ClassificationPartitionedLinearECOC.kfoldMargin - Classification margins for observations not used in training - MATLAB (original) (raw)
Classification margins for observations not used in training
Syntax
Description
[m](#bu6uj%5Fb-1-m) = kfoldMargin([CVMdl](#bu6uj%5Fb-1%5Fsep%5Fshared-CVMdl)) returns the cross-validated classification margins obtained by CVMdl, which is a cross-validated, error-correcting output codes (ECOC) model composed of linear classification models. That is, for every fold, kfoldMargin estimates the classification margins for observations that it holds out when it trains using all other observations.
m contains classification margins for each regularization strength in the linear classification models that comprise CVMdl.
[m](#bu6uj%5Fb-1-m) = kfoldMargin([CVMdl](#bu6uj%5Fb-1%5Fsep%5Fshared-CVMdl),[Name,Value](#namevaluepairarguments)) uses additional options specified by one or more Name,Value pair arguments. For example, specify a decoding scheme or verbosity level.
Input Arguments
Name-Value Arguments
Specify optional pairs of arguments asName1=Value1,...,NameN=ValueN, where Name is the argument name and Value is the corresponding value. Name-value arguments must appear after other arguments, but the order of the pairs does not matter.
Before R2021a, use commas to separate each name and value, and enclose Name in quotes.
Data Types: char | string | function_handle
Data Types: single | double
Output Arguments
Cross-validated classification margins, returned as a numeric vector or matrix.
m is _n_-by-L, where n is the number of observations in X and L is the number of regularization strengths in Mdl (that is, numel(Mdl.Lambda)).
m(_`i`_,_`j`_) is the cross-validated classification margin of observation i using the ECOC model, composed of linear classification models, that has regularization strength Mdl.Lambda(_`j`_).
Examples
Load the NLP data set.
X is a sparse matrix of predictor data, and Y is a categorical vector of class labels.
For simplicity, use the label 'others' for all observations in Y that are not 'simulink', 'dsp', or 'comm'.
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';
Cross-validate a multiclass, linear classification model.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learner','linear','CrossVal','on');
CVMdl is a ClassificationPartitionedLinearECOC model. By default, the software implements 10-fold cross validation. You can alter the number of folds using the 'KFold' name-value pair argument.
Estimate the _k_-fold margins.
m = kfoldMargin(CVMdl); size(m)
m is a 31572-by-1 vector. m(j) is the average of the out-of-fold margins for observation j.
Plot the _k_-fold margins using box plots.
figure; boxplot(m); h = gca; h.YLim = [-5 5]; title('Distribution of Cross-Validated Margins')
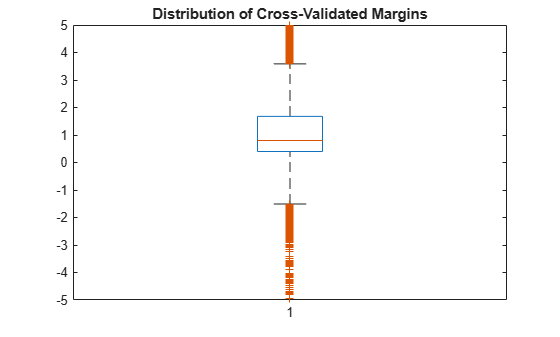
One way to perform feature selection is to compare _k_-fold margins from multiple models. Based solely on this criterion, the classifier with the larger margins is the better classifier.
Load the NLP data set. Preprocess the data as in Estimate k-Fold Cross-Validation Margins, and orient the predictor data so that observations correspond to columns.
load nlpdata Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others'; X = X';
Create these two data sets:
fullXcontains all predictors.partXcontains 1/2 of the predictors chosen at random.
rng(1); % For reproducibility p = size(X,1); % Number of predictors halfPredIdx = randsample(p,ceil(0.5*p)); fullX = X; partX = X(halfPredIdx,:);
Create a linear classification model template that specifies optimizing the objective function using SpaRSA.
t = templateLinear('Solver','sparsa');
Cross-validate two ECOC models composed of binary, linear classification models: one that uses the all of the predictors and one that uses half of the predictors. Indicate that observations correspond to columns.
CVMdl = fitcecoc(fullX,Y,'Learners',t,'CrossVal','on',... 'ObservationsIn','columns'); PCVMdl = fitcecoc(partX,Y,'Learners',t,'CrossVal','on',... 'ObservationsIn','columns');
CVMdl and PCVMdl are ClassificationPartitionedLinearECOC models.
Estimate the _k_-fold margins for each classifier. Plot the distribution of the _k_-fold margins sets using box plots.
fullMargins = kfoldMargin(CVMdl); partMargins = kfoldMargin(PCVMdl);
figure; boxplot([fullMargins partMargins],'Labels',... {'All Predictors','Half of the Predictors'}); h = gca; h.YLim = [-1 1]; title('Distribution of Cross-Validated Margins')
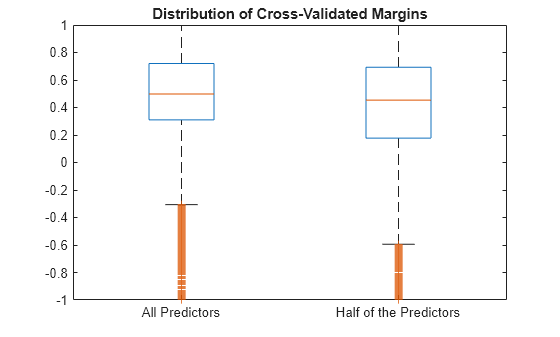
The distributions of the _k_-fold margins of the two classifiers are similar.
To determine a good lasso-penalty strength for a linear classification model that uses a logistic regression learner, compare distributions of _k_-fold margins.
Load the NLP data set. Preprocess the data as in Feature Selection Using k-fold Margins.
load nlpdata Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others'; X = X';
Create a set of 11 logarithmically-spaced regularization strengths from 10-8 through 101.
Lambda = logspace(-8,1,11);
Create a linear classification model template that specifies using logistic regression with a lasso penalty, using each of the regularization strengths, optimizing the objective function using SpaRSA, and reducing the tolerance on the gradient of the objective function to 1e-8.
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda,'GradientTolerance',1e-8);
Cross-validate an ECOC model composed of binary, linear classification models using 5-fold cross-validation and that
rng(10); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns','KFold',5)
CVMdl = ClassificationPartitionedLinearECOC CrossValidatedModel: 'LinearECOC' ResponseName: 'Y' NumObservations: 31572 KFold: 5 Partition: [1×1 cvpartition] ClassNames: [comm dsp simulink others] ScoreTransform: 'none'
Properties, Methods
CVMdl is a ClassificationPartitionedLinearECOC model.
Estimate the _k_-fold margins for each regularization strength. The scores for logistic regression are in [0,1]. Apply the quadratic binary loss.
m = kfoldMargin(CVMdl,'BinaryLoss','quadratic'); size(m)
m is a 31572-by-11 matrix of cross-validated margins for each observation. The columns correspond to the regularization strengths.
Plot the _k_-fold margins for each regularization strength.
figure; boxplot(m) ylabel('Cross-validated margins') xlabel('Lambda indices')
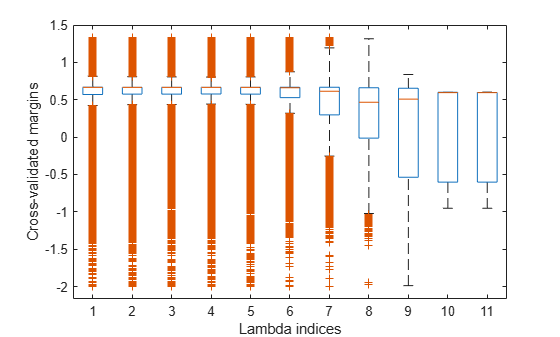
Several values of Lambda yield similarly high margin distribution centers with low spreads. Higher values of Lambda lead to predictor variable sparsity, which is a good quality of a classifier.
Choose the regularization strength that occurs just before the margin distribution center starts decreasing and spread starts increasing.
Train an ECOC model composed of linear classification model using the entire data set and specify the regularization strength LambdaFinal.
t = templateLinear('Learner','logistic','Solver','sparsa',... 'Regularization','lasso','Lambda',Lambda(5),'GradientTolerance',1e-8); MdlFinal = fitcecoc(X,Y,'Learners',t,'ObservationsIn','columns');
To estimate labels for new observations, pass MdlFinal and the new data to predict.
More About
The binary loss is a function of the class and classification score that determines how well a binary learner classifies an observation into the class. The decoding scheme of an ECOC model specifies how the software aggregates the binary losses and determines the predicted class for each observation.
Assume the following:
- mkj is element (k,j) of the coding design matrix_M_—that is, the code corresponding to class_k_ of binary learner j.M is a K_-by-B matrix, where K is the number of classes, and_B is the number of binary learners.
- sj is the score of binary learner_j_ for an observation.
- g is the binary loss function.
- k^ is the predicted class for the observation.
The software supports two decoding schemes:
- Loss-based decoding [2] (
Decodingis"lossbased") — The predicted class of an observation corresponds to the class that produces the minimum average of the binary losses over all binary learners. - Loss-weighted decoding [3] (
Decodingis"lossweighted") — The predicted class of an observation corresponds to the class that produces the minimum average of the binary losses over the binary learners for the corresponding class.
The denominator corresponds to the number of binary learners for class_k_. [1] suggests that loss-weighted decoding improves classification accuracy by keeping loss values for all classes in the same dynamic range.
The predict, resubPredict, andkfoldPredict functions return the negated value of the objective function of argmin as the second output argument (NegLoss) for each observation and class.
This table summarizes the supported binary loss functions, where_yj_ is a class label for a particular binary learner (in the set {–1,1,0}), sj is the score for observation j, and_g_(yj,sj) is the binary loss function.
| Value | Description | Score Domain | g(yj,sj) |
|---|---|---|---|
| "binodeviance" | Binomial deviance | (–∞,∞) | log[1 + exp(–2_yjsj_)]/[2log(2)] |
| "exponential" | Exponential | (–∞,∞) | exp(–yjsj)/2 |
| "hamming" | Hamming | [0,1] or (–∞,∞) | [1 – sign(yjsj)]/2 |
| "hinge" | Hinge | (–∞,∞) | max(0,1 – yjsj)/2 |
| "linear" | Linear | (–∞,∞) | (1 – yjsj)/2 |
| "logit" | Logistic | (–∞,∞) | log[1 + exp(–yjsj)]/[2log(2)] |
| "quadratic" | Quadratic | [0,1] | [1 – yj(2_sj_ – 1)]2/2 |
The software normalizes binary losses so that the loss is 0.5 when_yj_ = 0, and aggregates using the average of the binary learners [1].
Do not confuse the binary loss with the overall classification loss (specified by theLossFun name-value argument of the kfoldLoss andkfoldPredict object functions), which measures how well an ECOC classifier performs as a whole.
The classification margin is, for each observation, the difference between the negative loss for the true class and the maximal negative loss among the false classes. If the margins are on the same scale, then they serve as a classification confidence measure. Among multiple classifiers, those that yield greater margins are better.
References
[1] Allwein, E., R. Schapire, and Y. Singer. “Reducing multiclass to binary: A unifying approach for margin classifiers.” Journal of Machine Learning Research. Vol. 1, 2000, pp. 113–141.
[2] Escalera, S., O. Pujol, and P. Radeva. “Separability of ternary codes for sparse designs of error-correcting output codes.”Pattern Recog. Lett. Vol. 30, Issue 3, 2009, pp. 285–297.
[3] Escalera, S., O. Pujol, and P. Radeva. “On the decoding process in ternary error-correcting output codes.” IEEE Transactions on Pattern Analysis and Machine Intelligence. Vol. 32, Issue 7, 2010, pp. 120–134.
Extended Capabilities
To run in parallel, specify the Options name-value argument in the call to this function and set the UseParallel field of the options structure to true usingstatset:
Options=statset(UseParallel=true)
For more information about parallel computing, see Run MATLAB Functions with Automatic Parallel Support (Parallel Computing Toolbox).
Version History
Introduced in R2016a
Starting in R2023b, the following classification model object functions use observations with missing predictor values as part of resubstitution ("resub") and cross-validation ("kfold") computations for classification edges, losses, margins, and predictions.
In previous releases, the software omitted observations with missing predictor values from the resubstitution and cross-validation computations.