System Design Interview Questions and Answers (original) (raw)
Last Updated : 27 May, 2026
System Design is a key part of technical interviews at top tech companies, testing a candidate’s ability to build scalable, reliable, and efficient systems. It includes both Low-Level Design (LLD) and High-Level Design (HLD), making it important for freshers and experienced professionals targeting backend or system design roles. This article provides 100 curated System Design interview questions, including 50 LLD and 50 HLD questions.
- Covers frequently asked System Design interview questions, including both Low-Level Design (LLD) and High-Level Design (HLD).
- Useful for both beginners and experienced developers to understand key concepts.
- Helps in quick revision and effective interview preparation.
Low Level Design(LLD) Interview Questions
Low-Level Design (LLD) is a crucial phase in software development that involves turning high-level architectural designs into implementable modules.
1. What is the purpose of Low-Level System Design in software development?
Low-Level System Design (LLD) is the process of converting a high-level system design into detailed and implementable components that define how the system will actually work at the code level.
It focuses on designing class structures, object relationships, APIs, and internal logic of the system before coding begins.
- Removes ambiguity by clearly defining how each module behaves and interacts
- Ensures the system is scalable, maintainable, and aligned with the overall architecture
**Example: Designing a Parking Lot system where you define classes like Car, ParkingSpot, and ParkingLot, along with their relationships and responsibilities.
2. How does database indexing optimize query performance?
Database indexing is a technique used to speed up data retrieval by creating an additional data structure that allows the database to find rows efficiently without scanning the entire table.
It improves query performance by using structures like B-Trees, Hash Indexes, or Bitmap Indexes to quickly locate the required data.
- Improves SELECT query performance by enabling fast lookups instead of full table scans
- Reduces disk I/O and supports efficient filtering, joins, and range queries
**Example: In a user table, creating an index on the user_id column allows the database to directly locate a specific user record without checking every row in the table.

3. What are the four pillars of Object-Oriented Programming (OOP)?
The four pillars of OOP are the fundamental concepts used to design modular, reusable, and maintainable object-oriented systems.
These principles help developers organize code efficiently and model real-world entities in software applications.
- The four pillars are Encapsulation, Abstraction, Inheritance, and Polymorphism
- They improve code reusability, flexibility, security, and maintainability in software systems
**Example: In a banking application, inheritance allows different account types to share common features, while polymorphism enables different transaction behaviors using the same method interface.
4. Why is concurrency control important in multi-threaded systems?
Concurrency control ensures that multiple threads can safely access and modify shared resources without causing data inconsistency or unexpected behavior.
It prevents issues like race conditions, deadlocks, and corrupted states by managing how threads execute critical sections of code.
- Maintains data integrity by controlling simultaneous access to shared resources
- Ensures system reliability and correctness under parallel execution
**Example: In a banking system, concurrency control ensures that when two users try to withdraw money from the same account at the same time, the balance is updated correctly without losing any transaction.
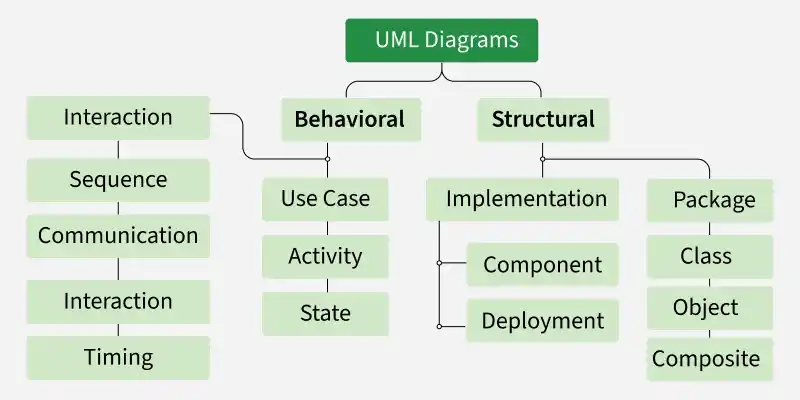
5. What are UML Behavioral Diagrams?
UML Behavioral Diagrams represent the dynamic behavior of a system by showing how objects interact and how the system changes over time in response to events.
They focus on system flow, interactions, and state changes rather than static structure.
- Model how different components interact and respond during execution
- Help visualize system behavior, workflows, and state transitions clearly
**Example: A sequence diagram for a login system shows how the user request flows from UI -> authentication service -> database and back as a response.
6. How do you model a sequence diagram for a user login process in UML?
A sequence diagram for login shows how different components interact in a time-ordered flow when a user tries to authenticate into a system.
It captures the sequence of messages exchanged between the user interface, backend services, and database.
- Represents interaction flow between User, Login Controller, Authentication Service, and Database
- Shows step-by-step message passing for authentication and response generation
**Example: User enters credentials -> Login Controller sends request to Authentication Service -> Service verifies data with Database -> Database returns result -> response is sent back to the User (success or failure).
7. How would you model the behavior of a system using a state diagram in UML?
A state diagram in UML is used to represent how an object changes its state over time based on different events or conditions.
It defines the lifecycle of an object by showing all possible states and the transitions between them.
- Represents object states and transitions triggered by events
- Helps model lifecycle behavior of entities like orders, payments, or sessions
**Example: In a payment system, the transaction moves through states like Pending -> Processing -> Completed or Failed based on events like payment success or failure.
8. What factors influence the choice of appropriate data structures in Low-Level System Design?
The choice of data structures depends on the system requirements such as performance, memory usage, and access patterns.
It is important to select the right structure to ensure efficient operations and scalable system behavior.
- Depends on access patterns, time complexity requirements, and memory constraints
- Must consider concurrency, scalability, and specific use-case requirements
**Example: A caching system typically uses a HashMap for O(1) lookups, while a messaging system uses a Queue to maintain order of message processing.
9. When designing a database schema, what are the benefits of normalization?
Normalization is the process of organizing database tables to reduce redundancy and improve data consistency.
It ensures that data is stored in a structured way, making the database more efficient and easier to maintain.
- Eliminates data redundancy and avoids duplicate data storage.
- Improves data integrity and makes updates, inserts, and deletes more reliable.
**Example: Instead of storing customer details in every order record, normalization separates Customers and Orders into different tables, linking them through a customer ID to avoid duplication.
10. How do you design an efficient logging and monitoring system for a complex application?
An efficient logging and monitoring system ensures observability of the application by capturing logs, metrics, and alerts in a structured and centralized way.
It helps in debugging issues, tracking performance, and proactively detecting system failures.
- Uses structured logging with log levels and centralized log aggregation for better traceability
- Implements monitoring dashboards and alerting systems to track metrics like latency, CPU usage, and errors
**Example: In a microservices-based system, each service logs events with a correlation ID, which is then used in tools like ELK Stack or Grafana to trace a request end-to-end and monitor performance issues.
11. What is tight coupling and why should it be avoided in Low-Level Design?
Tight coupling occurs when classes or modules are highly dependent on each other, making changes difficult and reducing system flexibility.
In LLD, loose coupling is preferred because it improves maintainability, scalability, and testability.
- Tight coupling makes code harder to modify, reuse, and unit test
- Loose coupling can be achieved using interfaces, abstraction, and dependency injection
**Example: If a PaymentService directly creates a PayPal object internally, switching to another payment provider becomes difficult without modifying the service code.
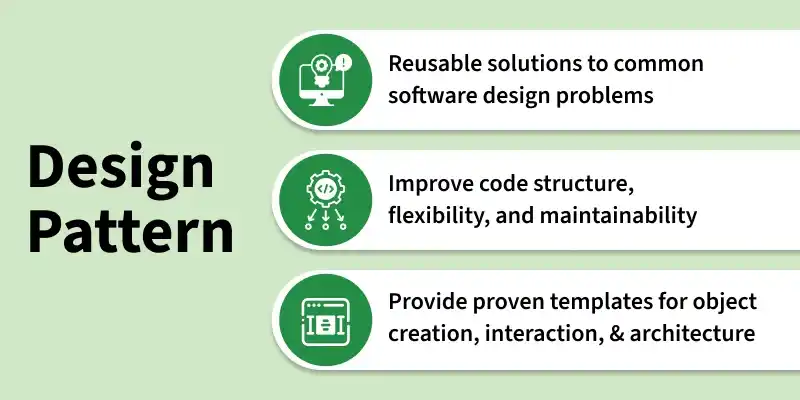
12. What are Design Patterns? Explain their importance in software development.
Design patterns are standardized and reusable solutions to common software design problems that occur in object-oriented system design. They provide a proven way to structure code for better design and maintainability.
They are important because they help developers build systems that are cleaner, more flexible, and easier to scale and maintain.
- Provide a common design language that improves consistency among developers
- Improve maintainability, scalability, and flexibility of software systems
**Example: Using the Factory Pattern in a payment system allows the application to create different payment methods (UPI, Card, Wallet) without changing the core business logic.
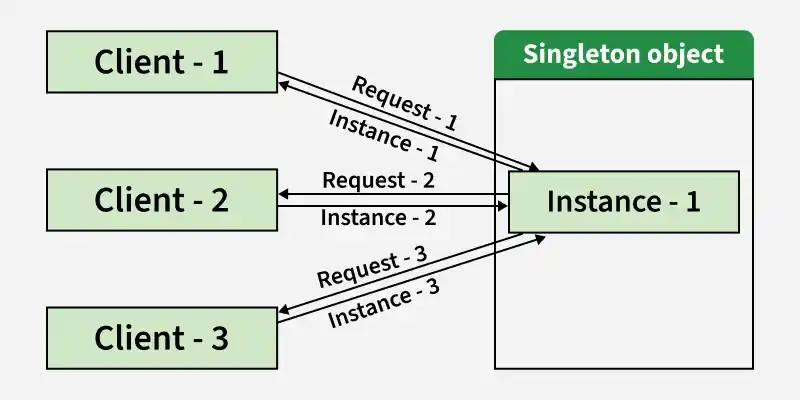
13. Can you explain the Singleton Design Pattern and its use cases?
The Singleton Pattern ensures:
- A class has only one instance.
- It provides a global access point to that instance.
**Implementation (in Java-like pseudocode):
`class Singleton { private static Singleton instance; private Singleton() {} // private constructor public static Singleton getInstance() { if (instance == null) { instance = new Singleton(); } return instance; } }
`
**Use Cases:
- **Database connection pools (only one shared instance).
- **Configuration managers (centralized global config).
- **Logging services (consistent, global logging mechanism).
**Note: Overuse can introduce global state -> harder to test and maintain.
14. What is the Observer Design Pattern? How would you implement it in a real-world scenario?
The Observer Design Pattern is a behavioral design pattern where one object (subject) maintains a list of dependent objects (observers) and automatically notifies them whenever its state changes.
It is used to establish a one-to-many relationship so that multiple objects stay updated without tight coupling.
- Defines a one-to-many relationship between a subject and multiple observers
- Automatically notifies all observers when the subject’s state changes
**Example: In a stock market system, when the stock price changes (subject), all registered traders or dashboard applications (observers) are automatically updated with the new price in real time.
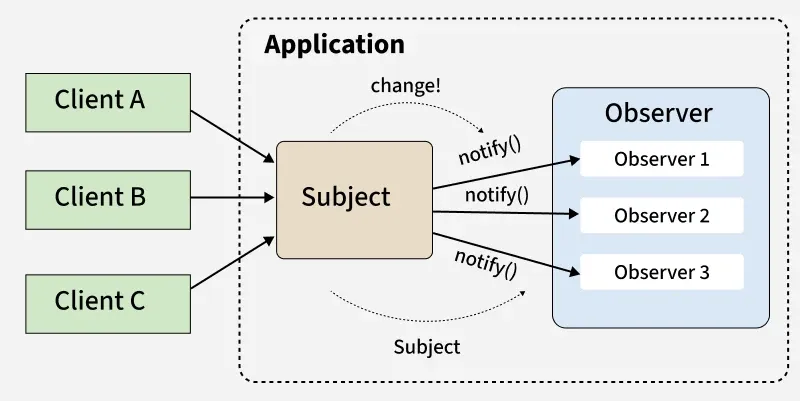
**Real-world Scenarios:
- **GUI frameworks: Button (subject) notifies listeners (observers) on click.
- **Messaging systems: Publisher sends updates -> multiple subscribers receive them.
- **Stock trading apps: Stock price change (subject) -> all trader dashboards update (observers).
**Pseudocode Example:
`interface Observer { void update(String msg); } class Subject { List observers = new ArrayList<>(); void addObserver(Observer o) { observers.add(o); } void notifyAll(String msg) { for (Observer o : observers) o.update(msg); } }
`
15. Describe the Factory Design Pattern and when you would use it.
The Factory Design Pattern is a creational design pattern that provides a way to create objects without exposing the exact creation logic to the client. Instead, object creation is handled by a factory method or class.
It helps in centralizing object creation and promoting loose coupling between the client and concrete implementations.
- Encapsulates object creation logic and hides the instantiation details from the client
- Promotes loose coupling and makes the system easier to extend and maintain
**Example: In a payment system, a Payment Factory can create different payment objects like UPI, Card, or Wallet based on user input at runtime without the client directly instantiating those classes.
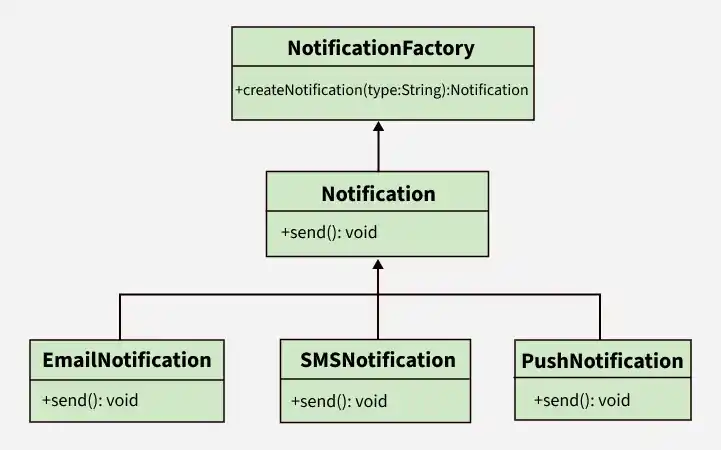
**When to Use:
- When the type of object isn’t known until runtime.
- When working with a family of related objects.
- To centralize complex creation logic.
**Example (Shape Factory):
`interface Shape { void draw(); } class Circle implements Shape { public void draw() {...} } class Square implements Shape { public void draw() {...} }
class ShapeFactory { public Shape getShape(String type) { if (type.equals("Circle")) return new Circle(); if (type.equals("Square")) return new Square(); return null; } }
`
16. What is the Strategy Design Pattern?
The Strategy Design Pattern is a behavioral design pattern that allows selecting an algorithm or behavior at runtime. Instead of implementing multiple algorithms inside a single class, each algorithm is defined separately and can be swapped dynamically.
It helps in making the system flexible and avoids tightly coupled or hardcoded logic.
- Encapsulates different algorithms into separate strategy classes
- Allows switching behavior at runtime without modifying existing code
**Example: In a payment system, different payment methods like UPI, Credit Card, or PayPal can be implemented as separate strategies, and the system can choose the appropriate one at runtime based on user selection.
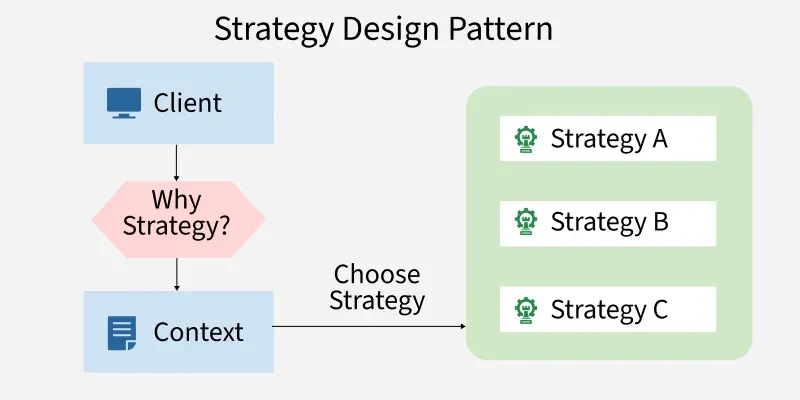
17. What is the role of interfaces in Low-Level Design?
Interfaces define a contract that classes must follow, helping different components communicate through abstraction instead of direct implementation dependency.
They are widely used in LLD to build flexible and loosely coupled systems.
- Interfaces improve extensibility and allow multiple implementations of the same behavior
- They support dependency inversion and make unit testing easier using mocks or stubs
**Example: A Notification interface can have different implementations such as EmailNotification, SMSNotification, and PushNotification without changing the client code.
18. Describe the factors influencing the choice of appropriate algorithms in the design of a sorting system for large datasets.
The choice of sorting algorithm for large datasets depends on system constraints such as data size, memory availability, and performance requirements.
It is important to select an algorithm that balances time efficiency, memory usage, and scalability.
- Depends on data size, distribution, memory constraints, and performance requirements
- Must consider stability, parallel processing capability, and whether data is in-memory or disk-based
**Example: For very large datasets that cannot fit into memory, external merge sort is used, while in-memory systems often prefer MergeSort or QuickSort depending on stability and performance needs.
19. In Low-Level System Design, how do you handle versioning and backward compatibility in evolving software systems?
Versioning and backward compatibility ensure that system updates do not break existing clients while allowing the system to evolve safely.
It involves structured API evolution, controlled database changes, and careful rollout strategies.
- Uses API versioning and controlled database migrations to manage changes safely
- Maintains backward compatibility through gradual deprecation, feature flags, and regression testing
**Example: In a REST-based service, /api/v1/users is kept active while /api/v2/users introduces new fields, ensuring older clients continue working without disruption during migration.
20. How would you design a secure authentication and authorization system in a distributed application?
A secure authentication and authorization system ensures proper verification of user identity and controlled access to resources across distributed services.
It combines secure identity management, token-based authentication, and fine-grained access control.
- Uses secure authentication mechanisms like OAuth 2.0, JWT, MFA, and password hashing for identity verification
- Implements authorization using RBAC/ABAC with centralized identity providers and secure token validation across services
**Example: In a microservices architecture, a user logs in via an identity provider, receives a JWT token, and each service validates the token before allowing access based on roles such as admin or user.
21. Why is modular design important in Low-Level Design?
Modular design divides a system into smaller independent modules, where each module handles a specific responsibility.
This approach improves system maintainability, scalability, and ease of development.
- Makes the system easier to debug, test, and extend independently
- Reduces code complexity by separating responsibilities into smaller components
**Example: In an e-commerce application, separate modules for User Management, Inventory, Payments, and Orders allow teams to work independently without affecting other parts of the system.
**22. Why is Low-Level Design (LLD) important in software development?
Low-Level Design (LLD) is important because it converts high-level architectural ideas into detailed, implementation-ready modules and components.
It provides a clear structure for developers, reducing confusion during development and improving code quality.
- Helps create maintainable, reusable, and scalable code through proper class and module design
- Reduces development errors by clearly defining object interactions, APIs, and workflows before coding begins
**Example: In a ride-sharing application, LLD defines how modules like Driver, Rider, RideRequest, and Payment interact internally, making implementation easier and more organized for developers.
**23. Which data structures are commonly used in Low-Level Design (LLD)?
In Low-Level Design, data structures are selected based on how efficiently data needs to be stored, accessed, updated, or processed within the system.
Choosing the right data structure improves application performance, memory usage, and overall code efficiency.
- Commonly used data structures include arrays, linked lists, stacks, queues, hash maps, trees, graphs, and heaps
- The choice depends on factors like lookup speed, insertion/deletion operations, ordering, and scalability requirements
**Example: A messaging application may use queues for message processing, hash maps for quick user lookup, and graphs to represent social connections between users.
**24. What are the important principles to consider while designing a database?
Database design focuses on organizing data efficiently so that it remains consistent, scalable, and easy to manage as the application grows.
A well-designed database improves query performance, reduces redundancy, and maintains data integrity.
- Important principles include normalization, proper relationships, indexing, constraints, and choosing suitable data types
- The design should also consider scalability, security, and efficient storage for long-term maintainability
**Example: In an e-commerce system, separate tables for users, orders, and products with proper foreign key relationships help maintain organized and consistent data management.
**25. Explain Object-Oriented Design (OOD) and its importance in software development.
Object-Oriented Design (OOD) is a design approach that models a system using objects, classes, and their interactions to solve real-world problems in a structured way.
It is important because it helps developers build software that is modular, reusable, scalable, and easier to maintain.
- Organizes software into classes and objects with clear responsibilities and relationships
- Encourages code reusability, flexibility, and easier maintenance through concepts like encapsulation and inheritance
**Example: In a banking application, classes such as Account, Customer, and Transaction represent real-world entities and interact with each other to perform operations like deposits and withdrawals.
26. What is Dependency Injection and why is it useful in LLD?
Dependency Injection is a design technique where dependencies are provided to a class from outside instead of being created internally by the class itself.
It helps create loosely coupled and easily testable systems.
- Improves flexibility by reducing direct dependency between classes
- Makes unit testing easier by allowing mock implementations to be injected
**Example: Instead of a UserService creating a Database object internally, the database dependency is injected through the constructor, allowing different database implementations to be used easily.
**27. What are the commonly used UML diagrams in software design?
UML (Unified Modeling Language) diagrams are visual representations used to model the structure and behavior of a software system during the design phase.
They help developers understand system architecture, object interactions, workflows, and component relationships more clearly.
- Common UML diagrams include Class Diagrams, Sequence Diagrams, Use Case Diagrams, Activity Diagrams, and State Diagrams
- These diagrams help visualize system structure, data flow, object interactions, and user behavior within the application
**Example: In a banking system, a Class Diagram may represent entities like Account and Customer, while a Sequence Diagram can illustrate the step-by-step flow of a money transfer process.
28. What are code smells and how can they be resolved?
Code smells are indicators of poor design or implementation practices in software code that may not cause immediate bugs but can make the system difficult to maintain, extend, or understand.
They highlight areas where refactoring is needed to improve code quality, readability, and maintainability.
- Common code smells include long methods, duplicated code, large classes, tight coupling, and excessive conditional statements
- Remedies include refactoring techniques such as modularization, applying design patterns, improving naming conventions, and following SOLID principles
**Example: If a single class handles user authentication, payment processing, and notifications together, it becomes a “God Class.” This can be resolved by splitting responsibilities into separate classes following the Single Responsibility Principle.
29. What are the Types of Design Patterns?
Three main types of Design Patterns are as follows
- **Creational Patterns: Deal with object creation mechanisms (e.g., Singleton, Factory).
- **Structural Patterns: Deal with object composition and inheritance (e.g., Adapter, Facade).
- **Behavioral Patterns: Deal with object interactions and communication (e.g., Observer, Strategy).
30. What Are the SOLID Principles?
The SOLID Principles are five design principles developers use to write clean, maintainable, and scalable code:
- **Single Responsibility Principle (SRP): A class should have a single reason to change.
- **Open-Closed Principle (OCP): Software entities must be open for extension but closed for modification.
- **Liskov Substitution Principle (LSP): Objects of a superclass should be replaceable with objects of its subclasses without changing the correctness of the program.
- **Interface Segregation Principle (ISP): Clients shouldn't be made to depend on interfaces they don't use.
- **Dependency Inversion Principle (DIP): High-level modules must not be dependent on low-level modules. Both of them must be dependent upon abstractions.

31. What is the DRY (Don’t Repeat Yourself) principle?
The DRY principle states that duplicate code or logic should be avoided by keeping a single reusable source of truth in the system.
It helps improve maintainability, readability, and consistency in software development.
- Reduces code duplication and makes updates easier to manage
- Encourages reusable methods, classes, and modular design practices
**Example: Instead of writing the same validation logic in multiple classes, a common ValidationService can be created and reused throughout the application.
32. When should you avoid using design patterns, and how can you prevent over-engineering?
Design patterns should be avoided when they add unnecessary complexity to a problem that can be solved with a simpler approach. Overusing patterns can lead to rigid, hard-to-maintain code and reduced readability.
- Avoid patterns when they introduce unnecessary abstraction or complexity
- Use patterns only when there is a clear design problem to solve
- Prefer simple solutions first; apply patterns only when needed
**Example: Using the Strategy Pattern for tax calculation when there is only one fixed tax rule adds unnecessary classes and complexity. A simple method is sufficient, and the pattern should be introduced only if multiple tax algorithms are needed in the future.
33. How do design patterns help in managing dependencies in large-scale applications?
Design patterns help manage dependencies by structuring interactions through abstractions instead of direct class-to-class references.
- Reduce tight coupling using interfaces and indirection
- Make dependency changes localized and predictable
**Example: In a large microservices-based system, Factory and Dependency Injection patterns manage object creation and wiring without spreading dependency logic across the codebase.
34. What is the KISS (Keep It Simple, Stupid) principle?
The KISS principle emphasizes designing systems and writing code in the simplest possible way without unnecessary complexity.
Simple designs are easier to understand, debug, maintain, and extend.
- Avoids over-engineering and keeps code clean and readable
- Improves maintainability by focusing only on required functionality
**Example: Using a simple if-else condition for a small business rule is better than introducing multiple complex design patterns unnecessarily.
35. What is the YAGNI (You Aren’t Gonna Need It) principle?
The YAGNI principle states that developers should implement only the features currently required and avoid building unnecessary functionality in advance.
It helps reduce complexity, development time, and unused code in the system.
- Prevents adding features or abstractions that are not immediately needed
- Keeps the codebase lightweight, focused, and easier to maintain
**Example: Building support for multiple payment gateways when the application currently needs only UPI payments is unnecessary and violates YAGNI.
**36. When should the Abstract Factory Pattern be preferred over the Factory Method Pattern?
The Abstract Factory Pattern should be preferred when you need to create families of related or dependent objects without specifying their concrete classes.
- When multiple related products must be created together and be compatible
- When switching entire product families at runtime is required
**Example: In a UI toolkit, Abstract Factory can create Windows buttons and menus or Mac buttons and menus together, while Factory Method would handle only one product at a time.
**37. What are the disadvantages of using the Singleton Pattern?
The Singleton Pattern can introduce hidden design and testing problems despite ensuring a single instance.
- Creates global state, making code harder to test and maintain
- Introduces tight coupling and limits flexibility
**Example: A Singleton database connection can make unit testing difficult because tests cannot easily replace it with a mock or create isolated instances.
38. How does the Proxy Pattern differ from the Decorator Pattern?
The Proxy Pattern controls access to an object, while the Decorator Pattern adds new behavior to an object dynamically.
- Proxy focuses on access control, lazy loading, or security
- Decorator focuses on extending functionality without changing the original class
**Example: A Proxy may check user permissions before accessing a file, whereas a Decorator may add logging or compression to file access without restricting it.
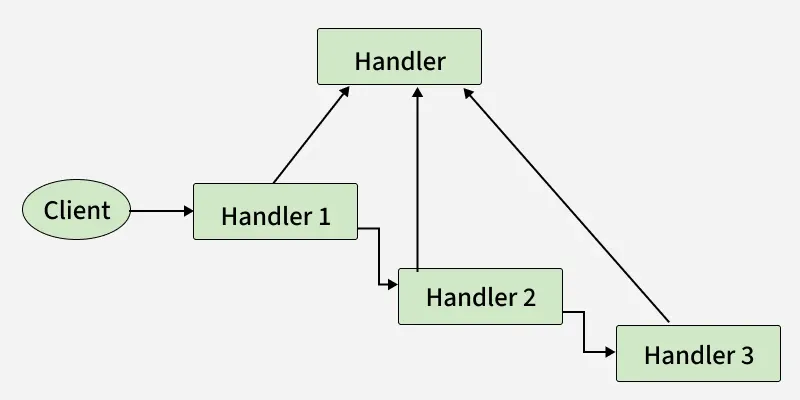
39. What problem does the Chain of Responsibility Pattern solve?
The Chain of Responsibility Pattern solves the problem of coupling a request sender to a specific request handler by passing the request through a chain of handlers.
- Allows multiple objects to handle a request without the sender knowing which one will process it
- Promotes loose coupling and flexible request handling
**Example: In an approval system, a request passes through manager, director, and CEO handlers until one of them approves it.
40. What is the difference between Composition and Aggregation in OOP?
Composition and Aggregation both represent “has-a” relationships between objects, but they differ in ownership and lifecycle dependency.
Composition represents strong ownership, while Aggregation represents a weaker relationship where objects can exist independently.
- In Composition, the child object’s lifecycle depends on the parent object
- In Aggregation, child objects can exist independently even if the parent is destroyed
**Example: A House and its Rooms represent Composition because rooms usually do not exist without the house, whereas a Department and Employees represent Aggregation because employees can exist independently of a department.
41. Explain how the Command Pattern supports undo and redo functionality.
The Command Pattern encapsulates a request as an object, allowing it to be stored, executed, and reversed later.
- Each command stores the information needed to undo an action
- Commands can be kept in a history stack for undo and redo
**Example: In a text editor, typing or deleting text is stored as command objects, enabling undo and redo by reversing or re-executing those commands.
42. What is the difference between Association, Aggregation, and Composition in OOP?
Association, Aggregation, and Composition define relationships between objects in object-oriented design, differing mainly in ownership strength and dependency.
These relationships help model real-world object interactions more clearly in UML and LLD.
- Association represents a general relationship, Aggregation shows weak ownership, and Composition shows strong ownership
- Composition has the strongest lifecycle dependency, while Association has the loosest relationship
**Example: A Teacher teaching Students is an Association, a Department having Employees is Aggregation, and a Car containing an Engine is Composition because the engine is tightly bound to the car’s lifecycle.
43. Can multiple design patterns be combined in a single solution? Provide examples.
Yes, multiple design patterns are often combined to solve complex design problems more effectively.
- Patterns complement each other by addressing different concerns
- Improves flexibility, scalability, and maintainability
**Example: In an MVC architecture, Observer is used for view updates, Strategy for interchangeable business logic, and Factory for creating objects.
44. What factors should be considered before choosing a design pattern?
Choosing a design pattern requires understanding the problem context and long-term impact on the system.
- Nature of the problem, complexity, and change frequency
- Impact on flexibility, performance, and maintainability
**Example: Using Singleton may seem simple for shared configuration, but considering testing and scalability needs might lead to choosing Dependency Injection instead.
45. How does the Null Object Pattern help eliminate null checks in code?
The Null Object Pattern replaces null references with a non-functional object that implements the same interface.
- Avoids repetitive null checks and conditional logic
- Makes code safer and easier to read
**Example: Instead of checking if a Logger is null, a NullLogger is used that performs no operation when log() is called.
46. What is the difference between static factory methods and the Factory Pattern?
Static factory methods are simple methods that return objects, while the Factory Pattern is a structured design approach for object creation using abstraction.
- Static factory methods are tied to a single class and lack polymorphism
- Factory Pattern supports extensibility through interfaces and subclasses
**Example: A static createUser() method returns a User object directly, whereas a Factory Pattern allows creating different User types without changing client code.
47. What is the difference between Abstraction and Encapsulation in OOP?
Abstraction focuses on hiding implementation details and showing only essential functionality, while Encapsulation focuses on restricting direct access to data by wrapping it inside a class.
Both concepts improve code security, maintainability, and modularity in object-oriented systems.
- Abstraction hides internal complexity, whereas Encapsulation protects data using access modifiers
- Abstraction is achieved using interfaces/abstract classes, while Encapsulation is implemented using private variables and getter-setter methods
**Example: A user can drive a car without knowing how the engine works (Abstraction), while the car’s engine components remain protected from direct access (Encapsulation).
48. How is Inheritance different from Composition in OOP?
Inheritance allows one class to acquire properties and behavior from another class, while Composition builds classes using objects of other classes.
Composition is generally preferred because it provides better flexibility and loose coupling.
- Inheritance represents an “is-a” relationship, whereas Composition represents a “has-a” relationship
- Composition makes systems easier to modify and maintain compared to deep inheritance hierarchies
**Example: A Car “has-an” Engine using Composition, while a Dog “is-an” Animal using Inheritance.
49. What is polymorphism in Object-Oriented Programming?
Polymorphism allows the same method or interface to behave differently based on the object or context in which it is used.
It improves flexibility and allows developers to write generic and reusable code.
- Compile-time polymorphism is achieved using method overloading, while runtime polymorphism uses method overriding
- Helps systems support multiple behaviors through a common interface
**Example: A Payment method may behave differently for Credit Card, UPI, or PayPal payments even though all use the same payment() function.
50. What is the difference between an Interface and an Abstract Class?
An Interface defines a contract that classes must implement, while an Abstract Class can provide both abstract and partially implemented methods.
Both are used to achieve abstraction but serve different design purposes.
- Interfaces support multiple inheritance and define behavior contracts only
- Abstract classes are used when classes share common state or partial implementation
**Example: A Vehicle interface may define methods like start() and stop(), while an abstract Vehicle class can additionally contain common properties such as speed and fuelType.
High Level Design(HLD) Interview Questions
High-Level Design (HLD) gives a big-picture view. It shows the main parts of a system and how they fit together. HLD acts as a map, focusing on modularity, scalability, and smooth integration. The aim is clear development direction while meeting business goals and technical limits.
1. What are the key components of a High-Level Design (HLD)?
High-Level Design (HLD) defines the overall architecture of a system and provides a high-level view of how different components interact with each other.
It focuses on system structure, major modules, scalability, security, and technology choices.
- Defines major system components, architecture layers, and integration points
- Includes scalability, security, database, and infrastructure considerations for the overall system
**Example: In an e-commerce application, HLD defines components like User Service, Product Service, Payment Gateway, Database, Cache, and Load Balancer, along with how they communicate within the system.
2. How do you decide between a Monolithic and Microservices Architecture in HLD?
The choice between Monolithic and Microservices architecture depends on factors such as application size, scalability requirements, system complexity, and team structure.
A monolithic architecture is suitable for smaller and simpler applications, while microservices are preferred for large-scale and highly scalable systems.
- Monolithic architecture is easier to develop and deploy but becomes difficult to scale and maintain as the system grows
- Microservices provide independent scalability and flexibility but introduce higher operational and communication complexity
**Example: A startup building an MVP may choose a monolithic architecture for faster development, whereas platforms like Netflix or Amazon use microservices to scale different services independently.
**Rule of Thumb: Start monolithic (if small) -> refactor to microservices as the system grows.
3. What are the trade-offs between a Relational and Non-Relational(NoSQL) database in an HLD?
The choice between Relational and NoSQL databases depends on factors such as data structure, scalability requirements, consistency needs, and application workload.
Relational databases are ideal for structured data and strong consistency, while NoSQL databases are preferred for scalability and flexible data models.
- Relational databases provide ACID transactions, strong consistency, and support complex SQL queries for structured data
- NoSQL databases offer flexible schemas, horizontal scalability, and high performance for large-scale distributed systems
**Example: A banking system typically uses a relational database like MySQL or PostgreSQL for transactional consistency, while social media platforms often use NoSQL databases like MongoDB or Cassandra to handle massive volumes of unstructured data and high traffic.
4. How do you ensure high availability in an HLD?
High availability ensures that a system remains operational and accessible even during failures or heavy traffic conditions.
It is achieved by eliminating single points of failure and designing the system with redundancy, failover, and distributed infrastructure.
- Uses redundancy, replication, and load balancing to keep services available during failures
- Implements failover mechanisms, monitoring, and disaster recovery strategies for reliability
**Example: In a cloud-based application, traffic is distributed across multiple servers using a load balancer, and if one server fails, requests are automatically redirected to healthy instances without downtime.
5. Explain the concept of load balancing in the context of HLD.
Load balancing is the process of distributing incoming network or application traffic across multiple servers to ensure optimal resource utilization, high availability, and better system performance.
It helps prevent any single server from becoming overloaded while improving scalability and fault tolerance.
- Distributes requests across multiple servers to improve performance and reliability
- Prevents server overload and ensures high availability by eliminating single points of failure
**Example: In a web application, a load balancer like Nginx or AWS ELB distributes user requests among multiple application servers so that traffic is handled efficiently even during peak load.
6. What are the key considerations for designing a scalable system in HLD?
Designing a scalable system involves ensuring that the application can efficiently handle increasing users, traffic, and data without performance degradation.
It requires distributing workloads, optimizing resource usage, and reducing bottlenecks across the system.
- Uses techniques like horizontal scaling, caching, partitioning, and database replication to handle increased load
- Improves performance and reliability through asynchronous processing and distributed infrastructure
**Example: A video streaming platform uses CDNs for static content delivery, Redis for caching, and multiple application servers behind a load balancer to support millions of concurrent users.
7. How do you handle security concerns in HLD?
Security in High-Level Design is achieved by incorporating protection mechanisms at every layer of the system architecture rather than treating security as an afterthought.
It involves securing user access, data transmission, APIs, and infrastructure to protect the system from unauthorized access and attacks.
- Implements authentication, authorization, encryption, and secure API practices to protect system resources
- Uses monitoring, logging, input validation, and zero-trust principles to detect and prevent security threats
**Example: In a banking application, users authenticate using OAuth 2.0 with MFA, all communication is encrypted using HTTPS/TLS, and role-based access control ensures users can only access authorized resources.
8. What is Database Indexing?
Database indexing is a technique used to improve the speed of data retrieval operations by creating a structured reference to data in a database table.
Indexes help databases locate records quickly without scanning the entire table.
- Improves query performance and reduces data retrieval time significantly
- Adds extra storage overhead and may slightly slow down insert or update operations
**Example: In a banking application, an index on the account number field allows the system to quickly find customer accounts during transactions.
9. What are the steps involved in designing an API in HLD?
Designing an API in HLD involves defining how different systems or clients will communicate with the application in a secure, scalable, and standardized way.
It requires careful planning of endpoints, data formats, authentication, error handling, and versioning.
- Defines resources, endpoints, request/response formats, and communication standards for the system
- Includes authentication, rate limiting, versioning, and proper documentation for secure and maintainable APIs
**Example: In an e-commerce application, APIs like /users, /products, and /orders are designed with JSON responses, JWT-based authentication, and versioning such as /api/v1/orders for backward compatibility.
10. How do you ensure data consistency across distributed systems in HLD?
Data consistency in distributed systems ensures that all nodes or services eventually maintain accurate and synchronized data even when multiple operations occur simultaneously.
The consistency approach depends on business requirements, system scalability, and availability needs.
- Uses techniques like distributed transactions, idempotent operations, and conflict resolution to maintain consistent data
- Chooses between strong consistency and eventual consistency based on system requirements and CAP theorem trade-offs
**Example: In an online banking system, strong consistency is used to ensure account balances remain accurate during transactions, while a social media feed may use eventual consistency for better scalability and availability.
11. What role does fault tolerance play in HLD?
Fault tolerance ensures that a system continues to function properly even when some components fail or become unavailable.
It improves system reliability by minimizing downtime and preventing failures from affecting the entire application.
- Uses redundancy, replication, and failure isolation to keep the system operational during failures
- Improves reliability and user experience through graceful degradation and recovery mechanisms
**Example: In a microservices-based application, if the recommendation service fails, the main application can still function by temporarily disabling recommendations instead of bringing down the entire system.
12. How do you design for disaster recovery in HLD?
Disaster recovery in HLD focuses on ensuring that the system can quickly recover and continue operating after major failures such as server crashes, data loss, or regional outages.
It involves backup strategies, data replication, failover mechanisms, and recovery planning to minimize downtime and data loss.
- Uses backups, geo-replication, and automated failover systems to maintain business continuity
- Defines recovery objectives like RPO and RTO to ensure fast and reliable system restoration
**Example: A cloud application replicates its database across multiple regions, so if one data center fails, traffic is automatically redirected to another region with minimal downtime and data loss.
13. Explain the concept of Event-Driven Architecture in HLD.
Event-Driven Architecture (EDA) is a design approach where system components communicate through events instead of direct synchronous calls, enabling loosely coupled and asynchronous interactions.
In this architecture, producers generate events, which are processed by consumers through an event broker or message queue.
- Enables asynchronous communication and improves scalability by decoupling system components
- Increases system resilience and flexibility, allowing services to evolve independently
**Example: In an e-commerce system, when an order is placed, an event is published to Kafka or RabbitMQ, and different services like payment, inventory, and notification systems consume the event independently to perform their tasks.
14. How does a cache know when it is full and decide what data to remove?
A cache continuously tracks its current memory usage whenever new data is added, updated, or removed.
Every cache entry has a size, and the cache manager maintains an internal counter of total memory consumption.
- When new data is inserted, the cache first calculates the size of that data and adds it to the current memory usage
- If the total memory exceeds the configured cache limit, the cache immediately triggers an eviction policy like LRU or LFU to free space
**Example: Suppose Redis cache has a limit of 1 GB and is currently using 950 MB. If a new object of 100 MB is added, Redis detects that total usage becomes 1.05 GB, which exceeds the limit. The cache then automatically removes older or less-used entries until memory usage goes below 1 GB again.
15. How do you handle concurrency control in HLD?
Concurrency control in HLD ensures that multiple users or processes can safely access and modify shared data without causing inconsistencies or conflicts.
It uses techniques like locking, isolation levels, and MVCC to maintain data integrity during simultaneous operations.
- Prevents issues like dirty reads, lost updates, and inconsistent data states during concurrent access
- Uses locking mechanisms, isolation levels, or MVCC based on system requirements and workload patterns
**Example: In a banking application, concurrency control ensures that two users cannot simultaneously update the same account balance incorrectly during fund transfers or withdrawals.
16. What are the principles of RESTful API design in HLD?
RESTful API design follows a set of architectural principles that enable scalable, standardized, and easy-to-maintain communication between clients and servers.
It focuses on resource-based communication, stateless interactions, and proper usage of HTTP standards.
- Uses resource-oriented URIs, standard HTTP methods, and status codes for consistent API communication
- Ensures scalability and maintainability through statelessness, versioning, and content negotiation
**Example: In a user management system, APIs like GET /users/1, POST /users, and DELETE /users/1 follow REST principles by treating users as resources and using appropriate HTTP methods for operations.
17. Explain the role of a message broker in HLD and give examples.
A message broker is a middleware component that enables asynchronous communication between different services or applications by receiving, storing, and forwarding messages.
It helps decouple system components, improving scalability, reliability, and fault tolerance in distributed systems.
- Enables asynchronous communication and loose coupling between services
- Improves scalability, reliability, and fault isolation through message buffering and delivery management
**Example: In an e-commerce application, when an order is placed, a message broker like Kafka or RabbitMQ sends events to inventory, payment, and notification services independently without direct service-to-service communication.
18. What is Database Replication?
Database replication is the process of copying and maintaining the same data across multiple database servers to improve availability, reliability, and performance.
It helps systems continue functioning even if one database server fails.
- Improves fault tolerance and high availability by maintaining multiple copies of data
- Enhances read scalability by distributing read requests across replica databases
**Example: In an e-commerce platform, the primary database handles writes, while replica databases serve read requests like product searches and order history.
19. What are the considerations for designing a fault-tolerant network infrastructure in HLD?
A fault-tolerant network infrastructure is designed to keep the system operational even when network components, servers, or connections fail.
It focuses on redundancy, traffic management, isolation, and disaster recovery to ensure reliability and continuous service availability.
- Uses redundant network paths, load balancing, and dynamic routing to avoid single points of failure
- Implements isolation, security mechanisms, and disaster recovery strategies to maintain system stability during failures
**Example: In a cloud-based application, if one data center or network route becomes unavailable, traffic is automatically redirected through backup routes and standby servers to ensure uninterrupted service.
20. What role does containerization play in HLD, and how does it benefit system architecture?
Containerization packages applications and their dependencies into isolated containers, ensuring consistent execution across different environments.
It improves scalability, deployment efficiency, and reliability, making it highly suitable for modern distributed and microservices-based architectures.
- Provides environment consistency, resource efficiency, and easy scalability through container orchestration platforms like Kubernetes
- Supports microservices architecture by isolating services and improving deployment, maintenance, and fault isolation
**Example: In a microservices application, each service such as authentication, payment, and notification runs inside separate Docker containers, allowing independent deployment and scaling without affecting other services.
21. How do you design for data privacy and protection in HLD?
Designing for data privacy and protection involves securing sensitive information throughout its lifecycle and ensuring that only authorized users can access it.
It requires implementing encryption, access controls, compliance standards, and continuous monitoring to protect data from unauthorized access and breaches.
- Uses encryption, access control mechanisms, and data masking techniques to secure sensitive information
- Ensures compliance, auditing, and regular security assessments to maintain data privacy and system trust
**Example: In a healthcare application, patient records are encrypted using AES, access is restricted through role-based permissions, and all data access activities are logged to comply with regulations like HIPAA.
22. Explain the concept of a distributed cache in HLD and its advantages.
A distributed cache is a caching system where cached data is stored across multiple servers or nodes instead of a single machine, allowing faster and scalable data access in distributed applications.
It helps reduce database load and improves application performance by serving frequently accessed data from memory.
- Improves response time and scalability by distributing cached data across multiple nodes
- Reduces database load and provides fault tolerance through cache replication and distribution
**Example: In an e-commerce platform, frequently accessed product details are stored in a distributed cache like Redis Cluster, enabling faster responses even during high traffic periods.
23. How do you ensure data integrity in an HLD, and what techniques can be employed?
Data integrity in HLD ensures that data remains accurate, consistent, and reliable throughout its lifecycle, even during failures or concurrent operations.
It is maintained through validation, database constraints, transactions, and secure data handling practices.
- Uses constraints, validation, and ACID transactions to maintain consistency and prevent invalid data operations
- Employs checksums, encryption, logging, and error handling to detect and protect against data corruption or inconsistencies
**Example: In a banking system, database transactions ensure that money is deducted from one account and credited to another atomically, preventing partial or inconsistent updates during fund transfers.
24. How does the CAP theorem affect the design of a distributed database?
The CAP theorem states that a distributed system can guarantee only two out of three properties: Consistency, Availability, and Partition Tolerance.
It helps architects decide the trade-offs a distributed database should make based on business and system requirements.
- CP systems prioritize consistency and partition tolerance, while AP systems prioritize availability and partition tolerance
- The database design choice depends on whether the application values strict consistency or continuous availability more
**Example: A banking application typically prefers consistency to ensure accurate transactions, while a social media platform may prioritize availability so users can continue accessing the system even during network failures.
25. How is Horizontal Scaling different from Vertical Scaling?
Scaling is the process of increasing a system’s capacity to handle higher traffic, users, or workloads. Horizontal and Vertical scaling are two common approaches used in system design.
Horizontal scaling adds more machines to the system, while vertical scaling increases the power of an existing machine.
- Horizontal scaling increases capacity by adding more servers, improving scalability and fault tolerance
- Vertical scaling upgrades existing hardware resources like CPU, RAM, or storage, but has hardware limitations
**Example: A social media platform may use horizontal scaling by adding multiple application servers behind a load balancer, while a small application may use vertical scaling by upgrading a single server’s RAM and CPU.
26. What is Rate Limiting?
Rate limiting is a technique used to control the number of requests a client can send to a server within a specific time period.
It protects systems from abuse, excessive traffic, and denial-of-service attacks.
- Prevents server overload and ensures fair resource usage among users
- Improves system stability and security by controlling API traffic
**Example: A public API may allow only 100 requests per minute per user to prevent misuse and maintain performance.
27. Explain the concepts of latency, throughput, and availability in system design.
Latency, throughput, and availability are important metrics used to measure the performance and reliability of a system. These factors help determine how efficiently a system handles user requests and stays operational.
Latency measures response delay, throughput represents the amount of work handled, and availability defines how often the system remains accessible.
- Latency refers to the time taken by the system to process and respond to a request
- Throughput measures the number of requests handled in a given time, while availability indicates system uptime and reliability
**Example: In a video streaming platform, low latency ensures videos start quickly, high throughput allows millions of users to stream simultaneously, and high availability keeps the service accessible without interruptions.
28. How does sharding differ from database partitioning?
Sharding and partitioning are techniques used to divide large datasets into smaller parts for better performance and manageability. Although both split data, they differ in how and where the data is distributed.
Partitioning usually divides data within the same database system, while sharding distributes data across multiple database servers.
- Partitioning organizes data into smaller sections inside a single database instance
- Sharding spreads data across multiple servers to improve scalability and handle massive workloads
**Example: A company may partition customer records by region within one database, but a large social media platform may shard user data across multiple servers to support millions of active users worldwide.
29. Explain caching and the different cache update strategies used in system design.
Caching is a technique used to temporarily store frequently accessed data in fast memory so that future requests can be served quickly without repeatedly querying the main database or backend service.
It helps reduce response time, lowers server load, and improves the overall efficiency of the application.
- Common cache update strategies include Write-Through, Write-Back, Cache-Aside, and Write-Around caching
- The choice of strategy depends on factors like consistency requirements, read/write patterns, and performance needs
**Example: In an e-commerce application, frequently viewed product details may be stored in Redis cache. When a product is updated, the cache can either be updated immediately (Write-Through) or refreshed only when needed (Cache-Aside).
30. Explain the concept of a Content Delivery Network (CDN) in system design.
A Content Delivery Network (CDN) is a distributed network of servers that stores and delivers cached content from locations closer to end users.
Its main goal is to reduce loading time, decrease server traffic, and provide faster content delivery across different geographic regions.
- Delivers static content like images, videos, and files from nearby edge servers for quicker access
- Reduces load on the main server and improves application performance during heavy traffic
**Example: When a user watches videos on a streaming platform, the CDN serves the content from the nearest edge server instead of the origin server, resulting in faster playback and lower latency.
31. Explain the concept of leader election in distributed systems.
Leader election is a process in distributed systems where one node is selected as the coordinator or leader to manage specific tasks and make centralized decisions for the cluster.
The elected leader handles responsibilities like coordination, synchronization, task scheduling, and maintaining consistency among nodes.
- Ensures that only one node performs critical coordination tasks at a given time
- Helps maintain consistency and avoid conflicts in distributed environments
**Example: In a distributed database cluster, one server may be elected as the leader to manage write operations, while other nodes act as followers and replicate the data.
32. How do message queues like Kafka and RabbitMQ improve system design?
Message queues like Kafka and RabbitMQ are communication mechanisms that allow different services or components to exchange data asynchronously without directly depending on each other.
They help systems process tasks more efficiently by decoupling services and managing high volumes of requests smoothly.
- Enable asynchronous communication between services, reducing direct dependency and system bottlenecks
- Improve scalability and reliability by buffering messages and handling traffic spikes efficiently
**Example: In a food delivery application, once an order is placed, a message queue sends events separately to payment, notification, and delivery services so each task can be processed independently without slowing down the main application.
33. Differentiate between synchronous and asynchronous communication in distributed systems.
Synchronous and asynchronous communication are two ways services interact in distributed systems. The main difference lies in whether the sender waits for an immediate response or continues processing independently.
Synchronous communication waits for a reply before moving forward, while asynchronous communication allows tasks to continue without blocking.
- In synchronous communication, the client waits for the server response, leading to tighter coupling and possible delays
- In asynchronous communication, requests are processed independently, improving scalability and responsiveness
**Example: A payment verification API is usually synchronous because the user waits for confirmation instantly, whereas email notifications are commonly asynchronous and processed later through message queues like Kafka or RabbitMQ.
34. Explain how you would design an API Gateway.
An API Gateway acts as a single entry point for client requests in a microservices architecture. It receives requests from clients and routes them to the appropriate backend services.
It also handles common functionalities like authentication, rate limiting, logging, and request aggregation.
- Centralizes request routing, authentication, monitoring, and traffic management for multiple services
- Reduces complexity for clients by providing a unified interface to backend microservices
**Example: In an e-commerce platform, the API Gateway receives requests from mobile and web applications and forwards them to services like user management, product catalog, and payment processing while also validating JWT tokens and applying rate limits.
35. What is the Circuit Breaker Pattern?
The Circuit Breaker Pattern is a fault-tolerance design pattern used in distributed systems to prevent repeated requests to a failing service.
It improves system resilience by stopping cascading failures during outages.
- Prevents unnecessary calls to failed services and allows systems to recover gracefully
- Improves reliability and response time during partial system failures
**Example: In a microservices application, if the payment service becomes unavailable, the circuit breaker temporarily blocks requests and returns fallback responses instead of repeatedly retrying failed calls.
36. Explain Consistent Hashing.
Consistent hashing is a distributed hashing technique used to evenly distribute data across multiple servers while minimizing data movement when servers are added or removed.
It is commonly used in distributed caching and database sharding systems.
- Reduces data redistribution when scaling servers up or down
- Improves scalability and load distribution in distributed systems
**Example: Distributed caching systems like Redis Cluster use consistent hashing to distribute cached data across multiple cache nodes efficiently.
37. What is Service Discovery?
Service discovery is a mechanism in microservices architecture that allows services to dynamically find and communicate with each other without hardcoded network locations.
It helps systems manage changing service instances automatically.
- Enables automatic detection and communication between distributed services
- Improves scalability and flexibility in dynamic cloud environments
**Example: In Kubernetes, services automatically discover other services using internal DNS and service registries.
38. What is a Reverse Proxy?
A reverse proxy is a server that receives client requests and forwards them to backend servers on behalf of the clients. it acts as an intermediary between users and application servers.
- Improves security, load balancing, caching, and request routing
- Hides backend server details and helps distribute incoming traffic efficiently
**Example: Nginx works as a reverse proxy by forwarding user requests to multiple application servers behind it.
39. What is the difference between ACID and BASE?
| ACID | BASE |
|---|---|
| Focuses on strong consistency and reliability | Focuses on high availability and scalability |
| Commonly used in relational databases | Commonly used in NoSQL databases |
| Follows strict transaction rules | Allows eventual consistency |
| Suitable for critical transactional systems | Suitable for large distributed systems |
| Prioritizes data accuracy over availability | Prioritizes availability over immediate consistency |
**Example: Banking systems use ACID databases like PostgreSQL for accurate transactions, while social media platforms use BASE databases like Cassandra for scalability and availability.
40. What is the difference between HLD and LLD?
| HLD (High-Level Design) | LLD (Low-Level Design) |
|---|---|
| Focuses on overall system architecture | Focuses on detailed component implementation |
| Defines modules, databases, APIs, and scalability | Defines classes, methods, and object interactions |
| Used during system planning phase | Used before actual coding begins |
| Describes how major components communicate | Describes internal logic of each module |
| More architecture-oriented | More code-oriented |
**Example: In a food delivery app, HLD defines services like User Service and Payment Service, while LLD designs classes such as User, Order, and PaymentProcessor.
41. What is the difference between Stateful and Stateless Systems?
| Stateful System | Stateless System |
|---|---|
| Stores session or client state on the server | Does not store client state on the server |
| Each request depends on previous requests | Every request is independent |
| Harder to scale in distributed systems | Easier to scale and load balance |
| Requires session management | No session storage required |
| Better for long user interactions | Better for scalable APIs and microservices |
**Example: Traditional web login sessions are stateful because the server stores session data, while REST APIs are stateless because each request contains complete authentication information like JWT tokens.
42. What is the OSI Model?
The OSI (Open Systems Interconnection) Model is a conceptual framework used to understand how different networking components communicate in a computer network.
It divides network communication into seven layers, where each layer performs a specific function.
- Helps standardize network communication and simplifies troubleshooting between systems
- Separates networking tasks into layers like Application, Transport, Network, and Physical for better modularity
**Example: When a user opens a website, data passes through all OSI layers, from the Application Layer (HTTP request) to the Physical Layer (network transmission).
43. What is the TCP/IP Model?
The TCP/IP Model is a networking model used for communication over the internet and modern computer networks.
It defines how data is transmitted between devices using protocols such as TCP, IP, HTTP, and UDP.
- Consists of four layers: Application, Transport, Internet, and Network Access Layer
- Forms the foundation of internet communication and real-world networking systems
**Example: When sending an email, protocols like SMTP use the TCP/IP model to transfer data reliably across networks.
44. What is the difference between HTTP and HTTPS?
| HTTP | HTTPS |
|---|---|
| Stands for HyperText Transfer Protocol | Stands for HyperText Transfer Protocol Secure |
| Data is transferred in plain text | Data is encrypted using SSL/TLS |
| Less secure for sensitive information | Provides secure communication over the internet |
| Uses port 80 by default | Uses port 443 by default |
| Suitable for non-sensitive websites | Used for banking, payments, and secure applications |
**Example: An online banking website uses HTTPS to encrypt user credentials and payment information during transmission.
45. What is the difference between TCP and UDP?
| TCP | UDP |
|---|---|
| Connection-oriented protocol | Connectionless protocol |
| Provides reliable data delivery | Does not guarantee delivery |
| Slower due to error checking and acknowledgments | Faster with lower overhead |
| Used where accuracy is important | Used where speed is more important |
| Suitable for file transfer and web applications | Suitable for gaming and video streaming |
**Example: Websites and banking systems use TCP for reliable communication, while online games and live video streaming often use UDP for faster data transfer.
46. What is DNS and why is it important?
DNS (Domain Name System) is a system that translates human-readable domain names into IP addresses so computers can locate and communicate with each other over the internet.
It acts like the phonebook of the internet.
- Converts domain names like google.com into machine-readable IP addresses
- Improves usability by allowing users to access websites using easy-to-remember names instead of numeric IPs
**Example: When a user enters “youtube.com” in the browser, DNS converts the domain name into an IP address so the browser can connect to the correct server.
47. What happens during a cache miss?
A cache miss occurs when the requested data is not found in the cache memory, forcing the system to fetch the data from the main database or backend service.
After retrieving the data, the system usually stores it in the cache for faster future access.
- Increases response time temporarily because the system must access slower backend storage
- Frequently accessed data is cached after retrieval to improve future performance and reduce database load
**Example: If a user searches for a product that is not available in Redis cache, the application fetches the product details from the database and then stores them in the cache for subsequent requests.
48. What is cache invalidation?
Cache invalidation is the process of removing or updating outdated data from the cache to ensure users receive the most recent and correct information.
It helps maintain consistency between cached data and the original data source.
- Prevents stale or outdated data from being served to users
- Can be performed using techniques like TTL (Time-To-Live), write-through updates, or manual invalidation
**Example: In an e-commerce application, when a product price changes in the database, the old cached product information is invalidated or updated so users always see the latest price.
49. What happens if the leader node fails in a distributed system?
In a distributed system, if the leader node fails, the remaining nodes detect the failure and elect a new leader to continue coordination and system operations.
This process helps maintain system availability and consistency without manual intervention.
- Failure detection is usually performed using heartbeat signals or timeout mechanisms between nodes
- A leader election algorithm like Raft or Paxos selects a new leader automatically to restore normal operations
**Example: In a distributed database cluster, if the primary server crashes, one of the replica nodes is automatically promoted as the new leader to continue handling write operations.
50. How does auto-scaling work in distributed systems?
Auto-scaling is a cloud computing feature that automatically increases or decreases system resources based on traffic, workload, or performance metrics.
It helps maintain application performance while optimizing infrastructure costs.
- Automatically adds servers during high traffic and removes unused servers during low traffic periods
- Uses monitoring metrics like CPU usage, memory usage, or request count to trigger scaling actions
**Example: During a festival sale, an e-commerce platform automatically launches additional application servers to handle increased user traffic and removes extra servers once traffic decreases.
51. What is Sticky Session in Load Balancing?
Sticky Session, also known as Session Persistence, is a load balancing technique where requests from the same user are always routed to the same backend server during a session.
It helps maintain user session data without sharing session information across multiple servers.
- Ensures user-specific session data remains available on the same server throughout the interaction
- Commonly implemented using cookies, client IP addresses, or session identifiers
**Example: In an online shopping website, if a user adds items to the cart, sticky sessions ensure subsequent requests from that user continue going to the same server so the cart data remains consistent during checkout.
52. How does a load balancer know whether a server is working or failed?
A load balancer regularly checks all servers by sending small test requests called health checks or heartbeat signals.
If a server responds correctly, the load balancer considers it healthy. If the server does not respond, it is marked as failed.
- The load balancer keeps checking servers continuously at fixed time intervals.
- If the server does not respond or returns errors multiple times, the load balancer marks it as failed and stops sending requests to it.
**Example: Imagine a food delivery app running on 4 servers. If one server suddenly crashes, the load balancer detects that the server is not replying to heartbeat checks and immediately stops sending user requests to that server. Users continue using the app normally through the remaining healthy servers.