
- tf.experimental.numpy.abs
- tf.experimental.numpy.absolute
- tf.experimental.numpy.amax
- tf.experimental.numpy.amin
- tf.experimental.numpy.angle
- tf.experimental.numpy.arange
- tf.experimental.numpy.arccos
- tf.experimental.numpy.arccosh
- tf.experimental.numpy.arcsin
- tf.experimental.numpy.arcsinh
- tf.experimental.numpy.arctan
- tf.experimental.numpy.arctanh
- tf.experimental.numpy.around
- tf.experimental.numpy.array
- tf.experimental.numpy.asanyarray
- tf.experimental.numpy.asarray
- tf.experimental.numpy.ascontiguousarray
- tf.experimental.numpy.average
- tf.experimental.numpy.bitwise_not
- tf.experimental.numpy.cbrt
- tf.experimental.numpy.ceil
- tf.experimental.numpy.conj
- tf.experimental.numpy.conjugate
- tf.experimental.numpy.copy
- tf.experimental.numpy.cos
- tf.experimental.numpy.cosh
- tf.experimental.numpy.cumprod
- tf.experimental.numpy.cumsum
- tf.experimental.numpy.deg2rad
- tf.experimental.numpy.diag
- tf.experimental.numpy.diagflat
- tf.experimental.numpy.diagonal
- tf.experimental.numpy.diff
- tf.experimental.numpy.empty_like
- tf.experimental.numpy.exp2
- tf.experimental.numpy.exp
- tf.experimental.numpy.expand_dims
- tf.experimental.numpy.expm1
- tf.experimental.numpy.fabs
- tf.experimental.numpy.fix
- tf.experimental.numpy.flatten
- tf.experimental.numpy.flip
- tf.experimental.numpy.fliplr
- tf.experimental.numpy.flipud
- tf.experimental.numpy.floor
- tf.experimental.numpy.full_like
- tf.experimental.numpy.imag
- tf.experimental.numpy.log10
- tf.experimental.numpy.log1p
- tf.experimental.numpy.log2
- tf.experimental.numpy.log
- tf.experimental.numpy.max
- tf.experimental.numpy.mean
- tf.experimental.numpy.min
- tf.experimental.numpy.moveaxis
- tf.experimental.numpy.nanmean
- tf.experimental.numpy.negative
- tf.experimental.numpy.ones_like
- tf.experimental.numpy.positive
- tf.experimental.numpy.prod
- tf.experimental.numpy.rad2deg
- tf.experimental.numpy.ravel
- tf.experimental.numpy.real
- tf.experimental.numpy.reciprocal
- tf.experimental.numpy.repeat
- tf.experimental.numpy.reshape
- tf.experimental.numpy.rot90
- tf.experimental.numpy.round
- tf.experimental.numpy.signbit
- tf.experimental.numpy.sin
- tf.experimental.numpy.sinc
- tf.experimental.numpy.sinh
- tf.experimental.numpy.sort
- tf.experimental.numpy.sqrt
- tf.experimental.numpy.square
- tf.experimental.numpy.squeeze
- tf.experimental.numpy.std
- tf.experimental.numpy.sum
- tf.experimental.numpy.swapaxes
- tf.experimental.numpy.tan
- tf.experimental.numpy.tanh
- tf.experimental.numpy.trace
- tf.experimental.numpy.transpose
- tf.experimental.numpy.triu
- tf.experimental.numpy.vander
- tf.experimental.numpy.var
- tf.experimental.numpy.zeros_like