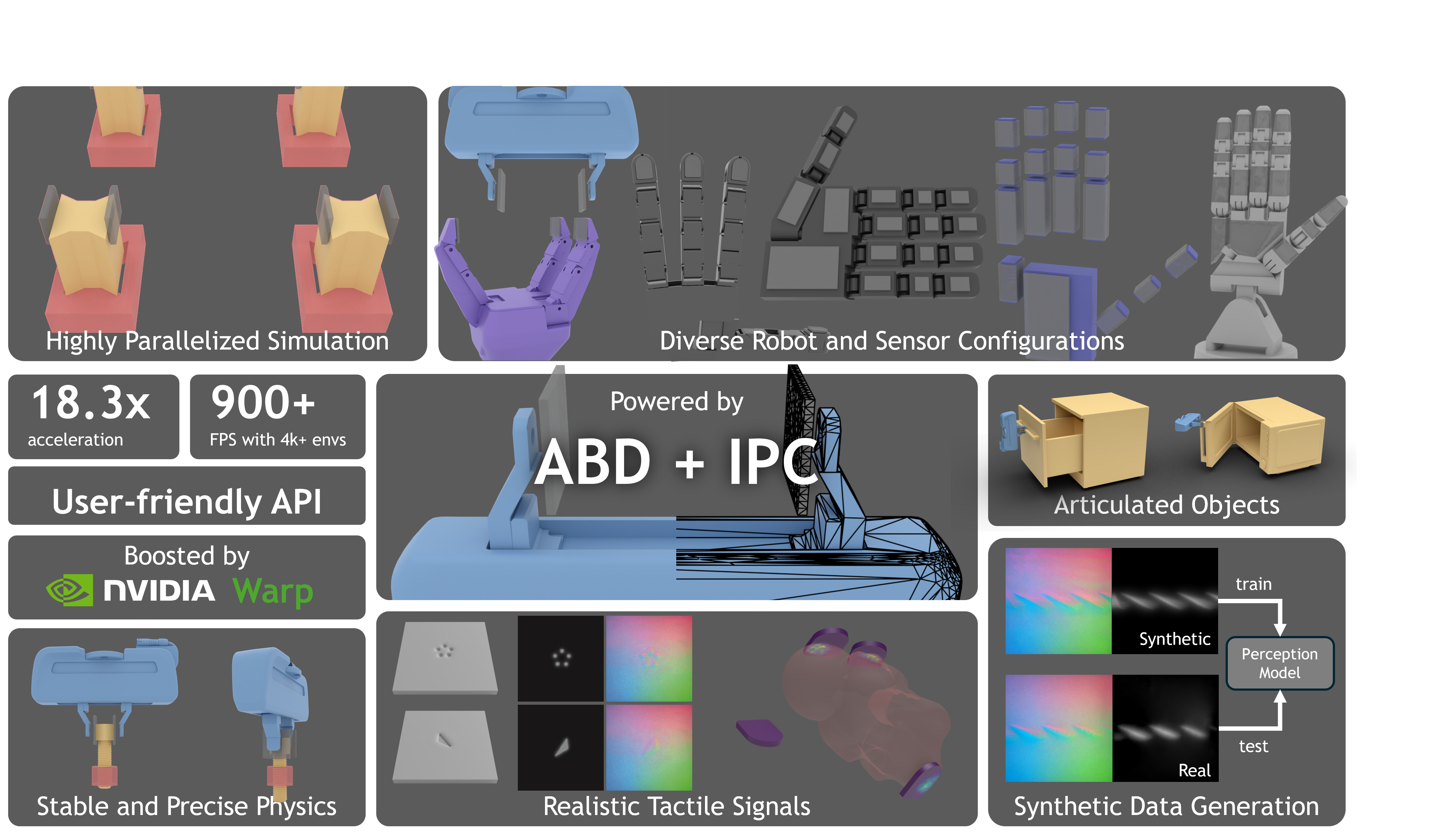
03/2024 Four papers are accepted by CVPR 2024, including three highlight papers! Three of them are about human motion modeling and skill learning, one is about 3D scene synthesis for embodied AI!
02/2024 Invited talk at DeepMind Robotics to introduce LEO.
GaussianFluent: Gaussian Simulation for Dynamic Scenes with Mixed Materials Bei Huang*,Yixin Chen*†,Ruijie Lu,Gang Zeng, Hongbin Zha, Yuru Pei†,Siyuan Huang† CVPR 2026 Oral PresentationBest Paper CandidatePaper / Project GaussianFluent is a framework for simulating and rendering dynamic scenes with complex mixed materials and fractures.
MotionMaster: Generalizable Text-Driven Motion Generation and Editing Nan Jiang*, Yunhao Li*, Lexi Pang*,Zimo He,Siyuan Huang†,Yixin Zhu† CVPR 2026 Project / Code MotionMaster finetunes a pretrained MLLM with large-scale motion data to enable text-generalizable, long-horizon motion generation and editing in a unified framework.
Mocap-2-to-3: Multi-view Lifting for Monocular Motion Recovery with 2D Pretraining Zhumei Wang*, Zechen Hu*,Ruoxi Guo,Huaijin Pi, Ziyong Feng, Liang Zhang,Mingtao Pei,Siyuan Huang CVPR 2026 Paper / Project Mocap-2-to-3 is a diffusion-based multi-view lifting framework that exploits 2D motion pretraining to recover metric-accurate 3D human motion with absolute world positions from monocular video.
Lifting Unlabeled Internet-level Data for 3D Scene Understanding Yixin Chen, Yaowei Zhang,Huangyue Yu,Junchao He,Yan Wang,Jiangyong Huang, Hongyu Shen,Junfeng Ni,Shaofei Wang,Baoxiong Jia,Song-Chun Zhu,Siyuan Huang CVPR 2026 Paper / Project / Code We present SceneVerse++, an automated data engine that lifts unlabeled internet videos into large-scale 3D training data, achieving strong zero-shot performance across 3D detection, segmentation, spatial VQA, and vision-language navigation.
SceneWeaver: All-in-One 3D Scene Synthesis with an Extensible and Self-Reflective Agent Yandan Yang*, Baoxiong Jia*,Shujie Zhang,Siyuan Huang NeurIPS 2025 Best Paper Award at IROS25 RoboGen Workshop Paper / Project / Code We present SceneWeaver, a reflective agentic framework that unifies diverse scene synthesis paradigms through tool-based iterative refinement.
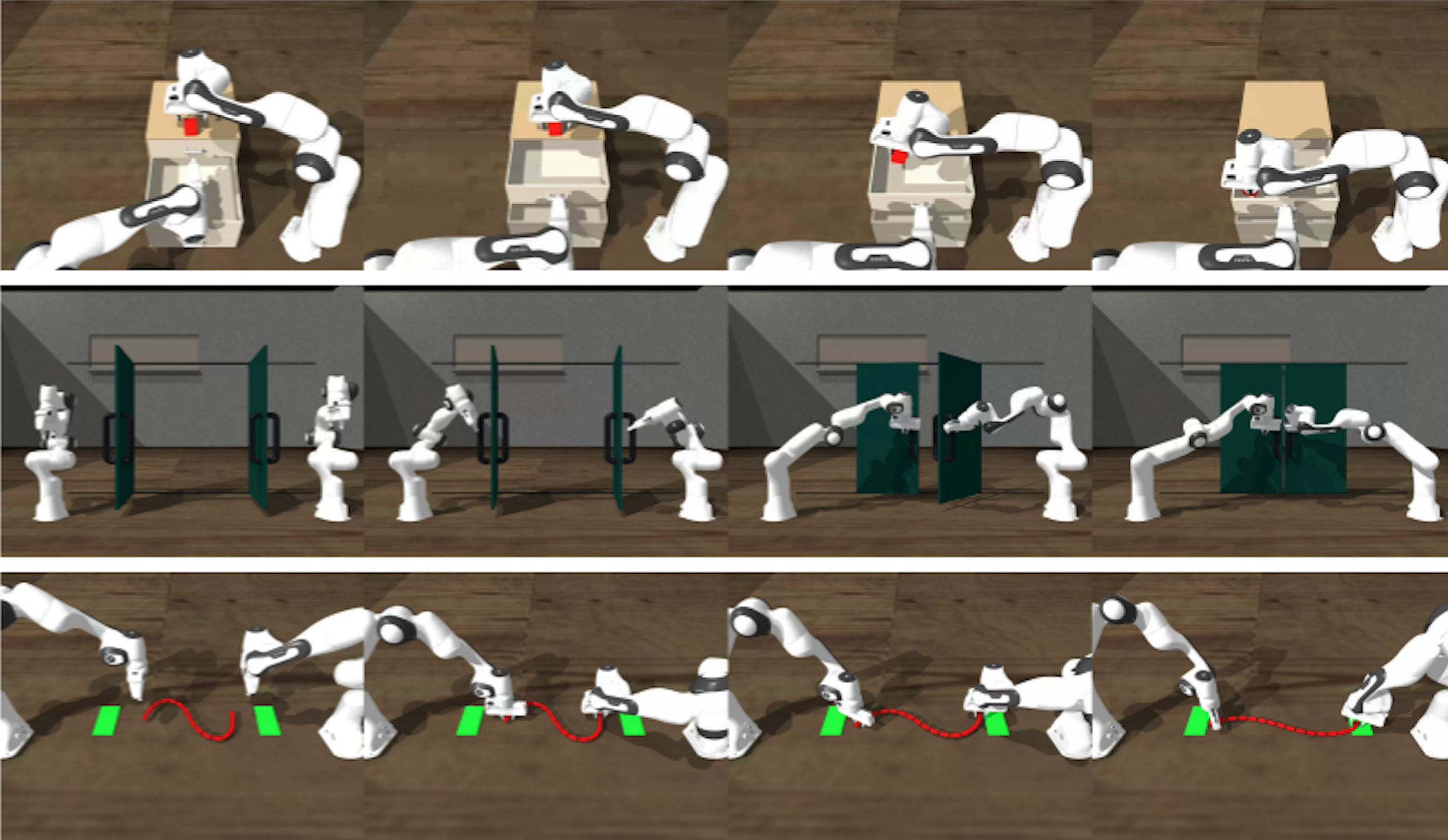
CLONE: Holistic Closed-Loop Humanoid Whole-Body Teleoperation for Long-Horizon Tasks Yixuan Li*,Yutang Lin*,Jieming Cui,Tengyu Liu,Wei Liang†,Yixin Zhu†,Siyuan Huang† CoRL 2025 Paper / Project / Code CLONE is a whole-body teleoperation system that achieves comprehensive robot control using a VR headset. It enables previously unattainable comprehensive skills, such as picking up an object from the ground and placing it in a distant bin, facilitating the collection of long-horizon interaction data.
Learning a Unified Policy for Position and Force Control in Legged Loco-Manipulation Peiyuan Zhi*, Peiyang Li*, Jianqin Yin,Baoxiong Jia†,Siyuan Huang† CoRL 2025 Best Paper AwardPaper / Project / Code We propose a unified control policy for legged robots that jointly models force and position control learned without force sensors. The policy enables a wide range of manipulation behaviors under varying combinations of force and position inputs, including position tracking, force application, force tracking, and compliant robot behaviors.
Trace3D: Consistent Segmentation Lifting via Gaussian Instance Tracing Hongyu Shen*, Junfeng Ni,Yixin Chen †, Weishuo Li,Mingtao Pei,Siyuan Huang† ICCV 2025 Paper / Project / Code We introduce Gaussian Instance Tracing (GIT), which augments the standard Gaussian representation with an instance weight matrix across input views.
Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang,Xiaojian Ma,Yixin Chen,Baoxiong Jia,Wei Liang, Qian Yu, Zhidong Deng, Siyuan Huang†,Qing Li† ICCV 2025 HighlightPaper / Project / Code We introduce Move to Understand (MTU3D), a unified framework that integrates active perception with 3D vision-language learning, enabling embodied agents to effectively explore and understand their environment.
Ag2x2: Robust Agent-Agnostic Visual Representations for Zero-Shot Bimanual Manipulation Ziyin Xiong*,Yinghan Chen*,Puhao Li,Yixin Zhu,Tengyu Liu†,Siyuan Huang† IROS 2025 Paper / Project / Code Ag2x2 is a computational framework for bimanual manipulation through coordination-aware visual representations that jointly encode object states and hand motion patterns while maintaining agent-agnosticism.
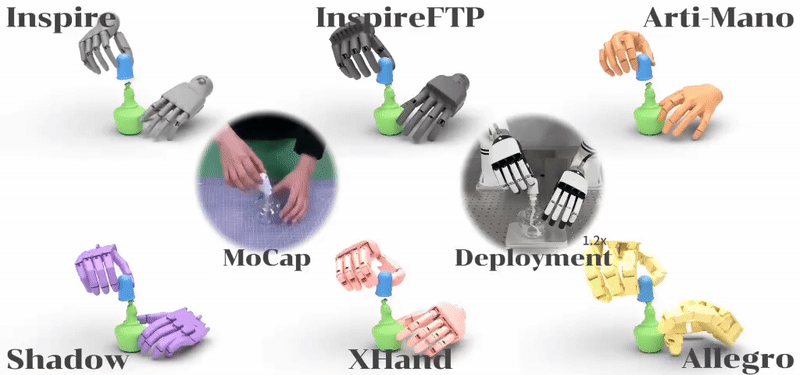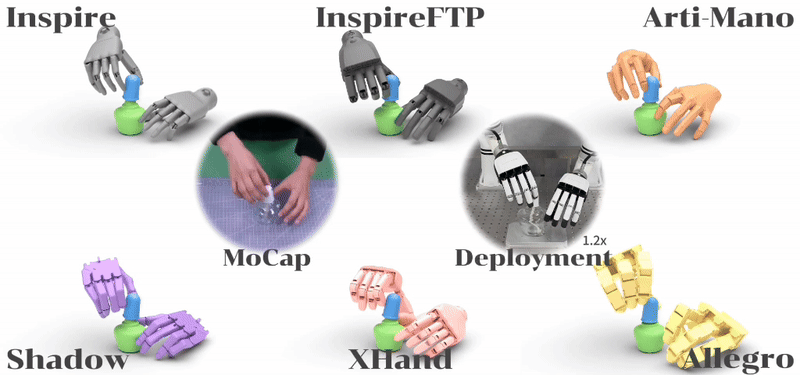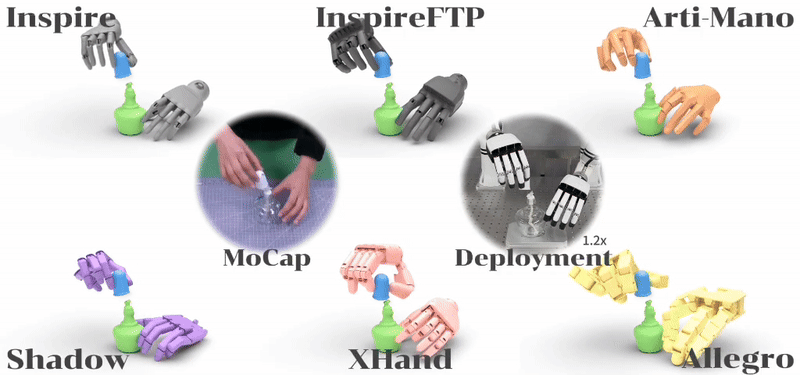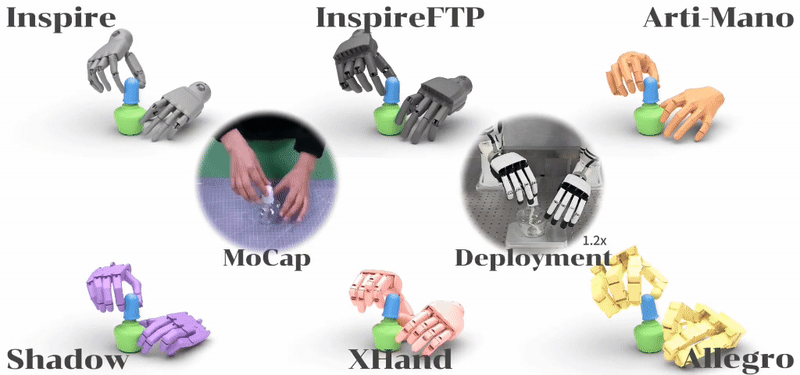
ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning Kailin Li,Puhao Li,Tengyu Liu,Yuyang Li,Siyuan Huang CVPR 2025 Paper / Project / Code We introduce ManipTrans, a novel two-stage method for efficiently transferring human bimanual skills to dexterous robotic hands in simulation. Leveraging ManipTrans, we transfer multiple hand-object datasets to robotic hands, creating DexManipNet, a large-scale dataset featuring previously unexplored tasks like pen capping and bottle unscrewing.
MetaScenes: Towards Automated Replica Creation for Real-world 3D Scans Huangyue Yu*,Baoxiong Jia*,Yixin Chen*, Yandan Yang, Rongpeng Su,Jiaxin Li,Qing Li,Wei Liang,Song-Chun Zhu,Tengyu Liu, Siyuan Huang CVPR 2025 Paper / Project / Code We present METASCENES, a large-scale 3D scene dataset constructed from real-world scans. It features 706 scenes with 15,366 objects across a wide array of types, arranged in realistic layouts, with visually accurate appearances and physical plausibility.
GROVE: A Generalized Reward for Learning Open-Vocabulary Physical Skill Jieming Cui*,Tengyu Liu*,Ziyu Meng, Jiale Yu, Ran Song, Wei Zhang,Yixin Zhu†,Siyuan Huang† CVPR 2025 Oral PresentationPaper / Project / Code GROVE generates open-vocabulary and physical-plausible motions through generalized reward. We introduce a generalized reward framework that enables open-vocabulary physical skill learning without manual engineering or task-specific demonstrations.
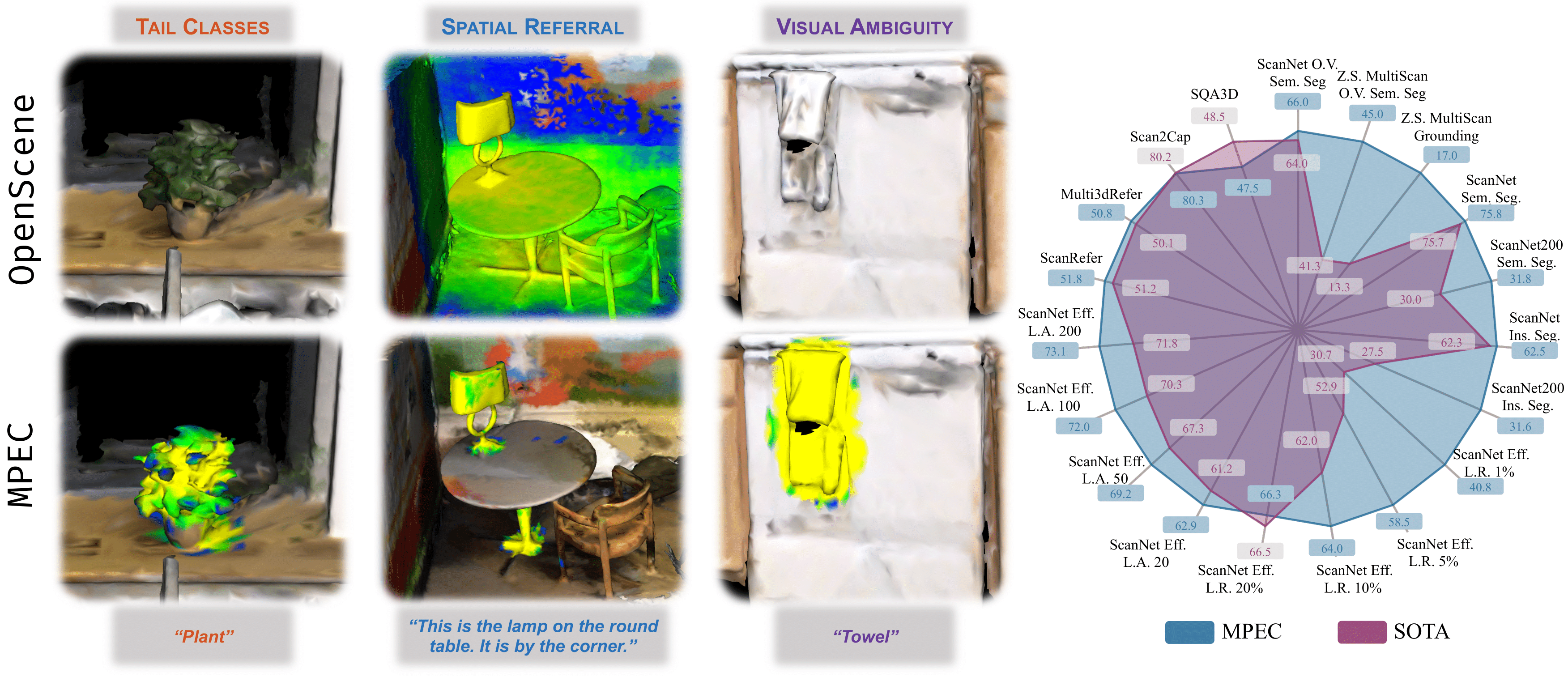
Masked Point-Entity Contrast for Open-Vocabulary 3D Scene Understanding Yan Wang*,Baoxiong Jia*,Ziyu Zhu,Siyuan Huang CVPR 2025 Paper / Project We propose MPEC (Masked Point-Entity Contrast) for open-vocabulary 3D scene understanding. MPEC achieves state-of-the-art on open-vocabulary 3D semantic segmentation and is more robust to tail classes, visual ambiguity and detailed descriptions.
InteractAnything: Zero-shot Human Object-Interaction Synthesis via LLM Feedback and Object Affordance Parsing Jinlu Zhang,Yixin Chen†,Zan Wang,Jie Yang,Yizhou Wang†,Siyuan Huang† CVPR 2025 HighlightPaper / Project / Code Our method enables the generation of diverse, detailed, and novel interactions for open-set 3D objects. Given a simple text description with goal interaction and any object mesh as input, we can synthesize different natural HOI results without training on 3D assets.
PhysPart: Physically Plausible Part Completion for Interactable Objects Rundong Luo*,Haoran Geng*,Congyue Deng,Puhao Li,Zan Wang,Baoxiong Jia,Leonidas Guibas,Siyuan Huang ICRA 2025 Paper We propose a diffusion-based part generation model that utilizes geometric conditioning through classifier-free guidance and formulates physical constraints as a set of stability and mobility losses to guide the sampling process.
SYNERGAI: Perception Alignment for Human-Robot Collaboration Yixin Chen*,Guoxi Zhang*, Yaowei Zhang, Hongming Xu, Peiyuan Zhi,Qing Li,Siyuan Huang ICRA 2025 Paper / Project We introduce SYNERGAI, a unified system designed to achieve both perceptual alignment and human-robot collaboration.
ArtGS: Building Interactable Replicas of Complex Articulated Objects via Gaussian Splatting Yu Liu*,Baoxiong Jia*,Ruijie Lu,Song-Chun Zhu,Siyuan Huang ICLR 2025 Paper / Project We introduce ArtGS, a novel approach that leverages 3D Gaussians as a flexible and efficient representation to reconstruct articulated objects.
PhyRecon: Physically Plausible Neural Scene Reconstruction Junfeng Ni*,Yixin Chen*, Bohan Jing,Nan Jiang,Bin Wang,Bo Dai,Puhao Li,Yixin Zhu,Song-Chun Zhu,Siyuan Huang NeurIPS 2024 Paper / Project / Code We introduce PhyRecon, the first approach to leverage both differentiable rendering and differentiable physics simulation to learn implicit surface representations for neural scene reconstruction.
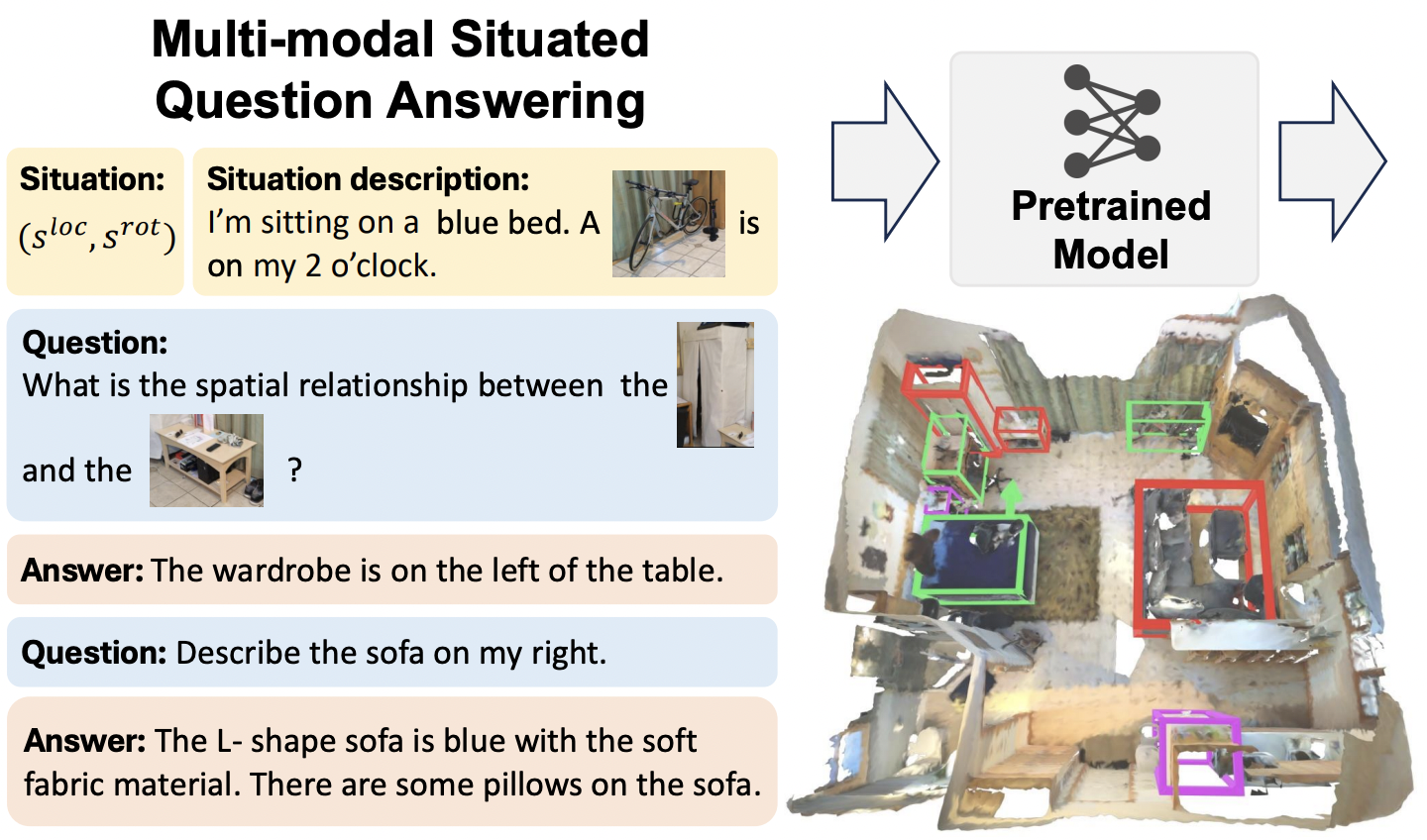
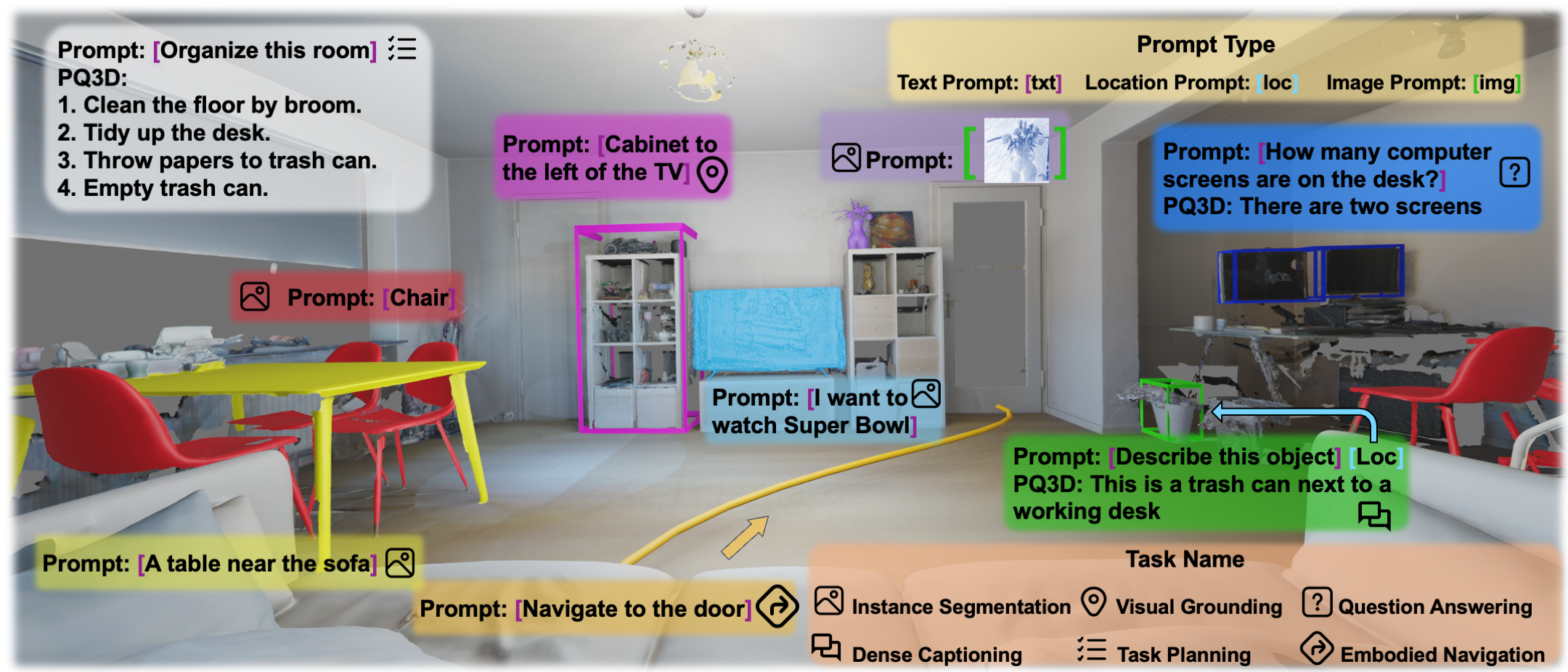
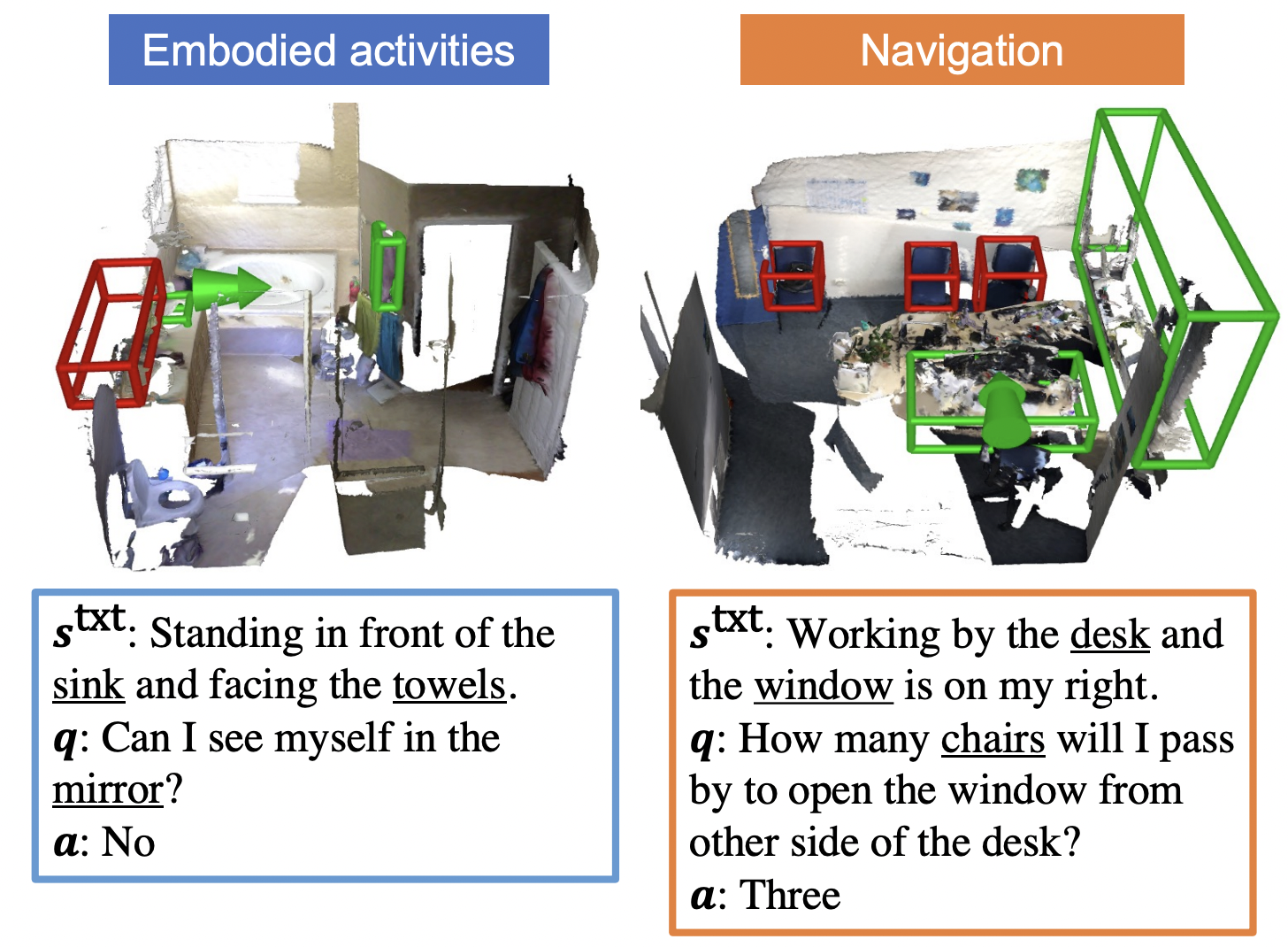
Multi-modal Situated Reasoning in 3D Scenes Xiongkun Linghu*,Jiangyong Huang*,Xuesong Niu,Xiaojian Ma,Baoxiong Jia†,Siyuan Huang† NeurIPS 2024 (Dataset and Benchmark Track) Paper / Project / Code We propose Multi-modal Situated Question Answering (MSQA), a large-scale multi-modal situated reasoning dataset, scalably collected leveraging 3D scene graphs and vision-language models (VLMs) across a diverse range of real-world 3D scenes.
SlotLifter: Slot-guided Feature Lifting for Learning Object-centric Radiance Fields Yu Liu*,Baoxiong Jia*,Yixin Chen,Siyuan Huang ECCV 2024 Paper / Project We propose SlotLifter, a novel object-centric radiance model addressing scene reconstruction and decomposition jointly via slot-guided feature lifting.
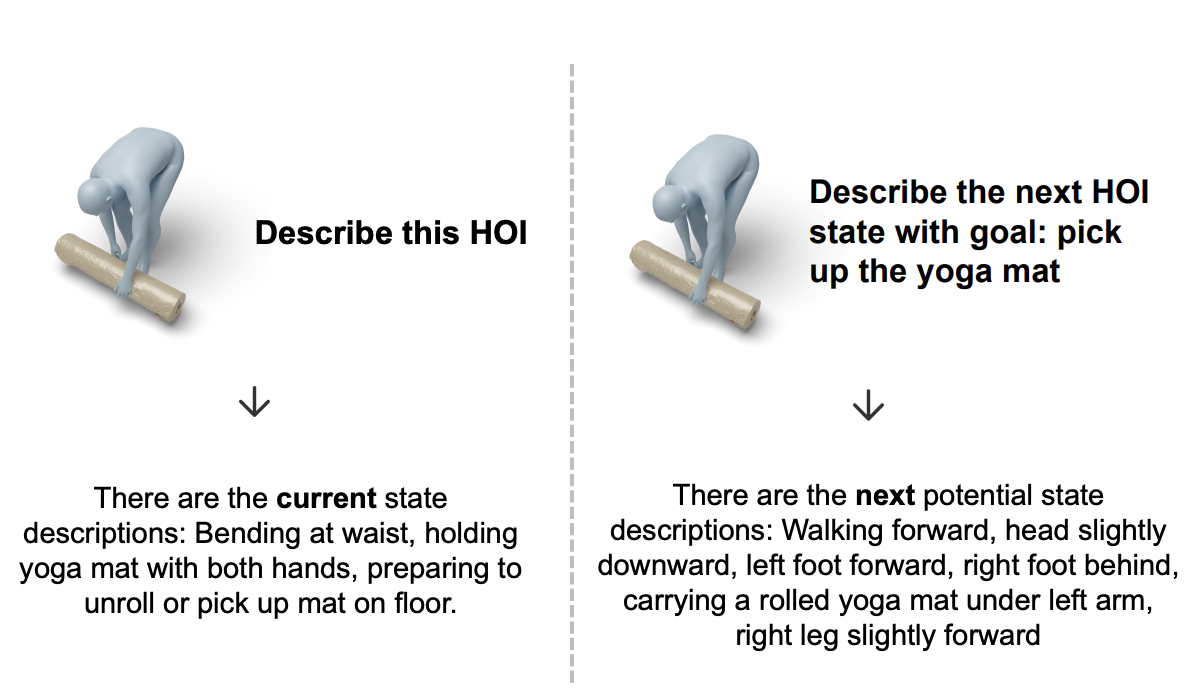
F-HOI: Toward Fine-grained Semantic-Aligned 3D Human-Object Interactions Jie Yang*,Xuesong Niu*,Nan Jiang*,Ruimao Zhang†,Siyuan Huang†, ECCV 2024 Paper / Project We propose a unified model called F-HOI, designed to leverage multimodal instructions and empower the Multi-modal Large Language Model to efficiently handle diverse HOI tasks.
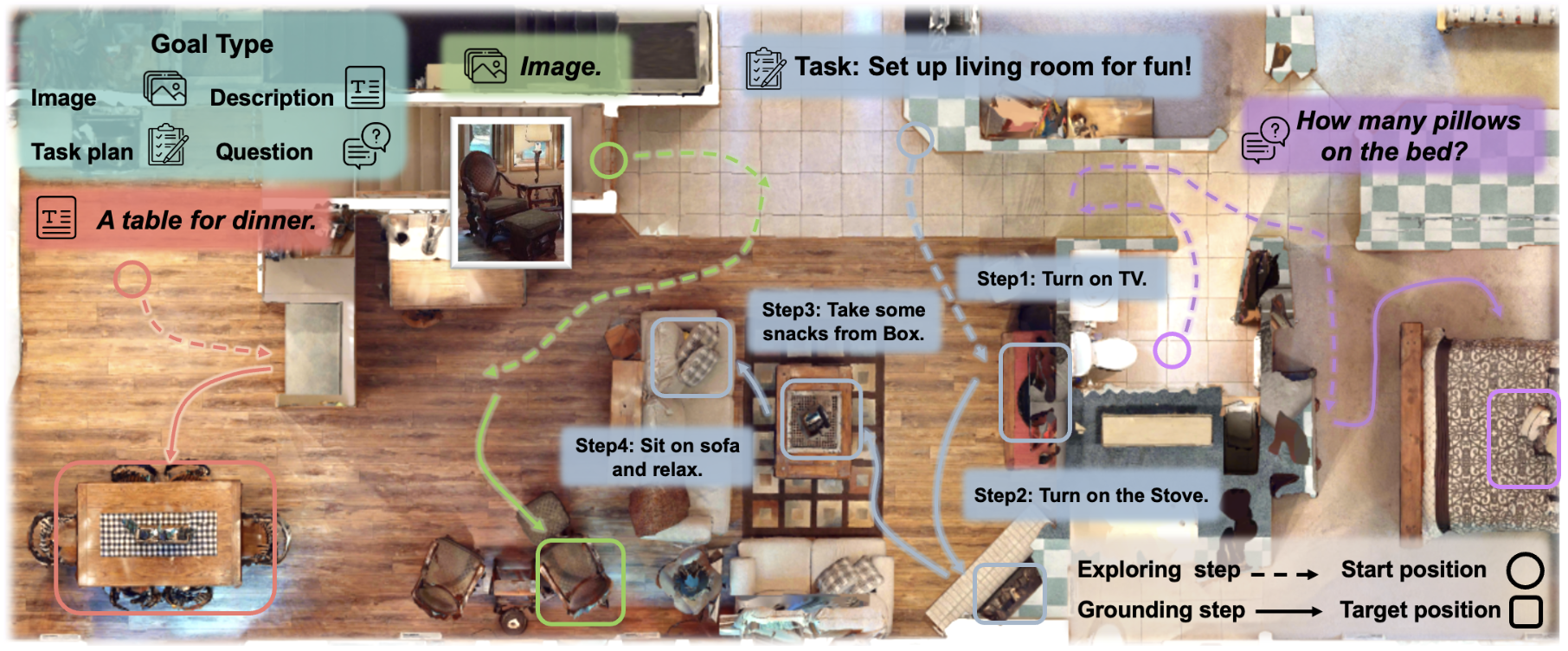
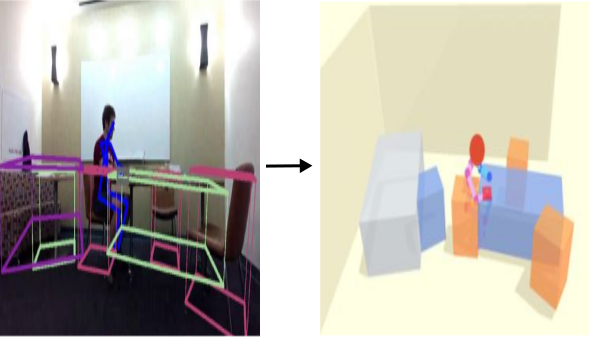
PHYSCENE: Physically Interactable 3D Scene Synthesis for Embodied AI Yandan Yang*,Baoxiong Jia*,Peiyuan Zhi,Siyuan Huang CVPR 2024 Highlight, 2.8%Paper / Project We introduce PhyScene, a novel method dedicated to generating interactive 3D scenes characterized by realistic layouts, articulated objects, and rich physical interactivity tailored for embodied agents.
Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance Zan Wang,Yixin Chen,Baoxiong Jia,Puhao Li,Jinlu Zhang, Jinze Zhang,Tengyu Liu,Yixin Zhu† ,Wei Liang†,Siyuan Huang† CVPR 2024 Highlight, 2.8%Paper / Project / Code We introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation.
Scaling Up Dynamic Human-Scene Interaction Modeling Nan Jiang*, Zhiyuan Zhang*, Hongjie Li, Xiaoxuan Ma,Zan Wang,Yixin Chen,Tengyu Liu,Yixin Zhu† ,Siyuan Huang † CVPR 2024 Highlight, 2.8%Paper / Project / Live Demo / Code We introduce the TRUMANS dataset as the most comprehensive motion-captured HSI dataset currently available, encompassing over 15 hours of human interactions across 100 indoor scenes. We also present the first model that scales up human-scene interaction modeling and achieves remarkable performance in generation.
AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents Jiemin Cui*,Tengyu Liu*,Nian Liu*,Yaodong Yang,Yixin Zhu† ,Siyuan Huang† CVPR 2024 Paper / Project / Code We propose AnySkill, a novel hierarchical method that learns physically plausible interactions following open-vocabulary instructions. AnySkill is the first method capable of open-vocabulary physical skill learning for interactive humanoid agents.
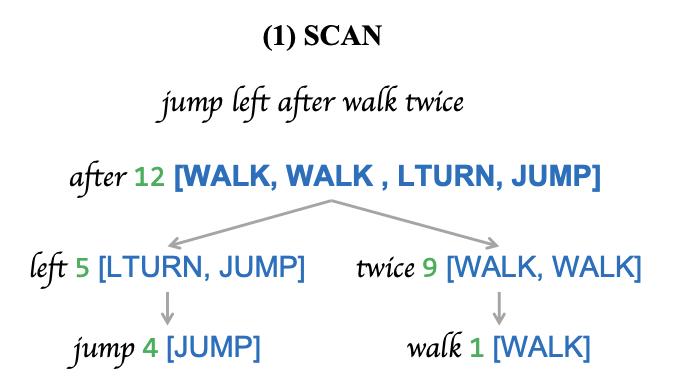
Neural-Symbolic Recursive Machine for Systematic Generalization Qing Li,Yixin Zhu,Yitao Liang,Ying Nian Wu,Song-Chun Zhu,Siyuan Huang ICLR 2024 Paper We propose Neural-Symbolic Recursive Machine (NSR) for learning compositional rules from limited data and applying them to unseen combinations in various domains. NSR achieves 100% generalization accuracy on SCAN and PCFG and outperforms state-of-the-art models on HINT by about 23%.
Single-view 3D Scene Reconstruction with High-fidelity Shape and Texture Yixin Chen*,Junfeng Ni*,Nan Jiang, Yaowei Zhang,Yixin Zhu,Siyuan Huang 3DV 2024 Paper / Project / Code We propose a novel framework for simultaneous high-fidelity recovery of object shapes and textures from single-view images.
ARNOLD: A Benchmark for Language-Grounded Task Learning with Continuous States in Realistic Scenes Ran Gong*,Jiangyong Huang*,Yizhou Zhao,Haoran Geng,Xiaofeng Gao,Qingyang Wu,Wensi Ai,Ziheng Zhou,Demetri Terzopoulos,Song-Chun Zhu,Baoxiong Jia,Siyuan Huang ICCV 2023 CoRL 2022 Workshop on Language and Robot Learning Spotlight PresentationArxiv / Project / Code We present ARNOLD, a benchmark that evaluates language-grounded task learning with continuous states in realistic 3D scenes. ARNOLD consists of 8 language-conditioned tasks that involve understanding object states and learning policies for continuous goals.
Full-Body Articulated Human-Object Interaction Nan Jiang*,Tengyu Liu*, Zhexuan Cao, Jieming Cui, Zhiyuan Zhang,He Wang,Yixin Zhu† ,Siyuan Huang† ICCV 2023 Paper / Project / Code We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 74 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions.
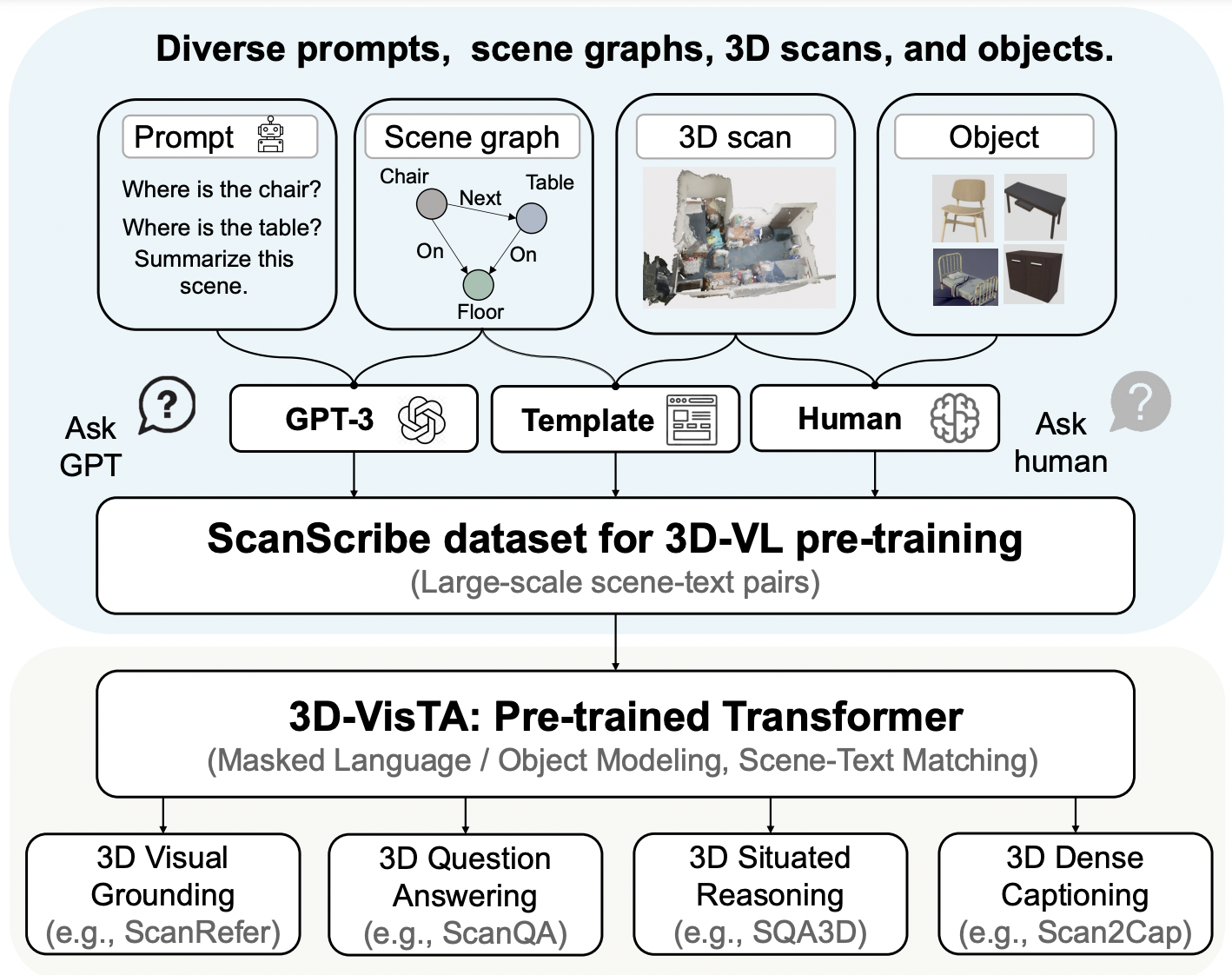
3D-VISTA: Pre-trained Transformer for 3D Vision and Text Alignment Ziyu Zhu,Xiaojian Ma,Yixin Chen, Zhidong Deng,Siyuan Huang†,Qing Li† ICCV 2023 Paper / Project / Code We propose 3D-VisTA, a foundation model that can be easily adapted to various 3D vision-language tasks.
Diffusion-based Generation, Optimization, and Planning in 3D Scenes Siyuan Huang*,Zan Wang*,Puhao Li,Baoxiong Jia,Tengyu Liu,Yixin Zhu,Wei Liang,Song-Chun Zhu CVPR 2023 Paper / Project / Code We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior work, SceneDiffuser is intrinsically scene-aware, physics-based, and goal-oriented.
GAPartNet: Learning Generalizable and Actionable Parts for Cross-Category Object Perception and Manipulation Haoran Geng*, Helin Xu*, Chengyang Zhao*,Chao Xu,Li Yi,Siyuan Huang,He Wang CVPR 2023 Highlight, 2.5%Paper / Project / Code We propose to learn generalizable object perception and manipulation skills via Generalizable and Actionable Parts, and present GAPartNet, a large-scale interactive dataset with rich part annotations.
A Minimalist Dataset for Systematic Generalization of Perception, Syntax, and Semantics Qing Li,Siyuan Huang,Yining Hong,Yixin Zhu,Ying Nian Wu,Song-Chun Zhu ICLR 2023 Spotlight, 5.7%Paper we present a new dataset, HINT, to study machines' capability of learning generalizable concepts at three different levels: perception, syntax, and semantics.
SQA3D: Situated Question Answering in 3D Scenes Xiaojian Ma,Silong Yong,Zilong Zheng,Qing Li ,Yitao Liang,Song-Chun Zhu,Siyuan Huang ICLR 2023 Paper / Project / Code / Slides We propose a new task to benchmark scene understanding of embodied agents: Situated Question Answering in 3D Scenes (SQA3D). Given a scene context (e.g., 3D scan), SQA3D requires the tested agent to first understand its situation (position, orientation, etc.) in the 3D scene as described by text, then reason about its surrounding environment and answer a question under that situation.
Improving Object-centric Learning with Query Optimization Baoxiong Jia*,Yu Liu*,Siyuan Huang ICLR 2023 Paper / Project / Code Our model, Bi-level Optimized Query Slot Attention, achieves state-of-the-art results on 3 challenging synthetic and 7 complex real-world datasets in unsupervised image segmentation and reconstruction, outperforming previous baselines by a large margin.
HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes Zan Wang,Yixin Chen,Tengyu Liu,Yixin Zhu,Wei Liang,Siyuan Huang NeurIPS 2022 Paper / Project / Code We present a novel scene-and-language conditioned generative model that can produce 3D human motions of the desirable action interacting with the specified objects. For example, sit on the armchair near the desk.To fill in the gap. We collect a large-scale and semantic-rich synthetic human-scene interaction dataset, denoted as HUMANISE, to enable such langauge-conditoned scene understanding tasks.
EgoTaskQA: Understanding Human Tasks in Egocentric Videos Baoxiong Jia ,Ting Lei,Song-Chun Zhu,Siyuan Huang NeurIPS 2022 (Dataset and Benchmark Track) Paper / Project / Code We introduce the EgoTaskQA benchmark that provides a single home for the crucial dimensions of task understanding through question answering on real-world egocentric videos. We meticulously design questions that target the understanding of (1) action dependencies and effects, (2) intents and goals, and (3) agents' beliefs about others.
Learning V1 simple cells with vector representations of local contents and matrix representations of local motions Ruiqi Gao ,Jianwen Xie ,Siyuan Huang,Yufan Ren,Song-Chun Zhu,Ying Nian Wu AAAI 2022 Paper We propose a representational model that couples the vector representations of local image contents with the matrix representations of local pixel displacements. When the image changes from one time frame to the next due to pixel displacements, the vector at each pixel is rotated by a matrix that represents the displacement of this pixel.
YouRefIt: Embodied Reference Understanding with Language and Gesture Yixin Chen,Qing Li, Deqian Kong, Yik Lun Kei,Tao Gao ,Yixin Zhu,Song-Chun Zhu,Siyuan Huang ICCV 2021 Oral PresentationPaper /Supplementary / Project / Code We study the machine's understanding of embodied reference: One agent uses both language and gesture to refer to an object to another agent in a shared physical environment.
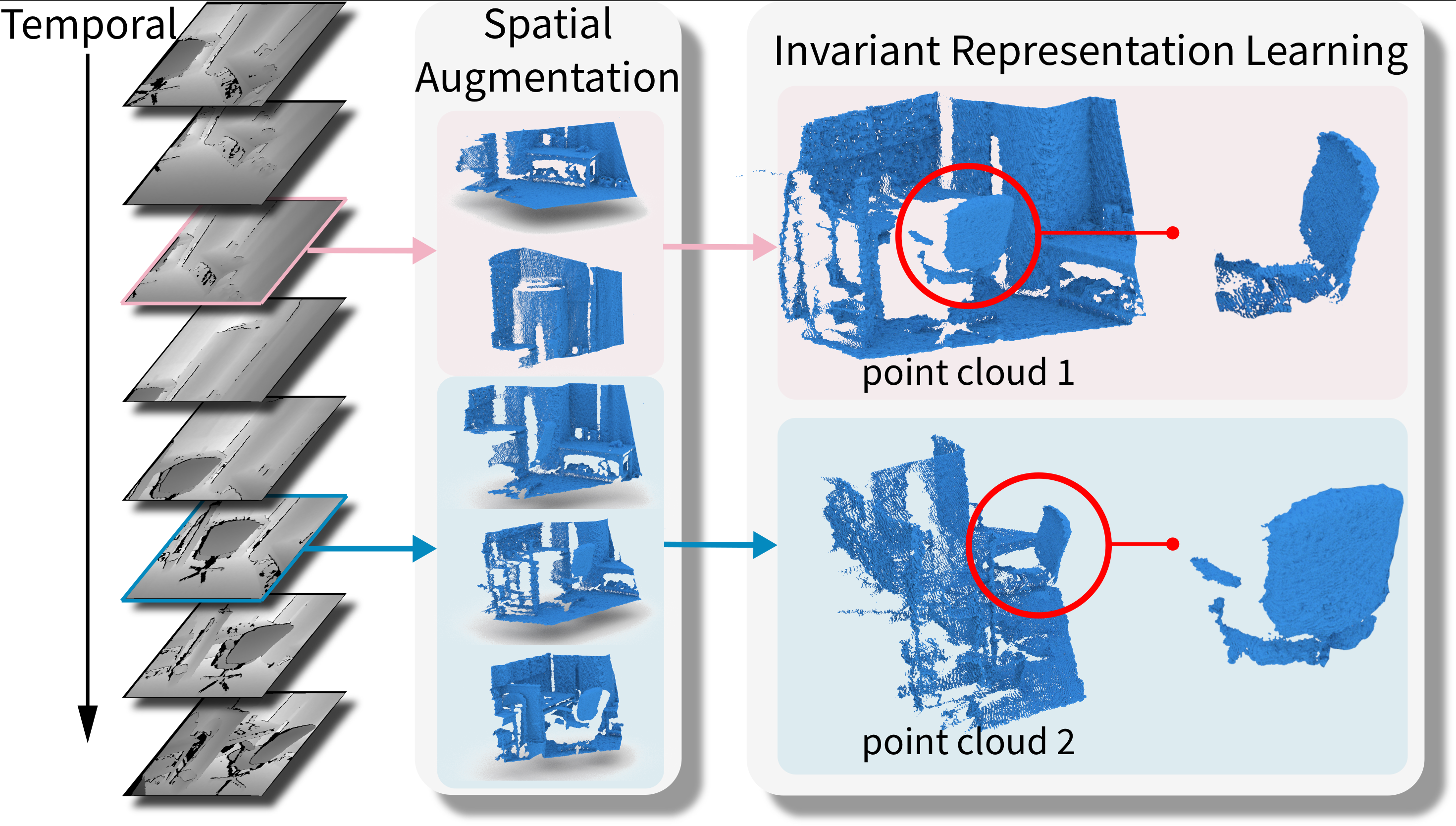
Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds Siyuan Huang*,Yichen Xie*Song-Chun Zhu,Yixin Zhu ICCV 2021 Paper /Supplementary / Project / Code We introduce a spatio-temporal representation learning (STRL) framework, capable of learning from unlabeled 3D point clouds in a self-supervised fashion.
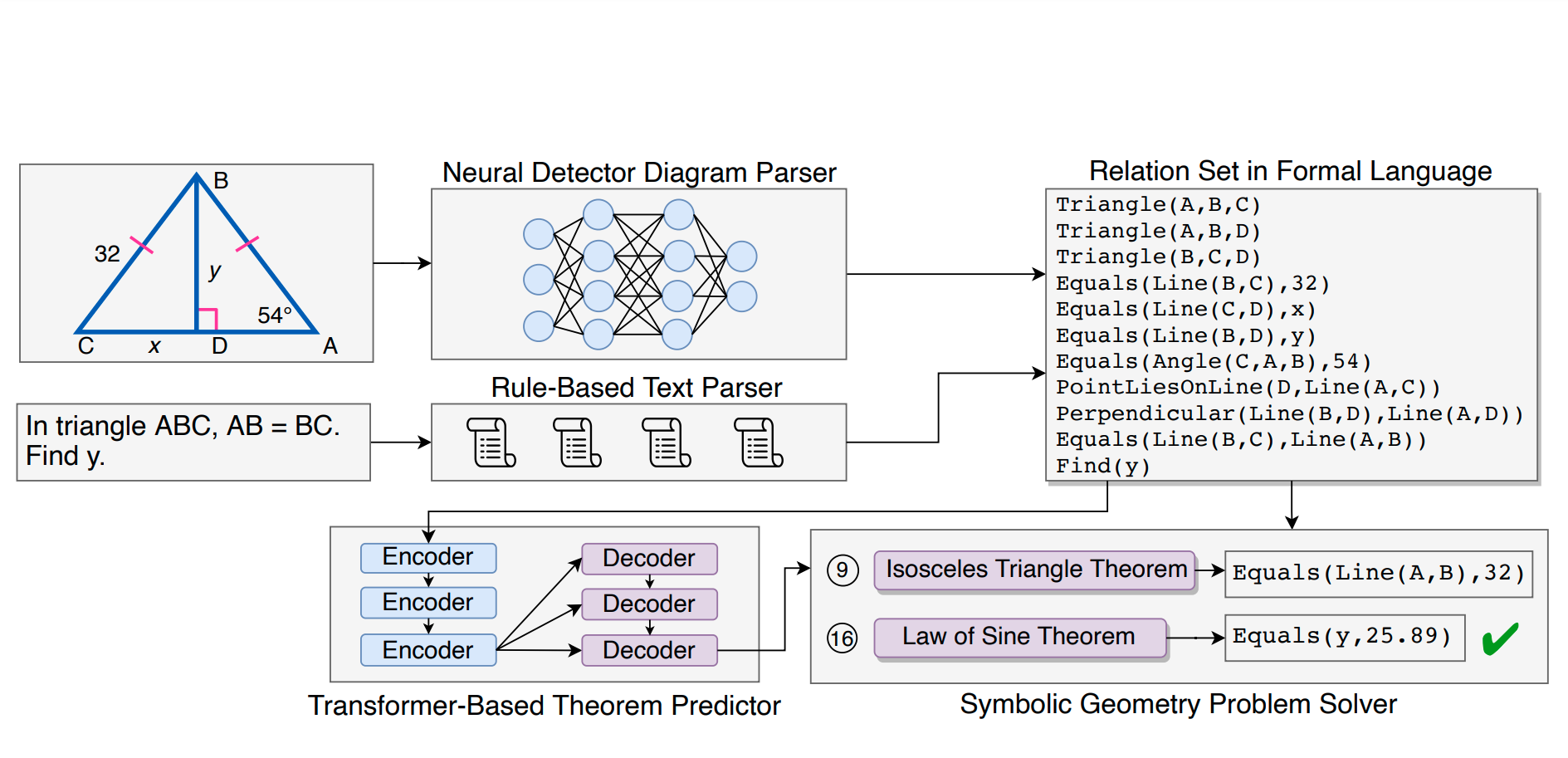
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning Pan Lu*, Ran Gong*, Shibiao Jiang*, Liang Qiu, Siyuan Huang, Xiaodan Liang, Song-Chun Zhu ACL 2021 Oral PresentationPaper /Code /Project /Bibtex We construct a new largescale benchmarkconsisting of 3,002 geometry problems with dense annotation in formal language and propose a novel geometry solving approach with formal language and symbolic reasoning.
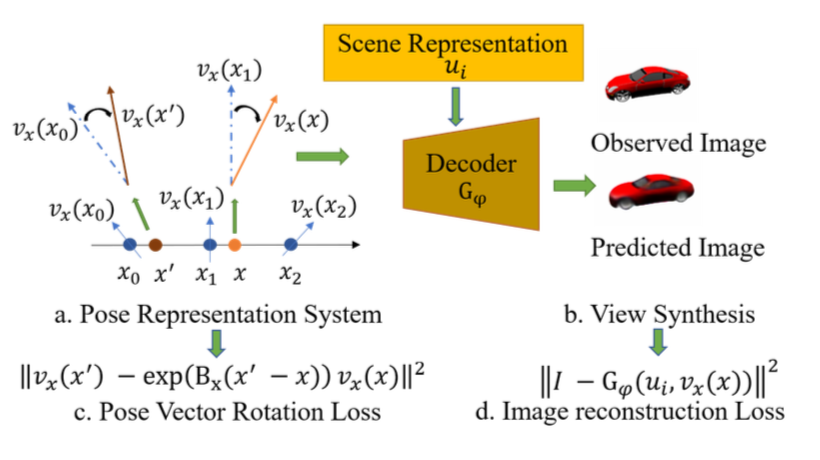
Learning Neural Representation of Camera Pose with Matrix Representation of Pose Shift via View Synthesis Yaxuan Zhu,Ruiqi Gao,Siyuan Huang,Song-Chun Zhu,Ying Nian Wu CVPR 2021 Oral PresentationPaper /Supplementary / Code To efficiently represent camera pose in 3D computer vision, we propose an approach to learn neural representations of camera poses and 3D scenes, coupled with neural representations of local camera movements.
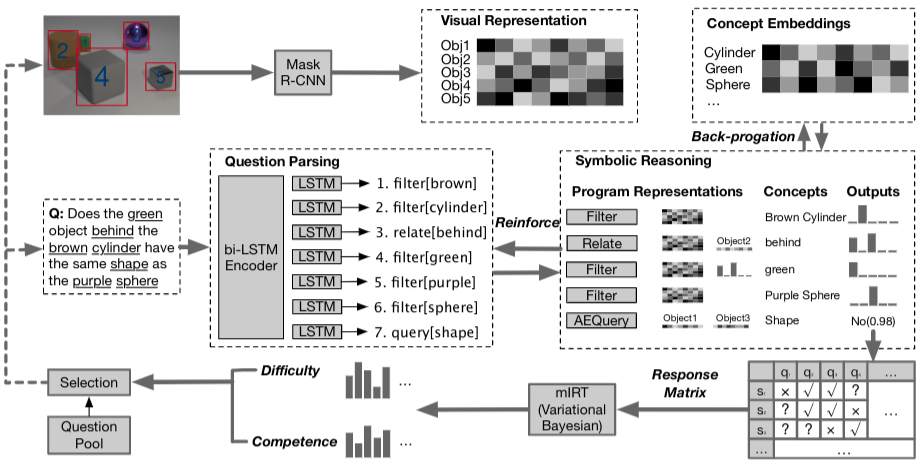
A Competence-aware Curriculum for Visual Concepts Learning via Question Answering Qing Li ,Siyuan Huang,Yining Hong,Song-Chun Zhu ECCV 2020 Oral PresentationPaper We design a neural-symbolic concept learner for learning the visual concepts and a multi-dimensional Item Response Theory (mIRT) model for guiding the visual concept learning process with an adaptive curriculum.
LEMMA: A Multi-view Dataset for Learning Multi-agent Multi-task Activities Baoxiong Jia,Yixin Chen,Siyuan Huang,Yixin Zhu,Song-Chun Zhu ECCV 2020 Paper /Code /Project /Bibtex We introduce the LEMMA dataset to provide a single home to address these missing dimensions with carefully designed settings, wherein the numbers of tasks and agents vary to highlight different learning objectives. We densely annotate the atomic-actions with human-object interactions to provide ground-truth of the compositionality, scheduling, and assignment of daily activities.
Dark, Beyond Deep: A Paradigm Shift to Cognitive AI with Humanlike Common Sense Yixin Zhu,Tao Gao,Lifeng Fan,Siyuan Huang,Edmonds Mark,Hangxin Liu,Feng Gao,Chi Zhang,Siyuan Qi,Ying Nian Wu, Josh Tenenbaum,Song-Chun Zhu Engineering 2020 Paper We demonstrate the power of this perspective to develop cognitive AI systems with humanlike common sense by showing how to observe and apply FPICU with little training data to solve a wide range of challenging tasks, including tool use, planning, utility inference, and social learning.
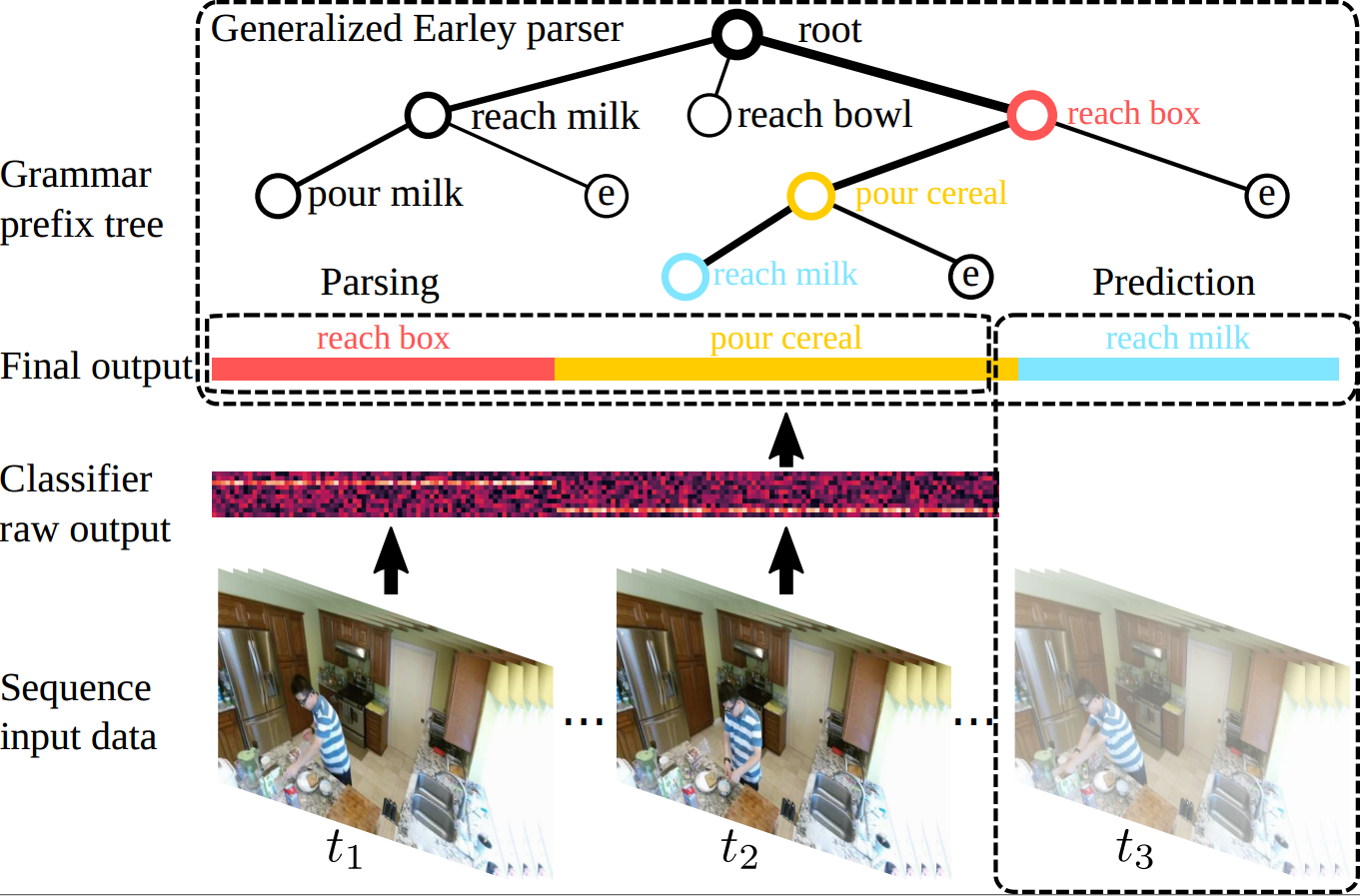
A Generalized Earley Parser for Human Activity Parsing and Prediction Siyuan Qi ,Baoxiong Jia ,Siyuan Huang,Ping Wei,Song-Chun Zhu TPAMI 2020 Paper Propose an algorithm to tackle the task of understanding complex human activities from (partially observed) videos from two important aspects: activity recognition and prediction.
PerspectiveNet: 3D Object Detection from a Single RGB Image via Perspective Points Siyuan Huang,Yixin Chen,Tao Yuan,Siyuan Qi,Yixin Zhu,Song-Chun Zhu Neural Information Processing Systems (NeurIPS) 2019 Paper To solve the problem of 3D object detection, we propose perspective points as a novel intermediate representation, defined as the 2D projections of locally-Manhattan 3D keypoints to locate an object, and they satisfy certain geometric constraints caused by the perspective projection.
Holistic++ Scene Understanding: Single-view 3D Holistic Scene Parsing and Human Pose Estimation with Human-Object Interaction and Physical Commonsense Yixin Chen *,Siyuan Huang *,Tao Yuan,Siyuan Qi,Yixin Zhu,Song-Chun Zhu IEEE International Conference on Computer Vision (ICCV) 2019 * Equal contributions Paper /Supplementary / Project Propose a new 3D holistic++ scene understanding problem, which jointly tackles two tasks from a single-view image: (i) holistic scene parsing and reconstruction- and (ii) 3D human pose estimation. We incorporate the human-object interaction (HOI) and physical commonsense to tackle this problem.
Understanding Human Gaze Communication by Spatio-Temporal Graph Reasoning Lifeng Fan *,Wenguan Wang *,Siyuan Huang, Xinyu Tang,Song-Chun Zhu IEEE International Conference on Computer Vision (ICCV) 2019 * Equal contributions Paper Propose a new problem of understanding human gaze communication in social videos from both atomic-level and event-level, which is significant for studying human social interactions.
Configurable 3D Scene Synthesis and 2D Image Rendering with Per-Pixel Ground Truth using Stochastic Grammars * Equal contributions Internatianal Journal of Computer Vision (IJCV) 2018 Paper /Demo Employ physics-based rendering to synthesize photorealistic RGB images while automatically synthesizing detailed,per-pixel ground truth data, including visible surface depth and normal, object identity and material information, as well as illumination.
Human-centric Indoor Scene Synthesis using Stochastic Grammar Siyuan Qi,Yixin Zhu ,Siyuan Huang,Chenfanfu Jiang ,Song-Chun Zhu IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018 Paper / Project / Code /Bibtex Present a human-centric method to sample and synthesize 3D room layouts and 2D images thereof, for the purpose of obtaining large-scale 2D/3D image data with the perfect per-pixel ground truth.
Predicting Human Activities Using Stochastic Grammar Siyuan Qi,Siyuan Huang,Ping Wei,Song-Chun Zhu IEEE International Conference on Computer Vision (ICCV) 2017 Paper /Bibtex /Code Use a stochastic grammar model to capture the compositional structure of events, integrating human actions, objects, and their affordances for modeling the rich context between human and environment.
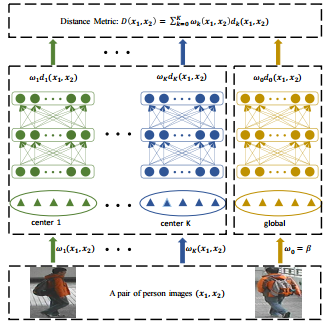
Nonlinear Local Metric Learning for Person Re-identification Siyuan Huang,Jiwen Lu,Jie Zhou,Anil K. Jain arXiv 2015 arXiv Paper Utilize the merits of both local metric learning and deep neural network to exploit the complex nonlinear transformations in the feature space of person re-identification data.
Building Change Detection Based on 3D reconstruction Baohua Chen,Lei Deng,Yueqi Duan,Siyuan Huang,Jie Zhou IEEE International Conference on Image Processing (ICIP) 2015 Paper /Bibtex Propose a change detection framework based on RGB-D map generated by 3D reconstruction which can overcome the large illumination changes .